Resistencia de diseño y directiva
Probablemente la expresión que más hayamos escuchado junto a "recuperación ante desastres" sea "continuidad del negocio". La continuidad tieen una connotación positiva. hace referencia la conveniencia de confinar el ámbito de un evento de desastre (o incluso de algo con un ámbito más reducido) a "las paredes" de un centro de datos.
Pero "continuidad" no es un término de ingeniería, a pesar de los esfuerzos en intentar que lo sea. La continuidad empresarial no tiene una fórmula, metodología o receta única. En toda organización hay un conjunto único de procedimientos recomendados que obedecen al tipo de negocio de la empresa y cómo se desarrolla. La continuidad es la puesta en marcha de estos procedimientos correctamente para lograr un resultado positivo.
El significado de resistencia
Los ingenieros entienden el concepto de resistencia. Cuando un sistema funciona correctamente en distintas circunstancias, se dice que es resistente. Un administrador de riesgos considera que una empresa está bien preparada cuando ha puesto en marcha medidas de seguridad a prueba de errores y procedimientos ante desastres listos para responder a cualquier impacto perjudicial al que pueda estar expuesta. Puede que un ingeniero no perciba el entorno en el que un sistema opera en términos tan absolutos, como "normal" y "amenazado", "seguridad" y "desastre", sino que considere que el sistema que hay detrás de una empresa funciona como debe cuando proporciona niveles de servicio continuos y predecibles en caso de que se produzcan circunstancias adversas.
En 2011, justo cuando la informática en la nube empezó a convertirse en tendencia creciente en los centros de datos, la Agencia de la Unión Europea para la Ciberseguridad (ENISA) publicó un informe en respuesta a una petición gubernamental por parte de la UE para obtener información sobre la resistencia de los sistemas usados para reunir y recopilar datos. El informe evidenció claramente que aún era necesario llegar a un consenso entre el personal de TI y comunicaciones europeo sobre qué significa realmente "resistencia", o cómo debe medirse.
A raíz de esto, la ENISA descubrió un proyecto creado por un equipo de investigadores en la Universidad de Kansas (KU) y dirigido por el Profesor James P. G. Sterbenz con vistas de implementarse en el Departamento de Defensa de EE. UU. Este proyecto, conocido como ResiliNets (iniciativa de redes resistentes y de supervivencia) 1, es un método para visualizar el estado fluctuante de la resistencia en los sistemas de información en diversos casos. ResiliNets es el prototipo de un modelo de consenso para la directiva de resistencia en las organizaciones.
Este modelo usa una serie de métricas conocidas y fáciles de explicar, algunas de las cuales ya se han mencionado en este capítulo, a saber:
Tolerancia a errores: como se ha explicado anteriormente, es la capacidad de un sistema para mantener los niveles de servicio esperados cuando hay errores.
Tolerancia a interrupciones: es la capacidad de ese mismo sistema para mantener los niveles de servicio esperados en caso de que se produzcan circunstancias impredecibles y, a menudo, situaciones operativas más extremas que sean ajenas al propio sistema (por ejemplo, cortes de electricidad, escasez del ancho de banda de Internet y picos de tráfico).
Supervivencia: es una estimación de la capacidad de un sistema para proporcionar unos niveles de rendimiento de servicio razonables, si no nominales, en todas las circunstancias posibles, como desastres naturales.
La teoría clave que ResiliNets pone sobre la mesa es que los sistemas de información se consiguen ser más resistentes a través de una combinación de ingeniería de sistemas y esfuerzo humano. Lo que los individuos hacen (es más, lo que hacen continuamente en su labor diaria) es lo que hace que los sistemas sean más seguros.
Tomando como referencia la forma en que soldados, marinos y marines aprenden y recuerdan los principios tácticos a través de una serie de maniobras perfectamente orquestadas, el equipo de la Universidad de Kansas propuso una regla mnemotécnica para recordar el ciclo de vida de la práctica de ResiliNets: D2R2 + DR. Las variables que se muestran en la Figura 9 hacen referencia a lo siguiente, en orden:**
Defender el sistema de las amenazas a su funcionamiento normal
Detectar la aparición de efectos adversos debido a posibles errores, así como a circunstancias externas
Resolver el impacto posterior que esos efectos podrían tener en el sistema, aun cuando ese impacto deba sostenerse
Recuperar los niveles de servicio normales
Diagnosticar las causas raíz de los eventos
Refinar futuros comportamientos según sea necesario para estar mejor preparados cuando el evento vuelva a aparecer
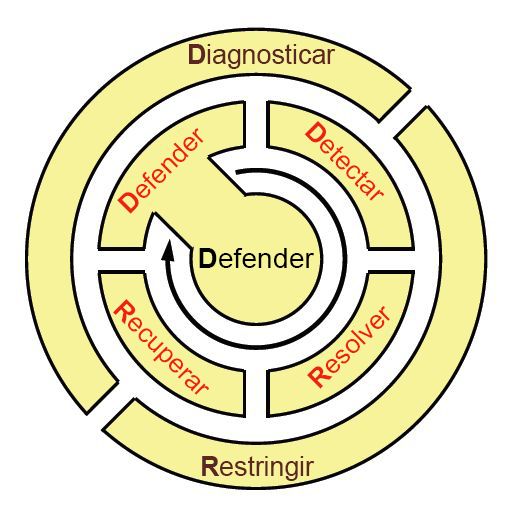
Figura 9: Ciclo de vida de las actividades de procedimientos recomendados en un entorno donde se usa ResiliNets
Durante cada una de estas fases, se obtienen unas métricas de rendimiento y de funcionamiento, relativas tanto a individuos como a sistemas. La combinación de estas métricas genera unos puntos que se pueden representar en un gráfico como el de la Figura 9.10 usando un plano geométrico euclidiano. Cada métrica se puede reducir a dos valores unidimensionales: uno que refleja los parámetros de nivel de servicio, P, y otro que representa el estado operativo, N. A medida que las seis fases del ciclo de ResiliNets se van implementando y repitiendo, el estado del servicio, S, se traza en las coordenadas del gráfico (N, P).
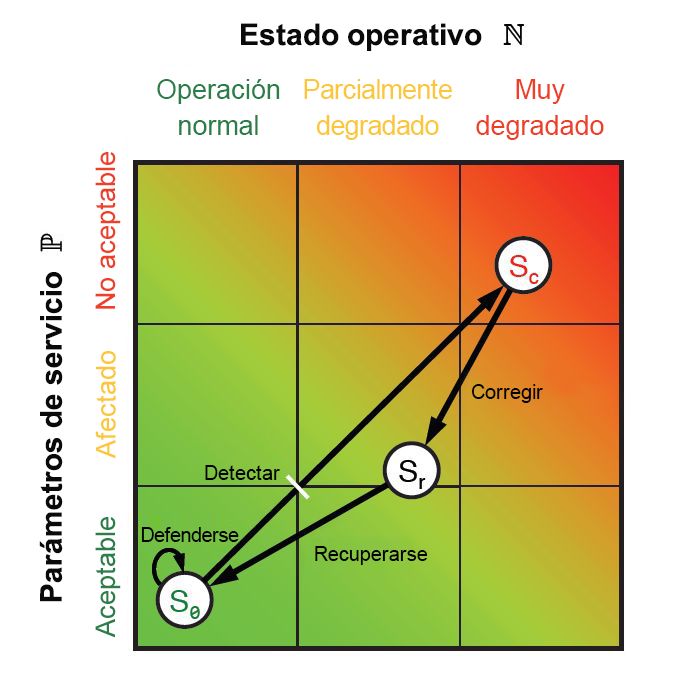
Figura 10: Espacio de estado y bucle interno de la estrategia de ResiliNets
Una organización que cumpla sus objetivos de servicio mantendrá su estado S rondando firmemente la esquina inferior izquierda del gráfico y, con suerte, permanecerá ahí o cerca de esa zona durante lo que se conoce como bucle interno. A medida que los objetivos de servicio se vayan degradando, el estado se irá desplazando por un vector no deseado hacia la esquina superior derecha.
Aunque el modelo ResiliNets no es un reflejo universal de la resistencia de TI en las empresas, su adopción por parte de algunas organizaciones destacadas, especialmente en el sector público, ha desencadenado algunos de los cambios que han cristalizado en la revolución en la nube:
Visualización del rendimiento. No es necesario que la resistencia sea una filosofía para que su estado actual se pueda comunicar a las partes interesadas pertinentes. De hecho, se puede demostrar con menos de una palabra. Las plataformas de administración de rendimiento modernas que incorporan métricas de la nube incluyen paneles y herramientas similares que se justifican solas de manera eficaz.
No es necesario que los procedimientos y las medidas de recuperación esperen a que un desastre se produzca. Un sistema de información completo y bien diseñado, vigilado continuamente por ingenieros y operadores, implementará procedimientos de mantenimiento de forma diaria que diferirán mínimamente, si lo hacen, de los procedimientos de corrección durante una crisis. En un entorno de recuperación ante desastres en espera activa, por ejemplo, la corrección del problema de nivel de servicio puede ser automático: el enrutador principal simplemente desviará el tráfico para que no llegue a los componentes afectados. Por expresarlo de otra manera: prepararse para un error no tiene que ser lo mismo a esperar a que ese error se produzca.
Los sistemas de información se componen de personas. La automatización puede hacer que las personas sean más productivas y, de igual modo, que los productos se generen de forma más eficaz, pero nunca podrá sustituir a las personas en un sistema diseñado para responder a los cambios circunstanciales y del entorno que no se pueden prever.
Informática orientada a la recuperación
ResiliNets es la implementación de un concepto que Microsoft ha contribuido a acuñar justo después del cambio de siglo, denominado informática orientada a la recuperación (ROC).2 Su principio básico reside en que los errores y los fallos son verdades inamovibles de los entornos informáticos. Así, en lugar de dedicar cantidades de tiempo desorbitadas a desinfectar ese entorno, quizá fuera mejor que las organizaciones pongan en marcha medidas sensatas que contribuyan a la vacunación del entorno. Sería el equivalente informático del concepto radical, nacido justo antes del siglo XX, de que tenemos que lavarnos las manos varias veces al día.
Resistencia en la nube pública
Todos los proveedores de servicios en la nube pública se adhieren a los principios y marcos de la resistencia, incluso cuando deciden no llamarla de esa forma. Con todo, una plataforma en la nube no agrega resistencia al centro de datos de una organización, a menos que absorba los recursos de información de la organización en la nube en su totalidad. Una implementación de nube híbrida es resistente en la medida en que lo es su administrador menos diligente. Si damos por sentado que los administradores de un CSP van a ser diligentes a la hora de cumplir los requisitos de resistencia (o, de no hacerlo , de infringir los términos de sus contratos de nivel de servicio), mantener la resistencia de todo el sistema siempre deberá ser tarea del cliente.
Marco de resistencia de Azure
La norma estándar internacional de estrategia de continuidad empresarial es la ISO 22301. Al igual que sucede con otros marcos de trabajo de International Standards Organization (ISO), esta norma especifica instrucciones de procedimientos recomendados y operaciones, lo que permite que una organización esté certificada profesionalmente.
Este marco ISO no define realmente el concepto de continuidad del negocio, ni tampoco el de resistencia, para el caso. En su lugar, define qué significa continuidad en el contexto propio de la organización. Según contiene su documento orientativo, "la organización debe identificar y seleccionar estrategias de continuidad del negocio en función de los resultados del análisis de impacto empresarial y la evaluación de riesgos. Las estrategias de continuidad del negocio deben constar de una o varias soluciones". La norma no señala una lista de cuáles pueden o deben ser esas soluciones.3
La Figura 11 es una representación de Microsoft de la implementación en varias fases de Azure en cumplimiento de la norma ISO 22301. Observe la inclusión de objetivos de tiempo de actividad de contrato de nivel de servicio (SLA). Para los clientes que eligen este nivel de resistencia, Azure replica los centros de datos virtuales dentro de sus zonas de disponibilidad local, pero aprovisiona réplicas independientes cuya ubicación geográfica esté separada por miles de kilómetros. No obstante, por motivos legales (especialmente para mantener el cumplimiento de las leyes de privacidad de la Unión Europea), esta redundancia separada por geolocalización suele estar acotada por "límites de residencia de datos", como Norteamérica o Europa.
![Figure 11: Azure Resiliency Framework, which protects active components on multiple levels, in accordance with ISO 22301. [Courtesy Microsoft]](../../cmu-cloud-admin/cmu-disaster-recovery-backup/media/fig9-11.jpg)
Figura 11: Marco de resistencia de Azure en el que se protegen los componentes activos en varios niveles según la norma ISO 22301. [Cortesía de Microsoft]
Aunque la norma ISO 22301 está asociada a la resistencia, y a menudo se describe como un conjunto de directrices de resistencia, los niveles de resistencia en los que Azure está probado solo se pueden aplicar a la plataforma de Azure, y no a los recursos de clientes hospedados en dicha plataforma. Sigue siendo responsabilidad del cliente administrar, mantener y mejorar sus procesos con frecuencia, incluido el modo en que sus recursos se replican en la nube de Azure y donde sea.
Google Container Engine
Hasta hace poco, el software se concebía como el estado de una máquina funcionalmente idéntico al hardware, si bien en el plano digital. Visto así, el software siempre se ha considerado como un componente relativamente estático en un sistema de información. Los protocolos de seguridad exigen que el software se actualice con regularidad, entendiendo "regularidad" por varias veces al año, cuando vayan estando disponibles actualizaciones y correcciones de errores.
Lo que la dinámica de la nube hizo factible, pero que muchos ingenieros de TI no previeron, fue la capacidad de implementar software de forma incremental, pero frecuente. La integración continua y la entrega continua (CI/CD) es un conjunto emergente de principios según los cuales la automatización permite el almacenamiento provisional frecuente (a menudo, a diario) de los cambios incrementales en el software, tanto en el lado servidor como cliente. Los usuarios de smartphones experimentan procesos de CI/CD con regularidad, ya que sus aplicaciones se actualizan como poco varias veces por semana en las tiendas de aplicaciones. Cada cambio que se materializa con CI/CD puede ser menor, pero el hecho de que los cambios menores puedan implementarse rápidamente sin dificultad ha traído un efecto secundario inesperado, si bien ventajoso: unos sistemas de información más resistentes.
Con los modelos de implementación de CI/CD, los clústeres de servidores totalmente redundantes se aprovisionan y mantienen (a menudo en la infraestructura de la nube pública) con el único objetivo de probar los componentes de software recién generados en busca de errores, tras lo cual se almacenan provisionalmente en un entorno de trabajo simulado para detectar posibles errores. De esta manera, los procesos de corrección tendrán lugar en un entorno seguro que no tendrá efecto directo alguno en los niveles de servicio orientados al cliente o al usuario hasta que se hayan aplicado, probado y aprobado correcciones para la implementación.
Google Container Engine (GKE, donde "K" corresponde a "Kubernetes") es el entorno de Google Cloud Platform para clientes que implementan aplicaciones y servicios basados en contenedor en lugar de aplicaciones basadas en máquinas virtuales. Una implementación puesta en marcha completamente con contenedores puede incluir microservicios, bases de datos separadas de las cargas de trabajo y diseñadas para funcionar de forma independiente ("conjuntos de datos con estado"), bibliotecas de código dependientes y sistemas operativos pequeños que se usan en caso de que el código de la aplicación debe emplear el propio sistema de archivos del contenedor. En la Figura 9.12 se ilustra una implementación de este tipo en el estilo que Google sugiere a sus clientes de GKE.
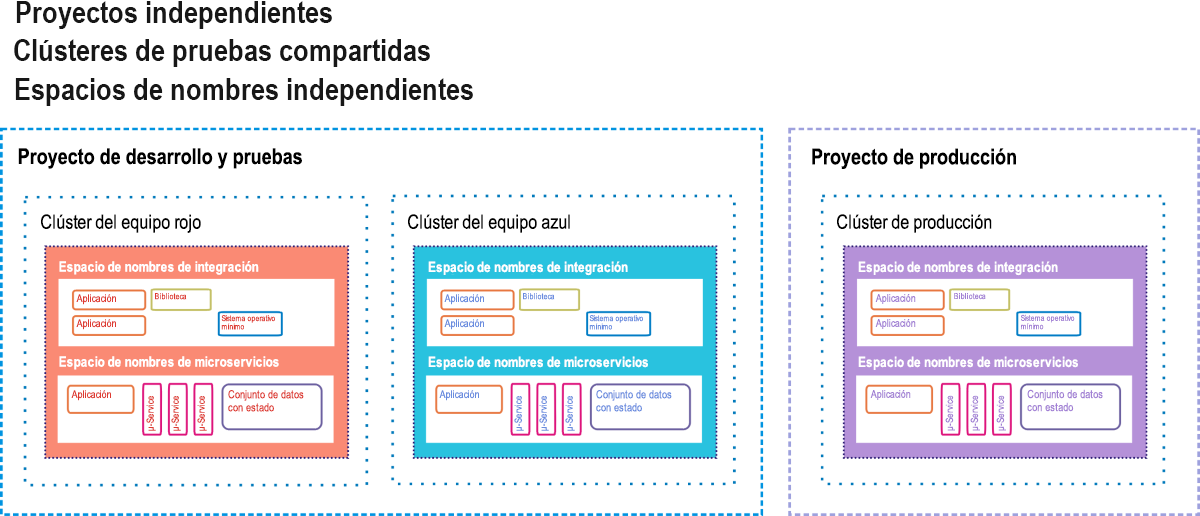
Figura 12: Opción de espera activa como entorno de ensayo de CI/CD de Google Container Engine
En GKE, un proyecto es similar a un centro de datos, ya que se considera que contiene todos los recursos que un centro de datos tendría normalmente, solo que en un formato virtual. Puede haber uno o varios clústeres de servidores asignados a un proyecto. Los componentes en contenedor existen en sus propios espacios de nombres, que son como sus universos particulares. Cada uno de ellos está conformado por todos los componentes direccionables a los que se permite el acceso a sus contenedores miembro, y cualquier elemento ajeno al espacio de nombres se debe direccionar mediante direcciones IP remotas. Los ingenieros de Google sugieren que las aplicaciones cliente/servidor a la vieja usanza (lo que los desarrolladores de contenedores denominan "monolitos") pueden coexistir con aplicaciones en contenedor, siempre que cada clase use su propio espacio de nombres para obtener seguridad, mientras comparten el mismo proyecto.
En este diagrama de implementación hay tres clústeres activos, cada uno de los cuales funciona con dos espacios de nombres: uno para el software antiguo y otro para el nuevo. Dos de estos clústeres están designados para pruebas: uno para las pruebas de desarrollo iniciales y otro para el almacenamiento provisional final. En una canalización de CI/CD, los contenedores de código nuevos se insertan en uno de los clústeres de prueba. En él, deben superar una tanda de pruebas automatizadas para demostrar que no contienen errores antes de transferirlos al almacenamiento provisional, donde les espera una segunda tanda de pruebas. Solo el código que supere las pruebas de almacenamiento provisional de segundo nivel se insertará en el clúster de producción activo que los clientes finales usen.
E incluso aquí habrá pruebas de errores. En un escenario de implementación A/B, el código nuevo coexiste con el anterior durante un tiempo determinado. Si el nuevo código no funciona según las especificaciones o presenta errores en el sistema, se puede retirar, lo que siempre nos dejará con el código anterior. Si el intervalo de vigilancia expira y el nuevo código funciona bien, el código anterior se retirará.
Este proceso es una forma sistemática y semiautomatizada de que los sistemas de información eviten la aparición de un mal funcionamiento que lleve a errores. No es una configuración de prueba ante desastres en sí, a menos que el propio clúster de producción se replique en un modo de espera activa. Evidentemente, este esquema de replicación consume una gran cantidad de recursos basados en la nube, pero posiblemente los costos derivados sigan siendo mucho más bajos que lo que una organización tendría que dedicar si no tuviera protección ante una interrupción del sistema.
Referencias
Sterbenz, James P.G., et al. "ResiliNets: Multilevel Resilient and Survivable Networking Initiative." https://resilinets.org/main_page.html.
Patterson, David, et al. "Recovery Oriented Computing: Motivation, Definition, Principles, and Examples" (Informática orientada a la recuperación: Motivación, definición, principios y ejemplos). Microsoft Research, marzo de 2002. https://www.microsoft.com/research/publication/recovery-oriented-computing-motivation-definition-principles-and-examples/.
ISO. "Security and resilience - Business continuity management systems - Requirements" (Seguridad y resistencia: Sistemas de administración de continuidad empresarial: Requisitos). https://dri.ca/docs/ISO_DIS_22301_(E).pdf.