Cette architecture de référence montre une architecture serverless basée sur des événements qui ingère un flux de données, traite les données et écrit les résultats dans une base de données back-end.
Architecture
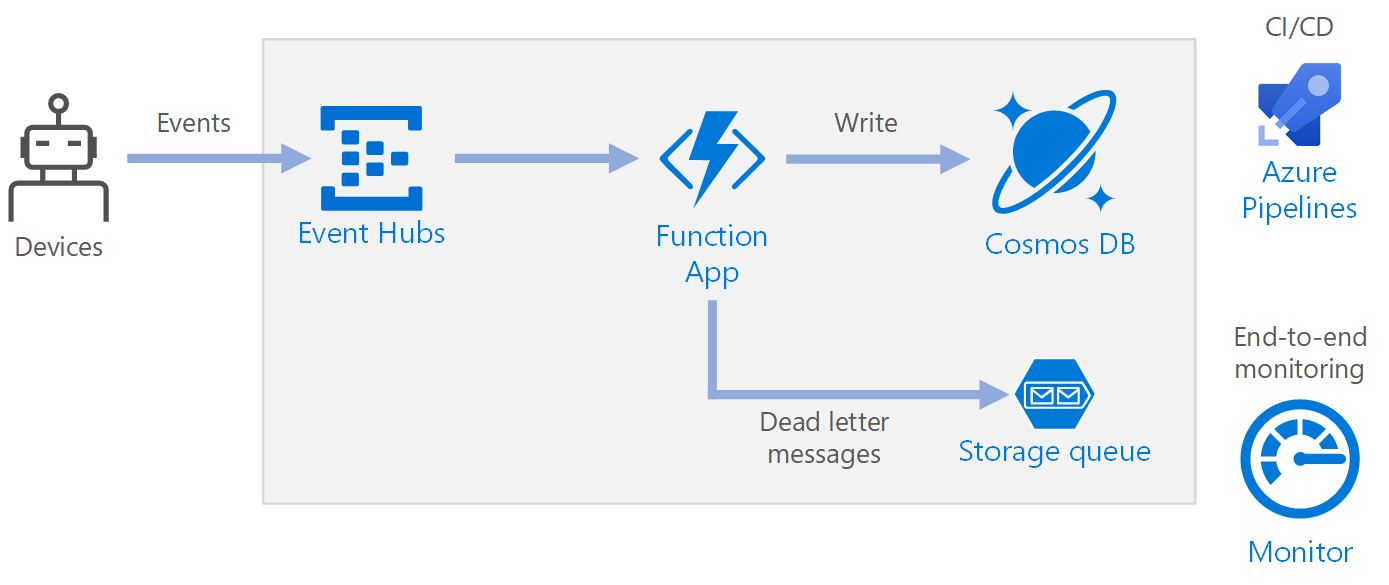
Workflow
- Les événements arrivent à Azure Event Hubs
- Une application de fonction est déclenchée pour gérer l’événement
- L’événement est stocké dans une base de données Azure Cosmos DB.
- Si l’application de fonction ne parvient pas à stocker l’événement, il est enregistré dans une file d’attente de stockage en vue d’un traitement ultérieur
Composants
Event Hubs ingère le flux de données. Event Hubs est conçu pour les scénarios de diffusion de données à débit élevé.
Notes
Pour les scénarios IoT (Internet des objets), nous recommandons Azure IoT Hub. IoT Hub a un point de terminaison intégré qui est compatible avec l’API Azure Event Hubs ; vous pouvez donc utiliser l’un ou l’autre service dans cette architecture sans aucune modification majeure dans le traitement back-end. Pour plus d’informations, consultez Connexion des appareils IoT à Azure : IoT Hub et Event Hubs.
Function App. Azure Functions est une solution de calcul serverless. Cette application utilise un modèle événementiel, dans lequel un morceau de code (une fonction) est invoqué par un déclencheur. Dans cette architecture, lorsque des événements arrivent dans Event Hubs, ils déclenchent une fonction qui traite les événements et écrit les résultats dans le stockage.
Function App ne convient pas pour le traitement des enregistrements individuels à partir d’Event Hubs. Pour les scénarios de traitement de flux de données plus complexes, pensez à Apache Spark avec Azure Databricks ou Azure Stream Analytics.
Azure Cosmos DB. Azure Cosmos DB est un service de base de données multimodèle qui est disponible en mode serverless et basé sur la consommation. Pour ce scénario, la fonction de traitement d’événements stocke les enregistrements JSON à l’aide d’Azure Cosmos DB for NoSQL.
Stockage de files d’attente. Stockage de files d’attente est utilisé pour les messages de lettres mortes. Si une erreur se produit lors du traitement d’un événement, la fonction stocke les données d’événement dans une file d’attente de lettres mortes pour les traiter plus tard. Pour plus d’informations, consultez la section Résilience plus loin dans cet article.
Azure Monitor. Monitor collecte les mesures de performances relatives aux services Azure déployés dans la solution. En les visualisant dans un tableau de bord, vous pouvez obtenir des informations sur l’intégrité de la solution.
Azure Pipelines. Pipelines est un service d'intégration continue (CI) et de livraison continue (CD) qui génère, teste et déploie l'application.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d’informations, consultez Microsoft Azure Well-Architected Framework.
Disponibilité
Le déploiement illustré ici se trouve dans une seule région Azure. Pour une approche plus résiliente à la récupération d’urgence, tirer parti des fonctionnalités de géo-distribution dans les différents services :
- Event Hubs. Créez deux espaces de noms Event Hubs, un espace de noms principal (actif) et un espace de noms secondaire (passif). Les messages sont automatiquement acheminés vers l’espace de noms actif, sauf si vous basculez vers l’espace de noms secondaire. Pour en savoir plus, voir Géorécupération d’urgence Azure Event Hubs.
- Function App. Déployez une deuxième application de fonction qui est en attente de lecture à partir de l’espace de noms Event Hubs secondaire. Cette fonction écrit dans un compte de stockage secondaire pour une file d’attente de lettres mortes.
- Azure Cosmos DB. Azure Cosmos DB prend en charge plusieurs régions d’écriture, ce qui permet des écritures dans toutes les régions que vous ajoutez à votre compte Azure Cosmos DB. Si vous n’activez pas multiwrite, vous pouvez toujours basculer vers la région d’écriture primaire. Les SDK client Azure Cosmos DB et les liaisons d’Azure Function gèrent automatiquement le basculement, vous n’avez pas besoin de mettre à jour les paramètres de configuration d’application.
- Stockage Azure. Utilisez le stockage RA-GRS pour la file d’attente de lettres mortes. Cette opération crée un réplica en lecture seule dans une autre région. Si la région primaire devient indisponible, vous pouvez lire les éléments actuellement présents dans la file d’attente. En outre, configurez un autre compte de stockage dans la région secondaire à laquelle la fonction peut écrire après un basculement.
Extensibilité
Event Hubs
La capacité de débit du service Event Hubs est mesurée par les unités de débit. Vous pouvez mettre automatiquement à l’échelle un Event Hub en activant l’augmentation automatique, qui ajuste automatiquement les unités de débit en fonction du trafic, jusqu’à la limite configurée.
Le déclencheur Event Hubs dans l’application de fonction effectue une mise à l’échelle en fonction du nombre de partitions dans le hub d’événements. Une instance de la fonction est assignée à chaque partition à la fois. Pour maximiser le débit, recevez les événements en un traitement, plutôt qu’un seul à la fois.
Azure Cosmos DB
Azure Cosmos DB est disponible sous deux modes de capacité :
- Serverless, pour les charges de travail avec un trafic intermittent ou imprévisible et un faible ratio de trafic moyen à pic.
- Débit provisionné pour les charges de travail avec un trafic soutenu nécessitant des performances prévisibles.
Pour garantir la scalabilité de votre charge de travail, il est important de choisir une clé de partition adaptée lorsque vous créez vos conteneurs Azure Cosmos DB. Voici certaines caractéristiques d’une bonne clé de partition :
- L’espace de valeur de clé est volumineux.
- Il y aura une répartition uniforme des lectures/écritures par valeur de clé, en évitant les clés sensibles.
- La quantité maximale de données stockées pour toute valeur de clé unique ne dépassera pas la taille maximale de la partition physique (20 Go).
- La clé de partition pour un document ne change pas. Vous ne pouvez pas mettre à jour la clé de partition sur un document existant.
Dans le scénario pour cette architecture de référence, la fonction stocke un seul document par appareil qui envoie des données. La fonction met continuellement à jour les documents avec le dernier état de l’appareil à l’aide d’une opération upsert. L’ID de l’appareil est une bonne clé de partition pour ce scénario, car les écritures seront réparties uniformément parmi les clés, et la taille de chaque partition sera strictement limitée étant donné qu’il existe un document unique pour chaque valeur de clé. Pour plus d'informations sur les clés de partition, consultez Partition et mise à l'échelle dans Azure Cosmos DB.
Résilience
Lorsque vous utilisez le déclencheur Event Hubs avec Functions, intercepter les exceptions dans votre boucle de traitement. Si une exception non prise en charge se produit, le runtime Functions ne retente pas les messages. Si un message ne peut pas être traité, placez-le dans une file d’attente de lettres mortes. Utilisez un processus hors-bande pour examiner les messages et de déterminer l’action corrective.
Le code suivant montre comment la fonction d’ingestion intercepte les exceptions et place les messages non traités dans une file d’attente de lettres mortes.
[FunctionName("RawTelemetryFunction")]
[StorageAccount("DeadLetterStorage")]
public static async Task RunAsync(
[EventHubTrigger("%EventHubName%", Connection = "EventHubConnection", ConsumerGroup ="%EventHubConsumerGroup%")]EventData[] messages,
[Queue("deadletterqueue")] IAsyncCollector<DeadLetterMessage> deadLetterMessages,
ILogger logger)
{
foreach (var message in messages)
{
DeviceState deviceState = null;
try
{
deviceState = telemetryProcessor.Deserialize(message.Body.Array, logger);
}
catch (Exception ex)
{
logger.LogError(ex, "Error deserializing message", message.SystemProperties.PartitionKey, message.SystemProperties.SequenceNumber);
await deadLetterMessages.AddAsync(new DeadLetterMessage { Issue = ex.Message, EventData = message });
}
try
{
await stateChangeProcessor.UpdateState(deviceState, logger);
}
catch (Exception ex)
{
logger.LogError(ex, "Error updating status document", deviceState);
await deadLetterMessages.AddAsync(new DeadLetterMessage { Issue = ex.Message, EventData = message, DeviceState = deviceState });
}
}
}
Notez que la fonction utilise la liaison de sortie de Stockage File d'attente pour placer des éléments dans la file d'attente.
Le code enregistre également les exceptions dans Application Insights. Vous pouvez utiliser le numéro de séquence et de clé de partition pour mettre en corrélation des messages de lettres mortes avec les exceptions dans les journaux.
Les messages dans la file d’attente de lettres mortes doivent fournir suffisamment d’informations pour que vous puissiez comprendre le contexte de l’erreur. Dans cet exemple, la DeadLetterMessage classe contient le message d’exception, les données d’événement d’origine et le message d’événement désérialisé (si disponible).
public class DeadLetterMessage
{
public string Issue { get; set; }
public EventData EventData { get; set; }
public DeviceState DeviceState { get; set; }
}
Utilisez Azure Monitor pour surveiller le concentrateur d'événements. Si vous voyez qu’il y a des entrées, mais aucune sortie, cela signifie que les messages ne sont pas traités. Dans ce cas, accédez à Log Analytics et recherchez les exceptions ou d'autres erreurs.
DevOps
Utilisez l’infrastructure en tant que code (IaC) dans la mesure du possible. IaC gère les ressources d’infrastructure, d’application et de stockage en utilisant une approche déclarative comme Azure Resource Manager. Cela permet d’automatiser le déploiement à l’aide de DevOps en tant que solution d’intégration continue et de livraison continue (CI/CD). Les modèles doivent présenter des versions et être inclus dans le pipeline de mise en version.
Lorsque vous créez des modèles, regroupez les ressources pour organiser et isoler ces ressources par charge de travail. Visualisez la charge de travail en tant qu’application serverless unique ou réseau virtuel. L’isolation des charges de travail a pour but d’associer les ressources à une équipe donnée, afin que l’équipe DevOps puisse gérer indépendamment tous les aspects de ces ressources et effectuer une tâche CI/CD.
Cette architecture comprend les étapes permettant de configurer Drone Status Function App à l’aide d’Azure Pipelines avec des emplacements YAML et Azure Functions.
Les services que vous déployez doivent être surveillés. Envisagez d’utiliser Application Insights pour permettre aux développeurs de surveiller les performances et de détecter les problèmes.
Pour plus d’informations, consultez la Liste de contrôle DevOps.
Récupération d'urgence
Le déploiement illustré ici se trouve dans une seule région Azure. Pour une approche plus résiliente à la récupération d’urgence, tirer parti des fonctionnalités de géo-distribution dans les différents services :
Event Hubs. Créez deux espaces de noms Event Hubs, un espace de noms principal (actif) et un espace de noms secondaire (passif). Les messages sont automatiquement acheminés vers l’espace de noms actif, sauf si vous basculez vers l’espace de noms secondaire. Pour en savoir plus, voir Géorécupération d’urgence Azure Event Hubs.
Function App. Déployez une deuxième application de fonction qui est en attente de lecture à partir de l’espace de noms Event Hubs secondaire. Cette fonction écrit dans un compte de stockage secondaire pour la file d’attente de lettres mortes.
Azure Cosmos DB. Azure Cosmos DB prend en charge plusieurs régions d’écriture, ce qui permet des écritures dans toutes les régions que vous ajoutez à votre compte Azure Cosmos DB. Si vous n’activez pas multiwrite, vous pouvez toujours basculer vers la région d’écriture primaire. Les SDK client Azure Cosmos DB et les liaisons d’Azure Function gèrent automatiquement le basculement, vous n’avez pas besoin de mettre à jour les paramètres de configuration d’application.
Stockage Azure. Utilisez le stockage RA-GRS pour la file d’attente de lettres mortes. Cette opération crée un réplica en lecture seule dans une autre région. Si la région primaire devient indisponible, vous pouvez lire les éléments actuellement présents dans la file d’attente. En outre, configurez un autre compte de stockage dans la région secondaire à laquelle la fonction peut écrire après un basculement.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Utilisez la Calculatrice de prix Azure pour estimer les coûts. Voici d’autres considérations sur Azure Functions et Azure Cosmos DB.
Azure Functions
Azure Functions prend en charge deux modèles d’hébergement :
- Plan de consommation. La puissance de calcul est allouée automatiquement lors de l'exécution de votre code.
- Plan App Service. Un ensemble de machines virtuelles est alloué pour votre code. Le plan App Service définit la taille des machines virtuelles et leur nombre.
Dans cette architecture, chaque événement qui arrive sur Event Hubs déclenche une fonction qui le traite. Du point de vue du coût, il est recommandé d’utiliser le plan de consommation , car vous payez uniquement pour les ressources de calcul que vous utilisez.
Azure Cosmos DB
Avec Azure Cosmos DB, vous payez pour les opérations que vous effectuez sur la base de données et pour le stockage utilisé par vos données.
- Opérations de base de données. La façon dont vous sont facturées vos opérations de base de données dépend du type de compte Azure Cosmos DB que vous utilisez.
- En mode serverless, vous n’avez pas besoin de provisionner un débit lors de la création de ressources dans votre compte Azure Cosmos DB. À la fin de votre période de facturation, vous recevez une facture pour la quantité d’unités de requête consommées par vos opérations de base de données.
- En mode Débit provisionné, vous spécifiez le débit dont vous avez besoin en unités de requête par seconde (RU/s). Vous recevez une facture à l’heure pour le débit provisionné maximal utilisé au cours d’une heure donnée. Remarque : Comme le modèle de débit provisionné consacre des ressources à votre conteneur ou à votre base de données, le débit provisionné vous est facturé même si vous n’exécutez aucune charge de travail.
- Stockage. Un tarif fixe vous est facturé pour la quantité totale de stockage (exprimée en Go) que vos données et index ont utilisée pendant une heure donnée.
Dans cette architecture de référence, la fonction stocke un seul document par appareil qui envoie des données. La fonction met continuellement à jour les documents avec le dernier état de l'appareil, en utilisant une opération upsert, ce qui est rentable en termes de stockage consommé. Pour plus d’informations, consultez le modèle de tarification Azure Cosmos DB.
Utilisez la calculatrice de capacité Azure Cosmos DB pour obtenir une estimation rapide du coût de la charge de travail.
Déployer ce scénario
 Une implémentation de référence de cette architecture est disponible sur GitHub.
Une implémentation de référence de cette architecture est disponible sur GitHub.
Étapes suivantes
- Présentation d’Azure Functions
- Bienvenue dans Azure Cosmos DB
- Qu’est-ce que Stockage File d’attente Azure ?
- Vue d’ensemble d’Azure Monitor
- Documentation Azure Pipelines
Ressources associées
- Présentation détaillée du code : Application serverless avec Fonctions
- Supervision du traitement d’événements serverless
- Division et filtrage dans le traitement des événements serverless avec Event Hubs
- Scénario de liaison privée dans le traitement de flux d’événements
- Azure Kubernetes dans le traitement de flux d’événements