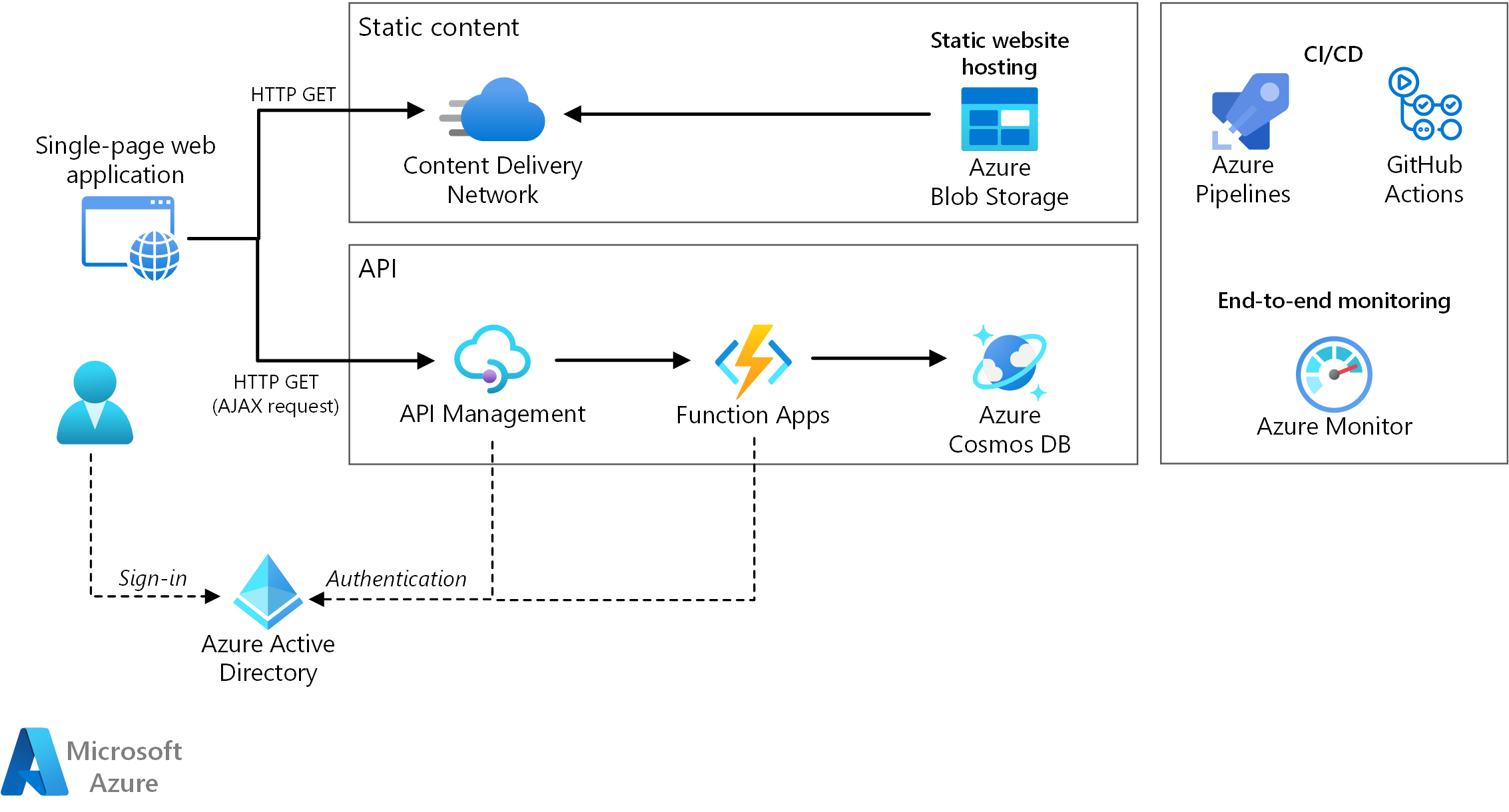
Cette architecture de référence montre une application web serverless. L’application gère le contenu statique à partir de Stockage Blob Azure et implémente une API à l’aide d’Azure Functions. L’API lit les données à partir de Azure Cosmos DB et renvoie les résultats à l’application web.
 Deux implémentations de référence de cette architecture sont disponibles sur GitHub : Drone Delivery App (ARM Azure Pipelines) et To Do App (Bicep GitHub Actions).
Deux implémentations de référence de cette architecture sont disponibles sur GitHub : Drone Delivery App (ARM Azure Pipelines) et To Do App (Bicep GitHub Actions).
Architecture
Téléchargez un fichier Visio de cette architecture.
Le terme « serverless » a deux significations distinctes mais liées :
- Serveur principal en tant que service (BaaS). Les services cloud principaux, tels que les bases de données et de stockage, fournissent des API qui permettent aux applications clientes de se connecter directement à ces services.
- Fonctions en tant que service (FaaS). Dans ce modèle, une « fonction » est un morceau de code qui est déployé sur le cloud et s’exécute au sein d’un environnement d’hébergement qui résume complètement les serveurs qui exécutent le code.
Les deux définitions ont en commun l’idée que les développeurs et le personnel DevOps n’ont pas besoin de déployer, configurer ou gérer des serveurs. Cette architecture de référence se concentre sur FaaS en utilisant Azure Functions, bien que la diffusion de contenu web à partir de Stockage Blob Azure puisse être un exemple de BaaS. Certaines caractéristiques importantes de FaaS sont :
- Les ressources de calcul sont allouées de façon dynamique en fonction des besoins de la plateforme.
- Facturation basée sur la consommation : vous êtes facturé uniquement pour les ressources de calcul qui ont été utilisées pour exécuter votre code.
- Les ressources de calcul évoluent à la demande en fonction du trafic, sans que le développeur n’ait à effectuer de configuration.
Les fonctions sont exécutées lorsqu’un déclencheur externe se produit, par exemple une requête HTTP ou un message arrive sur une file d’attente. Cela crée un style d'architecture basée sur les événements qui est naturel pour les architectures serverless. Pour coordonner le travail entre les composants de l’architecture, envisagez d’utiliser des répartiteurs de messages ou des modèles pub/sub. Pour vous aider à faire votre choix parmi les technologies de messagerie dans Azure, consultez Effectuer un choix parmi les services Azure qui envoient des messages.
Composants
L’architecture est constituée des composants suivants :
Stockage d'objets blob. Le contenu web statique, tel que les fichiers HTML, CSS et JavaScript, est stocké dans le Stockage Blob Azure, et il est distribué aux clients à l’aide de l’hébergement de site web statique. Toutes les interactions dynamiques s'effectuent par le biais du code JavaScript en passant des appels aux API back-end. Il n’existe aucun code côté serveur pour restituer la page web. Les supports d’hébergement de site web statique indexent les documents et les pages d’erreurs 404 personnalisées.
CDN. Utilisez Azure Content Delivery Network (CDN) pour mettre en cache le contenu afin de réduire la latence et d'accélérer la diffusion du contenu, tout en fournissant un point de terminaison HTTPS.
Applications de fonction. Azure Functions est une solution de calcul serverless. Cette application utilise un modèle basé sur les événements, dans lequel un morceau de code (une « fonction ») est invoqué par un déclencheur. Dans cette architecture, la fonction est appelée lorsqu’un client effectue une requête HTTP. La requête est toujours acheminée via une passerelle d’API, décrite ci-dessous.
Gestion des API. La Gestion des API Azure fournit une passerelle API qui se trouve devant la fonction HTTP. Vous pouvez utiliser Gestion des API pour publier et gérer les API utilisées par les applications clientes. Utiliser une passerelle permet de découpler l’application frontale à partir des API du serveur principal. Par exemple, Gestion des API peut réécrire des URL, transformer des requêtes avant qu'elles atteignent le back end, définir les en-têtes de requête ou de réponse, et ainsi de suite.
Gestion des API peut également servir à implémenter des problèmes transversaux tels que :
- Appliquer des quotas d’utilisation et des limites de débit
- Valider des jetons OAuth pour l’authentification
- Activer des requêtes de Cross-Origin (CORS)
- Mise en cache des réponses
- Suivi et enregistrement des requêtes
Si vous n'avez pas besoin de toutes les fonctionnalités fournies par Gestion des API, une autre option consiste à utiliser Functions Proxies. Cette fonctionnalité d’Azure Functions vous permet de définir une surface d’API unique pour plusieurs applications de fonction en créant des itinéraires pour les fonctions du serveur principal. Function Proxies peut également effectuer des transformations limitées sur la requête HTTP et la réponse. Toutefois, cette fonctionnalité ne fournit pas les capacités étendues basées sur la stratégie que l’on retrouve dans Gestion des API.
Azure Cosmos DB. Azure Cosmos DB est un service de base de données multimodèle. Pour ce scénario, l’application de fonction récupère les documents à partir d’Azure Cosmos DB en réponse aux requêtes HTTP GET provenant du client.
Microsoft Entra ID (Microsoft Entra ID). Les utilisateurs se connectent à l’application web à l’aide de leurs informations d’identification Microsoft Entra ID . Microsoft Entra ID retourne un jeton d’accès pour l’API, que l’application web utilise pour authentifier les demandes d’API (voir Authentification).
Azure Monitor. Azure Monitor collecte les mesures de performances sur les services Azure déployés dans la solution. En les visualisant dans un tableau de bord, vous pouvez obtenir des informations sur l’intégrité de la solution. Les journaux des applications sont également collectés.
Azure Pipelines. Azure Pipelines est un service d'intégration continue (CI) et de livraison continue (CD) qui génère, teste et déploie l’application.
GitHub Actions. Un workflow est un processus automatisé de CI/CD que vous configurez dans votre dépôt GitHub. Vous pouvez générer, tester, empaqueter, publier ou déployer n’importe quel projet sur GitHub avec un workflow.
Détails du scénario
Cas d’usage potentiels
Cette solution de livraison par drone est idéale pour les secteurs de l’aéronautique, de l’aviation, de l’aérospatiale et de la robotique.
Recommandations
Plans de l’Application de fonction
Azure Functions prend en charge deux modèles d’hébergement. Avec le plan Consommation, la puissance de calcul est allouée automatiquement lors de l’exécution de votre code. Avec le plan App Service, un ensemble de machines virtuelles (VM) sont allouées pour votre code. Le plan App Service définit la taille des machines virtuelles et leur nombre.
Notez que le plan App Service n’est pas exactement serverless, selon la définition donnée ci-dessus. Le modèle de programmation est cependant identique. Le même code de fonction peut s’exécuter à la fois dans un plan de consommation et dans un plan App Service.
Voici quelques facteurs à prendre en compte lorsque vous choisissez le type de plan à utiliser :
- Démarrage à froid. Avec le plan de consommation, une fonction qui n’a pas été appelée récemment entraîne une latence supplémentaire lors de sa prochaine exécution. Cette latence supplémentaire est due à l’allocation et à la préparation de l’environnement runtime. Elle est généralement de l’ordre de quelques secondes, mais cela dépend de plusieurs facteurs, notamment du nombre de dépendances qui doivent être chargées. Pour plus d'informations, consultez Comprendre le démarrage à froid serverless. En général, le démarrage à froid est un critère plus important pour les charges de travail interactives (déclencheurs HTTP) que pour les charges de travail asynchrones pilotées par messages (déclencheurs file d’attente ou Event Hubs), car la latence supplémentaire est directement observée par les utilisateurs.
- Délai d’expiration. Dans le plan de consommation, le délai d'attente de l'exécution d'une fonction arrive à expiration après une période configurable (10 minutes maximum).
- Isolement du réseau virtuel. L'utilisation d'un plan App Service permet aux fonctions de s'exécuter à l'intérieur d'un environnement ASE (App Service Environment), qui est un environnement d'hébergement dédié et isolé.
- Modèle de tarification. Le plan de consommation est facturé en fonction du nombre d’exécutions et de la consommation des ressources (mémoire x temps d’exécution). Le plan App Service est facturé au taux horaire basé sur l’instance de machine virtuelle SKU. Souvent, le plan de consommation peut être moins cher qu’un plan App Service, car vous payez uniquement pour les ressources de calcul que vous utilisez. Cela est particulièrement vrai si votre trafic est sujet à des hauts et des bas. Toutefois, si une application rencontre des constantes de débit élevées, un plan App Service peut coûter moins cher que le plan de consommation.
- Mise à l’échelle. Le gros avantage du modèle de consommation est qu’il s’adapte de façon dynamique, selon le trafic entrant. Cette mise à l’échelle se produit rapidement, mais il existe toujours une période de démarrage. Pour certaines charges de travail, vous pouvez délibérément fournir un excédent de budget pour les machines virtuelles, afin de gérer les pics de trafic sans aucune période de démarrage. Dans ce cas, envisagez un plan App Service.
Limites de l’Application de fonction
Une application de fonction héberge l’exécution d’une ou plusieurs fonctions. Vous pouvez utiliser une application de fonction pour regrouper plusieurs fonctions comme une unité logique. Au sein d’une application de fonction, les fonctions partagent les mêmes paramètres d’application, hébergeant le plan et le cycle de vie de déploiement. Chaque application de fonction possède son propre nom d’hôte.
Utilisez des applications de fonction pour grouper des fonctions qui partagent le même cycle de vie et les mêmes paramètres. Les fonctions qui ne partagent pas le même cycle de vie doivent être hébergées dans les applications de fonction différente.
Envisagez une approche de microservices, où chaque application de fonction représente un microservice, qui se compose éventuellement de plusieurs fonctions connexes. Dans une architecture de microservices, le couplage entre les services doit être souple et leur cohésion fonctionnelle élevée. Couplés de façon souple signifie que vous pouvez changer un service sans avoir à mettre à jour d’autres services au même moment. Cohésif signifie qu’un service a un usage unique et bien défini. Pour plus d’informations sur ces notions, consultez Conception de microservices : Analyse de domaine.
Liaisons de fonction
Utilisez des liaisons Functions lorsque cela est possible. Les liaisons fournissent une méthode déclarative pour connecter votre code aux données et l’intégrer à d’autres services Azure. Une liaison d’entrée remplit un paramètre d’entrée à partir de la source de données externe. Une liaison de sortie envoie la valeur de retour de la fonction à un récepteur de données, tel qu’une file d’attente ou une base de données.
Par exemple, la fonction GetStatus de l'implémentation de référence utilise la liaison d'entrée Azure Cosmos DB. Cette liaison est configurée pour rechercher un document dans Azure Cosmos DB, à l’aide des paramètres de requête extraits de la chaîne de requête dans la requête HTTP. Si le document est trouvé, il est passé à la fonction en tant que paramètre.
[FunctionName("GetStatusFunction")]
public static Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", Route = null)] HttpRequest req,
[CosmosDB(
databaseName: "%COSMOSDB_DATABASE_NAME%",
collectionName: "%COSMOSDB_DATABASE_COL%",
ConnectionStringSetting = "COSMOSDB_CONNECTION_STRING",
Id = "{Query.deviceId}",
PartitionKey = "{Query.deviceId}")] dynamic deviceStatus,
ILogger log)
{
...
}
En utilisant des liaisons, vous n’avez pas besoin d’écrire un code qui communique directement avec le service, ce qui simplifie le code de fonction et résume les détails de la source de données ou du récepteur. Toutefois, dans certains cas, vous aurez peut-être besoin d’une logique plus complexe que celle fournie par la liaison. Dans ce cas, utilisez directement le client Azure SDK.
Considérations
Ces considérations implémentent les piliers d’Azure Well-Architected Framework qui est un ensemble de principes directeurs qui permettent d’améliorer la qualité d’une charge de travail. Pour plus d’informations, consultez Microsoft Azure Well-Architected Framework.
Extensibilité
Fonctions. Pour le plan de consommation, le déclencheur HTTP met à l’échelle en fonction du trafic. Il existe une limite au nombre d’instances de fonction simultanées, mais chaque instance peut traiter plusieurs requêtes à la fois. Pour un plan App Service, le déclencheur HTTP met à l’échelle en fonction du nombre d’instances de machine virtuelle, qui peut être une valeur fixe ou une mise à l’échelle automatique basée sur un ensemble de règles de mise à l’échelle automatique. Pour plus d'informations, consultez Mise à l'échelle et hébergement dans Azure Functions.
Azure Cosmos DB. La capacité de débit pour Azure Cosmos DB est mesurée en unités de requête (RU). Un débit de 1 RU correspond au besoin d’un débit de la requête GET d’un document de 1 Ko. Pour mettre à l'échelle un conteneur Azure Cosmos DB au-delà de 10 000 RU, vous devez spécifier une clé de partition au moment de la création du conteneur, puis inclure la clé de partition dans chaque document que vous créez. Pour plus d'informations sur les clés de partition, consultez Partition et mise à l'échelle dans Azure Cosmos DB.
Gestion des API. Gestion des API peut effectuer un scale-out et prend en charge la mise à l’échelle basée sur une règle. Le processus de mise à l'échelle prend au moins 20 minutes. Si votre trafic est en rafale, vous devez configurer pour la rafale de trafic maximale que vous attendez. Toutefois, la mise à échelle automatique est utile pour la gestion des variations horaires ou quotidienne du trafic. Pour en savoir plus, consultez Mise à l'échelle automatique d'une instance de Gestion des API Azure.
Récupération d'urgence
Le déploiement illustré ici se trouve dans une seule région Azure. Pour une approche plus résistante à la récupération d’urgence, tirer parti des fonctionnalités de géo-distribution dans les différents services :
Gestion des API prend en charge le déploiement sur plusieurs régions, ce qui peut être utilisé pour ne distribuer qu’une seule instance de gestion des API sur le nombre de régions Azure. Pour en savoir plus, découvrez comment déployer une instance de service Gestion des API Azure dans plusieurs régions Azure.
Utilisez Traffic Manager pour diriger les requêtes HTTP vers la région primaire. Si l’application de fonction qui s’exécute dans cette région n’est plus disponible, Traffic Manager peut basculer vers une région secondaire.
Azure Cosmos DB prend en charge plusieurs régions d’écriture, ce qui permet des écritures dans toutes les régions que vous ajoutez à votre compte Azure Cosmos DB. Si vous n’activez pas multiwrite, vous pouvez toujours basculer vers la région d’écriture primaire. Les SDK client Azure Cosmos DB et les liaisons d’Azure Function gèrent automatiquement le basculement, vous n’avez pas besoin de mettre à jour les paramètres de configuration d’application.
Sécurité
La sécurité fournit des garanties contre les attaques délibérées, et contre l’utilisation abusive de vos données et systèmes importants. Pour plus d’informations, consultez Vue d’ensemble du pilier Sécurité.
Authentification
L’API GetStatus dans l’implémentation de référence utilise Microsoft Entra ID pour authentifier les demandes. Microsoft Entra ID prend en charge le protocole OpenID Connect, qui est un protocole d’authentification basé sur le protocole OAuth 2.
Dans cette architecture, l’application cliente est une application monopage (SPA) qui s’exécute dans le navigateur. Ce type d’application cliente ne peut pas suivre une clé secrète client ou un code d’autorisation masqué, donc le flux d’octroi implicite est approprié. (Consultez Quel flux OAuth 2.0 dois-je utiliser ?). Voici la séquence générale :
- L’utilisateur clique sur le lien « Se connecter » dans l’application web.
- Le navigateur est redirigé vers la page de connexion Microsoft Entra.
- L’utilisateur se connecte.
- Microsoft Entra ID redirige vers l’application cliente, y compris un jeton d’accès dans le fragment d’URL.
- Lorsque l’application web appelle l’API, elle ajoute le jeton d’accès dans l’en-tête d’authentification. L’ID de l’application est envoyé comme revendication d’audience (« aud ») dans le jeton d’accès.
- L'API back-end valide le jeton d'accès.
Pour configurer l’authentification :
Inscrivez une application dans votre locataire Microsoft Entra. Cela génère un ID d’application, que le client ajoute à l’URL de connexion.
Activez l’authentification Microsoft Entra dans l’application de fonction. Pour plus d’informations, consultez la page Authentification et autorisation dans Azure App Service.
Ajoutez la stratégie validate-jwt à Gestion des API pour autoriser la requête au préalable en validant le jeton d'accès.
Pour plus d'informations, consultez le fichier readme de GitHub.
Il est recommandé de créer des inscriptions d’applications distinctes dans Microsoft Entra ID pour l’application cliente et l’API principale. Donnez à l’application cliente l’autorisation d’appeler l’API. Cette approche permet de définir plusieurs API et clients et de contrôler les autorisations pour chacun.
Au sein d'une API, utilisez les étendues pour offrir aux applications un contrôle précis sur les autorisations requises auprès d'un utilisateur. Par exemple, une API peut présenter des étendues Read et Write, et une application cliente spécifique peut demander à l’utilisateur d’autoriser uniquement les autorisations Read.
Autorisation
Dans de nombreuses applications, l'API back-end doit vérifier si un utilisateur est autorisé à effectuer une action donnée. Il est recommandé d’utiliser l’autorisation basée sur les revendications, où les informations sur l’utilisateur sont transmises par le fournisseur d’identité (dans ce cas, Microsoft Entra ID) et utilisées pour prendre des décisions d’autorisation. Par exemple, lorsque vous inscrivez une application dans Microsoft Entra ID, vous pouvez définir un ensemble de rôles d’application. Lorsqu’un utilisateur se connecte à l’application, Microsoft Entra ID inclut une revendication roles pour chaque rôle accordé par l’utilisateur, y compris les rôles hérités par le biais de l’appartenance au groupe.
Le jeton d’ID retourné par Microsoft Entra ID au client contient certaines des revendications de l’utilisateur. Dans l'application de fonction, ces revendications sont disponibles dans l'en-tête X-MS-CLIENT-PRINCIPAL de la requête. Il est cependant plus simple de lire ces informations à partir des données de liaison. Pour d’autres revendications, utilisez Microsoft Graph pour interroger Microsoft Entra ID. (L'utilisateur doit consentir à cette action au moment de la connexion).
Pour plus d'informations, consultez Utilisation d'identités de clients.
CORS
Dans cette architecture de référence, l’application web et l’API ne partagent pas la même origine. Cela signifie que lorsque l’application appelle l’API, il s’agit d’une requête cross-origin. La sécurité des navigateurs empêche une page web d’adresser des demandes AJAX à un autre domaine. Cette restriction est appelée la stratégie de même origine et empêche un site malveillant de lire des données sensibles à partir d’un autre site. Pour activer une requête cross-origin, ajoutez une stratégie de partage de ressources cross-origin (CORS) à la passerelle de Gestion des API :
<cors allow-credentials="true">
<allowed-origins>
<origin>[Website URL]</origin>
</allowed-origins>
<allowed-methods>
<method>GET</method>
</allowed-methods>
<allowed-headers>
<header>*</header>
</allowed-headers>
</cors>
Dans cet exemple, l’attribut des informations d’identification est true. Cela autorise le navigateur à envoyer des informations d’identification (y compris des cookies) avec la requête. Sinon, par défaut le navigateur n’envoie pas d’informations d’identification avec une requête de cross-origin.
Notes
Soyez très prudent avec la configuration d’informations d’identification à true, car cela signifie qu’un site web peut envoyer des informations d’identification de l’utilisateur à votre API au nom de l’utilisateur, sans que l’utilisateur le sache. Vous devez faire confiance à l’origine autorisée.
Appliquer le protocole HTTPS
Pour une sécurité maximale, exiger HTTPS tout au long du pipeline de requête :
CDN. Azure CDN prend en charge HTTPS dans le
*.azureedge.netsous-domaine par défaut. Pour activer HTTPS dans le CDN pour les noms de domaine personnalisé, consultez le Tutoriel : Configurer HTTPS sur un domaine personnalisé Azure CDN.Hébergement de site web statique. Activer l'option « Transfert sécurisé requis » sur le compte de stockage. Lorsque cette option est activée, le compte de stockage autorise uniquement les demandes provenant de connexions HTTPS sécurisées.
Gestion des API. Configurez les API pour n’utiliser que le protocole HTTPS. Vous pouvez le configurer dans le portail Azure ou via un modèle Resource Manager :
{ "apiVersion": "2018-01-01", "type": "apis", "name": "dronedeliveryapi", "dependsOn": [ "[concat('Microsoft.ApiManagement/service/', variables('apiManagementServiceName'))]" ], "properties": { "displayName": "Drone Delivery API", "description": "Drone Delivery API", "path": "api", "protocols": [ "HTTPS" ] }, ... }Azure Functions. Activer le paramètre « HTTPS uniquement ».
Verrouiller l’application de fonction
Tous les appels à la fonction doivent passer par la passerelle d’API. Vous pouvez y parvenir de la façon suivante :
Configurez l’application de fonction pour demander une clé de fonction. La passerelle de gestion des API inclut la clé de fonction lors de l’appel à l’application de fonction. Cela empêche les clients d’appeler la fonction directement, en contournant la passerelle.
La passerelle de Gestion des API possède uneadresse IP statique. Restreindre Azure Function pour autoriser uniquement les appels de cette adresse IP statique. Pour plus d’informations, consultez Restrictions d’adresse IP statique avec Azure App Service. (Cette fonctionnalité est disponible uniquement pour les services de niveau Standard).
Protection des secrets d’application
Ne stockez pas les secrets de l’application, tels que les informations d’identification de la base de données dans vos fichiers de code ou de configuration. Utilisez plutôt les paramètres de l’application, qui sont stockés et chiffrés dans Azure. Pour plus d'informations, consultez Sécurité dans Azure App Service et Azure Functions.
Ou bien, vous pouvez stocker des secrets d’application dans Key Vault. Cela vous permet de centraliser le stockage des secrets, contrôler leur distribution et surveiller comment et quand les secrets sont ouverts. Pour plus d'informations, consultez Configurer une application web Azure pour lire un secret dans Key Vault. Toutefois, notez que les liaisons et déclencheurs de Functions chargent leurs paramètres de configuration à partir des paramètres de l’application. Il n’existe aucun moyen intégré pour configurer les déclencheurs et liaisons pour utiliser des secrets de coffre de clés.
DevOps
Déploiement frontal
La partie frontale de cette architecture de référence est une application d'une seule page dans laquelle JavaScript accède aux API back-end serverless et où le contenu statique offre une expérience utilisateur rapide. Voici quelques points importants à prendre en compte pour ce type d'application :
- Déployez l'application de manière uniforme auprès des utilisateurs d'une vaste zone géographique avec un CDN prêt pour le monde entier, le contenu statique étant hébergé dans le cloud. Cela évite d'avoir recours à un serveur web dédié. Pour commencer, lisez Intégrer un compte de stockage Azure à Azure CDN. Sécurisez votre application avec HTTPS. Lisez Meilleures pratiques en matière d'utilisation des réseaux de distribution de contenu pour accéder à des recommandations supplémentaires.
- Utilisez un service de CI/CD rapide et fiable comme Azure Pipelines ou GitHub Actions pour générer et déployer automatiquement chaque changement de source. La source doit résider dans un système de gestion de version en ligne. Pour plus d’informations sur Azure Pipelines, consultez Créer votre premier pipeline. Pour en savoir plus sur GitHub Actions pour Azure, consultez Déployer des applications dans Azure.
- Compressez les fichiers de votre site web pour réduire la consommation de bande passante sur le CDN et améliorer les performances. Azure CDN permet la compression à la volée sur les serveurs de périphérie. Le pipeline de déploiement de cette architecture de référence compresse également les fichiers avant de les déployer dans Stockage Blob. Cela réduit les besoins en stockage et vous donne plus de liberté pour choisir les outils de compression, quelles que soient les limitations du CDN.
- Le CDN doit pouvoir purger son cache pour veiller à ce que tous les utilisateurs reçoivent le contenu le plus récent. Une purge du cache est requise si les processus de génération et de déploiement ne sont pas atomiques, par exemple, s'ils remplacent d'anciens fichiers par des fichiers nouvellement créés dans le même dossier d'origine.
- Une stratégie de cache différente, telle que le contrôle de version à l'aide de répertoires, peut ne pas nécessiter de purge par le CDN. Le pipeline de build de cette application frontale crée un nouveau répertoire pour chaque nouvelle version. Cette version est téléchargée en tant qu'unité atomique dans Stockage Blob. Azure CDN ne pointe vers cette nouvelle version qu'à l'issue d'un déploiement.
- Augmentez la TTL du cache en mettant en cache les fichiers de ressources pour une durée plus longue, couvrant plusieurs mois. Pour veiller à ce que les fichiers mis en cache soient mis à jour lorsqu'ils changent, prenez les empreintes digitales des noms de fichiers lors de leur reconstruction. Cette application frontale prend les empreintes digitales de tous les fichiers, à l'exception des fichiers publics comme index.html. Comme le fichier index.html est fréquemment mis à jour, il reflète les noms de fichiers modifiés, ce qui entraîne une actualisation du cache. Pour plus d'informations, consultez Gérer l'expiration du contenu web dans Azure CDN.
Déploiement back-end
Pour déployer l'application de fonction, nous vous recommandons d'utiliser les fichiers de package (« Exécuter à partir du package »). Avec cette approche, vous chargez un fichier zip vers un conteneur Stockage Blob, alors que le runtime Functions monte le fichier zip en tant que système de fichiers en lecture seule. Il s’agit d’une opération atomique. Elle réduit le risque qu’un déploiement ayant échoué laisse l’application dans un état incohérent. Cette approche peut également améliorer les temps de démarrage à froid, en particulier pour les applications Node.js, car tous les fichiers sont échangés en même temps.
Contrôle de version d’API
Une API est un contrat entre un service et des clients. Dans cette architecture, le contrat d’API est défini au niveau de la couche Gestion des API. Gestion des API prend en charge deux concepts de contrôle de version distincts, mais complémentaires :
Les versions offrent aux consommateurs d’API la possibilité de choisir une version d’API en fonction de leurs besoins, par exemple v1 ou v2.
Les révisions permettent aux administrateurs d’API d’apporter des modifications mineures dans une API et de déployer ces modifications, ainsi que d’un journal des modifications pour informer les consommateurs de l’API des modifications.
Si vous modifiez radicalement une API, publiez une nouvelle version dans Gestion des API. Déployez la nouvelle version côte à côte avec la version d’origine, dans une application de fonction distincte. Cela vous permet de migrer des clients existants vers la nouvelle API sans interrompre les applications clientes. Finalement, vous pouvez désapprouver la version précédente. Le service Gestion des API prend en charge plusieurs schémas de contrôle de version : chemin d’URL, en-tête HTTP ou chaîne de requête. Pour plus d'informations sur le contrôle de version des API en règle générale, consultez Contrôle de version d'une API web RESTful.
Pour les mises à jour qui n’interrompent pas de modifications de l’API, déployez la nouvelle version à un emplacement de préproduction dans la même application de fonction. Vérifiez si le déploiement a réussi, puis remplacez la version de préproduction par la version de production. Publiez une révision dans Gestion des API.
Optimisation des coûts
L’optimisation des coûts consiste à examiner les moyens de réduire les dépenses inutiles et d’améliorer l’efficacité opérationnelle. Pour plus d’informations, consultez Vue d’ensemble du pilier d’optimisation des coûts.
Utiliser la calculatrice de prix Azure pour estimer les coûts. Tenez compte des points suivants pour optimiser le coût de cette architecture.
Azure Functions
Azure Functions prend en charge deux modèles d’hébergement.
Plan de consommation.
La puissance de calcul est allouée automatiquement lors de l'exécution de votre code.
Plan App Service.
Un ensemble de machines virtuelles est alloué pour votre code. Ce plan définit la taille des machines virtuelles et leur nombre.
Dans cette architecture, une fonction est appelée lorsqu'un client émet une requête HTTP. Dans la mesure où un débit à volume élevé constant n'est pas attendu dans ce cas d'usage, un plan de consommation est recommandé. Vous ne paierez ainsi que les ressources de calcul utilisées.
Azure Cosmos DB
Azure Cosmos DB facture le débit approvisionné et le stockage consommé par heure. Le débit approvisionné est exprimé en unités de requête par seconde (RU/s), qui peuvent être utilisées pour les opérations de base de données classiques, comme les insertions et les lectures. Le prix est basé sur la capacité en RU/s que vous réservez.
Le stockage est facturé pour chaque Go utilisé pour vos données et index stockés.
Pour plus d'informations, consultez Modèle de tarification Azure Cosmos DB.
Dans cette architecture, l'application de fonction récupère les documents à partir d’Azure Cosmos DB en réponse aux requêtes HTTP GET émises par le client. Dans ce cas, Azure Cosmos DB est rentable car les opérations de lecture sont nettement moins coûteuses que les opérations d'écriture exprimées en RU/s.
Réseau de distribution de contenu
Le taux facturable peut varier selon la région de facturation et en fonction de l'emplacement du serveur source qui fournit le contenu à l'utilisateur final. L'emplacement physique du client ne correspond pas à la région de facturation. Toute requête HTTP ou HTTPS qui parvient au CDN est un événement facturable qui inclut tous les types de réponse : réussite, échec ou autre. Des réponses différentes peuvent générer des volumes de trafic différents.
Dans cette architecture de référence, le déploiement se trouve dans une seule région Azure.
Pour réduire les coûts, envisagez d'augmenter la TTL du cache en mettant en cache les fichiers de ressources pour une durée plus longue et en définissant la TTL la plus longue possible sur votre contenu.
Pour plus d'informations, consultez la section Coûts de Microsoft Azure Well-Architected Framework.
Déployer ce scénario
Pour déployer l'implémentation de référence de cette architecture, consultez le fichier Readme de GitHub.
Étapes suivantes
Documentation du produit :
- Qu’est-ce que le Stockage Blob Azure ?
- Azure Content Delivery Network (CDN)
- Présentation d’Azure Functions
- En savoir plus sur la Gestion des API
- Bienvenue dans Azure Cosmos DB
- Microsoft Entra ID
- Vue d’ensemble d’Azure Monitor
- Qu’est-ce qu’Azure Pipelines ?
Modules Learn :
- Choix de la meilleure technologie serverless Azure pour un scénario métier
- Créer une logique serverless avec Azure Functions
Ressources associées
Pour en savoir plus sur l'implémentation de référence, lisez Code pas à pas : application serverless avec Azure Functions.
Aide connexe :