Points de terminaison pour l’inférence en production
S’APPLIQUE À : Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Extension Azure CLI v2 (actuelle)Kit de développement logiciel (SDK) Python azure-ai-ml v2 (version actuelle)
Après avoir entraîné des modèles ou des pipelines d’apprentissage automatique, vous devez les déployer en production afin que d’autres puissent les utiliser à des fins d’inférence. L’inférence est le processus d’application de nouvelles données d’entrée au modèle ou au pipeline d’apprentissage automatique pour générer des sorties. Bien que ces sorties soient généralement appelées « prédictions », l’inférence peut être utilisée pour générer des sorties pour d’autres tâches d’apprentissage automatique, telles que la classification et le clustering. Dans Azure Machine Learning, vous effectuez l’inférence à l’aide de points de terminaison et de déploiements. Les points de terminaison et les déploiements vous permettent de dissocier l’interface de votre charge de travail de production et l’implémentation qui la sert.
Intuition
Imaginons que vous travaillez sur une application qui prédit le type et la couleur d’une voiture en fonction de sa photo. Pour cette application, un utilisateur disposant de certaines informations d’identification effectue une requête HTTP à une URL et fournit une image d’une voiture dans le cadre de la requête. En retour, l’utilisateur obtient une réponse qui inclut le type et la couleur de la voiture en tant que valeurs de chaîne. Dans ce scénario, l’URL sert de point de terminaison.
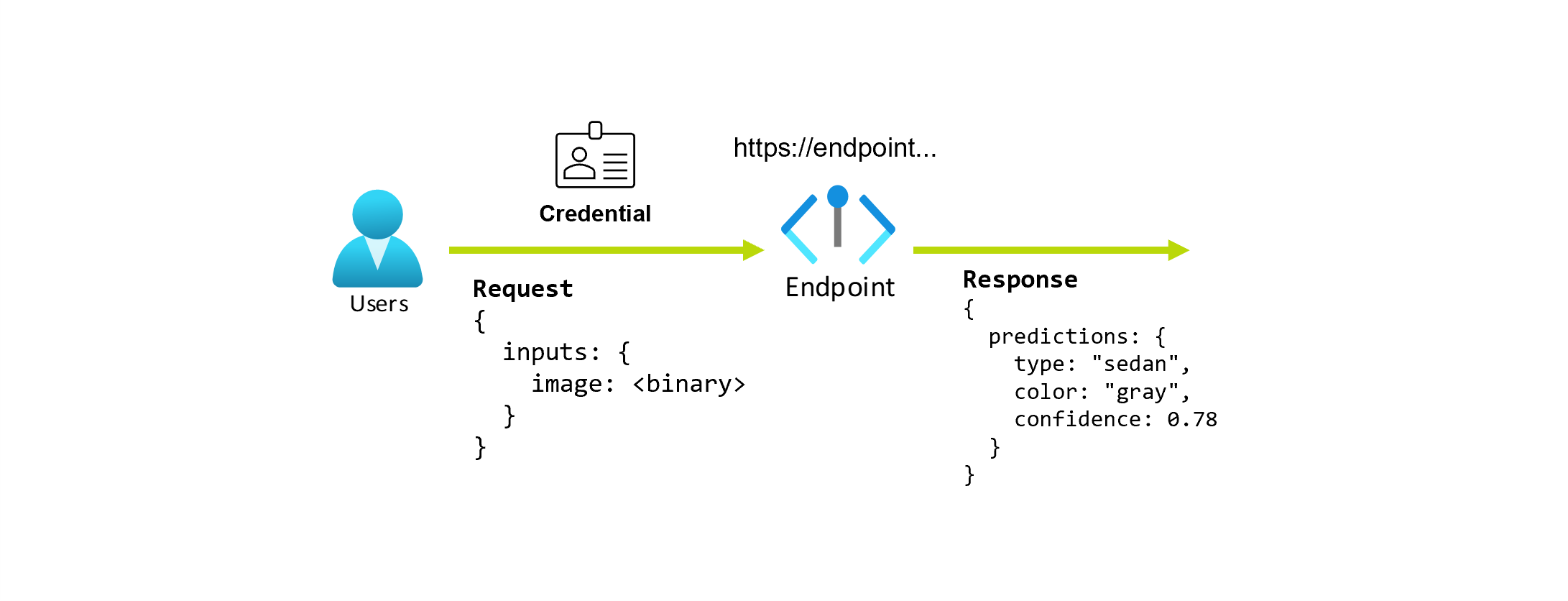
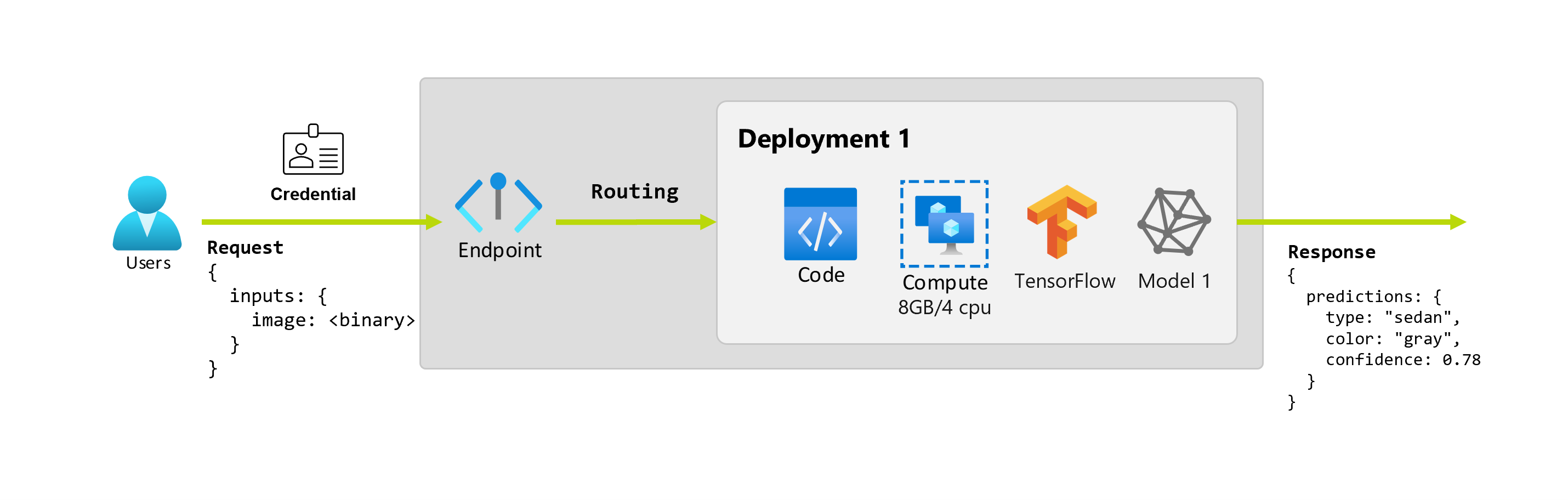
En outre, supposons qu’une scientifique des données, Alice, travaille à l’implémentation de l’application. Alice connaît bien TensorFlow et décide d’implémenter le modèle à l’aide d’un classifieur séquentiel Keras avec une architecture RestNet à partir du TensorFlow Hub. Après avoir testé le modèle, Alice est satisfaite de ses résultats et décide d’utiliser le modèle pour résoudre le problème de prédiction de voiture. Le modèle est volumineux et nécessite 8 Go de mémoire avec 4 cœurs pour s’exécuter. Dans ce scénario, le modèle d’Alice et les ressources, telles que le code et le calcul, nécessaires pour exécuter le modèle, constituent un déploiement sous le point de terminaison.
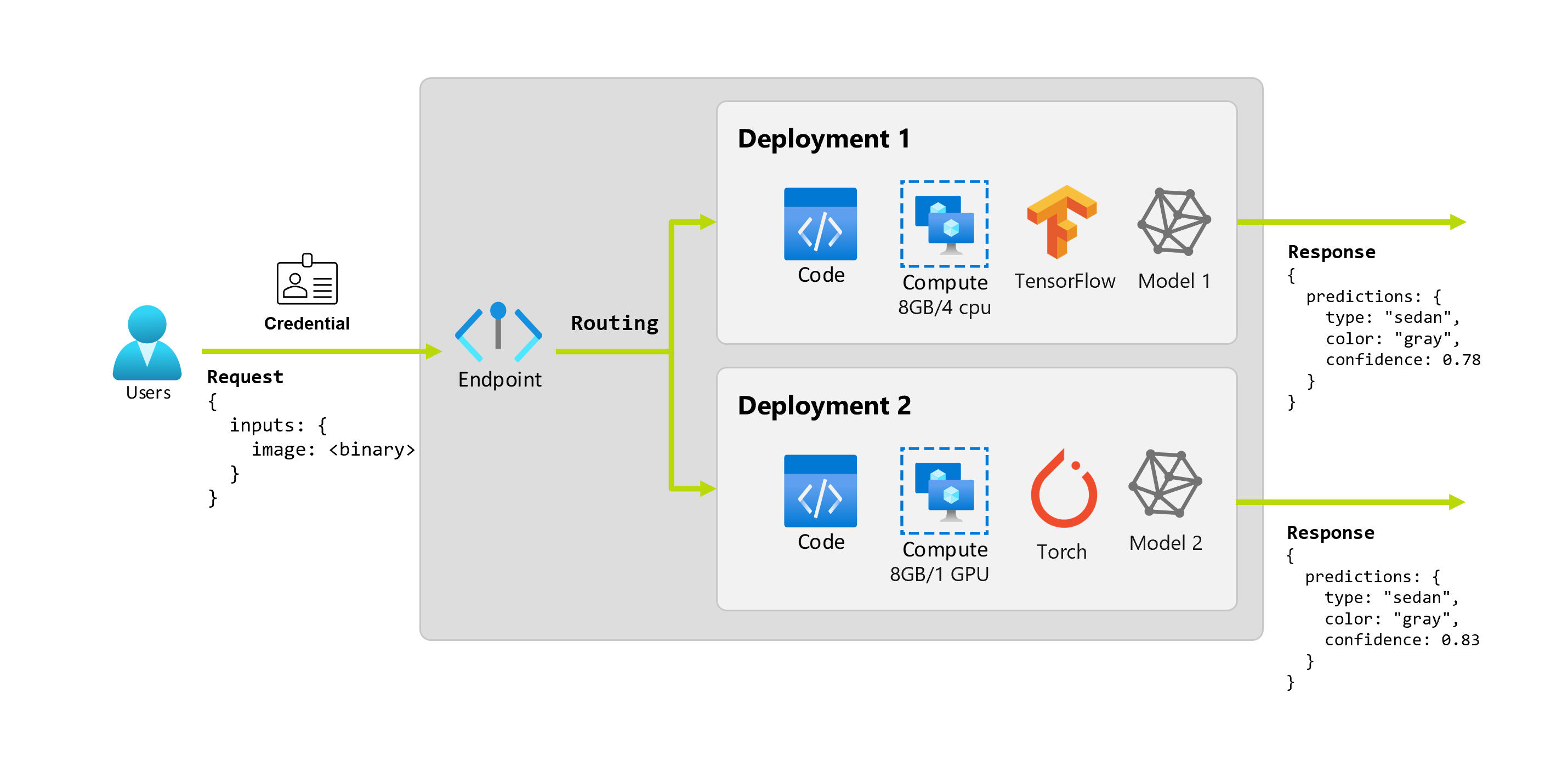
Enfin, imaginons qu’après quelques mois, l’organisation découvre que l’application fonctionne mal sur les images dans des conditions d’éclairage insuffisantes. Bob, un autre scientifique des données, connaît très bien les techniques d’argumentation des données qui aident le modèle à créer une robustesse sur ce facteur. Cependant, Bob préfère utiliser Torch pour implémenter le modèle et entraîne un nouveau modèle avec Torch. Bob aimerait essayer ce modèle en production progressivement jusqu’à ce que l’organisation soit prête à mettre hors service l’ancien modèle. Le nouveau modèle affiche également de meilleures performances lorsqu’il est déployé sur GPU, le déploiement doit donc inclure un GPU. Dans ce scénario, le modèle de Bob et les ressources, telles que le code et le calcul, nécessaires pour exécuter le modèle, constituent un autre déploiement sous le même point de terminaison.
Points de terminaison et déploiements
Un point de terminaison est une URL stable et durable qui peut être utilisé pour faire la requête ou appeler un modèle. Vous fournissez les entrées requises au point de terminaison et récupérez les sorties. Un point de terminaison fournit :
- une URL stable et durable (comme endpoint-name.region.inference.ml.azure.com),
- un mécanisme d’authentification, et
- un mécanisme d’autorisation.
Un déploiement est un ensemble de ressources et de calculs nécessaires pour héberger le modèle ou le composant qui effectue l’inférence réelle. Un point de terminaison unique peut contenir plusieurs déploiements. Ces déploiements peuvent héberger des éléments indépendants et consommer des ressources différentes en fonction de leurs besoins. Les points de terminaison ont un mécanisme de routage qui peut diriger les requêtes vers des déploiements spécifiques dans le point de terminaison.
Pour fonctionner correctement, chaque point de terminaison doit disposer d’au moins un déploiement. Les points de terminaison et les déploiements sont des ressources Azure Resource Manager indépendantes présentées dans le portail Azure.
Points de terminaison en ligne et par lots
Azure Machine Learning vous permet d’implémenter à la fois des points de terminaison en ligne et des points de terminaison par lots. Les points de terminaison en ligne sont conçus pour l’inférence en temps réel. Lorsque vous appelez le point de terminaison, les résultats sont renvoyés dans la réponse du point de terminaison. En revanche, les points de terminaison par lots sont conçus pour l’inférence par lots à long terme. Chaque fois que vous appelez un point de terminaison par lots, vous générez un programme de traitement par lots qui effectue le travail réel.
Quand utiliser le point de terminaison en ligne ou par lots pour votre cas d’usage
Utilisez les points de terminaison en ligne pour rendre les modèles opérationnels pour l’inférence en temps réel dans les requêtes synchrones à faible latence. Nous vous recommandons de les utiliser dans les cas suivants :
- Vous êtes soumis à des exigences de faible latence.
- Votre modèle peut répondre à la requête dans un laps de temps relativement court.
- Les entrées de votre modèle correspondent à la charge utile HTTP de la requête.
- Vous devez effectuer un scale-up en termes de nombre de requêtes.
Utilisez des points de terminaison de lot pour rendre opérationnels des modèles ou des pipelines pour l’inférence asynchrone de longue durée. Nous vous recommandons de les utiliser dans les cas suivants :
- Vous disposez de modèles ou de pipelines coûteux qui nécessitent un temps d’exécution plus long.
- Vous souhaitez rendre opérationnels les pipelines Machine Learning et réutiliser les composants.
- Vous devez effectuer une inférence sur de grandes quantités de données qui sont distribuées dans plusieurs fichiers.
- Vous n’avez pas d’exigences de faible latence.
- Les entrées de votre modèle sont stockées dans un compte de stockage ou dans un élément de données Azure Machine Learning.
- Vous pouvez tirer parti de la parallélisation.
Comparaison des points de terminaison en ligne et par lots
Les points de terminaison en ligne et par lots sont basés sur l’idée de points de terminaison et de déploiements, ce qui vous permet de passer facilement de l’un à l’autre. Toutefois, lorsque vous passez de l’un à l’autre, certaines différences sont à prendre en compte. Certaines de ces différences sont dues à la nature du travail :
Points de terminaison
La table suivante présente un résumé des différentes fonctionnalités disponibles pour les points de terminaison en ligne et par lots.
| Fonctionnalité | Points de terminaison en ligne | Points de terminaison batch |
|---|---|---|
| URL d’appel stable | Oui | Oui |
| Prise en charge de plusieurs déploiements | Oui | Oui |
| Routage du déploiement | Fractionnement du trafic | Basculement vers la valeur par défaut |
| Mettre en miroir le trafic pour un déploiement sécurisé | Oui | Non |
| Prise en charge de Swagger | Oui | Non |
| Authentification | Clé et jeton | Microsoft Entra ID |
| Prise en charge des réseaux privés | Oui | Oui |
| Isolation de réseau gérée | Oui | Oui (voir la configuration supplémentaire requise) |
| Clés gérées par le client | Oui | Oui |
| Base des coûts | None | None |
Déploiements
La table suivante présente un résumé des différentes fonctionnalités disponibles pour les points de terminaison en ligne et par lots au niveau du déploiement. Ces concepts s’appliquent à chaque déploiement sous le point de terminaison.
| Fonctionnalité | Points de terminaison en ligne | Points de terminaison batch |
|---|---|---|
| Types de déploiement | Modèles | Modèles et composants de pipeline |
| Déploiement de modèles MLflow | Oui | Oui |
| Déploiement de modèles personnalisés | Oui, avec un script de scoring | Oui, avec un script de scoring |
| Déploiement de package de modèle 1 | Oui (préversion) | Non |
| Serveur d’inférence 2 | – Serveur d’inférence Azure Machine Learning – Triton – Personnalisé (avec BYOC) |
Inférence par lots |
| Ressource de calcul consommée | Instances ou ressources granulaires | Instances de cluster |
| Type de capacité de calcul | Calcul managé et Kubernetes | Calcul managé et Kubernetes |
| Calcul à faible priorité | Non | Oui |
| Calcul de mise à l’échelle à zéro | Non | Oui |
| Calcul de mise à l’échelle automatique3 | Oui, en fonction de la charge des ressources | Oui, en fonction du nombre de travaux |
| Gestion des surcapacités | Limitation | Mise en file d'attente |
| Base des coûts4 | Par déploiement : instances de calcul en cours d’exécution | Par tâche : instance de calcul consommée dans la tâche (limité au nombre maximal d’instances du cluster). |
| Test local des déploiements | Oui | No |
1 Déploiement de modèles MLflow sur des points de terminaison sans connectivité Internet sortante ou réseaux privés nécessite empaqueter le modèle d’abord.
1Le serveur d’inférence fait référence à la technologie de service qui accepte les demandes, les traite et crée des réponses. Le serveur d’inférence détermine également le format de l’entrée et les sorties attendues.
2La mise à l’échelle automatique est la possibilité d’augmenter ou de réduire de façon dynamique les ressources allouées du déploiement en fonction de sa charge. Les déploiements en ligne et par lots utilisent différentes stratégies de mise à l’échelle automatique. Alors que les déploiements en ligne sont mis à l’échelle en fonction de l’utilisation des ressources (comme le processeur, la mémoire, les requêtes, etc.), les points de terminaison par lots sont mis à l’échelle en fonction du nombre de travaux créés.
4 Les déploiements en ligne et par lots sont facturés par les ressources consommées. Dans les déploiements en ligne, les ressources sont approvisionnées au moment du déploiement. Toutefois, dans le déploiement par lots, aucune ressource n’est consommée au moment du déploiement, mais au moment de l’exécution de la tâche. Par conséquent, aucun coût n’est associé au déploiement lui-même. Notez que les tâches en file d’attente ne consomment pas non plus de ressources.
Interfaces développeur
Les points de terminaison sont conçus pour aider les organisations à rendre opérationnelles les charges de travail au niveau de la production dans Azure Machine Learning. Les points de terminaison sont des ressources robustes et évolutives qui fournissent le meilleur des fonctionnalités pour implémenter des flux de travail MLOps.
Vous pouvez créer et gérer des points de terminaison par lots et en ligne avec plusieurs outils de développement :
- Interface Azure CLI et SDK Python
- API Azure Resource Manager/REST
- Portail web du studio Azure Machine Learning
- Portail Azure (informatique/administrateur)
- Prise en charge des pipelines MLOps CI/CD avec l’interface Azure CLI et les interfaces REST/ARM
Étapes suivantes
- Comment déployer des points de terminaison en ligne managés avec Azure CLI et le SDK Python
- Comment déployer des modèles avec des points de terminaison par lots
- Guide pratique pour déployer des pipelines avec des points de terminaison de lot
- Comment utiliser des points de terminaison en ligne avec le studio
- Guide pratique pour superviser des points de terminaison en ligne managés
- Gérer et augmenter les quotas pour les ressources avec Azure Machine Learning