La mise à l’échelle automatique exécute automatiquement la quantité appropriée de ressources pour gérer la charge sur votre application. Les points de terminaison en ligne prennent en charge la mise à l’échelle automatique via l’intégration à la fonctionnalité de mise à l’échelle automatique d’Azure Monitor.
La mise à l’échelle automatique d’Azure Monitor prend en charge un ensemble complet de règles. Vous pouvez configurer la mise à l’échelle basée sur les métriques (par exemple utilisation du processeur > 70 %), la mise à l’échelle basée sur la planification (par exemple les règles de mise à l’échelle pour les heures de pointe) ou une combinaison des deux. Pour plus d’informations, consultez Vue d’ensemble de la mise à l’échelle automatique dans Microsoft Azure.
Aujourd’hui, vous pouvez gérer la mise à l’échelle automatique à l’aide de l’interface Azure CLI, avec REST, ARM ou le portail Azure basé sur un navigateur. D’autres kits de développement logiciel (SDK) Azure Machine Learning, comme Python SDK, vont être pris en charge ultérieurement.
Pour utiliser la mise à l’échelle automatique, le rôle microsoft.insights/autoscalesettings/write doit être attribué à l’identité qui gère la mise à l’échelle automatique. Vous pouvez utiliser n’importe quel rôle intégré ou personnalisé qui autorise cette action. Pour obtenir des conseils généraux sur la gestion des rôles pour Azure Machine Learning, consultez Gérer les utilisateurs et les rôles. Pour plus d’informations sur les paramètres de mise à l’échelle automatique d’Azure Monitor, consultez Paramètres de mise à l’échelle automatique Microsoft Insights.
Définir un profil de mise à l’échelle automatique
Pour activer la mise à l’échelle automatique pour un point de terminaison, vous devez d’abord définir un profil de mise à l’échelle automatique. Ce profil définit les capacités par défaut, minimale et maximale du groupe identique. L’exemple suivant définit la capacité par défaut et la capacité minimale sous la forme de deux instances de machine virtuelle, ainsi que la capacité maximale sous la forme de cinq instances :
L’extrait de code suivant définit les noms des points de terminaison et des déploiements :
# set your existing endpoint name
ENDPOINT_NAME=your-endpoint-name
DEPLOYMENT_NAME=blue
Ensuite, récupérez l’ID d’Azure Resource Manager du déploiement et du point de terminaison :
# ARM id of the deployment
DEPLOYMENT_RESOURCE_ID=$(az ml online-deployment show -e $ENDPOINT_NAME -n $DEPLOYMENT_NAME -o tsv --query "id")
# ARM id of the deployment. todo: change to --query "id"
ENDPOINT_RESOURCE_ID=$(az ml online-endpoint show -n $ENDPOINT_NAME -o tsv --query "properties.\"azureml.onlineendpointid\"")
# set a unique name for autoscale settings for this deployment. The below will append a random number to make the name unique.
AUTOSCALE_SETTINGS_NAME=autoscale-$ENDPOINT_NAME-$DEPLOYMENT_NAME-`echo $RANDOM`
L’extrait de code suivant crée le profil de mise à l’échelle automatique :
from azure.ai.ml import MLClient
from azure.identity import DefaultAzureCredential
from azure.mgmt.monitor import MonitorManagementClient
from azure.mgmt.monitor.models import AutoscaleProfile, ScaleRule, MetricTrigger, ScaleAction, Recurrence, RecurrentSchedule
import random
import datetime
Définissez des variables pour l’espace de travail, le point de terminaison et le déploiement :
# Set a unique name for autoscale settings for this deployment. The below will append a random number to make the name unique.
autoscale_settings_name = f"autoscale-{endpoint_name}-{deployment_name}-{random.randint(0,1000)}"
mon_client.autoscale_settings.create_or_update(
resource_group,
autoscale_settings_name,
parameters = {
"location" : endpoint.location,
"target_resource_uri" : deployment.id,
"profiles" : [
AutoscaleProfile(
name="my-scale-settings",
capacity={
"minimum" : 2,
"maximum" : 5,
"default" : 2
},
rules = []
)
]
}
)
Dans Azure Machine Learning studio, sélectionnez votre espace de travail, puis sélectionnez Points de terminaison sur le côté gauche de la page. Une fois les points de terminaison répertoriés, sélectionnez celui que vous souhaitez configurer.
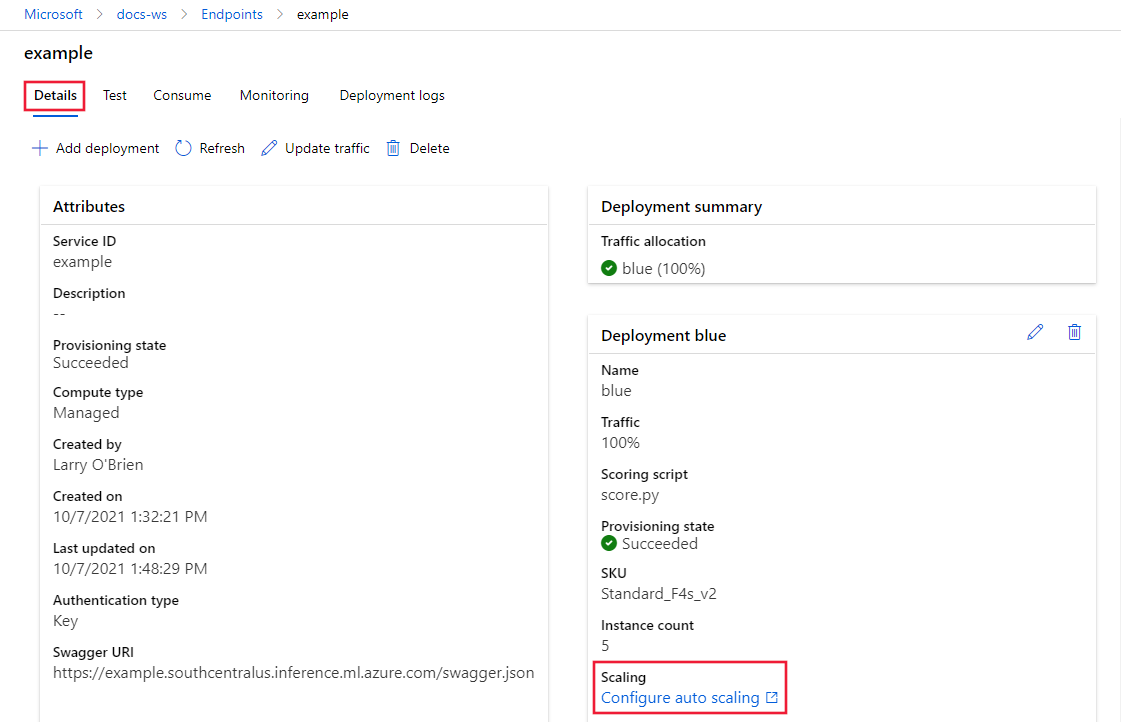
Dans l’onglet Détails du point de terminaison, sélectionnez Configurer la mise à l’échelle automatique.
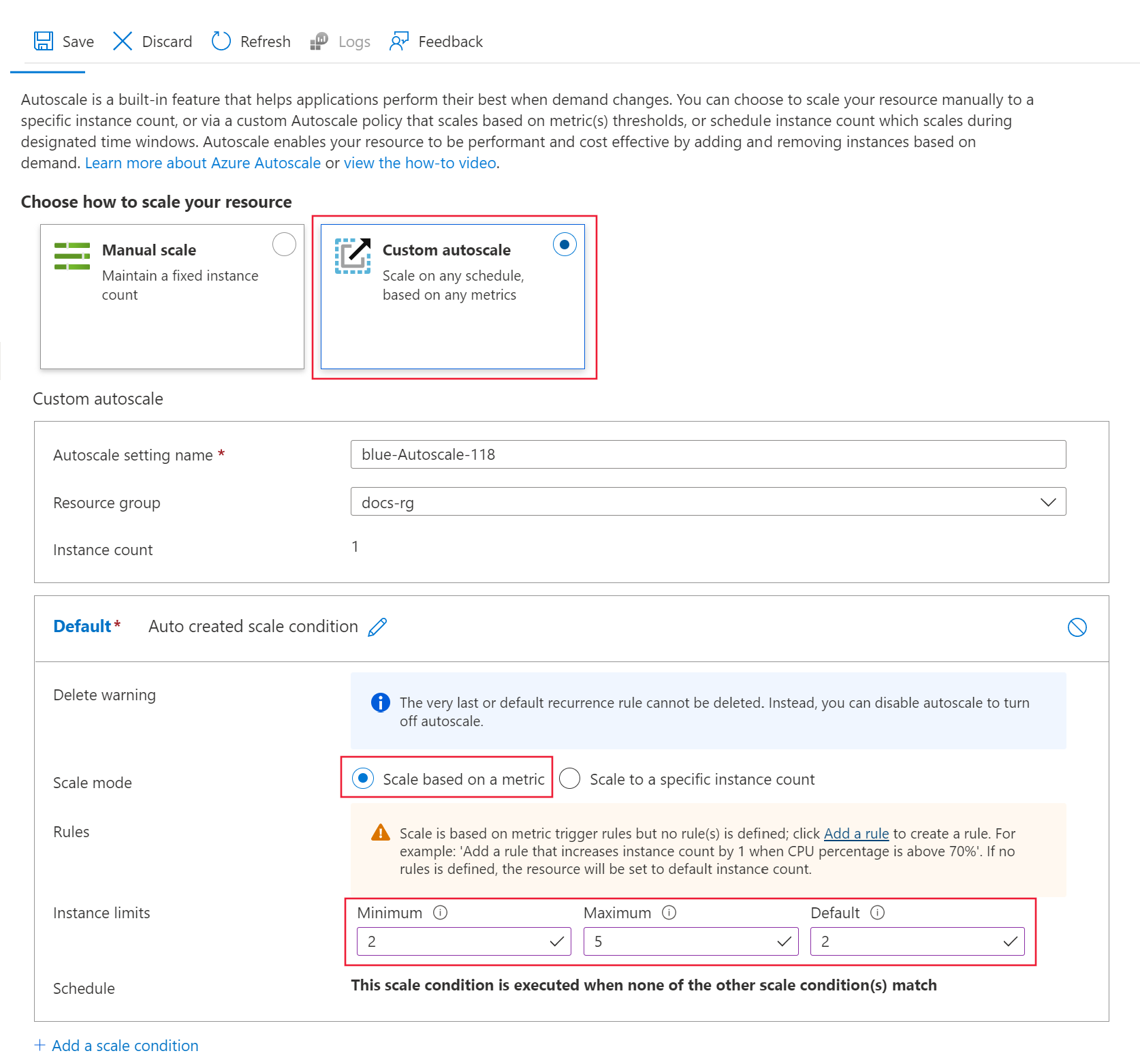
Sous Choisir comment mettre à l’échelle vos ressources, sélectionnez Mise à l’échelle automatique personnalisée pour commencer la configuration. Pour la condition de mise à l’échelle par défaut, utilisez les valeurs suivantes :
Définissez le Mode de mise à l’échelle sur Mettre à l’échelle selon une métrique.
Définissez Minimum sur 2.
Définissez Maximum sur 5.
Définissez Par défaut sur 2.
Créer une règle pour le scale-out à l’aide de métriques
Une règle de scale-out courante consiste à augmenter le nombre d’instances de machine virtuelle quand la charge moyenne du processeur est élevée. L’exemple suivant alloue deux nœuds supplémentaires (jusqu’au maximum) si la charge moyenne du processeur est supérieure à 70 % pendant cinq minutes :
az monitor autoscale rule create \
--autoscale-name $AUTOSCALE_SETTINGS_NAME \
--condition "CpuUtilizationPercentage > 70 avg 5m" \
--scale out 2
La règle fait partie du profil my-scale-settings (autoscale-name correspond à name dans le profil). La valeur de son argument condition indique que la règle doit se déclencher lorsque la consommation processeur moyenne des instances de machine virtuelle dépasse 70 % pendant cinq minutes. Lorsque cela se produit, deux instances de machine virtuelle supplémentaires sont allouées.
Notes
Pour plus d’informations sur la syntaxe de l’interface CLI, consultez az monitor autoscale.
Cette règle fait référence à la moyenne de 5 dernières minutes de CPUUtilizationpercentage provenant des arguments metric_name, time_window et time_aggregation. Quand la valeur de la métrique est supérieure au threshold de 70, deux instances de machine virtuelle supplémentaires sont allouées.
Mettez à jour le profil my-scale-settings pour inclure cette règle :
Dans la section Règles, sélectionnez +Ajouter une règle. La page Règle de mise à l’échelle s’affiche. Utilisez les informations suivantes pour remplir les champs de cette page :
Définissez le Nom de la métrique sur Pourcentage d’utilisation du processeur.
Définissez Opérateur sur Supérieur à et définissez le Seuil de métrique sur 70.
Définissez la Durée (en minutes) sur 5. Laissez la Statistique de grain de temps définie sur Moyen.
Définissez Opération sur Augmenter le nombre de et définissez le Nombre d’instances sur 2.
Enfin, sélectionnez le bouton Ajouter pour créer la règle.
Créer une règle pour le scale-in à l’aide de métriques
Quand la charge est faible, une règle de scale-in permet de réduire le nombre d’instances de machine virtuelle. L’exemple suivant permet de libérer un seul nœud, jusqu’à un minimum de 2, si la charge du processeur est inférieure à 30 % pendant 5 minutes :
Dans la section Règles, sélectionnez +Ajouter une règle. La page Règle de mise à l’échelle s’affiche. Utilisez les informations suivantes pour remplir les champs de cette page :
Définissez le Nom de la métrique sur Pourcentage d’utilisation du processeur.
Définissez Opérateur sur Inférieur à et définissez le Seuil de métrique sur 30.
Définissez la Durée (en minutes) sur 5.
Définissez Opération sur Diminuez le nombre de et définissez le Nombre d’instances sur 1.
Enfin, sélectionnez le bouton Ajouter pour créer la règle.
Si vous disposez à la fois de règles de scale-out et de scale-in, vos règles ressemblent à la capture d’écran suivante. Vous avez spécifié que si la charge moyenne du processeur dépasse 70 % pendant 5 minutes, 2 nœuds supplémentaires doivent être alloués, jusqu’à la limite de 5. Si la charge du processeur est inférieure à 30% pendant 5 minutes, un seul nœud doit être relâché, jusqu’à la valeur minimale de 2.
Créer une règle de mise à l’échelle basée sur les métriques de point de terminaison
Règles précédentes appliquées au déploiement. Ajoutez maintenant une règle qui s’applique au point de terminaison. Dans cet exemple, si la latence des requêtes est supérieure à une moyenne de 70 millisecondes pendant 5 minutes, allouez un autre nœud.
En bas de la page, sélectionnez + Ajouter une condition de mise à l’échelle.
Sélectionnez Mise à l’échelle en fonction des métriques, puis sélectionnez Ajouter une règle. La page Règle de mise à l’échelle s’affiche. Utilisez les informations suivantes pour remplir les champs de cette page :
Définissez Source des métriques sur Autre ressource.
Définissez Type de ressource sur Points de terminaison en ligne Machine Learning.
Définissez Ressource sur votre point de terminaison.
Définissez Nom de métrique sur Latence des requêtes.
Définissez Opérateur sur Supérieur à et définissez le Seuil de métrique sur 70.
Définissez la Durée (en minutes) sur 5.
Définissez Opération sur Augmenter le nombre de et définissez le Nombre d’instances sur 1.
Créer des règles de mise à l’échelle selon une planification
Vous pouvez également créer des règles qui s’appliquent uniquement à certains jours ou à certaines heures. Dans cet exemple, le nombre de nœuds est défini sur 2 pour le week-end.
En bas de la page, sélectionnez + Ajouter une condition de mise à l’échelle. Dans la nouvelle condition de mise à l’échelle, utilisez les informations suivantes pour remplir les champs :
Sélectionnez Mettre à l’échelle à un nombre d’instances spécifique.
Définissez le Nombre d’instances sur 2.
Définissez la planification sur Répéter des jours spécifiques.
Définissez la planification sur Répéter chaquesamedi et dimanche.
Supprimer des ressources
Si vous ne prévoyez pas d’utiliser vos déploiements, supprimez-les :
# delete the autoscaling profile
az monitor autoscale delete -n "$AUTOSCALE_SETTINGS_NAME"
# delete the endpoint
az ml online-endpoint delete --name $ENDPOINT_NAME --yes --no-wait
 Extension Azure CLI v2 (actuelle)
Extension Azure CLI v2 (actuelle)