Créer votre première expérience de science des données dans Machine Learning Studio (classique)
S’APPLIQUE À : Machine Learning Studio (classique).
Machine Learning Studio (classique). Azure Machine Learning
Azure Machine Learning
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Dans cet article, vous créez une expérience de Machine Learning dans Machine Learning Studio (classique) qui prédit le prix d’une voiture en fonction de plusieurs variables, comme la marque et les spécifications techniques.
Si vous ne connaissez pas bien l’apprentissage automatique, la série de vidéos Science des données pour les débutants offre une excellente introduction à l’apprentissage automatique, en présentant les termes et les concepts courants.
Ce guide de démarrage rapide suit le workflow par défaut d’une expérience :
- Création d’un modèle
- Formation du modèle
- Notation et test du modèle
Obtenir les données
Les données sont la première chose dont vous avez besoin pour l’apprentissage automatique. Vous pouvez utiliser plusieurs exemples de jeux de données inclus dans Studio (classique) ou importer d’autres données à partir de sources diverses. Pour les besoins de cet exemple, nous allons utiliser le jeu de données Données sur le prix des véhicules automobiles (brutes) inclus dans votre espace de travail. Ce jeu de données comprend des entrées relatives à plusieurs véhicules, notamment des informations sur la marque, le modèle, les caractéristiques techniques et le prix.
Conseil
Vous pouvez obtenir une copie de travail de l’expérience suivante dans la galerie Azure AI. Accédez à Votre première expérience de science des données : prédiction sur les prix automobiles et cliquez sur Ouvrir dans Studio pour télécharger une copie de l’expérience dans votre espace de travail Machine Learning Studio (classique).
Voici comment obtenir ce jeu de données dans le cadre de votre expérience.
Créez une expérience en cliquant sur + NOUVEAU en bas de la fenêtre Machine Learning Studio (classique). Sélectionnez EXPÉRIENCE>Expérience vide.
Un nom par défaut est attribué à l’expérience : il apparaît en haut du canevas. Sélectionnez le texte et remplacez-le par un nom plus significatif, par exemple Prédiction sur les prix automobiles. Le nom n’a pas besoin d’être unique.
Sur la gauche de la zone de dessin de l’expérience se trouve une palette de jeux de données et de modules. Tapez la valeur automobile dans la zone de recherche se trouvant en haut de cette palette, afin de rechercher le jeu de données Données sur le prix des véhicules automobiles (brutes) . Faites glisser ce jeu de données vers le canevas de l’expérience.
Pour voir à quoi ressemblent ces données, cliquez sur le port de sortie situé en bas du jeu de données d’automobile, puis sélectionnez Visualiser.
Conseil
Les jeux de données et les modules disposent de ports d’entrée et de sortie représentés par de petits cercles : les ports d’entrée se situent en haut, tandis que les ports de sortie se situent en bas. Pour créer un flux de données dans votre expérience, connectez le port de sortie d’un module au port d’entrée d’un autre module. À tout moment, vous pouvez cliquer sur le port de sortie d’un jeu de données ou d’un module afin de voir à quoi les données ressemblent à ce stade dans le flux de données.
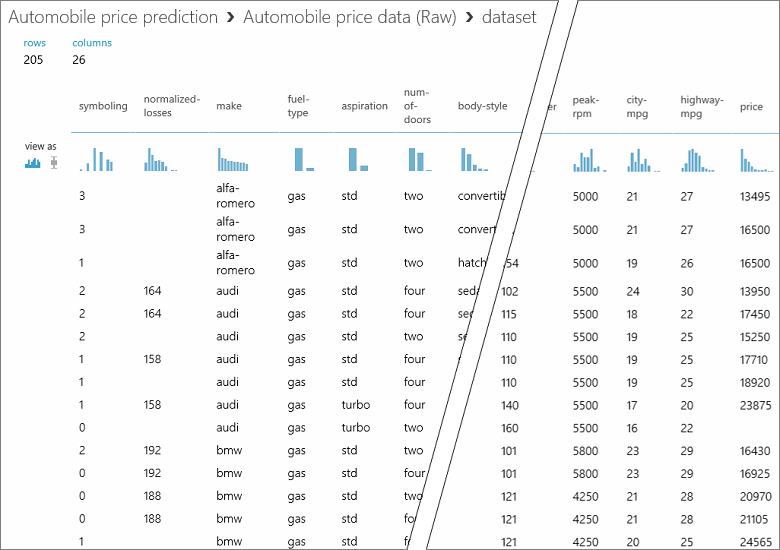
Dans ce jeu de données, chaque ligne représente un véhicule automobile et chaque colonne représente une variable associée au véhicule automobile. Nous allons prédire le prix dans la colonne la plus à droite (colonne 26, intitulée « price ») en fonction des autres variables associées à chaque véhicule automobile.
Fermez la fenêtre de visualisation en cliquant sur le symbole «x» dans le coin supérieur droit.
Préparer les données
Pour pouvoir être analysé, un jeu de données nécessite généralement un traitement préalable. Vous avez peut-être remarqué l'absence de certaines valeurs dans les colonnes des différentes lignes. Pour que vous puissiez analyser les données correctement, ces valeurs manquantes doivent être nettoyées. Nous supprimerons toutes les lignes dans lesquelles des valeurs sont manquantes. De plus, la colonne normalized-losses contient une grande quantité de valeurs manquantes. Nous allons donc l’exclure du modèle.
Conseil
Le nettoyage des valeurs manquantes des données d’entrée est un prérequis pour l’utilisation de la plupart des modules.
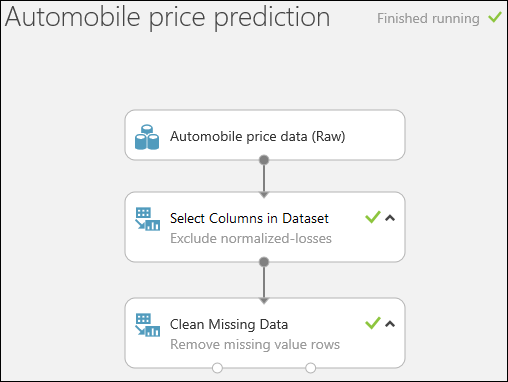
Nous commençons par ajouter un module qui supprime toute la colonne normalized-losses. Nous ajoutons ensuite un module qui supprime toutes les lignes où il manque des données.
Dans la zone de recherche située en haut de la palette de modules, entrez la chaîne sélectionner des colonnes afin de rechercher le module Sélectionner des colonnes dans le jeu de données. Faites ensuite glisser ce module vers le canevas de l’expérience. Ce module permet de sélectionner les colonnes de données à inclure ou exclure du modèle.
Connectez le port de sortie du jeu de données Données sur le prix des véhicules automobiles (brutes) au port d’entrée de Sélectionner des colonnes dans le jeu de données.
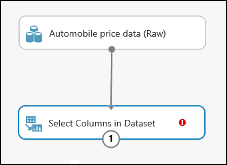
Cliquez sur le module Sélectionner des colonnes dans le jeu de données, puis cliquez sur Lancer le sélecteur de colonne dans le volet Propriétés.
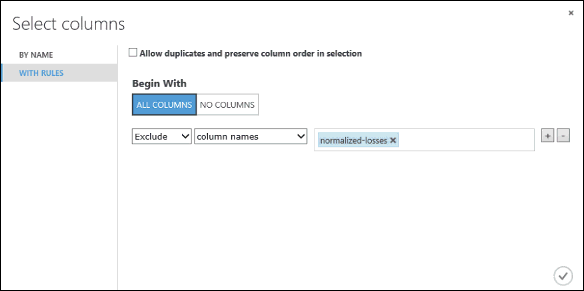
Sur la gauche, cliquez sur With rules
Sous Commencer par, cliquez sur Toutes les colonnes. Ces règles indiquent au module Sélectionner des colonnes dans le jeu de données de transmettre toutes les colonnes, sauf celles que nous nous apprêtons à exclure.
Dans les listes déroulantes, sélectionnez Exclure et Noms des colonnes, puis cliquez dans la zone de texte. Une liste de colonnes s’affiche. Sélectionnez la colonne normalized-losses, qui est alors ajoutée à la zone de texte.
Cliquez sur le bouton en forme de coche (OK) pour fermer le sélecteur de colonne (en bas à droite).
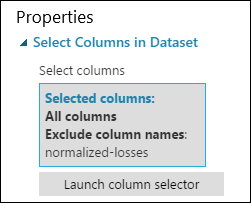
À présent, le volet de propriétés du module Sélectionner des colonnes dans le jeu de données indique qu’il transmettra toutes les colonnes du jeu de données, à l’exception de normalized-losses.
Conseil
Vous pouvez ajouter un commentaire dans un module en double-cliquant sur ce module, puis en saisissant du texte. Ceci peut vous aider à voir d'un seul coup d'œil ce que fait chaque module dans votre expérience. Dans ce cas, double-cliquez sur le module Sélectionner des colonnes dans le jeu de données, puis entrez le commentaire suivant : « Exclure les pertes normalisées ».
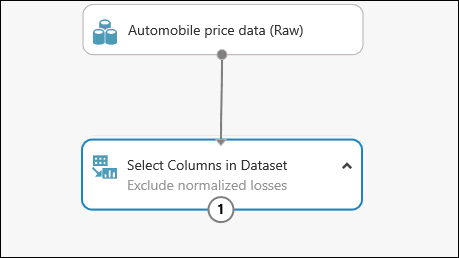
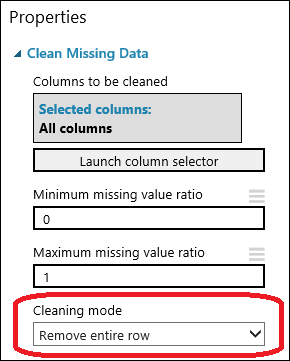
Faites glisser le module Nettoyer les données manquantes jusqu’à la zone de dessin de l’expérience et connectez-le au module Sélectionner des colonnes dans le jeu de données. Dans le volet Propriétés, sélectionnez Supprimer toute la ligne sous Mode de nettoyage. Ces options indiquent au module Clean Missing Data de nettoyer les données en supprimant les lignes dans lesquelles il manque des valeurs. Double-cliquez sur le module et saisissez le commentaire suivant : « Supprimer les lignes de valeur manquantes ».
Exécutez l’expérience en cliquant sur EXÉCUTER au bas de la page.
Une fois l’expérience terminée, une coche verte s’affiche en regard de chaque module pour indiquer la réussite de leurs opérations. Notez que le statut Exécution terminée s’affiche dans le coin supérieur droit de la fenêtre.
Conseil
Pourquoi exécutons-nous l’expérience maintenant ? Lors de l’exécution de l’expérience, les définitions de colonne de nos données sont transmises à partir du jeu de données, par le biais des modules Sélectionner des colonnes dans le jeu de données et Nettoyage des données manquantes. Autrement dit, tous les modules que nous connectons à Nettoyage des données manquantes disposent de ces mêmes informations.
Nous disposons maintenant de données nettoyées. Si vous souhaitez afficher le jeu de données nettoyé, cliquez sur le port de sortie gauche du module Nettoyage des données manquantes et sélectionnez Visualiser. Vous pouvez constater que la colonne normalized-losses n’est plus là et qu’il ne manque plus de données.
Maintenant que les données sont nettoyées, nous pouvons indiquer les fonctionnalités que nous allons utiliser dans le modèle de prévision.
Définition des fonctionnalités
Dans le domaine du Machine Learning, les caractéristiques sont les propriétés individuelles mesurables d’un élément qui vous intéresse. Dans notre jeu de données, chaque ligne représente un véhicule et chaque colonne une fonctionnalité de ce véhicule.
La recherche du jeu de fonctionnalités adéquat pour la création d’un modèle de prévision requiert certaines expériences et des connaissances sur le problème qui se pose. Certaines fonctionnalités sont mieux adaptées à la prévision que d’autres. Certaines fonctionnalités ont une forte corrélation avec d’autres fonctionnalités et peuvent être supprimées. Par exemple, city-mpg et highway-mpg sont étroitement liées : nous pouvons donc conserver l’une et supprimer l’autre sans trop affecter la prédiction.
Nous allons développer un modèle utilisant un sous-ensemble de ces fonctionnalités pour notre jeu de données. Vous pouvez revenir en arrière et sélectionner d’autres fonctionnalités, relancer l’expérience et voir si vous obtenez de meilleurs résultats. Mais pour commencer, nous allons essayer les fonctionnalités suivantes :
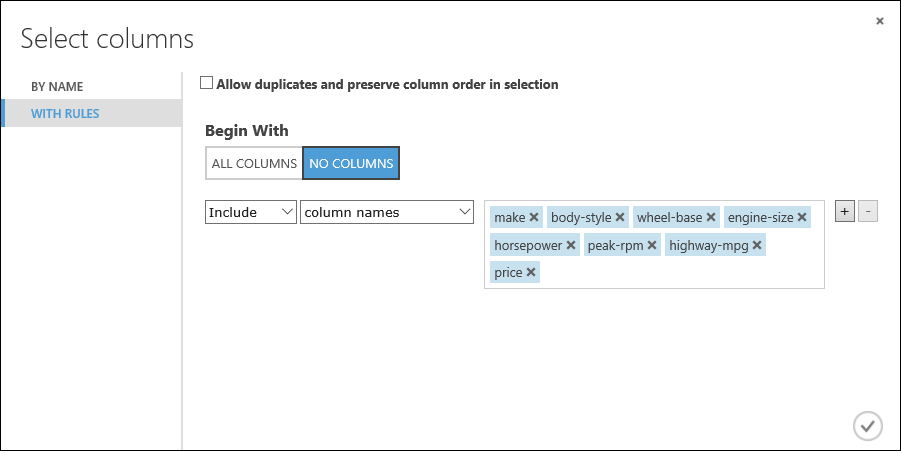
make, body-style, wheel-base, engine-size, horsepower, peak-rpm, highway-mpg, price
Faites glisser un autre module Sélectionner des colonnes dans le jeu de données vers le canevas de l’expérience. Connectez le port de sortie de gauche du module Nettoyage des données manquantes à l’entrée du module Sélectionner des colonnes dans le jeu de données.
Double-cliquez sur le module et saisissez le commentaire suivant : « Sélection des fonctionnalités pour la prévision ».
Cliquez sur l’option Lancer le sélecteur de colonne figurant dans le volet Propriétés.
Cliquez sur With rules(à l’aide de règles).
Sous Commencer par, cliquez sur Aucune colonne. Dans la ligne de filtre, sélectionnez Inclure et Noms des colonnes, puis sélectionnez notre liste de noms de colonnes dans la zone de texte. Ce filtre indique au module de transmettre uniquement les colonnes (fonctionnalités) sélectionnées.
Cliquez sur le bouton en forme de coche (OK) pour continuer.
Ce module produit un jeu de données filtré qui contient uniquement les fonctionnalités que nous souhaitons transmettre à l’algorithme d’apprentissage utilisé à l’étape suivante. Plus tard, vous pouvez reprendre la procédure en utilisant une autre sélection de fonctionnalités.
Sélection et application d’un algorithme
À présent que les données sont prêtes, la construction d'un modèle de prévision passe par la formation et le test. Nous allons utiliser nos données pour former le modèle, puis tester le modèle pour voir dans quelle mesure il peut prédire les prix.
La classification et la régression sont deux types d’algorithmes de machine learning supervisé. La classification permet de prédire une réponse à partir d'un jeu de catégories défini, comme une couleur (rouge, bleu ou vert). La régression est utilisée pour prédire un nombre.
Étant donné que nous voulons prédire un prix, correspondant à un nombre, nous allons utiliser un algorithme de régression. Dans cet exemple, nous utilisons un modèle de régression linéaire.
Nous formons le modèle en lui fournissant un jeu de données qui inclut le prix. Le modèle analyse les données et recherche les corrélations entre les fonctionnalités d’un véhicule automobile et son prix. Puis nous testons le modèle : nous lui affectons un ensemble de fonctionnalités pour véhicules automobiles que nous connaissons et nous étudions la précision du modèle concernant la prédiction des prix.
Nous allons utiliser nos données pour la formation et le test en les divisant en jeux de données distincts de formation et de test.
Sélectionnez et faites glisser le module Fractionner les données sur le canevas d’expérience et connectez-le au dernier module Sélectionner des colonnes dans le jeu de données.
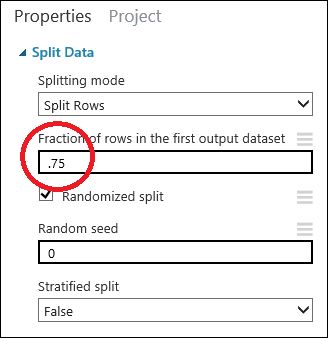
Cliquez sur le module Fractionner les données pour le sélectionner. Rechercher Fraction de lignes dans le premier jeu de données de sortie (dans le volet Propriétés à droite du canevas) et attribuez-lui la valeur 0,75. Ainsi, nous allons utiliser 75 % des données pour former le modèle, et 25 % pour le tester.
Conseil
En modifiant le paramètre Valeur de départ aléatoire , vous pouvez produire différents échantillons aléatoires pour la formation et le test. Ce paramètre contrôle la valeur de départ du générateur de nombres pseudo-aléatoire.
Exécutez l’expérience. Lors de l’expérience, les modules Sélectionner des colonnes dans le jeu de données et Fractionner les données transmettent des définitions de colonne aux modules que nous allons ajouter par la suite.
Pour sélectionner l’algorithme d’apprentissage, développez la catégorie Machine Learning dans la palette des modules, à gauche de la zone de dessin, puis développez Initialiser le modèle. Différentes catégories de modules s'affichent, permettant d'initialiser des algorithmes d'apprentissage automatique. Pour les besoins de cet exemple, sélectionnez le module Régression linéaire sous la catégorie Régression, puis faites-le glisser vers le canevas de l’expérience. Vous pouvez également rechercher le module en tapant « régression linéaire » dans la zone de recherche de la palette.
Recherchez et faites glisser le module Entraîner le modèle jusqu’à la zone de dessin. Connectez la sortie du module Régression linéaire à l’entrée de gauche du module Entraîner votre modèle, puis connectez la sortie des données d’entraînement (port gauche) du module Fractionner les données à l’entrée de droite du module Entraîner votre modèle.
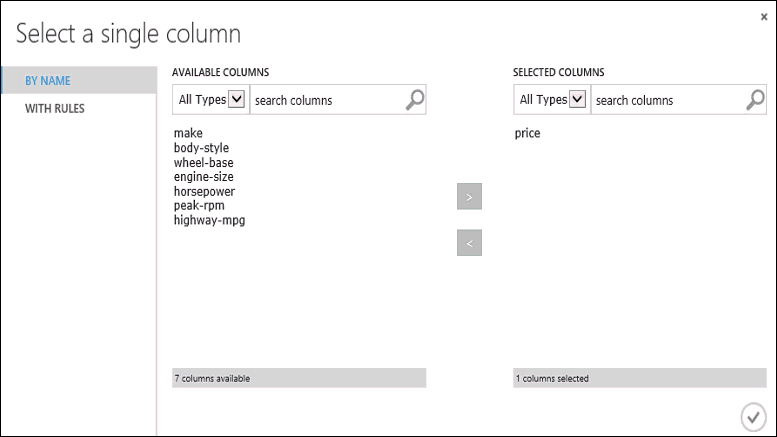
Cliquez sur le module Entraîner votre modèle, cliquez sur l’option Lancer le sélecteur de colonne dans le volet Propriétés, puis sélectionnez la colonne Price. Price est la valeur à prédire par notre modèle.
Vous pouvez sélectionner la colonne price dans le sélecteur de colonne en la faisant passer de la liste Colonnes disponibles à la liste Colonnes sélectionnées.
Exécutez l’expérience.
Nous disposons à présent d’un modèle de régression formé qui permet de noter de nouvelles données automobiles pour effectuer des prédictions de prix.
Prédiction des nouveaux prix des voitures
À présent que nous avons formé le modèle à l'aide de 75 % de nos données, nous pouvons l'utiliser pour la notation du reste de nos données (25 %), afin de voir s'il fonctionne correctement.
Recherchez et faites glisser le module Noter le modèle vers le canevas de l’expérience. Connectez la sortie du module Entraîner le modèle au port d’entrée de gauche du module Scorer le modèle. Connectez la sortie des données de test (port de droite) du module Fractionner les données au port d’entrée de droite du module Scorer le modèle.
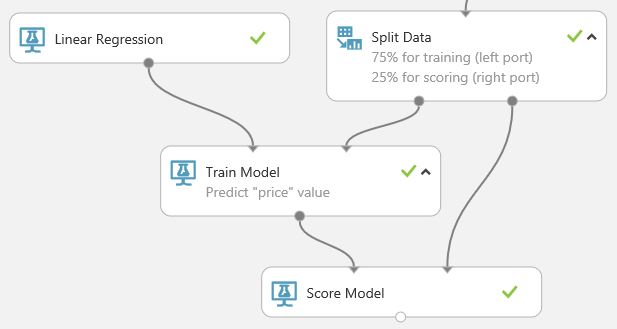
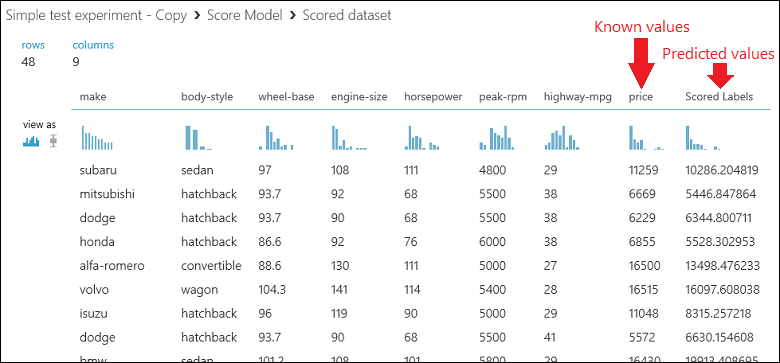
Exécutez l’expérience et affichez la sortie du module Noter le modèle en cliquant sur le port de sortie de Noter le modèle, puis sélectionnez Visualiser. La sortie affiche les valeurs de prévision associées au prix, ainsi que les valeurs connues des données de test.
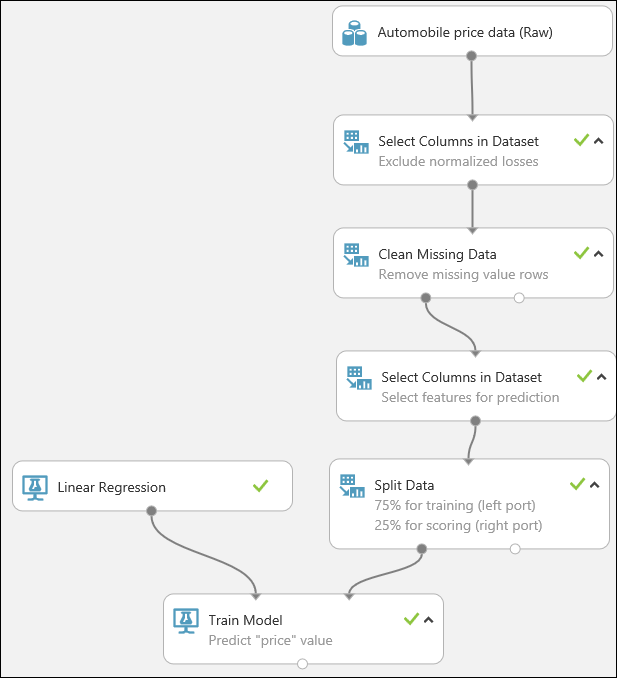
Enfin, nous testons la qualité des résultats. Sélectionnez et faites glisser le module Évaluer le modèle vers le canevas de l’expérience, puis connectez la sortie du module Noter le modèle à l’entrée de gauche du module Évaluer le modèle. L’expérience finale doit ressembler à ceci :
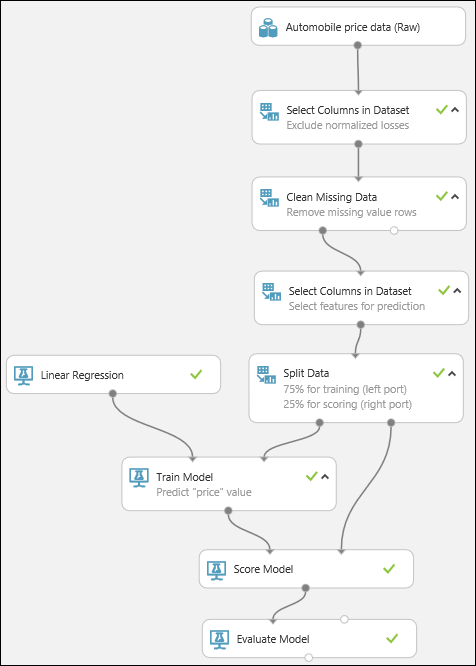
Exécutez l’expérience.
Pour afficher la sortie du module Évaluer le modèle, cliquez sur le port de sortie, puis sélectionnez Visualiser.
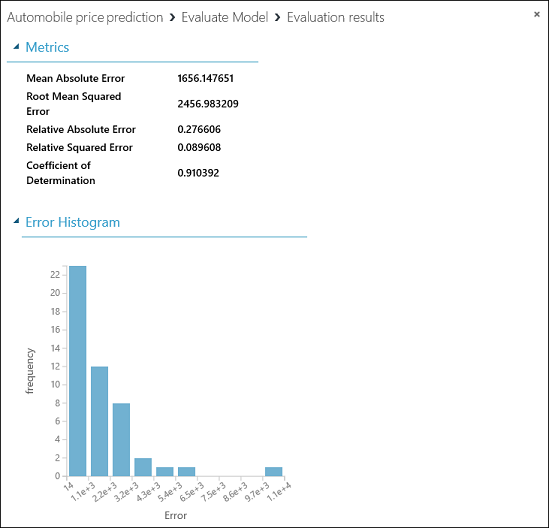
Les statistiques suivantes s’affichent pour notre modèle :
- Erreur Absolue Moyenne (EAM) la moyenne des erreurs absolues (une erreur correspond à la différence entre la valeur prévue et la valeur réelle).
- Racine de l’erreur quadratique moyenne (RMSE) : la racine carrée de la moyenne des erreurs carrées des prévisions effectuées sur le jeu de données de test.
- Erreur absolue relative: la moyenne des erreurs absolues relative à la différence absolue entre les valeurs réelles et la moyenne de toutes les valeurs réelles.
- Erreur carrée relative : la moyenne des erreurs carrées relative à la différence carrée entre les valeurs réelles et la moyenne de toutes les valeurs réelles.
- Coefficient de détermination : aussi nommé valeur R au carré, il s’agit d’une mesure statistique indiquant à quel point un modèle correspond aux données.
Pour chacune des statistiques liées aux erreurs, les valeurs les plus petites sont privilégiées. En effet, une valeur plus petite indique un degré de correspondance plus étroit avec la valeur réelle. Plus la valeur du Coefficient de détermination, est proche de un (1.0), plus la prévision est correcte.
Nettoyer les ressources
Si vous n’avez plus besoin des ressources que vous avez créées dans le cadre de cet article, supprimez-les pour éviter des frais inutiles. Découvrez comment faire dans l’article Exporter et supprimer des données utilisateur intégrées dans le produit.
Étapes suivantes
Dans ce guide de démarrage rapide, vous avez créé une expérience simple à partir d’un exemple de jeu de données. Pour approfondir le processus de création et de déploiement d’un modèle, passez au tutoriel sur les solutions prédictives.