Tutoriel 1 : Prédire le risque de crédit – Machine Learning Studio (classique)
S’APPLIQUE À  Machine Learning Studio (classique)
Machine Learning Studio (classique)  Azure Machine Learning
Azure Machine Learning
Important
Le support de Machine Learning Studio (classique) prend fin le 31 août 2024. Nous vous recommandons de passer à Azure Machine Learning avant cette date.
À partir du 1er décembre 2021, vous ne pourrez plus créer de nouvelles ressources Machine Learning Studio (classique). Jusqu’au 31 août 2024, vous pouvez continuer à utiliser les ressources Machine Learning Studio (classique) existantes.
- Consultez les informations sur le déplacement des projets de machine learning de ML Studio (classique) à Azure Machine Learning.
- En savoir plus sur Azure Machine Learning
La documentation ML Studio (classique) est en cours de retrait et ne sera probablement plus mise à jour.
Dans ce tutoriel, vous étudiez de manière approfondie le processus de développement d’une solution d’analyse prédictive. Vous développez un modèle simple dans Machine Learning Studio (classique). Vous déployez ensuite le modèle en tant que service web Machine Learning. Ce modèle déployé peut effectuer des prédictions à l’aide de nouvelles données. Ce tutoriel est la première partie d’une série de tutoriels qui en compte trois.
Supposons que vous deviez prédire le risque lié à l'octroi d'un crédit à un individu sur la base des informations fournies lors d'une demande de crédit.
L’évaluation du risque de crédit est un problème complexe, mais ce tutoriel va le simplifier un peu. Vous allez l’utiliser comme exemple de création d’une solution d’analyse prédictive à l’aide de Machine Learning Studio (classique). Vous allez utiliser Machine Learning Studio (classique) et un service web Machine Learning pour cette solution.
Dans ce tutoriel en trois parties, vous commencez avec des données de risque crédit disponibles publiquement. Ensuite, vous développez et entraînez un modèle prédictif. Enfin, vous déployez le modèle en tant que service web.
Dans cette partie du tutoriel, vous allez effectuer les opérations suivantes :
- Créer un espace de travail Machine Learning Studio (classique)
- Charger des données existantes
- Créer une expérience
Vous pouvez ensuite utiliser cette expérience pour entraîner des modèles dans la deuxième partie, puis les déployer dans la troisième partie.
Prérequis
Ce didacticiel suppose que vous avez utilisé Machine Learning Studio (classique) au moins une fois et que vous comprenez les concepts du Machine Learning. Il ne suppose pas non plus que vous êtes un expert.
Si vous n’avez jamais utilisé Machine Learning Studio (classique) , vous pouvez commencer par le démarrage rapide Créer votre première expérience de science des données dans Machine Learning Studio (classique). Ce guide de démarrage rapide vous accompagne lors de votre première utilisation de Machine Learning Studio (classique). Vous y découvrirez les principes fondamentaux de glisser-déplacer des modules vers votre expérience, et comment les connecter, réaliser votre expérience et étudier les résultats.
Conseil
Vous pouvez obtenir une copie de travail de l’expérience que vous développez dans ce tutoriel dans Azure AI Gallery. Accédez à didacticiel – Prédire le risque de crédit , puis cliquez sur Ouvrir dans Studio pour télécharger une copie de l’expérience dans votre espace de travail Machine Learning Studio (classique).
Créer un espace de travail Machine Learning Studio (classique)
Pour utiliser Machine Learning Studio (classique), vous devez disposer d’un espace de travail Machine Learning Studio (classique). Cet espace de travail contient les outils dont vous avez besoin pour créer, gérer et publier des expériences.
Pour créer un espace de travail, consultez Créer et partager un espace de travail Machine Learning Studio (classique).
Une fois votre espace de travail créé, ouvrez Machine Learning Studio (classique) (https://studio.azureml.net/Home). Si vous disposez de plusieurs espaces de travail, vous pouvez sélectionner l’espace de travail dans la barre d’outils dans le coin supérieur droit de la fenêtre.
Conseil
Si vous êtes propriétaire de l’espace de travail, vous pouvez partager les expériences sur lesquelles vous travaillez en invitant d’autres personnes dans l’espace de travail. Pour cela, dans Machine Learning Studio (classique), ouvrez la page PARAMÈTRES . Vous avez simplement besoin du compte Microsoft ou du compte professionnel de chaque utilisateur.
Dans la page PARAMÈTRES, cliquez sur UTILISATEURS, puis cliquez sur INVITER PLUS D’UTILISATEURS en bas de la fenêtre.
Charger des données existantes
Pour développer un modèle prédictif pour un risque de crédit, vous avez besoin de données que vous pouvez utiliser pour entraîner puis tester le modèle. Pour ce tutoriel, vous allez utiliser le modèle « UCI Statlog (German Credit Data) Data Set » qui se trouve dans le dépôt UC Irvine Machine Learning. Vous pouvez le trouver ici :
https://archive.ics.uci.edu/ml/datasets/Statlog+(German+Credit+Data)
Vous allez utiliser le fichier nommé german.data. Téléchargez ce fichier sur votre disque dur.
Le jeu de données german.data contient des lignes de 20 variables pour 1000 candidats à un crédit. Ces 20 variables représentent l’ensemble des caractéristiques du jeu de données (le vecteur de fonctionnalité), qui fournit des caractéristiques permettant d’identifier chaque candidat à un crédit. Une colonne supplémentaire pour chaque ligne représente le risque de crédit calculé de chaque candidat : 700 candidats constituent un faible risque de crédit et 300 un risque élevé.
Le site Web UCI fournit une description des attributs du vecteur de fonctionnalité pour ces données. Celles-ci incluent des informations financières, l’historique du crédit, le statut professionnel et des informations personnelles. Une évaluation binaire a été appliquée à chaque candidat, afin d'indiquer s'il constitue un risque de crédit faible ou élevé.
Vous allez utiliser ces données pour entraîner un modèle d’analyse prédictive. Quand vous aurez terminé, votre modèle pourra accepter un vecteur de fonctionnalité pour un nouvel individu et prédire si ce dernier constitue un risque de crédit faible ou élevé.
Voici une évolution intéressante.
Sur le site web UCI, la description du jeu de données détermine les coûts générés par une erreur de classification des risques associés à un crédit accordé. Si le modèle prévoit un crédit à haut risque pour une personne qui présente un risque réduit, cela signifie que la classification est erronée.
Cependant, le fait de prévoir un risque faible pour une personne présentant un risque élevé est cinq fois plus coûteux pour l’institution financière.
Vous voulez donc entraîner votre modèle de sorte qu’il considère l’erreur de classification ci-dessus comme étant cinq fois plus coûteuse que l’erreur inverse.
Il existe une manière assez simple d’y parvenir quand vous entraînez le modèle de votre expérience, à savoir multiplier par cinq la valeur des entrées représentant une personne qui présente un risque de crédit élevé.
Ensuite, si le modèle considère une personne présentant un risque élevé comme ne représentant qu’un faible risque, il reproduit cette erreur cinq fois, une fois par doublon. Cela augmentera le coût de cette erreur dans les résultats de formation.
Conversion du format du jeu de données
Le jeu de données d'origine utilise un format séparé par des espaces. Machine Learning Studio (classique) fonctionne mieux avec un fichier de valeurs séparées par des virgules (CSV). Vous allez donc convertir le jeu de données en remplaçant les espaces par des virgules.
Il existe de nombreux moyens de convertir ces données. L'une des méthodes consiste à utiliser la commande Windows PowerShell suivante :
cat german.data | %{$_ -replace " ",","} | sc german.csv
Vous pouvez aussi utiliser la commande Unix sed :
sed 's/ /,/g' german.data > german.csv
Dans les deux cas, vous avez créé une version séparée par des virgules des données dans un fichier nommé german.csv que vous pouvez utiliser dans votre expérience.
Télécharger le jeu de données vers Machine Learning Studio (classique)
Une fois les données converties au format CSV, vous devez les charger sur Machine Learning Studio (classique).
Ouvrez la page d’accueil de Machine Learning Studio (classique) (https://studio.azureml.net).
Cliquez sur le menu
 dans le coin supérieur gauche de la fenêtre, cliquez sur Azure Machine Learning, sélectionnez Studio, puis connectez-vous.
dans le coin supérieur gauche de la fenêtre, cliquez sur Azure Machine Learning, sélectionnez Studio, puis connectez-vous.Cliquez sur +NOUVEAU en bas de la fenêtre.
Sélectionnez JEU DE DONNÉES.
Sélectionnez DEPUIS UN FICHIER LOCAL.
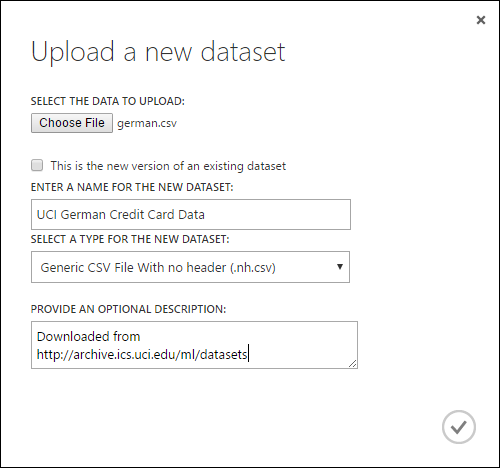
Dans la boîte de dialogue Charger un nouveau jeu de données, cliquez sur Parcourir, puis recherchez le fichier german.csv que vous avez créé.
Entrez le nom du jeu de données. Pour ce tutoriel, appelez-le « Données de carte de crédit allemande UCI ».
Pour le type de données, sélectionnez Fichier CSV générique sans en-tête (.nh.csv) .
Ajoutez la description de votre choix.
Cliquez sur la coche OK.
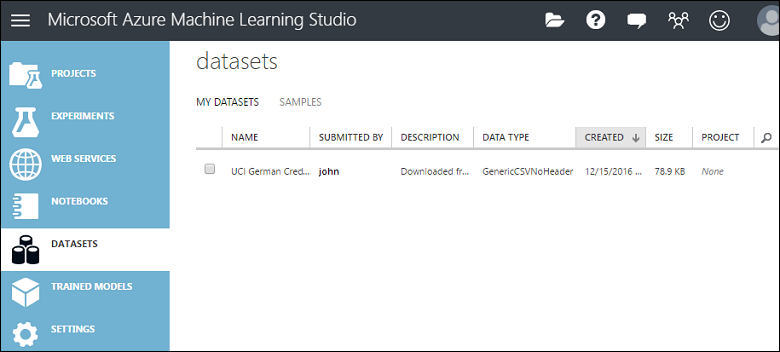
Les données sont chargées dans un module de jeu de données que vous pouvez utiliser dans une expérience.
Vous pouvez gérer les jeux de données que vous avez téléchargés dans Studio (classique) en cliquant sur l’onglet JEUX DE DONNÉES à gauche de la fenêtre de Studio (classique).
Pour plus d’informations sur l’importation d’autres types de données dans une expérience, consultez Importer vos données d’apprentissage dans Machine Learning Studio (classique).
Créer une expérience
L’étape suivante de ce tutoriel consiste à créer une expérience dans Machine Learning Studio (classique) qui utilise le jeu de données que vous avez chargé.
Dans Studio (classique), cliquez sur +NOUVEAU en bas de la fenêtre.
Sélectionnez EXPÉRIENCE, puis sélectionnez « Expérience vide ».
Sélectionnez le nom d’expérience par défaut, situé en haut du canevas, et remplacez-le par un nom significatif.

Conseil
Il est conseillé de compléter les champs Résumé et Description relatifs à l’expérience dans le volet Propriétés. Ces propriétés vous donnent la possibilité de documenter l'expérience afin que toute personne la consultant ultérieurement comprenne vos objectifs et votre méthodologie.

Dans la palette des modules à gauche du canevas d'expérience, développez Jeux de données enregistrés.
Recherchez le jeu de données que vous avez créé sous My Datasets (Mes jeux de données) et faites-le glisser sur la zone de dessin. Vous pouvez également le rechercher en entrant son nom dans la zone Rechercher au-dessus de la palette.
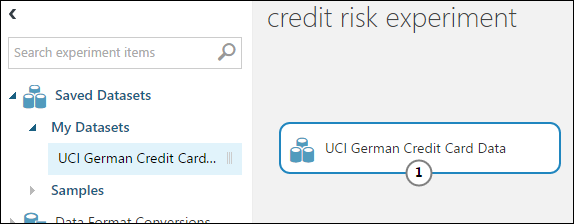
Préparer les données
Vous pouvez voir les 100 premières lignes de données et quelques informations statistiques concernant tout le jeu de données : pour ce faire, cliquez sur le port de sortie du jeu de données (le petit cercle en bas) et en sélectionnez Visualiser.
Le fichier de données étant dépourvu d’en-têtes de colonne, Studio (classique) a fourni des en-têtes génériques (Col1, Col2, etc. ). Des en-têtes explicites ne sont pas essentiels pour créer un modèle, mais ils facilitent l’utilisation des données dans l’expérience. En outre, lors de la publication de ce modèle dans un service web, les en-têtes permettent à l’utilisateur du service d’identifier les colonnes.
Vous pouvez ajouter des en-têtes de colonne en utilisant le module Modifier les métadonnées.
Vous utilisez le module Modifier les métadonnées pour modifier des métadonnées associées à un jeu de données. Dans ce cas, vous l’utilisez pour fournir des noms plus conviviaux pour les en-têtes de colonne.
Pour utiliser Modifier les métadonnées, vous devez commencer par spécifier les colonnes à modifier (en l’occurrence, toutes). Ensuite, vous spécifiez l’action à effectuer sur ces colonnes (en l’occurrence, la modification de leurs en-têtes).
Dans la palette des modules, tapez « métadonnées » dans la zone Rechercher . Le module Modifier les métadonnées apparaît dans la liste des modules.
Cliquez sur le module Modifier les métadonnées et faites-le glisser sur le canevas avant de le déposer sous le jeu de données que vous avez ajouté précédemment.
Connectez le jeu de données au module Modifier les métadonnées : cliquez sur le port de sortie du jeu de données (le petit cercle en bas du jeu de données), faites glisser vers le port d’entrée de Modifier les métadonnées (le petit cercle en haut du module), puis relâchez le bouton de la souris. Le jeu de données et le module restent connectés même si vous opérez des déplacements sur le canevas.
L'expérience doit ressembler à ceci :
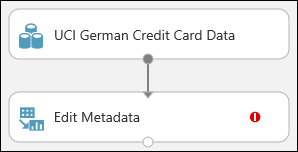
Le point d’exclamation rouge indique que vous n’avez pas encore défini les propriétés de ce module. Ce sera votre prochaine tâche.
Conseil
Vous pouvez ajouter un commentaire dans un module en double-cliquant sur ce module, puis en saisissant du texte. Ceci peut vous aider à voir d'un seul coup d'œil ce que fait chaque module dans votre expérience. Dans ce cas, double-cliquez sur le module Modifier les métadonnées et tapez le commentaire « Ajouter des en-têtes de colonne ». Cliquez n’importe où sur le canevas pour fermer la zone de texte. Pour afficher le commentaire, cliquez sur la flèche vers le bas sur le module.
Sélectionnez Modifier les métadonnées, puis, dans le panneau Propriétés à droite du canevas, cliquez sur Lancer le sélecteur de colonne.
Dans la boîte de dialogue Sélectionner les colonnes, sélectionnez toutes les lignes des Colonnes disponibles puis cliquez sur > pour les déplacer vers les Colonnes sélectionnées. La boîte de dialogue doit ressembler à ceci :
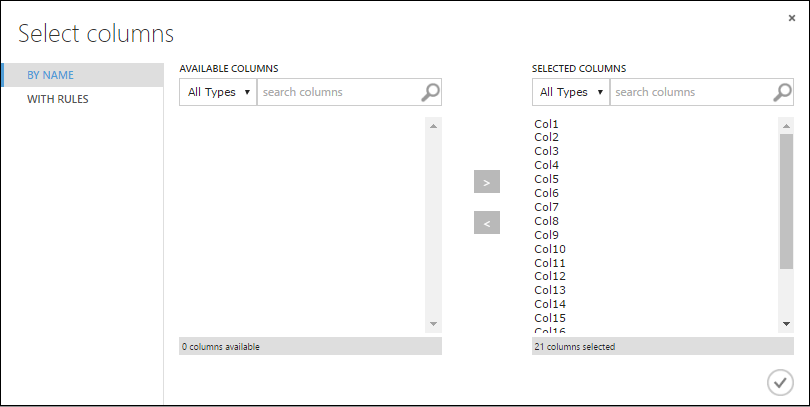
Cliquez sur la coche OK.
Dans le panneau Propriétés, recherchez le paramètre Nouveaux noms de colonne. Dans ce champ, entrez une liste de noms pour les 21 colonnes du jeu de données, séparés par des virgules et dans l’ordre de la colonne. Vous pouvez obtenir le nom des colonnes dans la documentation du jeu de données sur le site web UCI ou, par commodité, vous pouvez copier et coller la liste suivante :
Status of checking account, Duration in months, Credit history, Purpose, Credit amount, Savings account/bond, Present employment since, Installment rate in percentage of disposable income, Personal status and sex, Other debtors, Present residence since, Property, Age in years, Other installment plans, Housing, Number of existing credits, Job, Number of people providing maintenance for, Telephone, Foreign worker, Credit riskLe volet Propriétés ressemble à ceci :
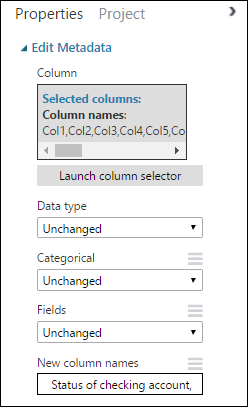
Conseil
Si vous souhaitez vérifier les en-têtes de colonne, exécutez l’expérience (cliquez sur EXÉCUTER sous le canevas d’expérience). À la fin de l’exécution (une coche verte s’affiche sur Modifier les métadonnées), cliquez sur le port de sortie du module Modifier les métadonnées et sélectionnez Visualiser. Vous pouvez voir la sortie de tous les modules en procédant de même pour afficher la progression des données dans l'expérience.
Création de jeux de données d'apprentissage et de test
Vous avez besoin de certaines données pour entraîner le modèle et d’autres pour le tester. Ainsi, lors de l’étape suivante de l’expérience, vous divisez le jeu de données en deux jeux de données distincts : un pour l’entraînement de votre modèle et l’autre pour le tester.
Pour ce faire, vous utilisez le module Fractionner les données.
Recherchez le module Fractionner les données, faites-le glisser sur le canevas et connectez-le au module Modifier les métadonnées.
Par défaut, le rapport de division est 0,5 et le paramètre Fractionnement aléatoire est défini. Cela signifie qu’une moitié aléatoire des données sort par un port du module Fractionner les données et l’autre moitié par l’autre port. Vous pouvez ajuster ces paramètres, de même que le paramètre Valeur de départ aléatoire, pour changer la répartition entre les données d’apprentissage et de test. Pour cet exemple, vous ne changez rien.
Conseil
La propriété Fraction de lignes dans le premier jeu de données de sortie détermine la quantité de données qui est sortie par le port de sortie gauche. Par exemple, si vous définissez le rapport sur 0,7, 70 % des données sont sorties par le port gauche et 30 % par le port droit.
Double-cliquez sur le module Fractionner les données et entrez le commentaire « Fractionnement des données de formation/test de 50 % ».
Vous pouvez utiliser les sorties du module Fractionner les données à votre gré, mais choisissons la sortie gauche comme données d’entraînement et la sortie droite comme données de test.
Comme indiqué lors de l’étape précédente, le coût d’une erreur consistant à classer un crédit à risque élevé comme étant à faible risque est cinq fois plus élevé que celui de l’erreur consistant à classer un crédit à faible risque comme étant à risque élevé. Pour tenir compte de cela, vous générez un nouveau jeu de données qui reflète cette fonction de coût. Dans le nouveau jeu de données, chaque exemple à haut risque est répliqué cinq fois, alors que les exemples à faible risque ne sont pas répliqués.
Vous pouvez procéder à la réplication en utilisant du code R :
Recherchez le module Exécuter un script R et faites-le glisser sur le canevas de l’expérience.
Connectez le port de sortie gauche du module Fractionner les données au premier port d’entrée (« Dataset 1 ») du module Exécuter un script R.
Double-cliquez sur le module Exécuter un script R et entrez le commentaire « Définir l’ajustement des coûts ».
Dans le volet Propriétés, supprimez le texte par défaut du paramètre Script R, puis entrez le script suivant :
dataset1 <- maml.mapInputPort(1) data.set<-dataset1[dataset1[,21]==1,] pos<-dataset1[dataset1[,21]==2,] for (i in 1:5) data.set<-rbind(data.set,pos) maml.mapOutputPort("data.set")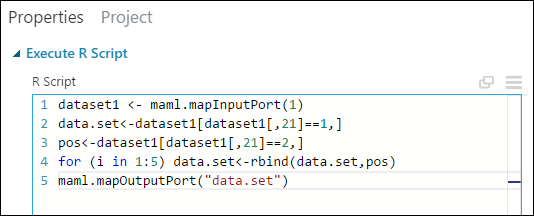
Vous devez répéter cette opération de réplication pour chaque sortie du module Fractionner les données afin que les données d’entraînement et de test aient le même ajustement des coûts. Pour ce faire, la manière la plus simple consiste à dupliquer le module Exécuter un script R que vous venez de créer et à le connecter à l’autre port de sortie du module Fractionner les données.
Cliquez avec le bouton droit sur le module Exécuter un script R et sélectionnez Copier.
Cliquez avec le bouton droit sur le canevas d'expérience et sélectionnez Coller.
Faites glisser le nouveau module pour le mettre en place, puis connectez le port de sortie droit du module Fractionner les données au premier port d’entrée du module Exécuter un script R.
En bas du canevas, cliquez sur Exécuter.
Conseil
La copie du Module d’exécution de script R contient le même script que le module d’origine. Lorsque vous copiez-collez un module sur le canevas, la copie conserve toutes les propriétés de l'original.
À ce stade, notre expérience ressemble à cela :
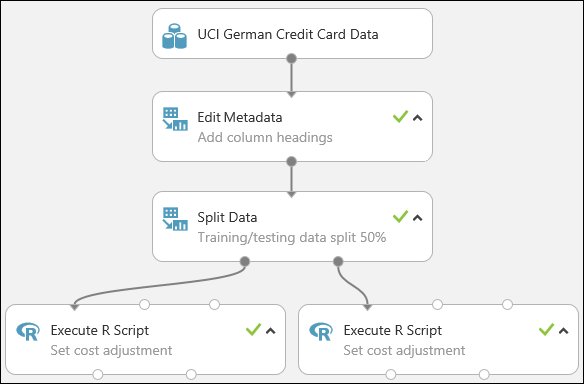
Pour plus d’informations sur l'utilisation de scripts R dans vos expériences, consultez la page Prolonger votre expérience avec R.
Nettoyer les ressources
Si vous n’avez plus besoin des ressources que vous avez créées dans le cadre de cet article, supprimez-les pour éviter des frais inutiles. Découvrez comment faire dans l’article Exporter et supprimer des données utilisateur intégrées dans le produit.
Étapes suivantes
Dans ce tutoriel, vous avez effectué les étapes suivantes :
- Créer un espace de travail Machine Learning Studio (classique)
- Charger des données existantes dans l’espace de travail
- Créer une expérience
Vous êtes maintenant prêt à entraîner et à évaluer des modèles pour ces données.