Suivre des expériences de Machine Learning Azure Databricks avec MLflow et Azure Machine Learning
MLflow est une bibliothèque open source permettant de gérer le cycle de vie de vos expériences de Machine Learning. Vous pouvez utiliser MLflow pour intégrer Azure Databricks à Azure Machine Learning afin de tirer le meilleur profit des deux produits.
Dans cet article, vous apprenez :
- Bibliothèques requises pour utiliser MLflow avec Azure Databricks et Azure Machine Learning.
- Découvrez comment Assurer le suivi des exécutions avec MLflow dans Azure Machine Learning.
- Comment journaliser des modèles avec MLflow pour les inscrire dans Azure Machine Learning.
- Comment déployer et utiliser des modèles inscrits dans Azure Machine Learning.
Prérequis
- Le package
azureml-mlflow, qui gère la connectivité avec Azure Machine Learning, y compris l’authentification. - Un cluster et un espace de travail Azure Databricks.
- Un espace de travail Azure Machine Learning.
Découvrez les autorisations d’accès nécessaires pour effectuer vos opérations MLflow avec votre espace de travail.
Exemples de notebooks
Le référentiel Entraîner des modèles dans Azure Databricks et les déployer sur Azure Machine Learning montre comment effectuer l’apprentissage de modèles dans Azure Databricks et les déployer dans Azure Machine Learning. Il explique également comment suivre les expériences et les modèles avec l’instance MLflow dans Azure Databricks. Il décrit comment utiliser Azure Machine Learning pour le déploiement.
Installation des bibliothèques
Pour installer des bibliothèques sur votre cluster :
Accédez à l’onglet Bibliothèques, puis sélectionnez Installer.
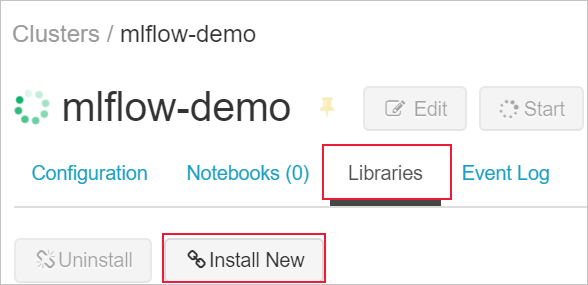
Dans le champ Package, entrez azureml-mlflow, puis sélectionnez Installer. Répétez cette étape si nécessaire afin d’installer d’autres packages sur votre cluster pour votre expérience.
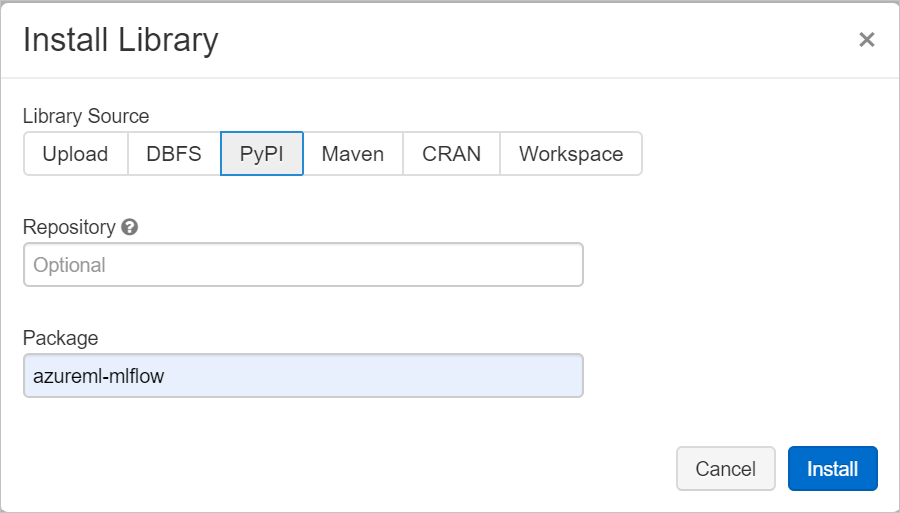
Suivre les exécutions Azure Databricks avec MLflow
Vous pouvez configurer Azure Databricks pour suivre les expériences avec MLflow de deux façons :
- Suivi dans votre espace de travail Azure Databricks et Azure Machine Learning (suivi double)
- Suivi exclusif sur Azure Machine Learning
Par défaut, lorsque vous liez votre espace de travail Azure Databricks, le double suivi est configuré pour vous.
Effectuer un double suivi sur Azure Databricks et Azure Machine Learning
Le fait de lier votre espace de travail Azure Databricks à votre espace de travail Azure Machine Learning vous permet de suivre vos données d’expérience dans l’espace de travail Azure Machine Learning et l’espace de travail Azure Databricks en même temps. Cette configuration est appelée le double suivi.
Le double suivi dans un espace de travail Azure Machine Learning avec liaison privée activée n’est actuellement pas pris en charge. Configurez un suivi exclusif avec votre espace de travail Azure Machine Learning à la place.
Le double suivi n’est actuellement pas pris en charge dans Microsoft Azure géré par 21Vianet. Configurez un suivi exclusif avec votre espace de travail Azure Machine Learning à la place.
Pour lier votre espace de travail Azure Databricks à un espace de travail Azure Machine Learning (nouveau ou existant) :
Connectez-vous au portail Azure.
Accédez à la page Vue d’ensemble de votre espace de travail Azure Databricks.
Sélectionnez Lier un espace de travail Azure Machine Learning.
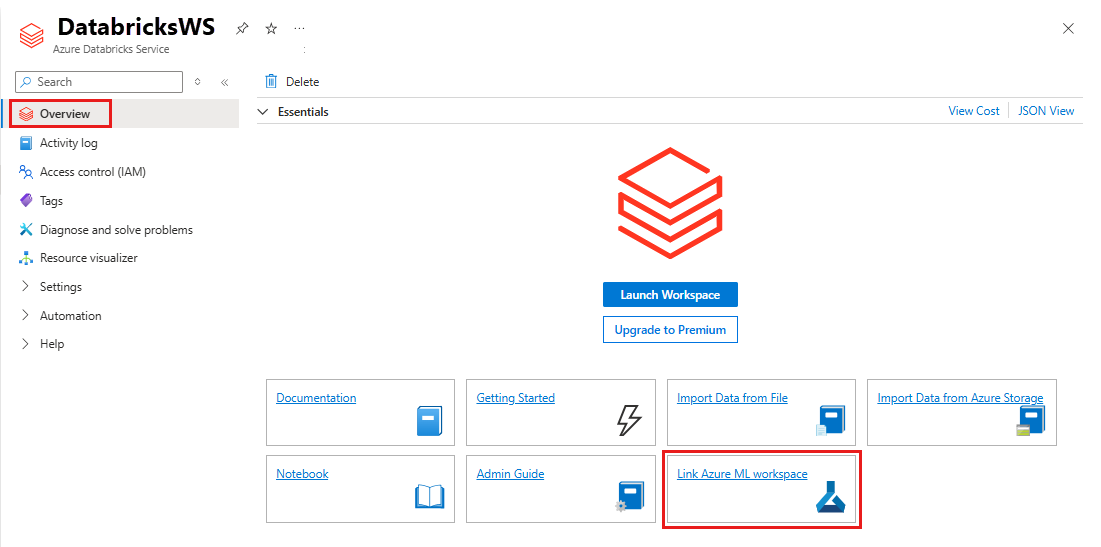

Une fois que vous avez lié votre espace de travail Azure Databricks à votre espace de travail Azure Machine Learning, le suivi MLflow est configuré pour s’effectuer automatiquement dans les emplacements suivants :
- L’espace de travail Azure Machine Learning lié.
- Votre espace de travail Azure Databricks d’origine.
Vous pouvez ensuite utiliser MLflow dans Azure Databricks comme à votre habitude. L’exemple suivant définit le nom de l’expérience comme d’habitude dans Azure Databricks et commence à journaliser certains paramètres.
import mlflow
experimentName = "/Users/{user_name}/{experiment_folder}/{experiment_name}"
mlflow.set_experiment(experimentName)
with mlflow.start_run():
mlflow.log_param('epochs', 20)
pass
Remarque
Contrairement au suivi, les registres de modèles ne prennent pas en charge l’inscription simultanée de modèles sur Azure Machine Learning et Azure Databricks. Pour plus d’informations, consultez Inscrire des modèles dans le registre avec MLflow.
Effectuer un suivi sur l’espace de travail Azure Machine Learning exclusivement
Si vous préférez gérer vos expériences suivies dans un emplacement centralisé, vous pouvez configurer MLflow Tracking pour effectuer le suivi uniquement dans votre espace de travail Azure Machine Learning. Cette configuration présente l’avantage de faciliter le déploiement à l’aide des options de déploiement d’Azure Machine Learning.
Avertissement
Pour un espace de travail Azure Machine Learning avec liaison privée, vous devez déployer Azure Databricks dans votre propre réseau (injection de réseau virtuel) pour garantir une connectivité appropriée.
Configurez l’URI de suivi MLflow pour qu’il pointe exclusivement vers Azure Machine Learning, comme illustré dans l’exemple suivant :
Configurer l’URI de suivi
Récupérez l’URI de suivi pour votre espace de travail.
S’APPLIQUE À :
 Extension ml Azure CLI v2 (actuelle)
Extension ml Azure CLI v2 (actuelle)Connectez-vous et configurez votre espace de travail.
az account set --subscription <subscription> az configure --defaults workspace=<workspace> group=<resource-group> location=<location>Vous pouvez obtenir l’URI de suivi à l’aide de la commande
az ml workspace.az ml workspace show --query mlflow_tracking_uri
Configurez l’URI de suivi.
La méthode
set_tracking_uri()pointe l’URI de suivi MLflow vers cet URI.import mlflow mlflow.set_tracking_uri(mlflow_tracking_uri)
Conseil
Lorsque vous travaillez avec des environnements partagés, comme un cluster Azure Databricks, un cluster Azure Synapse Analytics ou une alternative similaire, vous pouvez définir la variable d’environnement MLFLOW_TRACKING_URI au niveau du cluster. Cette approche vous permet de configurer automatiquement l’URI de suivi MLflow pour qu’il pointe vers Azure Machine Learning pour toutes les sessions qui s’exécutent dans le cluster plutôt que de le faire sur une base par session.
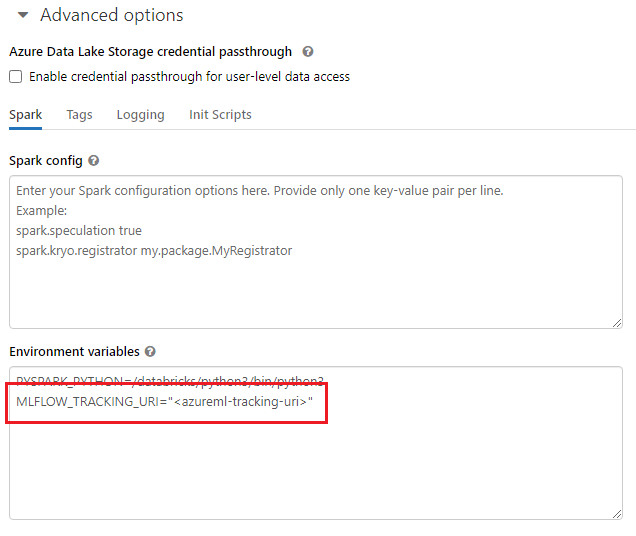
Après avoir configuré la variable d’environnement, toute expérience exécutée dans ce cluster est suivie dans Azure Machine Learning.
configurer l’authentification ;
Après avoir configuré le suivi, configurez comment s’authentifier auprès de l’espace de travail associé. Par défaut, le plug-in Azure Machine Learning pour MLflow ouvre un navigateur pour demander des informations d’identification de manière interactive. Pour connaître d’autres moyens de configurer l’authentification pour MLflow dans les espaces de travail Azure Machine Learning, consultez Configurer MLflow pour Azure Machine Learning : Configurer l’authentification.
Pour les travaux interactifs, quand un utilisateur est connecté à la session, vous pouvez vous appuyer sur l’authentification interactive. Dans ce cas, aucune action supplémentaire n’est requise.
Avertissement
L’authentification interactive par navigateur bloque l’exécution du code quand les informations d’identification sont demandées. Cette approche ne convient pas à l’authentification dans les environnements non surveillés, par exemple pour les travaux d’entraînement. Nous vous recommandons de configurer un mode d’authentification différent.
Pour les scénarios impliquant une exécution non surveillée, vous devez configurer un principal de service pour communiquer avec Azure Machine Learning.
import os
os.environ["AZURE_TENANT_ID"] = "<AZURE_TENANT_ID>"
os.environ["AZURE_CLIENT_ID"] = "<AZURE_CLIENT_ID>"
os.environ["AZURE_CLIENT_SECRET"] = "<AZURE_CLIENT_SECRET>"
Conseil
Quand vous travaillez sur des environnements partagés, il est recommandé de configurer ces variables d’environnement au niveau du calcul. Une meilleure pratique consiste à les gérer comme secrets dans une instance d’Azure Key Vault.
Par exemple, dans Azure Databricks, vous pouvez utiliser des secrets dans des variables d’environnement dans la configuration du cluster comme suit : AZURE_CLIENT_SECRET={{secrets/<scope-name>/<secret-name>}}. Pour plus d’informations sur l’implémentation de cette approche dans Azure Databricks, consultez Référencer un secret dans une variable d’environnement ou reportez-vous à la documentation de votre plateforme.
Nommer des expériences dans Azure Machine Learning
Lorsque vous configurez MLflow pour limiter le suivi des expériences à l’espace de travail Azure Machine Learning, la convention d’affectation de nom d’expérience doit suivre celle utilisée par Azure Machine Learning. Dans Azure Databricks, les expériences sont nommées selon le chemin d’accès à l’emplacement où l’expérience est enregistrée, par exemple /Users/alice@contoso.com/iris-classifier. En revanche, dans Azure Machine Learning, vous fournissez directement le nom de l’expérience. La même expérience serait nommée iris-classifier directement.
mlflow.set_experiment(experiment_name="experiment-name")
Effectuer un suivi des paramètres, métriques et artefacts
Une fois la configuration terminée, vous pouvez utiliser MLflow dans Azure Databricks comme à votre habitude. Pour plus d’informations, consultez Journaliser et afficher les métriques et les fichiers journaux.
Journaliser des modèles avec MLflow
Au terme de l’apprentissage de votre modèle, vous pouvez le consigner sur le serveur de suivi à l’aide de la méthode mlflow.<model_flavor>.log_model(). <model_flavor> fait référence au framework associé au modèle. Découvrez les versions du modèle prises en charge.
L’exemple suivant illustre l’inscription d’un modèle créé avec la bibliothèque Spark MLLib.
mlflow.spark.log_model(model, artifact_path = "model")
La saveur spark ne correspond pas au fait que vous entraînez un modèle dans un cluster Spark. Au lieu de cela, elle résulte de l’infrastructure de formation utilisée. Vous pouvez entraîner un modèle à l’aide de TensorFlow avec Spark. La saveur à utiliser serait tensorflow.
Les modèles sont consignés au sein de l’exécution qui fait l’objet du suivi. Ce fait signifie que les modèles sont disponibles à la fois dans Azure Databricks et Azure Machine Learning (par défaut), ou exclusivement dans Azure Machine Learning si vous avez configuré l’URI de suivi pour qu’il pointe vers celui-ci.
Important
Le paramètre registered_model_name n’a pas été spécifié. Pour plus d’informations sur ce paramètre et sur le registre, consultez Inscrire des modèles dans le registre à l’aide de MLflow.
Inscrire des modèles dans le registre à l’aide de MLflow
Contrairement au suivi, les registres de modèles ne peuvent pas fonctionner en même temps dans Azure Databricks et Azure Machine Learning. Ils doivent utiliser l’un ou l’autre. Par défaut, les registres de modèles utilisent l’espace de travail Azure Databricks. Si vous choisissez de configurer le suivi MLflow pour qu’il s’effectue uniquement dans votre espace de travail Azure Machine Learning, le registre de modèles est l’espace de travail Azure Machine Learning.
Si vous utilisez la configuration par défaut, le code suivant consigne un modèle dans les exécutions correspondantes d’Azure Databricks et d’Azure Machine Learning, mais il l’inscrit uniquement sur Azure Databricks.
mlflow.spark.log_model(model, artifact_path = "model",
registered_model_name = 'model_name')
- S’il n’existe pas de modèle inscrit sous ce nom, la méthode en inscrit un nouveau, crée la version 1, puis retourne un objet MLflow
ModelVersion. - S'il existe déjà un modèle inscrit sous ce nom, la méthode crée une nouvelle version du modèle et renvoie l'objet version.
Utiliser le registre Azure Machine Learning avec MLflow
Si vous souhaitez utiliser le registre de modèles Azure Machine Learning au lieu d’Azure Databricks, nous vous recommandons de configurer le suivi MLflow pour qu’il s’effectue uniquement dans votre espace de travail Azure Machine Learning. Cette approche supprime l’ambiguïté de l’emplacement d’inscription des modèles et simplifie la configuration.
Si vous souhaitez continuer à utiliser les fonctionnalités de double suivi mais inscrire des modèles dans Azure Machine Learning, vous pouvez demander à MLflow d’utiliser Azure Machine Learning pour les registres de modèles en configurant l’URI du registre de modèles MLflow. Cet URI a le même format et la même valeur que le MLflow qui suit l’URI.
mlflow.set_registry_uri(azureml_mlflow_uri)
Remarque
La valeur de azureml_mlflow_uri a été obtenue comme indiqué dans Configurer le suivi MLflow pour qu’il s’effectue uniquement dans votre espace de travail Azure Machine Learning.
Pour obtenir un exemple complet de ce scénario, consultez Entraîner des modèles dans Azure Databricks et les déployer sur Azure Machine Learning.
Déployer et utiliser des modèles inscrits dans Azure Machine Learning
Les modèles inscrits dans Azure Machine Learning Service à l’aide de MLflow peuvent être utilisés comme suit :
- Point de terminaison Azure Machine Learning (temps réel et traitement par lots). Ce déploiement vous permet d’utiliser des fonctionnalités de déploiement Azure Machine Learning pour l’inférence en temps réel et par lots dans Azure Container Instances, Azure Kubernetes ou les points de terminaison d’inférence managés.
- Objets de modèle MLflow ou fonctions Pandas définies par l’utilisateur (UDF), qui peuvent être utilisés dans des notebooks Azure Databricks dans les pipelines de diffusion en continu ou de traitement par lots.
Déployer des modèles sur des points de terminaison Azure Machine Learning
Vous pouvez utiliser le plug-in azureml-mlflow pour déployer un modèle dans votre espace de travail Azure Machine Learning. Pour plus d’informations sur le déploiement de modèles sur les différentes cibles, consultez Comment déployer des modèles MLflow.
Important
Pour pouvoir déployer des modèles, ceux-ci doivent être inscrits dans le registre Azure Machine Learning. Si vos modèles sont inscrits dans l’instance MLflow dans Azure Databricks, inscrivez-les à nouveau dans Azure Machine Learning. Pour plus d’informations, consultez Entraîner des modèles dans Azure Databricks et les déployer sur Azure Machine Learning
Déployer des modèles sur Azure Databricks pour le scoring par lots à l’aide de fonctions définies par l’utilisateur
Vous pouvez choisir des clusters Azure Databricks pour le scoring par lot. En utilisant MLflow, vous pouvez résoudre n’importe quel modèle à partir du registre auquel vous êtes connecté. Vous utiliserez généralement l’une des méthodes suivantes :
- Si votre modèle a été entraîné et généré avec des bibliothèques Spark comme
MLLib, utilisezmlflow.pyfunc.spark_udfpour charger un modèle et l’utiliser comme UDF Pandas Spark pour effectuer un scoring des nouvelles données. - Si votre modèle n’a pas été entraîné ou généré avec des bibliothèques Spark, utilisez
mlflow.pyfunc.load_modeloumlflow.<flavor>.load_modelpour charger le modèle dans le pilote de cluster. Vous devez orchestrer toute parallélisation ou distribution professionnelle que vous souhaitez effectuer dans le cluster. MLflow n’installe aucune bibliothèque dont votre modèle a besoin pour s’exécuter. Ces bibliothèques doivent être installées dans le cluster avant de l’exécuter.
L’exemple suivant montre comment charger un modèle à partir du Registre nommé uci-heart-classifier et l’utiliser comme fonction UDF Spark Pandas pour noter de nouvelles données.
from pyspark.sql.types import ArrayType, FloatType
model_name = "uci-heart-classifier"
model_uri = "models:/"+model_name+"/latest"
#Create a Spark UDF for the MLFlow model
pyfunc_udf = mlflow.pyfunc.spark_udf(spark, model_uri)
Pour obtenir d’autres façons de référencer des modèles à partir du registre, consultez Chargement de modèles à partir du registre.
Une fois le modèle chargé, vous pouvez utiliser cette commande pour effectuer un scoring de nouvelles données.
#Load Scoring Data into Spark Dataframe
scoreDf = spark.table({table_name}).where({required_conditions})
#Make Prediction
preds = (scoreDf
.withColumn('target_column_name', pyfunc_udf('Input_column1', 'Input_column2', ' Input_column3', …))
)
display(preds)
Nettoyer les ressources
Si vous souhaitez conserver votre espace de travail Azure Databricks, mais que vous n’avez plus besoin de l’espace de travail Azure Machine Learning, vous pouvez supprimer l’espace de travail Azure Machine Learning. Cette action entraîne la dissociation de votre espace de travail Azure Databricks et de l’espace de travail Azure Machine Learning.
Si vous ne prévoyez pas d’utiliser les métriques et les artefacts journalisés dans votre espace de travail, supprimez le groupe de ressources qui contient le compte de stockage et l’espace de travail.
- Dans le portail Azure, recherchez Groupes de ressources. Sous Services, sélectionnez Groupes de ressources.
- Dans la liste des groupes de ressources, recherchez et sélectionnez le groupe de ressources que vous avez créé pour l’ouvrir.
- Dans la page Vue d’ensemble, sélectionnez Supprimer le groupe de ressources.
- Pour vérifier la suppression, entrez le nom du groupe de ressources.