Microsoft Entra Connect Sync : comprendre l’architecture
Cette rubrique traite de l’architecture de base de Microsoft Entra Connect Sync. Si vous connaissez les technologies de synchronisation des identités antérieures, le contenu de cette rubrique vous sera également familier. Si vous ne connaissez pas la synchronisation, cette rubrique est pour vous. Il n’est toutefois pas nécessaire de connaître les détails de cette rubrique pour effectuer des personnalisations de Microsoft Entra Connect Sync (appelé « moteur de synchronisation » dans cette rubrique).
Architecture
Le moteur de synchronisation crée une vue intégrée des objets qui sont stockés dans plusieurs sources de données connectées et gère les informations d’identité dans ces dernières. Cette vue intégrée est déterminée par les informations d’identité, issues de sources de données connectées, et un ensemble de règles qui déterminent la manière de traiter ces informations.
Sources de données connectées et connecteurs
Le moteur de synchronisation traite les informations d’identité à partir de différents référentiels de données tels qu’Active Directory ou une base de données SQL Server. Chaque référentiel de données qui organise ses données dans un format de type base de données et qui fournit des méthodes d’accès aux données standard est une source de données potentielle pour le moteur de synchronisation. Les référentiels de données qui sont synchronisés par le moteur de synchronisation sont appelés sources de données connectées ou annuaires connectés.
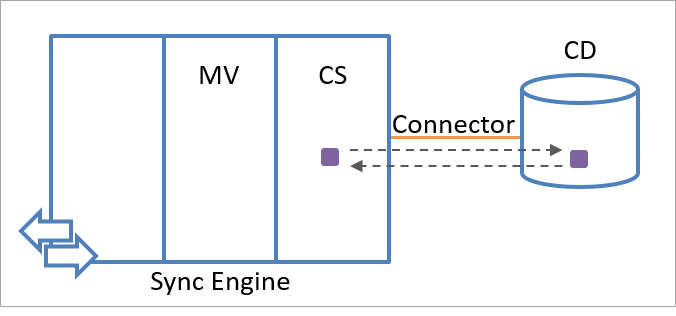
Le moteur de synchronisation encapsule l’interaction avec une source de données connectée au sein d’un module appelé connecteur. À chaque type de source de données connectée correspond un connecteur spécifique. Le connecteur traduit une opération requise dans un format que la source de données connectée peut comprendre.
Les connecteurs effectuent des appels d’API pour échanger des informations d’identité (en lecture et en écriture) avec une source de données connectée. Il est également possible d’ajouter un connecteur personnalisé à l’aide de l’infrastructure de connectivité extensible. L’illustration suivante indique comment un connecteur relie une source de données connectée au moteur de synchronisation.
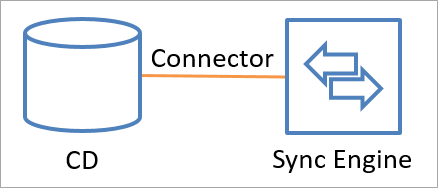
Les données peuvent circuler dans les deux sens, mais pas simultanément. En d’autres termes, un connecteur peut être configuré pour autoriser les données à circuler de la source de données connectée au moteur de synchronisation ou du moteur de synchronisation à la source de données connectée, mais il est uniquement possible d’effectuer l’une de ces opérations à la fois pour un objet et un attribut. La direction peut être différente pour divers objets et attributs.
Pour configurer un connecteur, vous spécifiez les types d’objets que vous souhaitez synchroniser. Le fait de spécifier les types d’objet permet d’avoir une vue globale sur les objets qui sont inclus dans le processus de synchronisation. L’étape suivante consiste à sélectionner les attributs à synchroniser dans une liste, connue sous le nom de liste d’inclusion d’attributs. Ces paramètres peuvent être modifiés à tout moment suite aux modifications apportées aux règles d’entreprise. Ces paramètres sont configurés pour vous lorsque vous utilisez l’assistant d’installation de Microsoft Entra Connect.
Pour exporter des objets vers une source de données connectée, la liste d’inclusion d’attributs doit inclure au moins le nombre minimal d’attributs requis pour créer un type d’objet spécifique dans une source de données connectée. Par exemple, l’attribut sAMAccountName doit être inclus dans la liste d’inclusion d’attributs pour exporter un objet utilisateur dans Active Directory. En effet, un attribut sAMAccountName doit être défini pour tous les objets utilisateur dans Active Directory. Là encore, l’assistant d’installation effectue cette configuration pour vous.
Si la source de données connectée utilise des composants structurels, tels que des partitions ou des conteneurs, pour organiser les objets, vous pouvez limiter les zones de la source de données connectée qui sont utilisées pour une solution donnée.
Structure interne de l’espace de noms du moteur de synchronisation
La totalité de l’espace de noms du moteur de synchronisation se compose de deux espaces de noms, qui stockent les informations d’identité. Ces deux espaces sont les suivants :
- L’espace connecteur
- Le métaverse (MV)
L’ espace connecteur est une zone de transit contenant les représentations des objets désignés à partir d’une source de données connectée, ainsi que des attributs spécifiés dans la liste d’inclusion d’attributs. Le moteur de synchronisation utilise l’espace connecteur pour identifier les éléments modifiés dans la source de données connectée et pour préparer les modifications entrantes. Le moteur de synchronisation utilise également l’espace connecteur pour préparer les modifications sortantes à des fins d’exportation vers la source de données connectée. Le moteur de synchronisation gère un espace connecteur distinct en tant que zone de transit pour chaque connecteur.
Grâce à la zone de transit, le moteur de synchronisation reste indépendant des sources de données connectées et n’est pas affecté par leur disponibilité et leur accessibilité. Par conséquent, vous pouvez traiter les informations d’identité à tout moment en utilisant les données de la zone de transit. Le moteur de synchronisation peut uniquement demander les modifications apportées à l’intérieur de la source de données connectée depuis l’arrêt de la dernière session de communication, ou émettre uniquement les modifications apportées aux informations d’identité que la source de données connectée n’a pas encore reçues, ce qui réduit le trafic réseau entre le moteur de synchronisation et la source de données connectée.
En outre, le moteur de synchronisation stocke les informations d’état sur tous les objets qu’il prépare dans l’espace connecteur. Lors de la réception de nouvelles données, le moteur de synchronisation évalue toujours si celles-ci ont déjà été synchronisées.
Le métaverse est une zone de stockage qui contient les informations d’identité agrégées à partir de plusieurs sources de données connectées, fournissant ainsi une vue globale et intégrée unique de tous les objets combinés. Les objets métaverse sont créés sur la base des informations d’identité récupérées à partir de sources de données connectées et d’un ensemble de règles qui vous permettent de personnaliser le processus de synchronisation.
L’illustration suivante représente l’espace de noms de l’espace connecteur ainsi que l’espace de noms du métaverse dans le moteur de synchronisation.
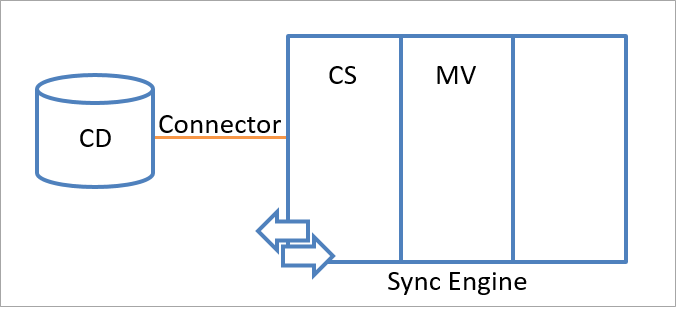
Objets d’identité du moteur de synchronisation
Les objets du moteur de synchronisation sont des représentations des objets dans la source de données connectée, ou de la vue intégrée de ces objets dont dispose le moteur de synchronisation. Chaque objet du moteur de synchronisation doit avoir un GUID. Les GUID garantissent l’intégrité des données et expriment les relations entre les objets.
Objets de l’espace connecteur
Lorsque le moteur de synchronisation communique avec une source de données connectée, il lit les informations d’identité dans cette dernière et utilise ces informations pour créer une représentation de l’objet d’identité dans l’espace connecteur. Il est impossible de créer ou de supprimer ces objets individuellement. Cependant, vous pouvez supprimer manuellement tous les objets dans un espace connecteur.
Tous les objets de l’espace connecteur présentent deux attributs :
- Un GUID
- Un nom unique
Si la source de données connectée affecte un attribut unique à l’objet, les objets de l’espace connecteur peuvent également présenter un attribut d’ancre. L’attribut d’ancre identifie un objet de manière unique dans la source de données connectée. Le moteur de synchronisation utilise l’ancre pour localiser la représentation correspondante de cet objet dans la source de données connectée. Le moteur de synchronisation suppose que l’ancre d’un objet ne change jamais pendant toute la durée de vie de l’objet.
Plusieurs connecteurs utilisent un identificateur unique connu pour générer automatiquement une ancre pour chaque objet lors de son importation. Par exemple, le connecteur Active Directory utilise l’attribut objectGUID à titre d’ancre. Pour les sources de données connectées qui ne fournissent pas un identificateur unique clairement défini, vous pouvez spécifier la génération d’une ancre dans le cadre de la configuration du connecteur.
Dans ce cas, l’ancre est construite à partir d’un ou de plusieurs attributs uniques d’un type d’objet. Aucun de ces derniers n’est modifié, ce qui permet d’identifier l’objet de manière unique dans l’espace connecteur (par exemple, un numéro d’employé ou un ID d’utilisateur).
Un objet d’espace connecteur peut être :
- Un objet intermédiaire
- Un espace réservé
Objets intermédiaires
Un objet intermédiaire représente une instance des types d’objet désignés de la source de données connectée. Outre le GUID et le nom unique, un objet intermédiaire présente toujours une valeur qui indique le type d’objet.
Les objets intermédiaires importés présentent toujours une valeur pour l’attribut d’ancre. Les objets intermédiaires récemment configurés par le moteur de synchronisation et en cours de création dans la source de données connectée ne présentent aucune valeur pour l’attribut d’ancre.
Les objets intermédiaires comportent aussi des valeurs actuelles pour les attributs d’entreprise ainsi que des informations opérationnelles nécessaires au moteur pour exécuter le processus de synchronisation. Les informations opérationnelles comprennent des indicateurs qui désignent le type des mises à jour préparées sur l’objet intermédiaire. Si un objet intermédiaire a reçu de nouvelles informations d’identité, qui proviennent de la source de données connectée et qui n’ont pas encore été traitées, l’objet est marqué d’un indicateur « Importation en attente». Si un objet intermédiaire contient de nouvelles informations d’identité qui n’ont pas encore été exportées vers la source de données connectée, l’objet est marqué d’un indicateur « En attente d’exportation » .
Un objet intermédiaire peut être un objet d’importation ou d’exportation. Le moteur de synchronisation crée un objet d’importation à l’aide des informations relatives aux objets envoyées par la source de données connectée. Lorsque le moteur de synchronisation reçoit des informations sur l’existence d’un nouvel objet qui correspond à l’un des types d’objet sélectionnés dans le connecteur, il crée un objet d’importation dans l’espace connecteur en tant que représentation de l’objet dans la source de données connectée.
L’illustration suivante montre un objet d’importation représentant un objet dans la source de données connectée.

Le moteur de synchronisation crée un objet d’exportation à l’aide des informations relatives aux objets dans le métaverse. Les objets d’exportation sont exportés vers la source de données connectée lors de la session de communication suivante. Du point de vue du moteur de synchronisation, les objets d’exportation n’existent pas encore dans la source de données connectée. Par conséquent, l’attribut d’ancre d’un objet d’exportation n’est pas disponible. Après avoir reçu l’objet du moteur de synchronisation, la source de données connectée crée une valeur unique pour l’attribut d’ancre de l’objet.
L’illustration suivante illustre la création d’un objet d’exportation à l’aide des informations d’identité dans le métaverse.
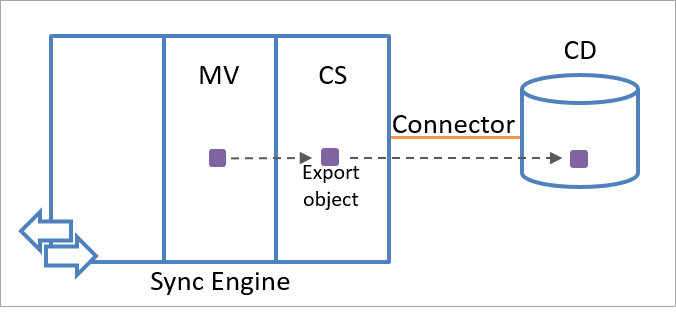
Le moteur de synchronisation confirme l’exportation de l’objet en le réimportant depuis la source de données connectée. Les objets d’exportation deviennent des objets d’importation lorsque le moteur de synchronisation les reçoit à la prochaine importation depuis cette source de données connectée.
Espaces réservés
Le moteur de synchronisation utilise un espace de noms plat pour stocker des objets. Toutefois, certaines sources de données connectées, telles qu’Active Directory, utilisent un espace de noms hiérarchique. Pour transformer les informations d’un espace de noms hiérarchique dans un espace de noms plat, le moteur de synchronisation utilise des espaces réservés, afin de conserver la hiérarchie.
Chaque espace réservé représente un composant (par exemple, une unité d’organisation) d’un nom hiérarchique d’objet qui n’a pas été importé dans le moteur de synchronisation, mais qui est requis pour construire le nom hiérarchique. Ces éléments comblent les vides créés par des références, dans la source de données connectée, à des objets qui ne sont pas des objets intermédiaires dans l’espace connecteur.
Le moteur de synchronisation utilise également des espaces réservés pour stocker les objets référencés qui n’ont pas encore été importés. Par exemple, si la synchronisation est configurée pour inclure l’attribut manager pour l’objet Abbie Spencer et si la valeur reçue est un objet qui n’a pas été importé, tel que CN=Lee Sperry,CN=Users,DC=fabrikam,DC=com, les informations de l’élément manager sont stockées en tant qu’espaces réservés dans l’espace connecteur. Si l’objet manager est ensuite importé, l’objet de l’espace réservé est remplacé par l’objet intermédiaire qui représente le gestionnaire.
Objets métaverse
Un objet métaverse contient la vue agrégée dont dispose le moteur de synchronisation sur les objets intermédiaires dans l’espace connecteur. Le moteur de synchronisation crée des objets métaverse à l’aide des informations contenues dans les objets importés. Plusieurs objets CS (Connector Space) peuvent être liés à un objet métaverse unique, mais un objet CS (Connector Space) ne peut pas être lié à plusieurs objets métaverse.
Les objets métaverse ne peuvent pas être créés ou supprimés manuellement. Le moteur de synchronisation supprime automatiquement les objets métaverse qui n’ont pas de lien vers un objet d’espace connecteur quelconque dans l’espace connecteur.
Pour mapper des objets dans une source de données connectée vers un type d’objet correspondant dans le métaverse, le moteur de synchronisation fournit un schéma extensible avec un ensemble prédéfini de types d’objets et attributs associés. Vous pouvez créer des attributs et des types d’objets pour les objets métaverse. Les attributs peuvent être à valeur unique ou à plusieurs valeurs et les types d’attribut peuvent correspondre à des chaînes, des références, des chiffres et des valeurs booléennes.
Relations entre les objets intermédiaires et les objets métaverse
Dans l’espace de noms du moteur de synchronisation, le flux de données est activé par la relation entre les objets intermédiaires et les objets métaverse. Un objet intermédiaire lié à un objet métaverse est appelé objet joint (ou objet connecteur). Un objet intermédiaire non lié à un objet métaverse est appelé objet disjoint (ou objet déconnecteur). L’utilisation des termes « joint » et « disjoint » est préférable, afin de ne pas les confondre avec les connecteurs responsables de l’importation et de l’exportation de données à partir d’un annuaire connecté.
Les espaces réservés ne sont jamais liés à un objet métaverse
Un objet joint comprend un objet intermédiaire et sa relation liée à un objet métaverse unique. Les objets joints sont utilisés pour synchroniser les valeurs d’attribut entre un objet CS (Connector Space) et un objet métaverse.
Lorsqu’un objet intermédiaire devient un objet joint au cours de la synchronisation, les attributs peuvent circuler entre l’objet intermédiaire et l’objet métaverse. Le flux d’attributs est bidirectionnel ; il est configuré à l’aide de règles d’attribut d’importation et d’exportation.
Un objet CS (Connector Space) unique peut être lié à un seul objet métaverse. Toutefois, chaque objet métaverse peut être lié à plusieurs objets CS (Connector Space) dans le même espace connecteur ou dans des espaces connecteur différents, comme indiqué dans l’illustration suivante.
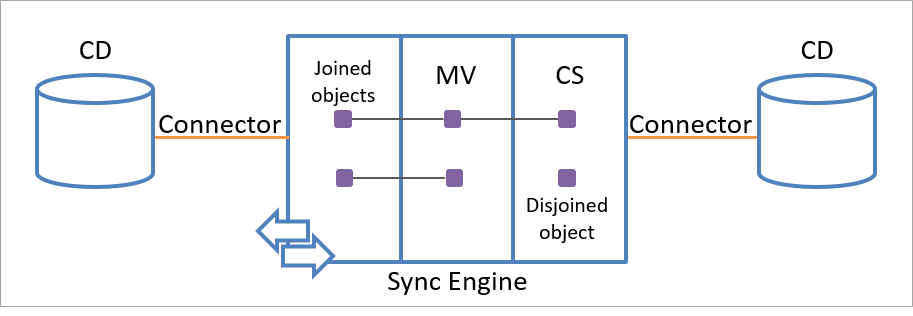
La relation entre l’objet intermédiaire et un objet métaverse est persistante et ne peut être supprimée que par les règles que vous spécifiez.
Un objet disjoint est un objet intermédiaire non lié à un objet métaverse. Les valeurs d’attribut d’un objet disjoint ne sont pas traitées davantage dans le métaverse. Les valeurs d’attribut de l’objet correspondant dans la source de données connectée ne sont pas mises à jour par le moteur de synchronisation.
À l’aide des objets disjoints, vous pouvez stocker des informations d’identité dans le moteur de synchronisation et les traiter ultérieurement. Le fait de conserver un objet intermédiaire sous forme d’objet disjoint dans l’espace connecteur présente de nombreux avantages. Étant donné que le système a déjà préparé les informations requises concernant cet objet, il n’est pas nécessaire de créer une représentation de ce dernier lors de l’importation suivante à partir de la source de données connectée. De cette façon, le moteur de synchronisation a toujours un aperçu complet de la source de données connectée, même s’il n’existe aucune connexion active à la source de données connectée. Les objets disjoints peuvent être convertis en objets joints (et vice versa) en fonction des règles que vous spécifiez.
Un objet d’importation est créé en tant qu’objet disjoint. Un objet d’exportation doit être un objet joint. La logique du système applique cette règle et supprime chaque objet d’exportation qui n’est pas un objet joint.
Processus de gestion des identités du moteur de synchronisation
Le processus de gestion des identités détermine de quelle manière les informations d’identité sont mises à jour entre les différentes sources de données connectées. La gestion des identités s’effectue en trois phases :
- Importer
- Synchronization
- Exporter
Pendant le processus d’importation, le moteur de synchronisation évalue les informations d’identité entrantes à partir d’une source de données connectée. Lorsque des modifications sont détectées, il crée des objets intermédiaires ou met à jour les objets intermédiaires existants dans l’espace connecteur, à des fins de synchronisation.
Pendant le processus de synchronisation, le moteur de synchronisation met à jour le métaverse afin de refléter les modifications qui se sont produites dans l’espace connecteur, actualisant l’espace connecteur pour refléter les modifications apportées dans le métaverse.
Pendant le processus d’exportation, le moteur de synchronisation envoie les modifications préparées sur les objets intermédiaires et marquées d’un indicateur signalant l’attente d’une exportation.
L’illustration suivante montre où chaque processus se produit lorsque les informations d’identité circulent d’une source de données à une autre.

Processus d’importation
Lors du processus d’importation, le moteur de synchronisation évalue les mises à jour des informations d’identité. Le moteur de synchronisation compare les informations d’identité provenant de la source de données connectée avec celles d’un objet intermédiaire et détermine si l’objet intermédiaire nécessite des mises à jour. S’il est nécessaire de mettre à jour l’objet intermédiaire avec les nouvelles données, ce dernier est marqué d’un indicateur signalant une attente d’importation.
En configurant avec étape intermédiaire les objets dans l’espace connecteur avant la synchronisation, le moteur de synchronisation peut traiter uniquement les informations d’identité qui ont changé. Ce processus permet de bénéficier des avantages suivants :
- Une synchronisation efficace. La quantité de données traitées pendant la synchronisation est réduite au minimum.
- Une resynchronisation efficace. Vous pouvez modifier le mode de traitement des informations d’identité par le moteur de synchronisation sans reconnecter la source de données à ce dernier.
- La possibilité d’afficher un aperçu de la synchronisation. Vous pouvez afficher un aperçu de la synchronisation pour vérifier que vos hypothèses sur le processus de gestion d’identité sont correctes.
Pour chaque objet spécifié dans le connecteur, le moteur de synchronisation essaie tout d’abord de localiser une représentation de l’objet dans l’espace connecteur du connecteur. Le moteur de synchronisation examine tous les objets intermédiaires dans l’espace connecteur et tente de trouver un objet intermédiaire qui possède un attribut d’ancre correspondant. Si aucun objet intermédiaire existant ne présente d’attribut d’ancre correspondant, le moteur de synchronisation essaie de trouver un objet intermédiaire correspondant portant le même nom unique.
Lorsque le moteur de synchronisation détecte un objet intermédiaire dont le nom unique correspond, mais non l’ancre, il adopte le comportement spécifique suivant :
- Si l’objet situé dans l’espace connecteur n’a aucune ancre, le moteur de synchronisation supprime cet objet de l’espace connecteur et indique sur l’objet métaverse avec lequel il est lié le message suivant : « refaire une tentative d’approvisionnement lors de l’exécution de la synchronisation suivante». Il crée ensuite un objet d’importation.
- Si l’objet situé dans l’espace connecteur a une ancre, le moteur de synchronisation suppose que cet objet a été renommé ou supprimé dans l’annuaire connecté. Il assigne un nouveau nom unique temporaire à l’objet CS (Connector Space) afin de pouvoir préparer l’objet entrant. L’ancien objet devient alors temporaire; il attend que le connecteur importe l’objet renommé ou supprimé pour résoudre le problème.
Les objets temporaires ne sont pas toujours un problème, et vous pouvez les voir même dans un environnement sain. Avec l’API de point de terminaison pour Microsoft Entra Connect Sync V2, les objets temporaires doivent être résolus automatiquement lors des cycles de synchronisation delta suivants. Un exemple courant dans lequel vous pouvez trouver des objets temporaires en cours de génération se produit sur les serveurs Microsoft Entra Connect installés en mode intermédiaire, lorsqu’un administrateur supprime définitivement un objet directement dans Microsoft Entra ID à l’aide de PowerShell, puis synchronise à nouveau l’objet plus tard.
Si le moteur de synchronisation localise un objet intermédiaire qui correspond aux objets spécifiés dans le connecteur, il détermine le type de modifications à appliquer. Le moteur de synchronisation peut, par exemple, renommer ou supprimer l’objet dans la source de données connectée, ou seulement mettre à jour les valeurs d’attribut de l’objet.
Les objets intermédiaires avec des données mises à jour sont marqués comme étant en attente d’importation. Plusieurs types d’importation en attente sont disponibles. Selon le résultat du processus d’importation, un objet intermédiaire dans l’espace connecteur présente l’un des types d’importations en attente suivants :
- Aucun. Aucune modification des attributs de l’objet intermédiaire n’est disponible. Le moteur de synchronisation ne marque pas ce type d’un indicateur d’attente d’importation.
- Ajouter. L’objet intermédiaire est un nouvel objet d’importation dans l’espace connecteur. Le moteur de synchronisation marque ce type d’un indicateur d’attente d’importation à des fins de traitement supplémentaire dans le métaverse.
- Mettre à jour. Le moteur de synchronisation recherche un objet intermédiaire correspondant dans l’espace connecteur et marque ce type d’un indicateur d’attente d’importation, afin que les mises à jour des attributs puissent être traitées dans le métaverse. Les mises à jour comprennent la modification des noms d’objets.
- Supprimer. Le moteur de synchronisation recherche un objet intermédiaire correspondant dans l’espace connecteur et marque ce type d’un indicateur d’attente d’importation afin de pouvoir supprimer l’objet joint.
- Supprimer/Ajouter. Le moteur de synchronisation recherche un objet intermédiaire correspondant dans l’espace connecteur, mais les types d’objet ne correspondent pas. Dans ce cas, une modification de type suppression-ajout est préparée. Une modification de type suppression-ajout indique au moteur de synchronisation qu’une resynchronisation complète de cet objet doit être effectuée, car un ensemble de règles différentes est appliqué à cet objet lorsque le type de ce dernier change.
En définissant un objet intermédiaire comme étant en attente d’importation, vous pouvez réduire considérablement la quantité de données traitées pendant la synchronisation. Cela permet au système de traiter uniquement les objets dont les données sont mises à jour.
Processus de synchronisation
La synchronisation consiste en deux processus connexes :
- la synchronisation entrante, lorsque le contenu du métaverse est mis à jour via les données de l’espace connecteur ;
- la synchronisation sortante, lorsque le contenu de l’espace connecteur est mis à jour à l’aide des données du métaverse.
En utilisant les informations préparées dans l’espace connecteur, le processus de synchronisation entrante crée, dans le métaverse, une vue intégrée des données stockées dans les sources de données connectées. Tous les objets intermédiaires, ou ceux qui sont en attente d’importation seulement, sont regroupés, selon le mode de configuration des règles.
Le processus de synchronisation sortante met à jour les objets d’exportation lorsque les objets métaverse sont modifiés.
La synchronisation entrante crée, dans le métaverse, la vue intégrée des informations d’identité provenant des sources de données connectées. Le moteur de synchronisation peut traiter les informations d’identité à tout moment, en utilisant les dernières informations d’identité qu’il a reçues de la source de données connectée.
Synchronisation entrante
La synchronisation entrante comprend les processus suivants :
- Configuration (également appelée Projection s’il s’avère nécessaire de distinguer ce processus de l’approvisionnement de synchronisation sortante). Le moteur de synchronisation crée un objet métaverse basé sur un objet intermédiaire et les lie l’un à l’autre. La configuration est une opération de niveau objet.
- Jointure. Le moteur de synchronisation lie un objet intermédiaire à un objet de métaverse existant. L’opération de jointure s’effectue au niveau de l’objet.
- Flux d’attributs d’importation. Le moteur de synchronisation met à jour les valeurs d’attribut de l’objet, appelées flux de valeur d’attribut, dans le métaverse. Le flux de valeur d’attribut d’importation est une opération au niveau de l’attribut, qui nécessite un lien entre un objet intermédiaire et un objet de métaverse.
La configuration est le seul processus qui crée des objets dans le métaverse. La configuration affecte uniquement les objets d’importation qui correspondent à des objets disjoints. Pendant la configuration, le moteur de synchronisation crée un objet métaverse qui correspond au type de l’objet d’importation et établit un lien entre les deux objets, créant ainsi un objet joint.
Le processus de jointure établit également un lien entre des objets d’importation et un objet métaverse. Il existe une différence entre la jointure et l’approvisionnement : le processus de jointure nécessite que l’objet d’importation soit lié à un objet métaverse existant, tandis que le processus d’approvisionnement crée un objet métaverse.
Le moteur de synchronisation tente de joindre un objet d’importation à un objet métaverse à l’aide des critères spécifiés dans la configuration de la règle de synchronisation.
Durant les processus d’approvisionnement et de jointure, le moteur de synchronisation lie un objet disjoint à un objet métaverse, les joignant. Une fois ces opérations de niveau objet terminées, le moteur de synchronisation peut mettre à jour les valeurs d’attribut de l’objet métaverse associé. Ce processus est appelé flux de valeur d’attribut d’importation.
Le flux de valeur d’attribut d’importation se produit sur tous les objets d’importation qui comportent de nouvelles données et sont liés à un objet métaverse.
Synchronisation sortante
La synchronisation sortante met à jour les objets d’exportation lorsqu’un objet métaverse est modifié sans être supprimé. L’objectif de la synchronisation sortante consiste à évaluer si les modifications apportées aux objets métaverse nécessitent des mises à jour des objets intermédiaires dans les espaces connecteur. Dans certains cas, les modifications peuvent exiger que les objets intermédiaires dans tous les espaces connecteur soient mis à jour. Les objets intermédiaires modifiés sont marqués d’un indicateur d’attente d’exportation, ce qui fait d’eux des objets d’exportation. Ces objets d’exportation sont ensuite transmis à la source de données connectée pendant le processus d’exportation.
La synchronisation sortante s’effectue en trois phases :
- Approvisionnement
- Annulation de l’approvisionnement
- Flux de valeur d’attribut d’exportation.
L’approvisionnement et l’annulation de l’approvisionnement sont des opérations de niveau objet. L’annulation de l’approvisionnement est fonction de l’approvisionnement, car ce dernier est le seul à pouvoir l’initier. L’annulation est déclenchée lorsque l’approvisionnement supprime le lien entre un objet métaverse et un objet d’exportation.
L’approvisionnement se déclenche toujours lorsque des modifications sont appliquées aux objets dans le métaverse. Lorsque des modifications sont apportées aux objets métaverse, le moteur de synchronisation peut effectuer les tâches suivantes dans le cadre du processus d’approvisionnement :
- La création d’objets joints, lors de laquelle un objet métaverse est lié à un objet d’exportation nouvellement créé.
- Le changement de nom d’un objet joint.
- La séparation des liens entre un objet métaverse et des objets intermédiaires, créant un objet disjoint.
Si l’approvisionnement nécessite que le moteur de synchronisation crée un objet connecteur, l’objet intermédiaire auquel est lié l’objet métaverse est toujours un objet d’exportation, car l’objet n’existe pas encore dans la source de données connectée.
Si l’approvisionnement nécessite que le moteur de synchronisation sépare un objet joint, créant un objet disjoint, l’annulation de l’approvisionnement est déclenchée. Ce processus d’annulation supprime l’objet.
Lors de cette annulation, la suppression d’un objet d’exportation ne supprime pas physiquement l’objet. L’objet est marqué d’un indicateur supprimé, ce qui signifie que l’opération de suppression est préparée sur l’objet.
Le flux de valeur d’attribut d’exportation se produit également lors du processus de synchronisation sortante, de la même manière que le flux de valeur d’attribut d’importation se produit pendant la synchronisation entrante. Le flux de valeur d’attribut d’exportation se produit uniquement entre les objets métaverse et les objets d’exportation qui sont joints.
Processus d’exportation
Pendant le processus d’exportation, le moteur de synchronisation examine tous les objets d’exportation qui sont marqués d’un indicateur d’attente d’exportation dans l’espace connecteur, puis envoie des mises à jour à la source de données connectée.
Le moteur de synchronisation peut indiquer la réussite d’une exportation, mais ne peut pas déterminer avec précision si le processus de gestion des identités est terminé. Les objets de la source de données connectée peuvent toujours être modifiés par d’autres processus. Étant donné que le moteur de synchronisation ne dispose pas d’une connexion permanente à la source de données connectée, il ne suffit pas d’émettre des hypothèses sur les propriétés d’un objet dans la source de données connectée sur la seule base d’une notification d’exportation réussie.
Par exemple, un processus dans la source de données connectée peut basculer les attributs de l’objet vers leurs valeurs d’origine (autrement dit, la source de données connectée peut remplacer les valeurs immédiatement après l’envoi des données par le moteur de synchronisation et leur application réussie dans la source de données connectée).
Le moteur de synchronisation stocke les informations d’état de l’exportation et de l’importation de chaque objet intermédiaire. Si les valeurs des attributs indiqués dans la liste d’inclusion d’attributs ont changé depuis la dernière exportation, le stockage des informations d’état de l’exportation et de l’importation permet au moteur de synchronisation de réagir en conséquence. Le moteur de synchronisation utilise le processus d’importation pour vérifier les valeurs d’attribut qui ont été exportées vers la source de données connectée. Une comparaison entre les informations importées et exportées, comme indiqué dans l’illustration suivante, permet au moteur de synchronisation de déterminer si l’exportation a réussi ou si elle doit être répétée.
Par exemple, si le moteur de synchronisation exporte l’attribut C, qui a la valeur 5, vers une source de données connectée, il stocke la valeur C=5 dans sa mémoire de statut d’exportation. Chaque exportation supplémentaire de cet objet entraîne une nouvelle tentative d’exportation de la valeur C=5 vers la source de données connectée, car le moteur de synchronisation suppose que cette valeur n’a pas été appliquée à l’objet de manière continue (sauf si une valeur différente a été importée récemment à partir de la source de données connectée). La mémoire d’exportation est désactivée en cas de réception de la valeur C=5 au cours d’une opération d’importation sur l’objet.
Étapes suivantes
Apprenez-en davantage sur la configuration de Microsoft Entra Connect Sync.
Explorez plus en détail l’Intégration de vos identités locales avec Microsoft Entra ID.