Événements
Créer des applications et des agents IA
17 mars, 21 h - 21 mars, 10 h
Rejoignez la série de rencontres pour créer des solutions IA évolutives basées sur des cas d’usage réels avec d’autres développeurs et experts.
S’inscrire maintenantCe navigateur n’est plus pris en charge.
Effectuez une mise à niveau vers Microsoft Edge pour tirer parti des dernières fonctionnalités, des mises à jour de sécurité et du support technique.
Cet article vous montre comment configurer Azure Monitor Application Insights pour Java.
Pour plus d’informations, consultez Prise en main d’OpenTelemetry qui inclut des exemples d’applications.
La chaîne de connexion et le nom de rôle sont les paramètres les plus courants dont vous avez besoin pour commencer :
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
}
}
La chaîne de connexion est obligatoire. Le nom de rôle est important chaque fois que vous envoyez des données de différentes applications à la même ressource Application Insights.
Vous trouverez plus d’informations et d’options de configuration dans les sections suivantes.
Par défaut, Application Insights Java 3 s'attend à ce que le fichier de configuration soit nommé applicationinsights.json et situé dans le même répertoire que applicationinsights-agent-3.7.0.jar.
Vous pouvez spécifier un fichier config personnalisé avec
Si vous fournissez un chemin relatif, il sera résolu par rapport au répertoire où se trouve applicationinsights-agent-3.7.0.jar.
Au lieu d’utiliser un fichier config, vous pouvez définir la configuration JSON complète avec :
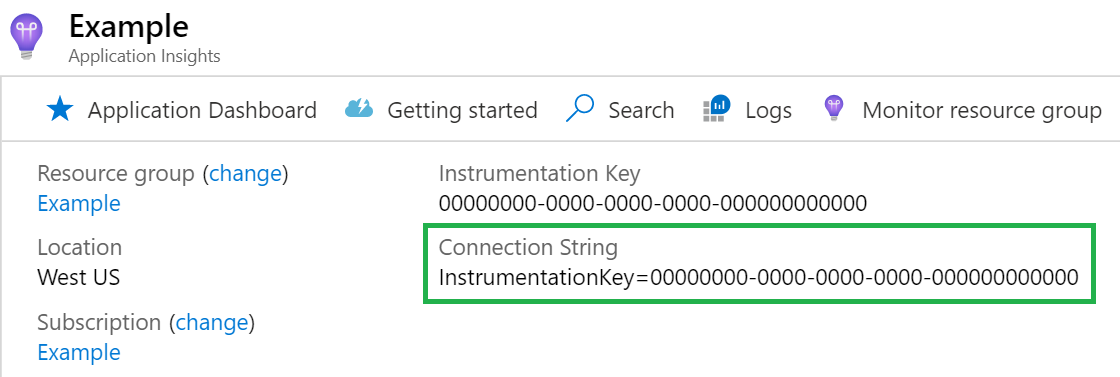
La chaîne de connexion est obligatoire. Vous pouvez trouver votre chaîne de connexion dans votre ressource Application Insights.
{
"connectionString": "..."
}
Vous pouvez également définir la chaîne de connexion en utilisant la variable d’environnement APPLICATIONINSIGHTS_CONNECTION_STRING. Elle est alors prioritaire sur la chaîne de connexion spécifiée dans la configuration JSON.
Vous pouvez également définir la chaîne de connexion à l’aide de la propriété système Java applicationinsights.connection.string. Elle est également prioritaire sur la chaîne de connexion spécifiée dans la configuration JSON.
Vous pouvez également définir la chaîne de connexion en spécifiant un fichier à partir duquel charger la chaîne de connexion.
Si vous spécifiez un chemin relatif, il est résolu par rapport au répertoire où se trouve applicationinsights-agent-3.7.0.jar.
{
"connectionString": "${file:connection-string-file.txt}"
}
Le fichier doit contenir uniquement la chaîne de connexion et rien d’autre.
Si vous ne définissez pas la chaîne de connexion, l’agent Java est désactivé.
Si vous avez déployé plusieurs applications dans la même Machine Virtuelle Java (JVM) et que vous souhaitez qu’elles envoient des données de télémétrie à différentes chaînes de connexion, consultez Remplacements de chaînes de connexion (préversion).
Le nom du rôle cloud est utilisé pour étiqueter le composant sur la cartographie d’application.
Si vous souhaitez définir le nom du rôle cloud :
{
"role": {
"name": "my cloud role name"
}
}
Si le nom du rôle cloud n’est pas défini, le nom de la ressource Application Insights est utilisé pour étiqueter le composant sur la cartographie d’application.
Vous pouvez également définir le nom de rôle cloud à l’aide de la variable d’environnement APPLICATIONINSIGHTS_ROLE_NAME. Il est alors prioritaire sur le nom du rôle cloud spécifié dans la configuration JSON.
Vous pouvez également définir le nom du rôle cloud en utilisant la propriété système Java applicationinsights.role.name. Il est également prioritaire sur le nom du rôle cloud spécifié dans la configuration JSON.
Si vous avez déployé plusieurs applications dans la même machine virtuelle JVM et que vous souhaitez qu’elles envoient des données de télémétrie à différents noms de rôles cloud, consultez Remplacements de noms de rôle cloud (préversion).
Par défaut, l’instance de rôle cloud correspond au nom de la machine.
Si vous souhaitez définir l'instance de rôle cloud sur autre chose que le nom de la machine :
{
"role": {
"name": "my cloud role name",
"instance": "my cloud role instance"
}
}
Vous pouvez également définir l’instance de rôle cloud en utilisant la variable d’environnement APPLICATIONINSIGHTS_ROLE_INSTANCE. Elle est alors prioritaire sur l’instance de rôle cloud spécifiée dans la configuration JSON.
Vous pouvez également définir l’instance de rôle cloud en utilisant la propriété système Java applicationinsights.role.instance.
Elle est également prioritaire sur l’instance de rôle cloud spécifiée dans la configuration JSON.
Notes
L’échantillonnage peut être un excellent moyen de réduire le coût d’Application Insights. Veillez à paramétrer votre configuration d’échantillonnage de manière appropriée pour votre cas d’usage.
L’échantillonnage est basé sur la demande, ce qui signifie que si une demande est capturée (échantillonnée), c’est aussi le cas de ses dépendances, journaux et exceptions.
L’échantillonnage est également basé sur l’ID de trace pour garantir des décisions d’échantillonnage cohérentes entre différents services.
L’échantillonnage ne s’applique qu’aux journaux dans une requête. Les journaux qui ne sont pas à l’intérieur d’une requête (par exemple, les journaux de démarrage) sont toujours collectés par défaut. Si vous souhaitez échantillonner ces journaux, vous pouvez utiliser des remplacements d’échantillonnage.
À partir de la version 3.4.0, l’échantillonnage à fréquence limitée est disponible et constitue désormais le réglage par défaut.
Si aucun échantillonnage n’a été configuré, l’échantillonnage par défaut est désormais limité par taux configuré pour capturer au maximum de (environ) cinq requêtes par seconde, ainsi que l’ensemble des dépendances et journaux sur ces requêtes.
Cette configuration remplace la valeur par défaut précédente qui capturait toutes les demandes. Si vous souhaitez toujours capturer toutes les demandes, utilisez l’échantillonnage à pourcentage fixe et définissez le pourcentage d’échantillonnage sur 100.
Notes
L’échantillonnage à fréquence limitée est approximatif, car en interne, il doit adapter un pourcentage d’échantillonnage « fixe » au fil du temps pour émettre des nombres d’éléments précis sur chaque enregistrement de télémétrie. En interne, l’échantillonnage à fréquence limitée est réglé pour s’adapter rapidement (0,1 seconde) aux nouvelles charges d’application. Vous ne devriez donc pas le voir dépasser la fréquence configurée de beaucoup ou pendant très longtemps.
Cet exemple montre comment définir l’échantillonnage pour capturer au maximum (environ) une demande par seconde :
{
"sampling": {
"requestsPerSecond": 1.0
}
}
Notez que requestsPerSecond peut être une décimale, de sorte que vous pouvez le configurer pour capturer moins d’une requête par seconde si vous le souhaitez. Par exemple, une valeur de 0.5 signifie une capture d’au moins une requête toutes les 2 secondes.
Vous pouvez également définir le pourcentage d’échantillonnage en utilisant la variable d’environnement APPLICATIONINSIGHTS_SAMPLING_REQUESTS_PER_SECOND. Il est alors prioritaire sur la limite de fréquence spécifiée dans la configuration JSON.
Cet exemple montre comment définir l’échantillonnage pour capturer environ un tiers de toutes les demandes :
{
"sampling": {
"percentage": 33.333
}
}
Vous pouvez également définir le pourcentage d’échantillonnage en utilisant la variable d’environnement APPLICATIONINSIGHTS_SAMPLING_PERCENTAGE. Il est alors prioritaire sur le pourcentage d’échantillonnage spécifié dans la configuration JSON.
Notes
Pour le pourcentage d’échantillonnage, choisissez un pourcentage proche de 100/N, où N est un nombre entier. L’échantillonnage ne prend actuellement en charge aucune autre valeur.
Les remplacements d’échantillonnage vous permettent de remplacer le pourcentage d’échantillonnage par défaut. Par exemple, vous pouvez :
/login même si l’échantillonnage par défaut est configuré sur un niveau inférieur.Pour plus d’informations, consultez la documentation Remplacements d’échantillonnage.
Si vous souhaitez collecter d’autres métriques Java Management Extensions (JMX) :
{
"jmxMetrics": [
{
"name": "JVM uptime (millis)",
"objectName": "java.lang:type=Runtime",
"attribute": "Uptime"
},
{
"name": "MetaSpace Used",
"objectName": "java.lang:type=MemoryPool,name=Metaspace",
"attribute": "Usage.used"
}
]
}
Dans l’exemple de configuration précédent :
name est le nom attribué à cette métrique JMX (peut être un nom quelconque).objectName est le Nom d’objet du JMX MBean que vous souhaitez collecter. Le caractère générique astérisque (*) est pris en charge.attribute est le nom d’attribut à l’intérieur du JMX MBean que vous souhaitez collecter.Les valeurs de métrique JMX numériques et booléennes sont prises en charge. Les métriques JMX booléennes sont mappées à 0 pour false et à 1 pour true.
Pour obtenir plus d’informations, consultez la documentation Métriques JMX.
Si vous souhaitez ajouter des dimensions personnalisées à toute votre télémétrie :
{
"customDimensions": {
"mytag": "my value",
"anothertag": "${ANOTHER_VALUE}"
}
}
Vous pouvez utiliser ${...} pour lire la valeur de la variable d’environnement spécifiée au démarrage.
Notes
À partir de la version 3.0.2, si vous ajoutez une dimension personnalisée nommée service.version, la valeur est stockée dans la colonne application_Version de la table des journaux Application Insights plutôt que sous forme de dimension personnalisée.
À compter de la version 3.2.0, vous pouvez définir une dimension personnalisée par programmation sur vos données de télémétrie de requête. Cela garantit l’héritage par dépendance et la télémétrie des journaux. Tous sont capturés dans le contexte de cette requête.
{
"preview": {
"inheritedAttributes": [
{
"key": "mycustomer",
"type": "string"
}
]
}
}
Ensuite, au début de chaque requête, appelez :
Span.current().setAttribute("mycustomer", "xyz");
Consultez également : Ajouter une propriété personnalisée à une étendue.
Cette fonctionnalité est en préversion, à partir de la version 3.4.0.
Les remplacements de chaîne de connexion vous permettent de remplacer la chaîne de connexion par défaut. Par exemple, vous pouvez :
/myapp1./myapp2/.{
"preview": {
"connectionStringOverrides": [
{
"httpPathPrefix": "/myapp1",
"connectionString": "..."
},
{
"httpPathPrefix": "/myapp2",
"connectionString": "..."
}
]
}
}
Cette fonctionnalité est en préversion, à partir de 3.3.0.
Les remplacements de noms de rôle cloud vous permettent de remplacer le nom de rôle cloud par défaut. Par exemple, vous pouvez :
/myapp1./myapp2/.{
"preview": {
"roleNameOverrides": [
{
"httpPathPrefix": "/myapp1",
"roleName": "Role A"
},
{
"httpPathPrefix": "/myapp2",
"roleName": "Role B"
}
]
}
}
À partir de la version 3.4.8, si vous avez besoin de la possibilité de configurer la chaîne de connexion au moment de l’exécution, ajoutez cette propriété à votre configuration json :
{
"connectionStringConfiguredAtRuntime": true
}
Ajoutez applicationinsights-core à votre application :
<dependency>
<groupId>com.microsoft.azure</groupId>
<artifactId>applicationinsights-core</artifactId>
<version>3.7.0</version>
</dependency>
Utilisez la méthode statique configure(String) dans la classe com.microsoft.applicationinsights.connectionstring.ConnectionString.
Notes
Toutes les données de télémétrie capturées avant la configuration de la chaîne de connexion seront supprimées. Il est donc préférable de les configurer le plus tôt possible au démarrage de votre application.
À partir de la version 3.2.0, si vous souhaitez capturer les dépendances « InProc » du contrôleur, utilisez la configuration suivante :
{
"preview": {
"captureControllerSpans": true
}
}
Cette fonctionnalité injecte automatiquement le Chargeur de kit de développement logiciel (SDK) du navigateur dans les pages HTML de votre application, notamment en configurant la chaîne de connexion appropriée.
Par exemple, lorsque votre application Java retourne une réponse telle que :
<!DOCTYPE html>
<html lang="en">
<head>
<title>Title</title>
</head>
<body>
</body>
</html>
Cela modifie automatiquement le retour :
<!DOCTYPE html>
<html lang="en">
<head>
<script type="text/javascript">
!function(v,y,T){var S=v.location,k="script"
<!-- Removed for brevity -->
connectionString: "YOUR_CONNECTION_STRING"
<!-- Removed for brevity --> }});
</script>
<title>Title</title>
</head>
<body>
</body>
</html>
Le script vise à aider les clients à suivre les données de l’utilisateur web et à renvoyer les données de télémétrie côté serveur collectées aux Portail Azure des utilisateurs. Pour obtenir plus d’informations, consultez ApplicationInsights-JS.
Si vous souhaitez activer cette fonctionnalité, ajoutez l’option de configuration ci-dessous :
{
"preview": {
"browserSdkLoader": {
"enabled": true
}
}
}
Vous pouvez utiliser des processeurs de télémétrie pour configurer des règles destinées à être appliquées à la télémétrie des demandes, des dépendances et des traces. Par exemple, vous pouvez :
Pour plus d’informations, consultez la documentation Processeur de télémétrie.
Notes
Si vous souhaitez annuler des étendues spécifiques (entières) pour contrôler le coût d’ingestion, consultez Remplacements d’échantillonnage.
À partir de la version 3.3.1, vous pouvez capturer des étendues pour une méthode dans votre application :
{
"preview": {
"customInstrumentation": [
{
"className": "my.package.MyClass",
"methodName": "myMethod"
}
]
}
}
Par défaut, lorsque le pourcentage d’échantillonnage effectif dans l’agent Java est de 100 % et que l’échantillonnage d’ingestion a été configuré sur votre ressource Application Insights, le pourcentage d’échantillonnage d’ingestion est appliqué.
Notez que ce comportement s’applique à la fois à l’échantillonnage à fréquence fixe de 100 % et à l’échantillonnage à fréquence limitée lorsque le débit de la demande n’excède pas la limite de débit (capture efficace de 100 % pendant la fenêtre de temps glissante continue).
À partir de la version 3.5.3, vous pouvez désactiver ce comportement (et conserver 100 % des données de télémétrie dans ces cas même lorsque l’échantillonnage d’ingestion a été configuré sur votre ressource Application Insights) :
{
"preview": {
"sampling": {
"ingestionSamplingEnabled": false
}
}
}
Log4j, Logback, JBoss Logging et java.util.logging sont instrumentés automatiquement. La journalisation effectuée via ces frameworks de journalisation est collectée automatiquement.
La journalisation est capturée uniquement si elle :
Par exemple, si votre framework de journalisation est configuré (comme décrit précédemment) pour journaliser WARN à partir du package com.example et qu’Application Insights est configuré (comme décrit) pour capturer INFO, Application Insights capture uniquement WARN (et versions plus sévères) à partir du package com.example.
Le niveau par défaut configuré pour Application Insights est INFO. Si vous souhaitez modifier ce seuil :
{
"instrumentation": {
"logging": {
"level": "WARN"
}
}
}
Vous pouvez également définir le niveau avec la variable d’environnement APPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_LEVEL. Il est alors prioritaire sur le niveau spécifié dans la configuration JSON.
Vous pouvez utiliser ces valeurs level valides dans le fichier applicationinsights.json. Le tableau montre les niveaux de journalisation équivalents dans différents frameworks de journalisation.
| Level | Log4j | Logback | JBoss | JUL |
|---|---|---|---|---|
| OFF | OFF | OFF | OFF | OFF |
| FATAL | FATAL | ERROR | FATAL | SEVERE |
| ERROR (ou SEVERE) | ERROR | ERROR | ERROR | SEVERE |
| WARN (ou WARNING) | WARN | WARN | WARN | WARNING |
| INFO | INFO | INFO | INFO | INFO |
| CONFIG | DEBUG | DEBUG | DEBUG | CONFIG |
| DEBUG (ou FINE) | DEBUG | DEBUG | DEBUG | FINE |
| FINER | DEBUG | DEBUG | DEBUG | FINER |
| TRACE (ou FINEST) | TRACE | TRACE | TRACE | FINEST |
| ALL | ALL | ALL | ALL | ALL |
Notes
Si un objet d’exception est transmis à l’enregistreur d’événements, le message de journal (et les détails de l’objet d’exception) s’affiche dans le portail Azure dans la table exceptions au lieu de la table traces. Si vous souhaitez voir les messages de journal dans les deux tables (traces et exceptions), vous pouvez écrire une requête Logs (Kusto) pour les unir. Par exemple :
union traces, (exceptions | extend message = outerMessage)
| project timestamp, message, itemType
À partir de la version 3.4.2, vous pouvez capturer les marqueurs de journal pour Logback et Log4j 2 :
{
"preview": {
"captureLogbackMarker": true,
"captureLog4jMarker": true
}
}
À partir de la version 3.4.3, vous pouvez capturer FileName, ClassName, MethodName et LineNumber pour Logback :
{
"preview": {
"captureLogbackCodeAttributes": true
}
}
Avertissement
La capture d’attributs de code peut ajouter une surcharge de performances.
À partir de la version 3.3.0, LoggingLevel n’est pas capturé par défaut dans le cadre de la dimension personnalisée Traces, car ces données sont déjà capturées dans le champ SeverityLevel.
Si nécessaire, vous pouvez provisoirement réactiver le comportement précédent :
{
"preview": {
"captureLoggingLevelAsCustomDimension": true
}
}
Si votre application utilise Micrometer, les métriques envoyées au registre global de Micrometer sont collectées automatiquement.
Par ailleurs, si votre application utilise Spring Boot Actuator, les métriques configurées par Spring Boot Actuator sont également collectées automatiquement.
Pour envoyer des métriques personnalisées à l'aide de Micrometer :
Ajoutez Micrometer à votre application web, comme illustré dans l’exemple suivant.
<dependency>
<groupId>io.micrometer</groupId>
<artifactId>micrometer-core</artifactId>
<version>1.6.1</version>
</dependency>
Utilisez le registre global de Micrometer pour créer un compteur comme illustré dans l’exemple suivant.
static final Counter counter = Metrics.counter("test.counter");
Utilisez le compteur pour enregistrer les métriques en utilisant la commande suivante.
counter.increment();
Les métriques sont ingérées dans la table customMetrics, avec des étiquettes capturées dans la colonne customDimensions. Vous pouvez également afficher les métriques dans Metrics Explorer sous l’espace de noms de métriques Log-based metrics.
Notes
Application Insights Java remplace, par des traits de soulignement, tous les caractères non alphanumériques (à l’exception des tirets) dans le nom de la métrique Micrometer. Par conséquent, la métrique test.counter précédente se présente comme suit : test_counter.
Pour désactiver la collection automatique des métriques de Micrometer et des métriques de Spring Boot Actuator :
Notes
Les métriques personnalisées sont facturées séparément et peuvent occasionner des coûts supplémentaires. Veillez à consulter les informations sur les tarifs. Pour désactiver les métriques de Micrometer et de Spring Boot Actuator, ajoutez la configuration suivante à votre fichier config.
{
"instrumentation": {
"micrometer": {
"enabled": false
}
}
}
Les valeurs littérales dans les requêtes Java Database Connectivity (JDBC) sont masquées par défaut pour éviter de capturer accidentellement des données sensibles.
À partir de la version 3.4.0, ce comportement peut être désactivé. Par exemple :
{
"instrumentation": {
"jdbc": {
"masking": {
"enabled": false
}
}
}
}
Les valeurs littérales dans les requêtes Mongo sont masquées par défaut pour éviter de capturer accidentellement des données sensibles.
À partir de la version 3.4.0, ce comportement peut être désactivé. Par exemple :
{
"instrumentation": {
"mongo": {
"masking": {
"enabled": false
}
}
}
}
À compter de la version 3.3.0, vous pouvez capturer les en-têtes de demande et de réponse sur la télémétrie de votre serveur (demande) :
{
"preview": {
"captureHttpServerHeaders": {
"requestHeaders": [
"My-Header-A"
],
"responseHeaders": [
"My-Header-B"
]
}
}
}
Le nom des en-têtes ne respecte pas la casse.
Les exemples précédents sont capturés sous les noms de propriété http.request.header.my_header_a et http.response.header.my_header_b.
De même, vous pouvez capturer les en-têtes de demande et de réponse sur la télémétrie du client (dépendance) :
{
"preview": {
"captureHttpClientHeaders": {
"requestHeaders": [
"My-Header-C"
],
"responseHeaders": [
"My-Header-D"
]
}
}
}
La encore, le nom des en-têtes ne respecte pas la casse. Les exemples précédents sont capturés sous les noms de propriété http.request.header.my_header_c et http.response.header.my_header_d.
Par défaut, les demandes de serveur HTTP qui génèrent des codes de réponse 4xx sont capturées sous forme d’erreurs.
À compter de la version 3.3.0, vous pouvez changer ce comportement pour les capturer en tant que réussites :
{
"preview": {
"captureHttpServer4xxAsError": false
}
}
À partir de la version 3.0.3, une télémétrie collectée automatiquement spécifique peut être supprimée en utilisant les options de configuration suivantes :
{
"instrumentation": {
"azureSdk": {
"enabled": false
},
"cassandra": {
"enabled": false
},
"jdbc": {
"enabled": false
},
"jms": {
"enabled": false
},
"kafka": {
"enabled": false
},
"logging": {
"enabled": false
},
"micrometer": {
"enabled": false
},
"mongo": {
"enabled": false
},
"quartz": {
"enabled": false
},
"rabbitmq": {
"enabled": false
},
"redis": {
"enabled": false
},
"springScheduling": {
"enabled": false
}
}
}
Vous pouvez également supprimer ces instrumentations à l’aide de ces variables d’environnement sur false :
APPLICATIONINSIGHTS_INSTRUMENTATION_AZURE_SDK_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_CASSANDRA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JDBC_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_JMS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_KAFKA_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_LOGGING_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MICROMETER_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_MONGO_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_RABBITMQ_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_REDIS_ENABLEDAPPLICATIONINSIGHTS_INSTRUMENTATION_SPRING_SCHEDULING_ENABLEDCes variables sont alors prioritaires sur les variables activées spécifiées dans la configuration JSON.
Notes
Si vous souhaitez un contrôle plus précis, par exemple pour supprimer, une partie mais pas la totalité des appels redis, consultez la rubrique Remplacements d’échantillonnage.
À partir de la version 3.2.0, vous pouvez activer les instrumentations en préversion suivantes :
{
"preview": {
"instrumentation": {
"akka": {
"enabled": true
},
"apacheCamel": {
"enabled": true
},
"grizzly": {
"enabled": true
},
"ktor": {
"enabled": true
},
"play": {
"enabled": true
},
"r2dbc": {
"enabled": true
},
"springIntegration": {
"enabled": true
},
"vertx": {
"enabled": true
}
}
}
}
Notes
L’instrumentation Akka est disponible à partir de la version 3.2.2. L’instrumentation de la bibliothèque HTTP Vertx est disponible à partir de la version 3.3.0.
Par défaut, les métriques sont capturées toutes les 60 secondes.
À partir de la version 3.0.3, vous pouvez modifier cet intervalle :
{
"metricIntervalSeconds": 300
}
À compte de la disponibilité générale de la version 3.4.9, vous pouvez aussi définir metricIntervalSeconds en utilisant la variable d’environnement APPLICATIONINSIGHTS_METRIC_INTERVAL_SECONDS. Elle est alors prioritaire sur le paramètre metricIntervalSeconds défini dans la configuration JSON.
Le paramètre s’applique aux métriques suivantes :
Par défaut, Application Insights Java 3.x envoie une métrique de pulsation toutes les 15 minutes. Si vous utilisez la métrique de pulsation pour déclencher des alertes, vous pouvez augmenter la fréquence de cette pulsation :
{
"heartbeat": {
"intervalSeconds": 60
}
}
Notes
Vous ne pouvez pas augmenter l’intervalle à plus de 15 minutes, car les données de pulsation sont également utilisées pour assurer le suivi de l’utilisation d’Application Insights.
Notes
La fonctionnalité d’authentification est en disponibilité générale (GA) depuis la version 3.4.17.
Vous pouvez utiliser l’authentification pour configurer l’agent afin de générer les informations d’identification de jeton requises pour l’authentification Microsoft Entra. Pour plus d’informations, consultez la documentation sur l’authentification.
Si votre application se trouve derrière un pare-feu et n’est pas en mesure de se connecter directement à Application Insights, consultezAdresses IP utilisées par Application Insights.
Pour contourner ce problème, vous pouvez configurer Application Insights Java 3.x pour utiliser un proxy HTTP.
{
"proxy": {
"host": "myproxy",
"port": 8080
}
}
Vous pouvez également définir le proxy http à l’aide de la variable d’environnement APPLICATIONINSIGHTS_PROXY, qui prend en charge le format https://<host>:<port>. Il est alors prioritaire sur le proxy spécifié dans la configuration JSON.
Vous pouvez fournir un utilisateur et un mot de passe pour votre proxy avec la APPLICATIONINSIGHTS_PROXYvariable d’environnement : https://<user>:<password>@<host>:<port>.
Application Insights Java 3.x respecte également les propriétés système https.proxyHost et https.proxyPort globales, si elles sont définies, et http.nonProxyHosts, le cas échéant.
Quand l’envoi d’une télémétrie au service Application Insights échoue, Application Insights Java 3.x stocke la télémétrie sur disque et continue à réessayer à partir du disque.
La limite par défaut pour la persistance de disque est de 50 Mo. Si vous avez un volume de télémétrie élevé ou que vous devez pouvoir récupérer à partir de pannes de service réseau ou d’ingestion plus longues, vous pouvez augmenter cette limite à partir de la version 3.3.0 :
{
"preview": {
"diskPersistenceMaxSizeMb": 50
}
}
La fonctionnalité « Autodiagnostics » fait référence à la journalisation interne à partir d’Application Insights Java 3.x. Elle permet de détecter et de diagnostiquer des problèmes liés à Application Insights.
Par défaut, Application Insights Java 3.x se connecte au niveau INFO au fichier applicationinsights.log et à la console, ce qui correspond à la configuration suivante :
{
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}
Dans l’exemple de configuration précédent :
level peut être OFF, ERROR, WARN, INFO, DEBUG ou TRACE.path peut être un chemin d’accès absolu ou relatif. Les chemins d’accès relatifs sont résolus par rapport au répertoire où se trouve le fichier applicationinsights-agent-3.7.0.jar.Depuis la version 3.0.2, vous pouvez également définir le level des autodiagnostics avec la variable d’environnement APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_LEVEL. Il est alors prioritaire sur le niveau des autodiagnostics spécifié dans la configuration JSON.
À partir de la version 3.0.3, vous pouvez également définir l’emplacement des fichiers d’autodiagnostic avec la variable d’environnement APPLICATIONINSIGHTS_SELF_DIAGNOSTICS_FILE_PATH. Il est alors prioritaire sur le chemin des fichiers d’autodiagnostic spécifié dans la configuration JSON.
La corrélation télémétrique est activée par défaut, mais vous pouvez la désactiver dans la configuration.
{
"preview": {
"disablePropagation": true
}
}
Cet exemple montre à quoi ressemble un fichier config avec plusieurs composants. Configurez des options spécifiques en fonction de vos besoins.
{
"connectionString": "...",
"role": {
"name": "my cloud role name"
},
"sampling": {
"percentage": 100
},
"jmxMetrics": [
],
"customDimensions": {
},
"instrumentation": {
"logging": {
"level": "INFO"
},
"micrometer": {
"enabled": true
}
},
"proxy": {
},
"preview": {
"processors": [
]
},
"selfDiagnostics": {
"destination": "file+console",
"level": "INFO",
"file": {
"path": "applicationinsights.log",
"maxSizeMb": 5,
"maxHistory": 1
}
}
}
Événements
Créer des applications et des agents IA
17 mars, 21 h - 21 mars, 10 h
Rejoignez la série de rencontres pour créer des solutions IA évolutives basées sur des cas d’usage réels avec d’autres développeurs et experts.
S’inscrire maintenantEntrainement
Parcours d’apprentissage
Use advance techniques in canvas apps to perform custom updates and optimization - Training
Use advance techniques in canvas apps to perform custom updates and optimization