Présentation du service Analyse d'images
Le service Analyse d’images de Azure AI Vision peut extraire un large éventail de caractéristiques visuelles à partir de vos images. Par exemple, il peut déterminer si une image contient du contenu pour adultes, identifier des marques ou des objets spécifiques, ou trouver des visages humains.
La dernière version d’Analyse d’image (4.0) qui est désormais en disponibilité générale, a de nouvelles fonctionnalités telles que la reconnaissance optique de caractères synchrones et la détection de personnes. Nous vous recommandons d'utiliser cette version.
Vous pouvez utiliser le service Analyse d'images via un kit SDK de bibliothèque de client ou en appelant directement l'REST API. Pour vous lancer, suivez le guide de démarrage rapide.
Ou vous pouvez essayer les fonctionnalités d’analyse d’image rapidement et facilement dans votre navigateur à l’aide de Vision Studio.
Cette documentation contient les types d’articles suivants :
- Les guides de démarrage rapide sont des instructions pas à pas qui vous permettent d’effectuer des appels au service et d’obtenir des résultats en peu de temps.
- Les guides patiques contiennent des instructions sur l’utilisation du service de manière plus spécifique ou personnalisée.
- Les articles conceptuels fournissent des explications approfondies sur les fonctions et fonctionnalités du service.
- Les tutoriels sont des guides plus longs qui montrent comment utiliser ce service en tant que composant dans des solutions métier plus larges.
Pour une approche plus structurée, suivez un module de formation pour l’analyse d’images.
Versions de l’analyse d’images
Important
Sélectionnez la version de l’API Analyse d’image qui correspond le mieux à vos besoins.
| Version | Fonctionnalités disponibles | Recommandation |
|---|---|---|
| version 4.0 | Lire du texte, Légendes, Légendes denses, Balises, Détection d’objets, Classification d’images/ détection d’objets personnalisées, Personnes, Rognage intelligent | De meilleurs modèles – utilisez la version 4.0 si elle prend en charge votre cas d’usage. |
| version 3.2 | Balises, Objets, Descriptions, Marques, Visages, Type d’image, Jeu de couleurs, Repères, Célébrités, Contenu pour adultes, Rognage intelligent | Un plus grand choix de fonctionnalités – utilisez la version 3.2 si votre cas d’usage n’est pas encore pris en charge dans la version 4.0 |
Nous vous recommandons d’utiliser l’API Analyse d’images 4.0 si elle prend en charge votre cas d’usage. Utilisez la version 3.2 si votre cas d’usage n’est pas encore pris en charge par la version 4.0.
Vous devez également utiliser la version 3.2 si vous souhaitez légender des images et si votre ressource Vision se trouve en dehors de ces régions Azure : USA Est, France Centre, Corée Centre, Europe Nord, Asie Sud-Est, Europe Ouest, USA Ouest, Asie Est. La fonctionnalité de légendes d’images dans Analyse d’image 4.0 est uniquement prise en charge dans ces régions Azure. La légende d’images dans la version 3.2 est disponible dans toutes les régions qui disposent de Azure AI Vision.
Analyser l’image
Vous pouvez analyser des images pour fournir des insights sur leurs caractéristiques visuelles. Toutes les fonctionnalités répertoriées dans la liste ci-dessous sont fournies par l'API Analyse d'images. Pour bien démarrer, suivez un guide de démarrage rapide.
| Name | Description | Page Concept |
|---|---|---|
| Personnalisation du modèle (préversion v4.0 uniquement) | Vous pouvez créer et entraîner des modèles personnalisés pour effectuer la classification d’images ou la détection d’objets. Ajoutez vos propres images et étiquetez-les avec des balises personnalisées pour que l’analyse des images forme un modèle personnalisé à votre cas d’usage. | Personnalisation des modèles |
| Lire le texte des images (v4.0 uniquement) | La préversion de la version 4.0 d’Analyse d’image offre la possibilité d’extraire du texte lisible à partir d’images. Par rapport à l’API Read Vision par ordinateur 3.2 asynchrone, la nouvelle version offre le moteur OCR Read habituel dans une API synchrone unifiée et aux performances avancées, ce qui permet d’obtenir facilement l’OCR ainsi que d’autres informations dans une seule opération d’API. | OCR pour les images |
| Détecter les personnes dans des images (v4.0 uniquement) | La version 4.0 de l’analyse d’image offre la possibilité de détecter les personnes apparaissant dans des images. Les coordonnées du cadre englobant de chaque personne détectée sont retournées, ainsi qu’un score de confiance. | Détection des visages |
| Générer des légendes d’image | Générez la légende d’une image dans un langage explicite, en utilisant des phrases complètes. Les algorithmes du service Vision par ordinateur génèrent différentes légendes selon les objets identifiés dans l’image. La version 4.0 du modèle de légende d’images est une implémentation plus avancée et fonctionne avec une gamme plus large d’images d’entrée. Elle n’est disponible que dans les régions suivantes : USA Est, France Centre, Corée Centre, Europe Nord, Asie Sud-Est, Europe Ouest, USA Ouest. La version 4.0 vous permet également d’utiliser la légende dense, qui génère des légendes détaillées pour les objets individuels qui se trouvent dans l’image. L’API retourne les coordonnées du cadre englobant (en pixels) de chaque objet trouvé dans l’image accompagné d’une légende. Vous pouvez utiliser cette fonctionnalité pour générer des descriptions de parties distinctes d’une image. 
|
Générer des légendes d’image (v3.2) (v4.0) |
| Détecter des objets | La détection d’objets est similaire au balisage, mais l’API retourne les coordonnées de cadre englobant pour chaque balise appliquée. Par exemple, si une image contient un chien, un chat et une personne, l’opération de détection liste ces objets ainsi que leurs coordonnées dans l’image. Vous pouvez utiliser cette fonctionnalité pour traiter d’autres relations entre les objets dans une image. Elle vous permet également de savoir quand il existe plusieurs instances de la même balise dans une image. 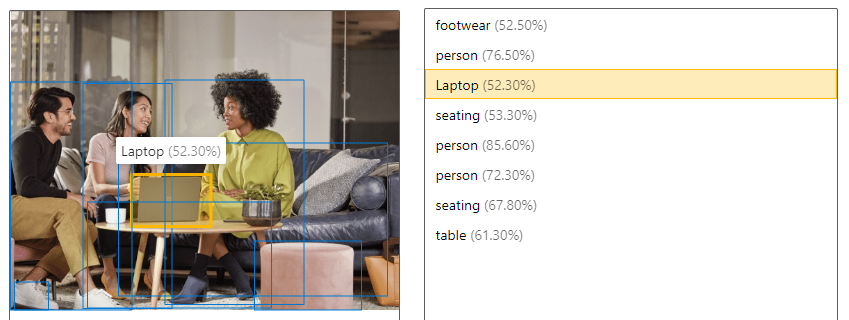
|
Détecter des objets (v3.2) (v4.0) |
| Identifier les composants visuels à l’aide de balises | Identifier les composants visuels d’une image et les marquer à l’aide de balises à partir d’un ensemble de milliers d’objets, d’êtres vivants, de scènes et d’actions reconnaissables. Quand les étiquettes sont ambigües ou inhabituelles, la réponse de l’API fournit des conseils pour clarifier le contexte de l’étiquette. Le balisage ne se limite pas au sujet principal, comme une personne au premier plan, mais il inclut également le décor (intérieur ou extérieur), le mobilier, les outils, les plantes, les animaux, les accessoires, les gadgets, etc.
|
Étiqueter des fonctionnalités visuelles (v3.2) (v4.0) |
| Obtenir la zone d’intérêt / la culture intelligente | Analysez le contenu d’une image pour retourner les coordonnées de la zone d’intérêt qui correspond à un rapport d’aspect spécifié. Le service Vision par ordinateur retourne les coordonnées de cadre englobant de la région pour que l’application appelante puisse modifier l’image d’origine de la manière souhaitée. La version 4.0 du modèle de rognage intelligent est une implémentation plus avancée et fonctionne avec une gamme plus large d’images d’entrée. Elle n’est disponible que dans les régions suivantes : USA Est, France Centre, Corée Centre, Europe Nord, Asie Sud-Est, Europe Ouest, USA Ouest. |
Générer une miniature (v3.2) (préversion v4.0) |
| Détecter des marques (v3.2 uniquement) | Identifiez les marques commerciales dans les images ou vidéos à partir d’une base de données de milliers de logos internationaux. Vous pouvez utiliser cette fonctionnalité, par exemple, pour déterminer quelles marques sont les plus populaires sur les réseaux sociaux, et lesquelles prédominent dans les médias. | Détecter les marques |
| Catégoriser une image (v3.2 uniquement) | Identifier et catégoriser une image dans son ensemble en utilisant une taxonomie des catégories comprenant des hiérarchies héréditaires parent/enfant. Les catégories peuvent être utilisées seules ou avec nos nouveaux modèles de balisage. Actuellement, l’anglais est la seule langue prise en charge pour le balisage et la catégorisation des images. |
Catégoriser une image |
| Détecter des visages (v3.2 uniquement) | Détecter les visages dans une image et fournir des informations sur chaque visage détecté. Le service Azure AI Vision indique les coordonnées, le rectangle, le sexe et l’âge pour chaque visage détecté. Vous pouvez également utiliser l’API Visage dédiée à ces fins. Elle offre une analyse plus détaillée (reconnaissance faciale, détection de la posture, etc.). |
Détecter des visages |
| Détecter des types d’images (v3.2 uniquement) | Détecter les caractéristiques relatives à une image, par exemple si une image est un dessin au trait ou s’il pourrait s’agir d’une image clipart. | Détecter les types d’images |
| Détecter du contenu spécifique à un domaine (v.3.2 uniquement) | Utiliser des modèles de domaine pour détecter et identifier le contenu spécifique à un domaine dans une image, notamment pour reconnaître des célébrités ou des éléments géographiques. Par exemple, si une image contient des célébrités, le service Azure AI Vision peut utiliser un modèle de domaine pour célébrités afin de déterminer si les personnes détectées dans l’image correspondent à des célébrités connues. | Détecter le contenu spécifique à un domaine |
| Détecter le modèle de couleurs (v3.2 uniquement) | Analyser l’utilisation des couleurs dans une image. Azure AI Vision peut déterminer si une image est en noir et blanc ou en couleur. Pour les images en couleur, il peut également identifier les couleurs dominantes et d’accentuation. | Détecter le jeu de couleurs |
| Modérer du contenu dans des images (v3.2 uniquement) | Vous pouvez utiliser Azure AI Vision pour détecter des contenus pour adultes dans une image et retourner des scores de confiance pour différentes classifications. Le seuil de marquage du contenu peut être défini sur une échelle pour prendre en compte vos préférences. | Détecter du contenu pour adultes |
Conseil
Vous pouvez utiliser les fonctionnalités de détection de texte et d’objet en lecture de l’analyse d’images via le service Azure OpenAI. Le modèle GPT-4 Turbo avec Vision vous permet de converser avec un assistant IA capable d’analyser les images que vous partagez, et l’option Amélioration de Vision utilise l’analyse des images pour fournir à l’assistance IA plus de détails (texte lisible et emplacements des objets) sur l’image. Pour plus d’informations, consultez le Guide de démarrage rapide de GPT-4 Turbo avec Vision.
Reconnaissance de produits (préversion v4.0 uniquement)
Les API Reconnaissance de produits vous permettent d’analyser des photos d’étagères dans un magasin de vente au détail. Vous pouvez détecter la présence ou l’absence de produits et obtenir leurs coordonnées de cadre englobant. Utilisez-la en combinaison avec la personnalisation du modèle pour entraîner un modèle afin d’identifier vos produits spécifiques. Vous pouvez également comparer les résultats de la reconnaissance de produits au document de planogramme de votre magasin.
Incorporations multimodales (v4.0 uniquement)
Les API d’incorporations multimodales permettent la vectorisation des images et des requêtes de texte. Elles convertissent les images en coordonnées dans un espace vectoriel multidimensionnel. Ensuite, les requêtes de texte entrantes peuvent également être converties en vecteurs, et les images peuvent être mises en correspondance avec le texte en fonction de la proximité sémantique. L’utilisateur peut ainsi rechercher un ensemble d’images en tirant parti d’un texte, sans devoir utiliser des balises d’image ou d’autres métadonnées. La proximité sémantique produit souvent de meilleurs résultats dans la recherche.
L’API 2024-02-01 inclut un modèle multilingue qui prend en charge la recherche de texte dans 102 langues. Le modèle anglais-uniquement d’origine est toujours disponible, mais il ne peut pas être combiné avec le nouveau modèle dans le même index de recherche. Si vous avez vectorisé du texte et des images à l’aide du modèle anglais-uniquement, ces vecteurs ne seront pas compatibles avec les vecteurs de texte et d’image multilingues.
Ces API ne sont disponibles que dans les régions suivantes : USA Est, France Centre, Corée Centre, Europe Nord, Asie Sud-Est, Europe Ouest, USA Ouest.
Suppression de l’arrière-plan (préversion v4.0 uniquement)
L’analyse d’image 4.0 (préversion) permet de supprimer l’arrière-plan d’une image. Cette fonctionnalité peut générer une image de l’objet au premier plan détecté avec un arrière-plan transparent ou une image alpha mate en nuances de gris montrant l’opacité de l’objet détecté au premier plan.
| Image originale | Avec l’arrière-plan supprimé | Couche alpha |
|---|---|---|

|

|

|
Exigences des images
Analyse d'images fonctionne sur les images qui répondent aux exigences suivantes :
- L’image doit être présentée au format JPEG, PNG, GIF, BMP, WEBP, ICO, TIFF ou MPO
- La taille de fichier de l’image doit être inférieure à 20 mégaoctets (Mo)
- Les dimensions de l’image doivent être supérieures à 50 x 50 pixels et inférieures à 16 000 x 16 000 pixels
Conseil
Les critères d’entrée pour les incorporations multimodales sont différents et listés dans Incorporations multimodales
Sécurité et confidentialité des données
Comme avec tous les Azure AI services, les développeurs utilisant le service Azure AI Vision doivent connaître les politiques de Microsoft relatives aux données client. Si vous souhaitez obtenir plus d’informations, consultez la page Azure AI services dans le Centre de gestion de la confidentialité Microsoft.
Étapes suivantes
Pour vous familiariser avec Analyse d'images, suivez le guide de démarrage rapide correspondant à votre langage de développement préféré :