Comment utiliser l’Analyse de texte pour la santé
Important
L’Analyse de texte pour la santé est une fonctionnalité fournie « en l’état » et « avec toutes les erreurs ». L’Analyse de texte pour l’intégrité n’est pas destinée à être utilisée en tant que dispositif médical, support clinique, outil de diagnostic ou autre technologie destinée à être utilisée dans le diagnostic, la guérison, l’atténuation, le traitement ou la prévention de maladies ou d’autres conditions, et aucune licence ou droit n’est accordé par Microsoft pour utiliser cette fonctionnalité à ces fins. Cette fonctionnalité n’est pas conçue ou destinée à être mise en œuvre ou déployée en remplacement de conseils médicaux professionnels ou d’avis de santé, de diagnostic, de traitement ou de jugement clinique d’un professionnel de la santé, et ne doit pas être utilisé en tant que tel. Le client est seul responsable de l’utilisation de l’Analyse de texte pour l’intégrité. Le client doit disposer séparément d’une licence pour tous les vocabulaires sources qu’il envisage d’utiliser selon les conditions définies dans cette Annexe du Contrat de licence du métathésaurus de l’UMLS ou tout lien équivalent futur. Il incombe au client de s’assurer de la conformité avec les termes du contrat de licence, y compris en ce qui concerne les restrictions géographiques ou autres restrictions applicables.
L’analyse de texte pour la santé permet désormais d’extraire des Déterminants sociaux de la santé (SDOH) et des mentions d’origine ethnique dans le texte. Cette fonctionnalité peut ne pas couvrir tous les SDOH potentiels et ne dérive pas d’inférences basées sur les SDOH ou l’origine ethnique (par exemple, les renseignements sur l’usage de substances sont exposés, mais l’abus de substances n’est pas déduit). Toutes les décisions tirant parti des sorties de l’Analyse de texte pour la santé qui ont un impact sur les individus ou l’allocation des ressources (y compris, mais sans s’y limiter, celles liées à la facturation, aux ressources humaines ou à la gestion des traitements médicaux) doivent être prises avec une supervision humaine et ne pas se baser uniquement sur les résultats du modèle. L’objectif des SDOH et de la capacité d’extraction de l’origine ethnique est d’aider les prestataires à améliorer les résultats en matière de santé et ils ne doivent pas être utilisés pour stigmatiser ou tirer des inférences négatives sur les utilisateurs ou les consommateurs des données des SDOH, ou les populations de patients, au-delà de l’objectif déclaré d’aider les prestataires à améliorer les résultats de santé.
L’Analyse de texte pour la santé extrait et étiquette les informations médicales pertinentes à partir de textes non structurés, tels que les notes du médecin, les bilans de sortie d’hospitalisation, les documents cliniques et les enregistrements d’intégrité électroniques. Le service effectue la reconnaissance d’entité nommée, l’extraction de relation, la liaison d’entités et la détection d’assertion pour découvrir des insights à partir du texte d’entrée. Pour plus d’informations sur les scores de confiance renvoyés, consultez la note sur la transparence.
Conseil
Si vous souhaitez tester la fonctionnalité sans écrire de code, utilisez Language Studio.
Il existe deux façons d'appeler le service :
- Un conteneur Docker (synchrone)
- Utilisation de API Web et bibliothèques clientes (asynchrones)
Options de développement
Pour utiliser l’Analyse de texte pour la santé, vous envoyez du texte brut non structuré à des fins d’analyse et gérez la sortie de l’API dans votre application. L’analyse est effectuée telle quelle, sans aucune personnalisation supplémentaire du modèle utilisé sur vos données. Il existe deux façons d’utiliser l’Analyse de texte pour la santé :
| Option de développement | Description |
|---|---|
| Language studio | Language Studio est une plateforme web qui vous permet d’essayer la liaison d’entités avec des exemples de texte sans compte Azure et vos propres données lorsque vous vous inscrivez. Pour plus d’informations, consultez le site web Language Studio ou le démarrage rapide de Language Studio. |
| API REST ou bibliothèque de client (SDK Azure) | Intégrez l’Analyse de texte pour la santé dans vos applications à l’aide de l’API REST ou de la bibliothèque cliente disponible dans différents langages. Pour plus d’informations, consultez le Guide de démarrage rapide d’Analyse de texte pour la santé. |
| Conteneur Docker | Utilisez le conteneur Docker disponible pour déployer cette fonctionnalité localement. Ces conteneurs Docker vous donnent la possibilité de rapprocher le service plus près de vos données, ce qui peut être souhaitable pour des raisons de conformité, de sécurité ou opérationnelles. |
Langues de saisie
L’Analyse de texte pour la santé prend en charge l’anglais en plus de plusieurs langues actuellement en préversion. Vous pouvez utiliser l’API hébergée ou déployer l’API dans un conteneur, comme indiqué dans Prise en charge des langues pour l’analyse de texte pour la santé.
Envoi de données
Pour envoyer une demande d’API, vous aurez besoin du point de terminaison et de la clé de votre ressource Language.
Notes
Vous trouverez la clé et le point de terminaison de votre ressource Language dans le portail Azure. Ils sont dans la page Clé et point de terminaison de la ressource, sous Gestion des ressources.
L’analyse est effectuée à la réception de la demande. Si vous envoyez une requête à l’aide de l’API REST ou de la bibliothèque cliente, les résultats sont retournés de façon asynchrone. Si vous utilisez le conteneur Docker, ils sont retournés de façon synchrone.
Lors de l’utilisation de cette fonctionnalité de manière asynchrone, les résultats de l’API sont disponibles pendant 24 heures à partir du moment où la requête a été ingérée, et sont indiqués dans la réponse. Après cette période, les résultats sont purgés et ne sont plus disponibles pour récupération.
Envoi d’une demande FHIR (Fast Healthcare Interopérabilité Resources)
Fast Healthcare Interoperability Resources (FHIR) est la norme de communication du secteur de la santé développée par l’organisation Health Level Seven International (HL7). La norme définit les formats de données (ressources) et la structure de l’API pour l’échange de données de soins de santé électroniques. Pour recevoir votre résultat à l’aide de la structure FHIR, vous devez envoyer la version FHIR dans le corps de la requête API.
| Nom du paramètre | Type | Valeur |
|---|---|---|
| fhirVersion | string | 4.0.1 |
Obtention des résultats de la fonctionnalité
En fonction de votre demande d’API et des données que vous envoyez au Analyse de texte pour l’intégrité, vous obtiendrez :
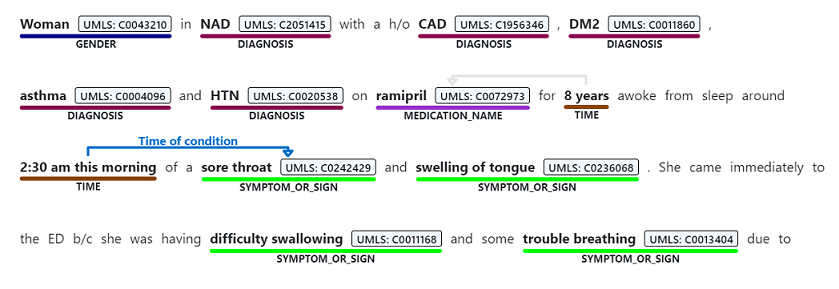
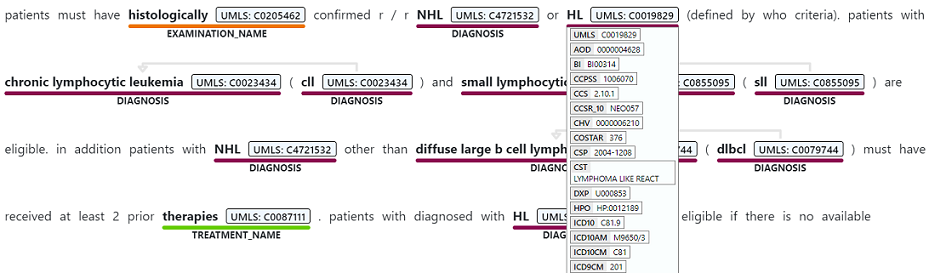
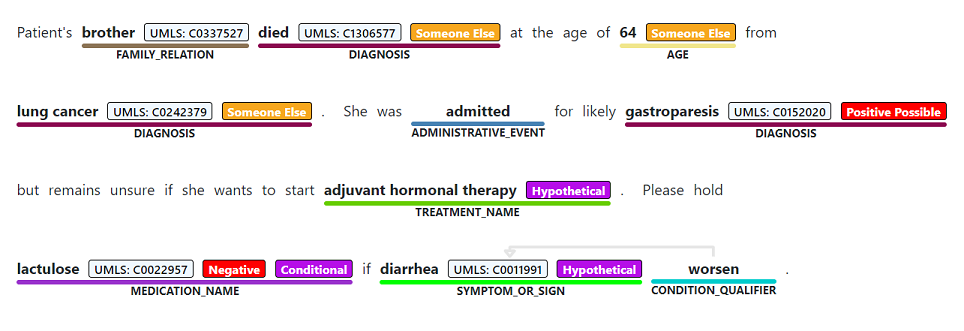
La reconnaissance d’entité nommée est utilisée pour effectuer une extraction sémantique de mots et d’expressions mentionnés à partir d’un texte non structuré associé à l’un des types d’entités pris en charge, tels que le diagnostic, le nom du médicament, le symptôme/signe ou l’âge.

Limites du service et des données
Pour connaître la taille et le nombre de demandes que vous pouvez envoyer par minute et seconde, consultez l’article Limites de service.