Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les travaux Lakeflow fournissent un moyen non interactif d’exécuter des applications dans un cluster Azure Databricks, par exemple, un travail ETL ou une tâche d’analyse des données qui doivent s’exécuter selon une planification. Généralement, ces tâches s'exécutent en tant qu'utilisateur qui les a créées, mais cela peut présenter certaines limitations :
- La création et l’exécution de travaux sont possibles si l’utilisateur dispose des autorisations appropriées.
- Seul l’utilisateur qui a créé le travail y a accès.
- Or, l’utilisateur peut être supprimé de l’espace de travail Azure Databricks.
L’utilisation d’un compte de service (un compte associé à une application plutôt qu’à un utilisateur spécifique) est une méthode courante pour s’affranchir de ces limites. Dans Azure, vous pouvez utiliser une application et un principal de service Microsoft Entra ID pour créer un compte de service.
Par exemple, cela est important lorsque les principaux de service contrôlent l’accès aux données stockées dans un compte Azure Data Lake Storage. L’exécution de travaux avec ces principaux de service permet aux travaux d’accéder aux données incluses dans le compte de stockage et de contrôler l’étendue de l’accès aux données.
Ce tutoriel explique comment créer un principal de service et une application Microsoft Entra ID, puis désigner ce principal de service comme propriétaire d’un travail. Vous allez également apprendre à accorder des autorisations d’exécution de travail à d’autres groupes qui ne possèdent pas le travail. Voici une vue d’ensemble des tâches parcourues dans le cadre de ce tutoriel :
- Créez un principal de service dans Microsoft Entra ID.
- Créer un jeton d’accès personnel (PAT) dans Azure Databricks. Vous allez utiliser le PAT pour vous authentifier auprès de l’API REST Databricks.
- Ajouter le principal de service en tant qu’utilisateur non administrateur à Azure Databricks à l’aide de l’API SCIM Databricks.
- Créer une étendue de secrets Azure Key Vault dans Azure Databricks.
- Accorder au principal de service un accès en lecture à l’étendue de secrets.
- Créer un travail dans Azure Databricks et configurer le cluster de travail pour lire les secrets de l’étendue de secrets.
- Transférer la propriété du travail au principal de service.
- Tester le travail en l’exécutant en tant que principal de service.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Remarque
Vous ne pouvez pas utiliser un cluster avec une transmission des informations d'identification activée pour exécuter une tâche détenue par un service principal. Si votre travail nécessite un principal de service pour accéder au stockage Azure, consultez Se connecter à Azure Data Lake Storage ou Stockage Blob à l’aide des informations d’identification Azure.
Spécifications
Vous aurez besoin des éléments suivants pour ce tutoriel :
- Un compte d’utilisateur disposant des autorisations nécessaires pour inscrire une application dans votre tenant Microsoft Entra ID.
- Privilèges d’administration dans l’espace de travail Azure Databricks dans lequel vous allez exécuter des travaux.
- Un outil pour effectuer des demandes d’API à Azure Databricks. Ce tutoriel utilise cURL, mais vous pouvez utiliser n’importe quel outil qui vous permet de soumettre des demandes d’API REST.
Créer un principal de service dans Microsoft Entra ID
Un principal de service est l’identité d’une application Microsoft Entra ID. Pour créer le principal de service à utiliser pour exécuter des travaux :
- Dans le portail Azure, sélectionnez Microsoft Entra ID > Inscriptions d’applications > Nouvelle inscription. Entrez un nom pour l’application et cliquez sur Inscrire.
- Accédez à Certificats et secrets, cliquez sur Nouveau secret client et générez un nouveau secret client. Copiez et enregistrez le secret dans un endroit sécurisé.
- Accédez à Vue d’ensemble et prenez note des valeurs ID d’application (client) et ID d’annuaire (locataire).
Créer le jeton d’accès personnel Azure Databricks
Vous allez utiliser un jeton d’accès personnel Azure Databricks (PAT) pour vous authentifier auprès de l’API REST Databricks. Pour créer un PAT utilisable pour effectuer des demandes d’API :
- Accédez à votre espace de travail Azure Databricks.
- Cliquez sur votre nom d’utilisateur dans le coin supérieur droit de l’écran, puis cliquez sur Paramètres.
- Cliquez sur Développeur.
- À côté de Jetons d’accès, cliquez sur Gérer.
- Cliquez sur Générer un nouveau jeton.
- Copiez et enregistrez la valeur du jeton.
Conseil
Cet exemple utilise un jeton d’accès personnel, mais vous pouvez utiliser un jeton Microsoft Entra ID pour la plupart des API. Dans le cadre des bonnes pratiques, un jeton PAT convient aux tâches de configuration administratives, tandis que les jetons Microsoft Entra ID sont préférables pour les charges de travail de production.
Vous pouvez limiter la génération des PAT aux seuls administrateurs pour des raisons de sécurité. Pour plus d’informations, consultez Surveiller et révoquer des jetons d’accès personnels.
Ajouter le principal de service à l’espace de travail Azure Databricks
Vous ajoutez le principal de service Microsoft Entra ID à un espace de travail en utilisant l’API Service Principals. Vous devez aussi accorder au principal de service l’autorisation de lancer des clusters de travail automatisés. Vous pouvez accorder cette autorisation par le biais de l’autorisation allow-cluster-create. Ouvrez un terminal, utilisez la CLI Databricks et exécutez la commande suivante pour ajouter le principal de service et octroyer les autorisations nécessaires :
databricks service-principals create --json '{
"schemas":[
"urn:ietf:params:scim:schemas:core:2.0:ServicePrincipal"
],
"applicationId":"<application-id>",
"displayName": "test-sp",
"entitlements":[
{
"value":"allow-cluster-create"
}
]
}'
Remplacez <application-id> par Application (client) ID pour l’inscription d’application Microsoft Entra ID.
Créer une étendue de secrets soutenue par Azure Key Vault dans Azure Databricks
Gérer les étendues de secrets fournit un stockage et une gestion sécurisés des secrets. Vous allez stocker le secret associé au principal de service dans une étendue secrète. Vous pouvez stocker des secrets dans un espace de secrets Azure Databricks ou un espace de secrets pris en charge par Azure Key Vault. Ces instructions décrivent l’option soutenue par Azure Key Vault :
- Créez une instance Azure Key Vault dans le portail Azure.
- Créez l’étendue de secrets Azure Databricks s’appuyant sur l’instance Azure Key Vault.
Étape 1 : Créer une instance Azure Key Vault
Dans le portail Azure, sélectionnez Key Vaults > + Ajouter et donnez un nom au Key Vault.
Cliquez sur Vérifier + créer.
Une fois la validation terminée, cliquez sur Créer.
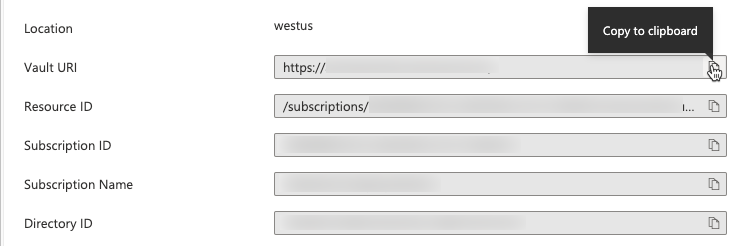
Après avoir créé le Key Vault, accédez à la page Propriétés du nouveau Key Vault.
Copiez et enregistrez l’URI du coffre et l’ID de la ressource.
Étape 2 : Créer un espace de secrets supporté par Azure Key Vault
Les ressources Azure Databricks peuvent faire référence à des secrets stockés dans un Azure Key Vault en créant une étendue de secrets reposant sur Key Vault. Pour créer l’étendue de secrets Azure Databricks :
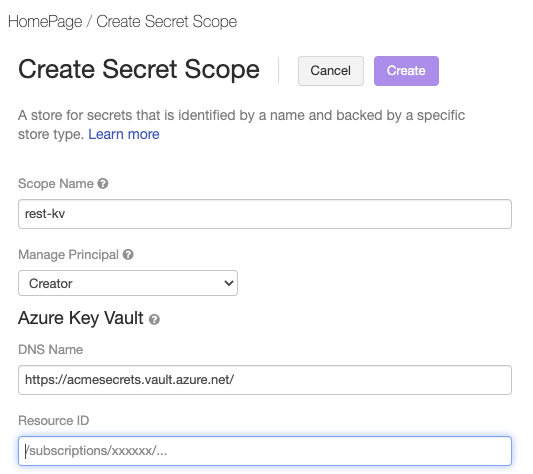
Accédez à la page Créer une étendue de secrets Azure Databricks sur
https://<per-workspace-url>/#secrets/createScope. Remplacezper-workspace-urlpar l’URL par espace de travail unique de votre espace de travail Azure Databricks.Entrez un Nom d’étendue.
Entrez les valeurs URI du coffre et ID de la ressource de l’Azure Key Vault que vous avez créé à l’étape 1 : Créer une instance Azure Key Vault.
Cliquez sur Créer.
Enregistrer le secret client dans Azure Key Vault
Dans le portail Azure, accédez au service Key Vault.
Sélectionnez le Key Vault créé à l’étape 1 : Créer une instance Azure Key Vault.
Sous Paramètres > Secrets, cliquez sur Générer/Importer.
Sélectionnez l’option de chargement Manuel, puis entrez le secret client dans le champ Valeur.
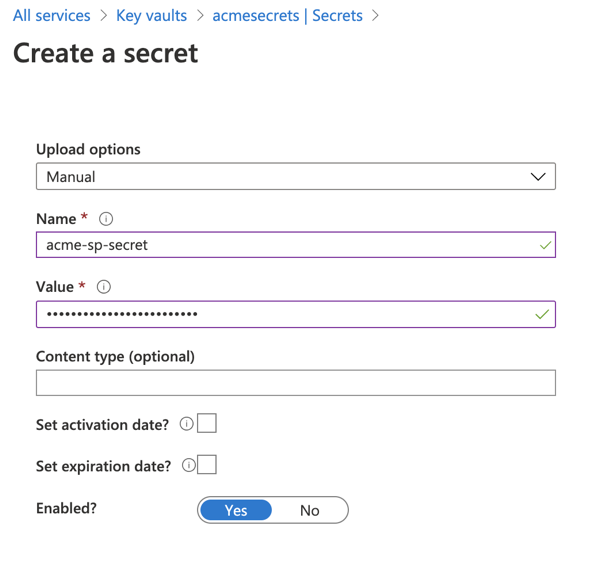
Cliquez sur Créer.
Accorder au principal de service un accès en lecture à l’étendue de secrets
Vous avez créé un périmètre secret et stocké la clé secrète du client principal de service dans ce périmètre. Vous allez maintenant accorder au principal de service l’accès pour lire le secret à partir de l’étendue du secret.
Ouvrez un terminal et utilisez l’interface CLI Databricks pour exécuter la commande suivante :
databricks secrets put-acl <scope-name> <application-id> READ
- Remplacez
<scope-name>par le nom de la portée de secrets Azure Databricks qui contient le secret client. - Remplacez
<application-id>parApplication (client) IDpour l’inscription d’application Microsoft Entra ID.
Créer un travail dans Azure Databricks et configurer le cluster pour lire les secrets de l’étendue de secrets
Vous êtes maintenant prêt à créer un travail qui peut s’exécuter en tant que nouveau principal de service. Vous allez utiliser un notebook créé dans l’interface utilisateur Azure Databricks et ajouter la configuration pour permettre au cluster de travaux de récupérer le secret du principal de service.
Accédez à votre page d'accueil Azure Databricks et sélectionnez Nouveau > Bloc-notes. Donnez un nom à votre notebook et sélectionnez SQL comme langage par défaut.
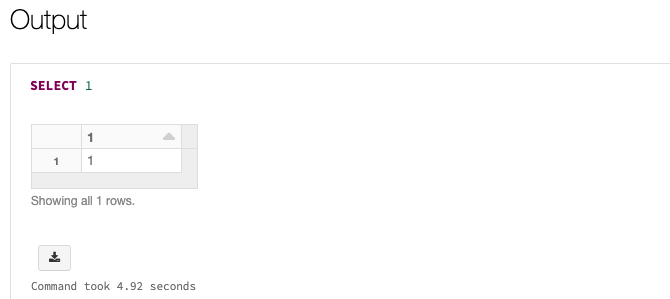
Entrez
SELECT 1dans la première cellule du notebook. Il s’agit d’une commande simple qui affiche simplement 1 en cas de réussite. Si vous avez accordé à votre principal de service un accès à des fichiers ou chemins particuliers dans Azure Data Lake Storage Gen2, vous pouvez lire plutôt à partir de ces chemins.Dans votre espace de travail, cliquez sur
 Travaux & Pipelines dans la barre latérale.
Travaux & Pipelines dans la barre latérale.Sous Créer, puis Travail.
Donnez un nom au travail et à la tâche, cliquez sur Sélectionner un Notebook et sélectionnez le bloc-notes que vous venez de créer.
Cliquez sur Modifier en regard des informations sur le cluster.
Dans la page Configurer le cluster, cliquez sur Options avancées.
Sous l’onglet Spark, entrez la configuration Spark suivante :
fs.azure.account.auth.type.<storage-account>.dfs.core.windows.net OAuth fs.azure.account.oauth.provider.type.<storage-account>.dfs.core.windows.net org.apache.hadoop.fs.azurebfs.oauth2.ClientCredsTokenProvider fs.azure.account.oauth2.client.id.<storage-account>.dfs.core.windows.net <application-id> fs.azure.account.oauth2.client.secret.<storage-account>.dfs.core.windows.net {{secrets/<secret-scope-name>/<secret-name>}} fs.azure.account.oauth2.client.endpoint.<storage-account>.dfs.core.windows.net https://login.microsoftonline.com/<directory-id>/oauth2/token- Remplacez
<storage-account>par le nom du compte de stockage contenant vos données. - Remplacez
<secret-scope-name>par le nom de la portée de secrets Azure Databricks qui contient le secret client. - Remplacez
<application-id>parApplication (client) IDpour l’inscription d’application Microsoft Entra ID. - Remplacez
<secret-name>par le nom associé à la valeur de la clé secrète client dans l’étendue de secrets. - Remplacez
<directory-id>parDirectory (tenant) IDpour l’inscription d’application Microsoft Entra ID.
- Remplacez
Transférer la propriété du travail au principal de service
Un travail peut avoir exactement un propriétaire. Vous devrez donc transférer la propriété du travail de vous-même vers le principal de service. Pour vous assurer que les autres utilisateurs puissent gérer le travail, vous pouvez aussi accorder des autorisations PEUT GÉRER à un groupe. Dans cet exemple, nous utilisons l’API Permissions pour définir ces autorisations.
Ouvrez un terminal et utilisez l’interface CLI Databricks pour exécuter la commande suivante :
databricks permissions set jobs <job-id> --json '{
"access_control_list": [
{
"service_principal_name": "<application-id>",
"permission_level": "IS_OWNER"
},
{
"group_name": "admins",
"permission_level": "CAN_MANAGE"
}
]
}'
- Remplacez
<job-id>par l’identificateur unique du travail. Pour rechercher l’ID de travail, cliquez sur Travaux & Pipelines dans la barre latérale, puis cliquez sur le nom du travail. L’ID du travail figure dans le panneau latéral Détails du travail. - Remplacez
<application-id>parApplication (client) IDpour l’inscription d’application Microsoft Entra ID.
Le travail aura également besoin d’autorisations de lecture sur le notebook. Utilisez l’interface CLI Databricks pour exécuter la commande suivante pour accorder les autorisations requises :
databricks permissions set notebooks <notebook-id> --json '{
"access_control_list": [
{
"service_principal_name": "<application-id>",
"permission_level": "CAN_READ"
}
]
}'
- Remplacez
<notebook-id>par l’ID du notebook associé au travail. Pour rechercher l’ID, accédez au notebook dans l’espace de travail Azure Databricks et recherchez l’ID numérique qui suitnotebook/dans l’URL du notebook. - Remplacez
<application-id>parApplication (client) IDpour l’inscription d’application Microsoft Entra ID.
Tester la tâche
Vous exécutez des travaux avec un principal de service de la même façon qu’en tant qu’utilisateur, à savoir par le biais de l’interface utilisateur, de l’API ou de l’interface CLI. Pour tester le travail à l’aide de l’interface utilisateur Azure Databricks :
- Accédez à Travaux & Pipelines dans l’interface utilisateur Azure Databricks et sélectionnez le travail.
- Cliquez sur Exécuter maintenant.
Vous verrez un état de Réussite pour le travail si tout s’exécute correctement. Vous pouvez sélectionner la tâche dans l'interface utilisateur pour vérifier le résultat.
En savoir plus
Pour en savoir plus sur la création et l'exécution de tâches, consultez Lakeflow Jobs.