Entrainement
Module
Implémenter des modèles d’architecture de diffusion en continu avec Delta Live Tables - Training
Découvrir la diffusion en continu structurée avec Delta Live Tables
Ce navigateur n’est plus pris en charge.
Effectuez une mise à niveau vers Microsoft Edge pour tirer parti des dernières fonctionnalités, des mises à jour de sécurité et du support technique.
Delta Lake est profondément intégré à Spark Structured Streaming par le biais de readStream et writeStream. Delta Lake surmonte bon nombre des limitations généralement associées aux systèmes et aux fichiers de streaming, notamment :
Notes
Cet article détaille l’utilisation des tables Delta Lake comme sources et récepteurs de diffusion en continu. Pour découvrir comment charger des données à l’aide de tables de diffusion en continu dans Databricks SQL, consultez l’article Charger des données au moyen des tables de diffusion en continu dans Databricks SQL.
Pour plus d’informations sur les jointures statiques de flux avec Delta Lake, consultez Jointures statiques de flux.
Structured Streaming lit de manière incrémentielle les tables Delta. Lorsqu’une requête de diffusion en continu est active sur une table Delta, les nouveaux enregistrements sont traités de manière idempotente lorsque les nouvelles versions de table sont validées dans la table source.
Les exemples de code suivants montrent la configuration d’une lecture en continu à l’aide du nom de la table ou du chemin d’accès au fichier.
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
spark.readStream.table("table_name")
spark.readStream.load("/path/to/table")
Important
Si le schéma d’une table Delta change après le début d’une lecture en continu sur la table, la requête échoue. Pour la plupart des modifications de schéma, vous pouvez redémarrer le flux pour résoudre l’incompatibilité de schéma et poursuivre le traitement.
Dans Databricks Runtime 12.2 LTS et les versions antérieures, vous ne pouvez pas diffuser en continu à partir d’une table Delta avec le mappage de colonnes activé qui a subi une évolution de schéma non additive, telle que le changement de nom ou la suppression de colonnes. Si vous souhaitez obtenir plus d’informations, consultez Diffusion en continu avec un mappage de colonnes et des modifications de schéma.
Les options suivantes sont disponibles pour contrôler les microlots :
maxFilesPerTrigger : Nombre de nouveaux fichiers à prendre en compte dans chaque microlot. La valeur par défaut est 1000.maxBytesPerTrigger : Quantité de données traitées dans chaque microlot. Cette option définit une valeur « soft max », qui signifie qu’un lot traite approximativement cette quantité de données et peut traiter plus que la limite afin de faire avancer la requête de streaming dans les cas où la plus petite unité d’entrée est supérieure à cette limite. Elle n’est pas définie par défaut.Si vous utilisez maxBytesPerTrigger conjointement avec maxFilesPerTrigger, le microlot traite les données jusqu’à ce que la limite maxFilesPerTrigger ou maxBytesPerTrigger soit atteinte.
Notes
Dans les cas où les transactions de table source sont nettoyées en raison de la logRetentionDurationconfiguration et que la requête de diffusion en continu tente de traiter ces versions, par défaut, la requête ne parvient pas à éviter la perte de données. Vous pouvez choisir l’option failOnDataLoss à false pour ignorer les données perdues et poursuivre le traitement.
Le flux des changements de données Delta Lake enregistre les modifications apportées à une table Delta, y compris les mises à jour et les suppressions. Lorsque cela est activé, vous pouvez envoyer en streaming un flux des changements de données et écrire une logique pour effectuer les insertions, les mises à jour et les suppressions dans les tables en aval. La sortie du flux des changements de données diffère légèrement de la table Delta qu’elle décrit, mais cela fournit une solution pour propager des modifications incrémentielles vers les tables en aval dans une architecture de médaillon.
Important
Dans Databricks Runtime 12.2 LTS et les versions antérieures, vous ne pouvez pas diffuser en continu à partir du flux des changements de données d’une table Delta avec le mappage de colonnes activé qui a subi une évolution de schéma non additive, telle que le changement de nom ou la suppression de colonnes. Consultez Diffusion en continu avec un mappage de colonnes et des modifications de schéma.
Le flux structuré ne traite pas les entrées qui ne sont pas des ajouts et lève une exception si des modifications sont apportées à la table utilisée comme source. Il existe deux stratégies principales pour traiter les modifications qui ne peuvent pas être propagées automatiquement en aval :
ignoreDeletes : ignore les transactions qui suppriment des données aux limites de la partition.skipChangeCommits : ignorer les transactions qui suppriment ou modifient des enregistrements existants.
skipChangeCommits englobe ignoreDeletes.Notes
Dans Databricks Runtime 12.2 LTS et versions ultérieures, skipChangeCommits remplace le paramètre ignoreChanges précédent. Dans Databricks Runtime 11.3 LTS et versions antérieures, ignoreChanges est la seule option prise en charge.
La sémantique pour ignoreChanges diffère considérablement de skipChangeCommits. Lorsque ignoreChanges est activé, les fichiers de données réécrits dans la table source sont réécrits après une opération de modification de données telle que UPDATE, MERGE INTO, DELETE (dans des partitions) ou OVERWRITE. Les lignes inchangées sont souvent émises à côté de nouvelles lignes, de sorte que les consommateurs en aval doivent être en mesure de gérer les doublons. Les suppressions ne sont pas propagées en aval.
ignoreChanges englobe ignoreDeletes.
skipChangeCommits ignore entièrement les opérations de modification de fichier. Les fichiers de données qui sont réécrits dans la table source en raison d’une opération de modification des données comme UPDATE, MERGE INTO, DELETE et OVERWRITE sont entièrement ignorés. Pour refléter les modifications apportées aux tables sources en amont, vous devez implémenter une logique distincte pour propager ces modifications.
Les charges de travail configurées avec ignoreChanges continuent de fonctionner à l’aide d’une sémantique connue, mais Databricks recommande d’utiliser skipChangeCommits pour toutes les nouvelles charges de travail. La migration des charges de travail à l’aide de ignoreChanges vers skipChangeCommits nécessite une logique de refactorisation.
Par exemple, supposons que vous ayez une table user_events avec des colonnes date, user_email et action, partitionnée par date. Vous sortez de la table user_events et vous devez en supprimer les données conformément au RGPD.
Lorsque vous supprimez des données aux limites des partitions (c’est-à-dire que WHERE se trouve sur une colonne de partition), les fichiers sont déjà segmentés par valeur, de sorte que la suppression supprime uniquement ces fichiers des métadonnées. Lorsque vous supprimez une partition entière de données, vous pouvez utiliser les éléments suivants :
spark.readStream
.option("ignoreDeletes", "true")
.table("user_events")
Si vous supprimez des données dans plusieurs partitions (dans cet exemple, le filtrage sur user_email), utilisez la syntaxe suivante :
spark.readStream
.option("skipChangeCommits", "true")
.table("user_events")
Si vous mettez à jour un user_email avec l’instruction UPDATE, le fichier contenant le user_email en question est réécrit. Utilisez skipChangeCommits pour ignorer les fichiers de données modifiés.
Vous pouvez utiliser les options suivantes pour spécifier le point de départ de la source de streaming Delta Lake sans traiter la totalité de la table.
startingVersion : Version de Delta Lake de départ. Databricks recommande d’omettre cette option pour la plupart des charges de travail. Lorsqu’il n’est pas défini, le flux démarre à partir de la dernière version disponible, y compris une capture instantanée complète de la table à ce moment-là.
S’il est spécifié, le flux lit toutes les modifications apportées à la table Delta à partir de la version spécifiée (inclusive). Si la version spécifiée n’est plus disponible, le flux ne démarre pas. Vous pouvez obtenir les versions de validation à partir de la colonne version de la sortie de commande DESCRIBE HISTORY.
Pour retourner uniquement les dernières modifications, spécifiez latest.
startingTimestamp : Timestamp de départ. Toutes les modifications de table validées à partir de ce timestamp (inclus) sont lues par le lecteur de streaming. Si le timestamp fourni précède toutes les validations de table, la lecture en continu commence par le timestamp disponible le plus ancien. Valeurs possibles :
"2019-01-01T00:00:00.000Z"."2019-01-01".Vous ne pouvez pas définir les deux options en même temps. Elles prennent effet uniquement lors du démarrage d’une nouvelle requête de streaming. Si une requête de streaming a démarré et que sa progression a été enregistrée dans son point de contrôle, ces options sont ignorées.
Important
Bien que vous puissiez démarrer la source de streaming à partir d’une version ou d’un timestamp spécifié, le schéma de la source de streaming est toujours le schéma le plus récent de la table Delta. Vous devez vous assurer qu’aucune modification de schéma incompatible n’a été apportée à la table Delta après la version ou le timestamp spécifié. Sinon, la source de streaming peut renvoyer des résultats incorrects lors de la lecture des données avec un schéma incorrect.
Par exemple, supposons que vous ayez une table user_events. Si vous souhaitez lire les modifications apportées depuis la version 5, utilisez :
spark.readStream
.option("startingVersion", "5")
.table("user_events")
Si vous souhaitez lire les modifications apportées depuis la version 2018-10-18, utilisez :
spark.readStream
.option("startingTimestamp", "2018-10-18")
.table("user_events")
Cette fonctionnalité est disponible sur Databricks Runtime 11.3 LTS et versions ultérieures.
Lorsque vous utilisez une table Delta comme source de flux, la requête traite d’abord toutes les données présentes dans la table. La table Delta de cette version est appelée capture instantanée initiale. Par défaut, les fichiers de données de la table Delta sont traités en fonction du dernier fichier modifié. Toutefois, l’heure de la dernière modification ne représente pas nécessairement l’ordre chronologique des événements d’enregistrement.
Dans une requête de diffusion en continu avec état avec un filigrane défini, le traitement des fichiers par heure de modification peut entraîner le traitement des enregistrements dans un ordre incorrect. Cela peut entraîner le marquage des enregistrements en tant qu’événements en retard par le filigrane.
Vous pouvez éviter le problème de suppression de données en activant l’option suivante :
Une fois l’ordre chronologique des événements activé, l’intervalle de temps d’événement des données de capture instantanée initiale est divisé en compartiments de temps. Chaque micro-lot traite un compartiment en filtrant les données dans l’intervalle de temps. Les options de configuration maxFilesPerTrigger et maxBytesPerTrigger sont toujours applicables pour contrôler la taille du microbatch, mais de manière approximative en raison de la nature du traitement.
Le graphique ci-dessous montre ce processus :
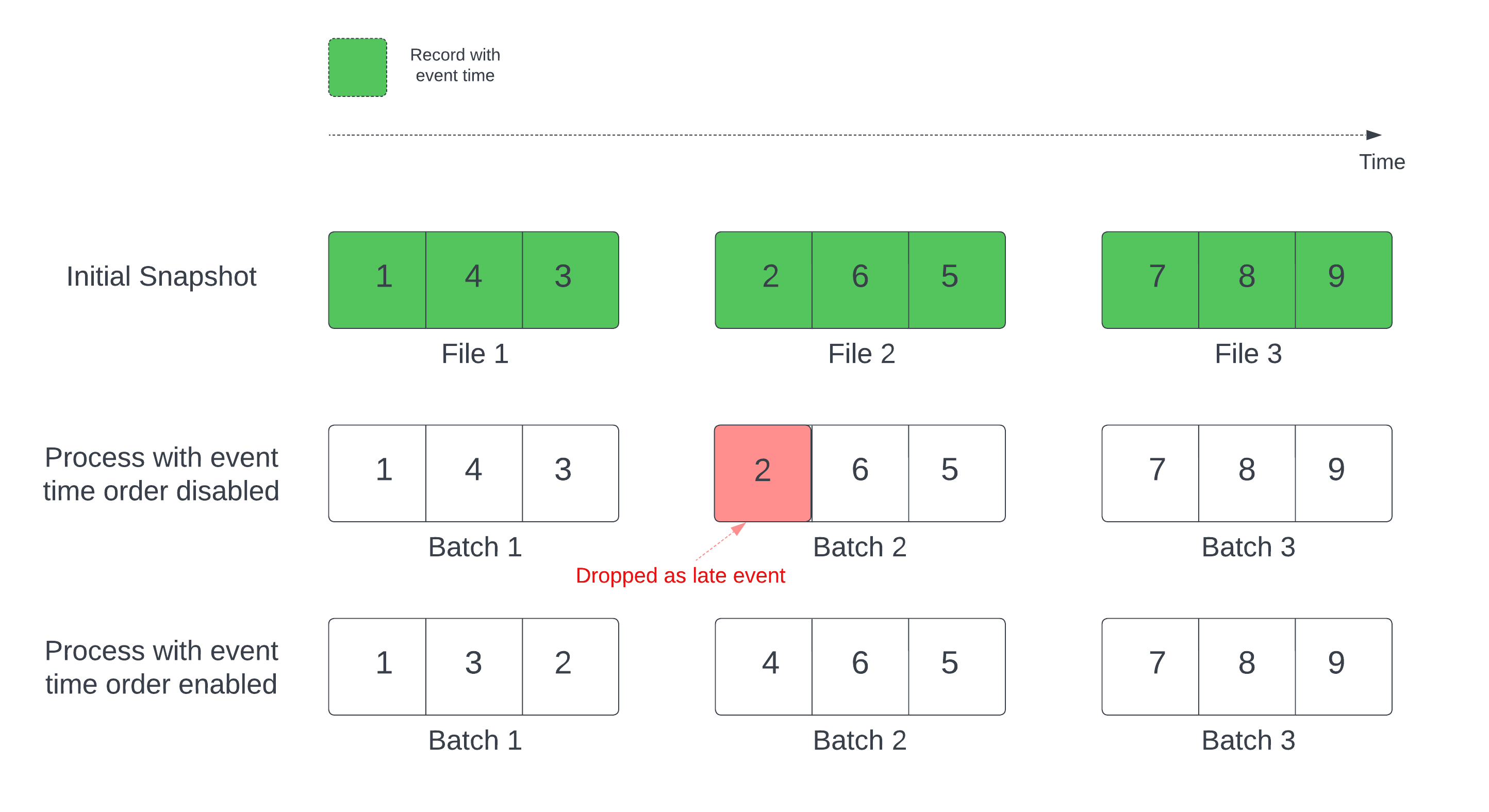
Informations notables sur cette fonctionnalité :
withEventTimeOrder une fois la requête de flux démarrée pendant le traitement de la capture instantanée initiale. Pour redémarrer le processus en modifiant withEventTimeOrder, vous devez supprimer le point de contrôle.Supposons que vous ayez une table user_events avec une colonne event_time. Votre requête de diffusion en continu est une requête d’agrégation. Si vous souhaitez vous assurer qu’aucune suppression de données n’aura lieu lors du traitement de la capture instantanée initiale, vous pouvez utiliser :
spark.readStream
.option("withEventTimeOrder", "true")
.table("user_events")
.withWatermark("event_time", "10 seconds")
Notes
Vous pouvez également activer cette fonctionnalité avec la configuration Spark sur le cluster qui s’applique à toutes les requêtes de diffusion en continu : spark.databricks.delta.withEventTimeOrder.enabled true.
Vous pouvez également écrire des données dans une table Delta à l’aide de Structured Streaming. Le journal des transactions permet à Delta Lake de garantir un traitement « une seule fois », même si d’autres flux ou requêtes par lot s’exécutent simultanément sur la table.
Notes
La fonction VACUUM Delta Lake supprime tous les fichiers non gérés par Delta Lake, mais ignore les répertoires qui commencent par _. Vous pouvez stocker sans risque des points de contrôle en même temps que d’autres données et métadonnées pour une table Delta à l’aide d’une structure de répertoires telle que <table-name>/_checkpoints.
Vous pouvez connaître le nombre d’octets et le nombre de fichiers encore à traiter dans un processus de requête de streaming grâce aux métriques numBytesOutstanding et numFilesOutstanding. Les métriques supplémentaires sont les suivantes :
numNewListedFiles : nombre de fichiers Delta Lake listés afin de calculer le backlog pour ce lot.
backlogEndOffset : version de table utilisée pour calculer le backlog.Si vous exécutez le flux dans un notebook, vous pouvez voir ces métriques sous l’onglet Données brutes du tableau de bord de progression des requêtes de diffusion en continu :
{
"sources": [
{
"description": "DeltaSource[file:/path/to/source]",
"metrics": {
"numBytesOutstanding": "3456",
"numFilesOutstanding": "8"
}
}
]
}
Par défaut, les flux s’exécutent en mode ajout, ce qui adjoint de nouveaux enregistrements à la table.
Utilisez la méthode toTable lors de la diffusion en continu vers des tables, comme dans l’exemple suivant :
(events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
)
events.writeStream
.outputMode("append")
.option("checkpointLocation", "/tmp/delta/events/_checkpoints/")
.toTable("events")
Vous pouvez également utiliser Structured Streaming pour remplacer la table entière par chaque lot. Un exemple de cas d’usage consiste à calculer un résumé à l’aide de l’agrégation :
(spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
)
spark.readStream
.table("events")
.groupBy("customerId")
.count()
.writeStream
.outputMode("complete")
.option("checkpointLocation", "/tmp/delta/eventsByCustomer/_checkpoints/")
.toTable("events_by_customer")
L’exemple précédent met continuellement à jour une table qui contient le nombre agrégé d’événements par client.
Pour les applications dont les exigences en matière de latence sont plus souples, vous pouvez économiser des ressources de calcul grâce à des déclencheurs à usage unique. Utilisez-les pour mettre à jour les tables d’agrégation récapitulatives selon une planification donnée, en traitant uniquement les nouvelles données qui sont arrivées depuis la dernière mise à jour.
Vous pouvez utiliser une combinaison de merge et foreachBatch pour écrire des upserts complexes à partir d’une requête de streaming dans une table Delta. Consultez Utiliser foreachBatch pour écrire dans des récepteurs de données arbitraires.
Ce modèle a de nombreuses applications, dont celles-ci :
foreachBatch pour appliquer en permanence un flux de modifications à une table Delta.foreachBatch pour écrire en continu des données (avec des doublons) dans une table Delta avec déduplication automatique.Notes
merge dans foreachBatch est idempotente, car des redémarrages de la requête de diffusion en continu peuvent appliquer l’opération sur le même lot de données plusieurs fois.merge est utilisé dans foreachBatch, le taux de données d'entrée de la requête de diffusion en continu (signalé par StreamingQueryProgress et visible dans le graphique du taux du notebook) peut être signalé comme un multiple du taux réel de génération des données à la source. Cela est dû au fait que merge lit les données d’entrée plusieurs fois, entraînant une multiplication des métriques d’entrée. S’il s’agit d’un goulot d’étranglement, vous pouvez mettre en cache le lot tramedonnées avant l’opération merge, puis le sortir du cache après l’opération merge.L’exemple suivant montre comment utiliser SQL dans foreachBatch pour accomplir cette tâche :
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
// Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
// Use the view name to apply MERGE
// NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
microBatchOutputDF.sparkSession.sql(s"""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
# Set the dataframe to view name
microBatchOutputDF.createOrReplaceTempView("updates")
# Use the view name to apply MERGE
# NOTE: You have to use the SparkSession that has been used to define the `updates` dataframe
# In Databricks Runtime 10.5 and below, you must use the following:
# microBatchOutputDF._jdf.sparkSession().sql("""
microBatchOutputDF.sparkSession.sql("""
MERGE INTO aggregates t
USING updates s
ON s.key = t.key
WHEN MATCHED THEN UPDATE SET *
WHEN NOT MATCHED THEN INSERT *
""")
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Vous pouvez également choisir d’utiliser les API Delta Lake pour effectuer des upserts de streaming, comme dans l’exemple suivant :
import io.delta.tables.*
val deltaTable = DeltaTable.forName(spark, "table_name")
// Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF: DataFrame, batchId: Long) {
deltaTable.as("t")
.merge(
microBatchOutputDF.as("s"),
"s.key = t.key")
.whenMatched().updateAll()
.whenNotMatched().insertAll()
.execute()
}
// Write the output of a streaming aggregation query into Delta table
streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta _)
.outputMode("update")
.start()
from delta.tables import *
deltaTable = DeltaTable.forName(spark, "table_name")
# Function to upsert microBatchOutputDF into Delta table using merge
def upsertToDelta(microBatchOutputDF, batchId):
(deltaTable.alias("t").merge(
microBatchOutputDF.alias("s"),
"s.key = t.key")
.whenMatchedUpdateAll()
.whenNotMatchedInsertAll()
.execute()
)
# Write the output of a streaming aggregation query into Delta table
(streamingAggregatesDF.writeStream
.foreachBatch(upsertToDelta)
.outputMode("update")
.start()
)
Notes
Databricks recommande de configurer une écriture de streaming distincte pour chaque récepteur que vous souhaitez mettre à jour au lieu d’utiliser foreachBatch. Cela est dû au fait que les écritures dans plusieurs tables sont sérialisées lors de l’utilisation de « foreachBatch », ce qui réduit la parallélisation et augmente la latence globale.
Les tables Delta prennent en charge les options suivantes DataFrameWriter pour effectuer des écritures dans plusieurs tables au sein d'idempotents foreachBatch :
txnAppId : chaîne unique que vous pouvez transmettre à chaque écriture DataFrame. Par exemple, vous pouvez utiliser l’ID StreamingQuery comme txnAppId.txnVersion : Nombre à croissance monotone qui fait office de version de transaction.Delta Lake utilise la combinaison de txnAppId et txnVersion pour identifier les écritures en double et les ignorer.
Si l’écriture d’un lot est interrompue en cas d’échec, la réexécution du lot utilise la même application et le même ID de lot pour aider le runtime à identifier correctement les écritures en double et à les ignorer. L’ID d’application (txnAppId) peut être toute chaîne unique générée par l’utilisateur et ne doit pas nécessairement être liée à l’ID du flux. Consultez Utiliser foreachBatch pour écrire dans des récepteurs de données arbitraires.
Avertissement
Si vous supprimez le point de contrôle de diffusion en continu et redémarrez la requête avec un nouveau point de contrôle, vous devez fournir un autre txnAppId. Les nouveaux points de contrôle commencent par un ID de lot de 0. Delta Lake utilise l’ID de lot et txnAppId comme clé unique, et ignore les lots avec des valeurs déjà vues.
L’exemple de code suivant illustre ce modèle :
app_id = ... # A unique string that is used as an application ID.
def writeToDeltaLakeTableIdempotent(batch_df, batch_id):
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 1
batch_df.write.format(...).option("txnVersion", batch_id).option("txnAppId", app_id).save(...) # location 2
streamingDF.writeStream.foreachBatch(writeToDeltaLakeTableIdempotent).start()
val appId = ... // A unique string that is used as an application ID.
streamingDF.writeStream.foreachBatch { (batchDF: DataFrame, batchId: Long) =>
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 1
batchDF.write.format(...).option("txnVersion", batchId).option("txnAppId", appId).save(...) // location 2
}
Entrainement
Module
Implémenter des modèles d’architecture de diffusion en continu avec Delta Live Tables - Training
Découvrir la diffusion en continu structurée avec Delta Live Tables
Documentation
Configurer des intervalles de déclencheur Structured Streaming - Azure Databricks
Découvrez comment configurer des intervalles de déclencheur de Structured Streaming sur Azure Databricks.
Utiliser foreachBatch pour écrire dans des récepteurs de données arbitraires - Azure Databricks
Utilisez foreachBatch et foreach pour écrire des sorties personnalisées avec Structured Streaming sur Azure Databricks.
Modèles de flux structuré sur Azure Databricks - Azure Databricks
Consultez des exemples d’utilisation de la diffusion en continu de Spark avec Cassandra, Azure Synapse Analytics, les Notebooks Python et les blocs-notes Scala dans Azure Databricks.