Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
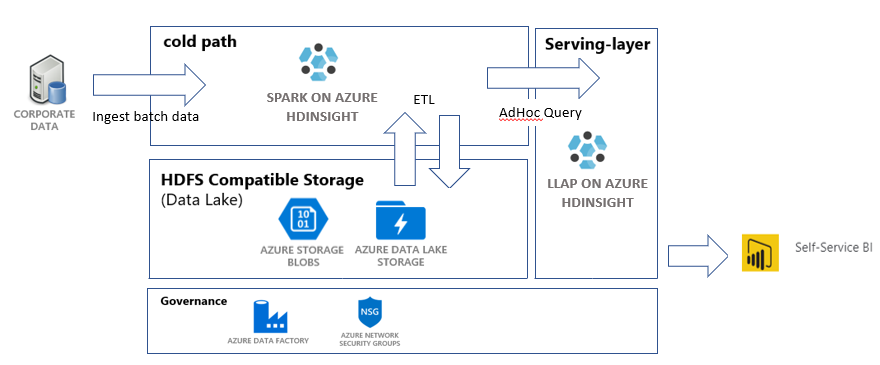
Dans ce tutoriel, vous allez créer un pipeline de données de bout en bout qui effectue des opérations d’extraction, transformation et chargement (ETL). Le pipeline utilise des clusters Apache Spark et Apache Hive s’exécutant sur Azure HDInsight pour interroger et manipuler les données. Vous utiliserez également des technologies comme Azure Data Lake Storage Gen2 pour le stockage des données et Power BI pour la visualisation.
Ce pipeline de données combine les données de différents magasins, supprime les données indésirables, ajoute de nouvelles données et recharge les données dans votre stockage afin que vous puissiez visualiser les insights métier. Si vous souhaitez en savoir plus sur les pipelines ETL, veuillez consulter Extraire, transformer et charger à grande échelle.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
- Azure CLI, version 2.2.0 ou ultérieure. Voir Installer l’interface de ligne de commande Azure.
- jq, processeur JSON en ligne de commande. Consultez le site web jq.
- Un membre du rôle intégré Azure : Propriétaire.
- Si vous utilisez PowerShell pour déclencher le pipeline Azure Data Factory, vous avez besoin du module Az PowerShell.
- Power BI Desktop, pour visualiser les insights métier à la fin de ce tutoriel.
Créer des ressources
Cette section montre comment créer des ressources.
Cloner le dépôt avec des scripts et des données
Connectez-vous à votre abonnement Azure. Si vous prévoyez d’utiliser Azure Cloud Shell, sélectionnez Essayer dans le coin supérieur droit du bloc de code. Sinon, entrez la commande suivante :
az login # If you have multiple subscriptions, set the one to use # az account set --subscription "SUBSCRIPTIONID"Vérifiez que vous êtes membre du rôle Azure Propriétaire. Remplacez
user@contoso.compar votre compte, puis entrez la commande suivante :az role assignment list \ --assignee "user@contoso.com" \ --role "Owner"Si aucun enregistrement n’est retourné, vous n’êtes pas membre et ne pouvez pas suivre ce tutoriel.
Téléchargez les données et les scripts de ce tutoriel à partir du dépôt ETL HDInsight d’insights de ventes. Entrez la commande suivante :
git clone https://github.com/Azure-Samples/hdinsight-sales-insights-etl.git cd hdinsight-sales-insights-etlVérifiez que les
salesdata scripts templatesont été créés. Pour ce faire, utilisez la commande suivante :ls
Déployer les ressources Azure nécessaires pour le pipeline
Ajoutez des autorisations d’exécution pour tous les scripts en entrant la commande suivante :
chmod +x scripts/*.shDéfinissez des variables pour un groupe de ressources. Remplacez
RESOURCE_GROUP_NAMEpar le nom d’un groupe de ressources existant ou nouveau, puis entrez la commande suivante :RESOURCE_GROUP="RESOURCE_GROUP_NAME"Exécutez le script. Remplacez
LOCATIONpar la valeur de votre choix, puis entrez la commande suivante :./scripts/resources.sh $RESOURCE_GROUP LOCATIONSi vous ne savez pas quelle région spécifier, récupérez la liste des régions prises en charge pour votre abonnement à l’aide de la commande az account list-locations.
La commande déploie les ressources suivantes :
- Un compte de stockage Blob Azure. Ce compte contient les données de ventes de l’entreprise.
- Un compte Data Lake Storage Gen2. Ce compte sert de compte de stockage pour les deux clusters HDInsight. Pour en savoir plus sur HDInsight et Data Lake Storage Gen2, consultez Azure HDInsight integration with Data Lake Storage Gen2.
- Identité managée affectée par l’utilisateur. Ce compte donne aux clusters HDInsight l’accès au compte Data Lake Storage Gen2.
- Un cluster Apache Spark. Ce cluster est utilisé pour nettoyer et transformer les données brutes.
- Cluster Interactive Query Apache Hive. Vous pouvez utiliser ce cluster pour interroger les données de ventes et les visualiser avec Power BI.
- Un réseau virtuel Azure pris en charge par des règles de groupe de sécurité réseau. Ce réseau virtuel permet aux clusters de communiquer et sécurise leurs communications.
La création du cluster peut prendre environ 20 minutes.
Le mot de passe par défaut utilisé pour l’accès du protocole Secure Shell (SSH) aux clusters est Thisisapassword1. Si vous souhaitez changer le mot de passe, accédez au fichier ./templates/resourcesparameters_remainder.json, puis modifiez le mot de passe pour les paramètres sparksshPassword, sparkClusterLoginPassword, llapClusterLoginPassword et llapsshPassword.
Vérifier le déploiement et recueillir des informations sur les ressources
Si vous souhaitez vérifier l’état de votre déploiement, accédez au groupe de ressources dans le portail Azure. Sous Paramètres, sélectionnez Déploiements. Sélectionnez ensuite votre déploiement. Ici, vous pouvez voir les ressources qui ont été déployées avec succès et celles qui sont toujours en cours de déploiement.
Pour voir les noms des clusters, entrez la commande suivante :
SPARK_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.sparkClusterName.value') LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') echo "Spark Cluster" $SPARK_CLUSTER_NAME echo "LLAP cluster" $LLAP_CLUSTER_NAMEPour voir le compte de stockage Azure et la clé d’accès, entrez la commande suivante :
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value') blobKey=$(az storage account keys list \ --account-name $BLOB_STORAGE_NAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $BLOB_STORAGE_NAME echo $BLOB_KEYPour voir le compte Data Lake Storage Gen2 et la clé d’accès, entrez la commande suivante :
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value') ADLSKEY=$(az storage account keys list \ --account-name $ADLSGEN2STORAGENAME \ --resource-group $RESOURCE_GROUP \ --query [0].value -o tsv) echo $ADLSGEN2STORAGENAME echo $ADLSKEY
Créer une fabrique de données
Azure Data Factory est un outil qui permet d’automatiser des pipelines Azure. Ce n’est pas l’unique moyen d’effectuer ces tâches, mais c’est un excellent moyen d’automatiser les processus. Si vous souhaitez en savoir plus sur Data Factory, veuillez consulter la documentation Data Factory.
Cette fabrique de données présente un pipeline avec deux activités :
- La première activité copie les données de Stockage Blob vers le compte de stockage Data Lake Storage Gen2 afin d’imiter l’ingestion des données.
- La deuxième activité transforme les données dans le cluster Spark. Le script transforme les données en supprimant les colonnes indésirables. Il ajoute également une nouvelle colonne qui calcule le chiffre d’affaires généré par une transaction unique.
Pour configurer votre pipeline Data Factory, exécutez la commande suivante. Vous devez toujours vous trouver au niveau du répertoire hdinsight-sales-insights-etl.
BLOB_STORAGE_NAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.blobStorageName.value')
ADLSGEN2STORAGENAME=$(cat resourcesoutputs_storage.json | jq -r '.properties.outputs.adlsGen2StorageName.value')
./scripts/adf.sh $RESOURCE_GROUP $ADLSGEN2STORAGENAME $BLOB_STORAGE_NAME
Ce script effectue les actions suivantes :
- Il crée un principal de service avec des autorisations
Storage Blob Data Contributorsur le compte de stockage Data Lake Storage Gen2. - Il obtient un jeton d’authentification pour autoriser les requêtes
POSTauprès de l’API REST du système de fichiers Data Lake Storage Gen2. - Il renseigne le nom réel de votre compte de stockage Data Lake Storage Gen2 dans les fichiers
sparktransform.pyetquery.hql. - Il obtient les clés de stockage pour le compte Data Lake Storage Gen2 et le compte Stockage Blob.
- Il crée un autre déploiement de ressources pour créer un pipeline Data Factory avec ses services liés et ses activités associés. Il transmet les clés de stockage en tant que paramètres au fichier de modèle pour que les services liés puissent accéder correctement aux comptes de stockage.
Exécuter le pipeline de données
Cette section montre comment exécuter le pipeline de données.
Déclencher les activités Data Factory
La première activité dans le pipeline Data Factory que vous avez créée déplace les données de Stockage Blob vers Data Lake Storage Gen2. La deuxième activité applique les transformations Spark aux données et enregistre les fichiers .csv transformés à un nouvel emplacement. L’exécution du pipeline entier peut prendre quelques minutes.
Pour récupérer le nom Data Factory, entrez la commande suivante :
cat resourcesoutputs_adf.json | jq -r '.properties.outputs.factoryName.value'
Pour déclencher le pipeline, vous avez deux options. Vous pouvez :
Déclenchez le pipeline Data Factory dans PowerShell. Remplacez
RESOURCEGROUPetDataFactoryNamepar les valeurs appropriées, puis exécutez les commandes suivantes :# If you have multiple subscriptions, set the one to use # Select-AzSubscription -SubscriptionId "<SUBSCRIPTIONID>" $resourceGroup="RESOURCEGROUP" $dataFactory="DataFactoryName" $pipeline =Invoke-AzDataFactoryV2Pipeline ` -ResourceGroupName $resourceGroup ` -DataFactory $dataFactory ` -PipelineName "IngestAndTransform" Get-AzDataFactoryV2PipelineRun ` -ResourceGroupName $resourceGroup ` -DataFactoryName $dataFactory ` -PipelineRunId $pipelineRéexécutez
Get-AzDataFactoryV2PipelineRunsi nécessaire pour superviser la progression.Vous pouvez également :
Ouvrez la fabrique de données et sélectionnez Créer et surveiller. Déclenchez le pipeline
IngestAndTransformà partir du portail. Si vous souhaitez en savoir plus sur le déclenchement de pipelines via le portail, veuillez consulter Créer des clusters Apache Hadoop à la demande dans HDInsight en utilisant Azure Data Factory.
Pour vérifier que le pipeline a été exécuté, effectuez l’une des étapes suivantes :
- Accédez à la section Superviser de votre fabrique de données par le biais du portail.
- Dans l’Explorateur Stockage Azure, accédez à votre compte de stockage Data Lake Storage Gen2. Accédez au système de fichiers
files, puis au dossiertransformed. Vérifiez le contenu du dossier pour voir si le pipeline a réussi.
Pour découvrir d’autres façons de transformer des données avec HDInsight, consultez cet article sur l’utilisation de Jupyter Notebook.
Créer une table sur le cluster Interactive Query pour afficher les données sur Power BI
Copiez le fichier
query.hqlsur le cluster LLAP en utilisant la commande SCP (copie sécurisée). Entrez la commande :LLAP_CLUSTER_NAME=$(cat resourcesoutputs_remainder.json | jq -r '.properties.outputs.llapClusterName.value') scp scripts/query.hql sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.net:/home/sshuser/Rappel : Le mot de passe par défaut est
Thisisapassword1.Utilisez SSH pour accéder au cluster LLAP. Entrez la commande suivante :
ssh sshuser@$LLAP_CLUSTER_NAME-ssh.azurehdinsight.netUtilisez la commande suivante pour exécuter le script :
beeline -u 'jdbc:hive2://localhost:10001/;transportMode=http' -f query.hqlCe script crée une table managée sur le cluster Interactive Query auquel vous pouvez accéder depuis Power BI.
Créer un tableau de bord Power BI à partir de données de ventes
Ouvrez Power BI Desktop.
Dans le menu, accédez à Obtenir des données>Plus...>Azure>HDInsight Interactive Query.
Sélectionnez Connecter.
Dans la boîte de dialogue HDInsight Interactive Query :
- Dans la zone de texte Serveur, entrez le nom de votre cluster LLAP au format https://LLAPCLUSTERNAME.azurehdinsight.net.
- Dans la zone de texte base de données, entrez default.
- Cliquez sur OK.
Dans la boîte de dialogue AzureHive :
- Dans la zone de texte Nom d’utilisateur, entrez admin.
- Dans la zone de texte Mot de passe, entrez Thisisapassword1.
- Sélectionnez Connecter.
Dans Navigateur, sélectionnez sales ou sales_raw pour afficher un aperçu des données. Une fois les données chargées, vous pouvez faire des essais avec le tableau de bord que vous souhaitez créer. Pour bien démarrer avec les tableaux de bord Power BI, consultez les articles suivants :
Nettoyer les ressources
Si vous ne pensez pas continuer à utiliser cette application, supprimez toutes les ressources pour éviter d’être facturé.
Pour supprimer le groupe de ressources, entrez la commande ci-après :
az group delete -n $RESOURCE_GROUPPour supprimer le principal de service, entrez les commandes ci-après :
SERVICE_PRINCIPAL=$(cat serviceprincipal.json | jq -r '.name') az ad sp delete --id $SERVICE_PRINCIPAL