Tutoriel : Une solution de bout en bout à l’aide d’Azure Machine Learning et IoT Edge
S’applique à :![]() IoT Edge 1.1
IoT Edge 1.1
Important
IoT Edge la date de fin du support 1.1 était le 13 décembre 2022. Consultez la page Politique de support Microsoft pour plus d’informations sur la prise en charge de ce produit, de ce service, de cette technologie ou de cette API. Pour plus d’informations sur la mise à jour vers la dernière version de IoT Edge, consultez Mettre à jour IoT Edge.
Souvent, les applications IoT souhaitent tirer parti du cloud intelligent et de la périphérie intelligente. Dans ce didacticiel, nous vous guidons durant l’apprentissage d’un modèle Machine Learning avec les données collectées à partir d’appareils IoT dans le cloud, suivi du déploiement de ce modèle sur IoT Edge. Pour finir, nous verrons comment assurer périodiquement la maintenance et l’affinement de ce modèle.
Notes
Les concepts abordés dans cet ensemble de tutoriels s’appliquent à toutes les versions d’IoT Edge, mais l’exemple d’appareil que vous créez pour tester le scénario exécute IoT Edge version 1.1.
L’objectif principal de ce didacticiel consiste à expliquer comment fonctionne le traitement des données IoT avec le Machine Learning, en particulier en périphérie. Même si nous abordons plusieurs aspects du flux de travail Machine Learning, ce didacticiel n’est pas une présentation exhaustive du Machine Learning. À titre d’exemple, nous n’essayons pas de créer un modèle hautement optimisé pour le cas d’usage : nous en faisons juste assez pour illustrer le processus de création et d’utilisation d’un modèle viable pour le traitement des données IoT.
Cette section du tutoriel traite des points suivants :
- Prérequis à remplir pour effectuer les étapes suivantes du tutoriel.
- Public cible du tutoriel.
- Cas d’usage simulé par le tutoriel.
- Processus global suivi par le tutoriel pour respecter le cas d’usage.
Si vous n’avez pas d’abonnement Azure, créez un compte gratuit avant de commencer.
Prérequis
Pour suivre ce didacticiel, vous devez avoir un abonnement Azure dans lequel vous disposez des droits pour créer des ressources. Plusieurs services utilisés dans ce didacticiel occasionnent des frais Azure. Si vous n’avez pas d’abonnement Azure, vous pourrez peut-être commencer par utiliser un compte Azure gratuit.
Vous devez également avoir un ordinateur sur lequel PowerShell est installé, et où vous pouvez exécuter des scripts pour configurer une machine virtuelle Azure pour qu’elle soit votre ordinateur de développement.
Voici les outils que nous avons utilisés lors des procédures décrites dans ce document :
Un hub Azure IoT pour la capture des données
Azure Notebooks en tant que serveur frontal principal pour la préparation des données et l’expérimentation Machine Learning. L’exécution du code Python dans un bloc-notes sur un sous-ensemble des données d’échantillon est un excellent moyen d’obtenir une rotation rapide itérative et interactive pendant la préparation des données. Les blocs-notes Jupyter peuvent également servir à préparer des scripts à exécuter à l’échelle dans un serveur principal de calcul.
Azure Machine Learning comme serveur principal pour le Machine Learning à l’échelle et la génération d’image Machine Learning. Nous pilotons le serveur principal Azure Machine Learning à l’aide de scripts conçus et testés dans les blocs-notes Jupyter.
Azure IoT Edge pour l’application en dehors du cloud d’une image Machine Learning
Évidemment, d’autres options sont envisageables. Par exemple, dans certains scénarios, vous pouvez utiliser IoT Central en tant qu’alternative pour capturer des données d’apprentissage initial à partir d’appareils IoT sans utiliser de code.
Public et rôles cibles
Cet ensemble d’articles est destiné aux développeurs n’ayant jamais expérimenté le développement IoT ou le Machine Learning. Le déploiement du Machine Learning en périphérie nécessite des connaissances sur la façon de connecter un large éventail de technologies. Par conséquent, ce didacticiel décrit un scénario complet expliquant de bout en bout comment connecter de telles technologies pour élaborer une solution IoT. Dans un environnement concret, ces tâches peuvent être distribuées entre plusieurs personnes dotées de spécialisations différentes. Par exemple, des développeurs peuvent se concentrer sur le code de l’appareil ou du cloud, tandis que des scientifiques des données conçoivent les modèles d’analyses. Pour qu’un développeur puisse suivre ce didacticiel, nous fournissons des conseils supplémentaires concernant les insights, ainsi que des liens vers d’autres informations qui, nous l’espérons, seront suffisantes pour vous permettre de comprendre le déroulement des procédures.
Vous pouvez également suivre ce didacticiel avec des collègues occupant différents rôles, pour que chacun puisse bénéficier de l’expertise des autres. L’ensemble de votre équipe pourra ainsi comprendre comment mener à bien les procédures adéquates.
Dans tous les cas, dans un souci de lisibilité, chaque article de ce didacticiel indique le rôle prévu pour le lecteur. Ces rôles sont les suivants :
- Développeur cloud (dont un développeur cloud travaillant selon la méthode DevOps)
- L’Analytique données
Cas d’usage Maintenance prédictive
Ce scénario repose sur un cas d’usage présenté lors d’une conférence intitulée Prognostics and Health Management (« Prognostics et gestion de l’intégrité ») donnée en 2008. L’objectif consiste à prévoir la durée de vie restante d’un ensemble de moteurs d’avion à turboréacteurs. Ces données ont été générées à l’aide de C-MAPSS, la version commerciale du logiciel MAPSS (Modular Aero-Propulsion System Simulation, ou « Simulation d’un système aéro-propulseur modulaire »). Ce logiciel fournit un environnement flexible simulant le fonctionnement d’un moteur à turboréacteur. Il permet d’établir facilement des paramètres de simulation concernant l’intégrité, le contrôle et le moteur en lui-même.
Les données utilisées dans ce didacticiel provient du jeu de données de simulation de dégradation du turboréacteur.
Voici ce qu’en dit le fichier Readme (Lisez-moi) :
Scénario expérimental
Ces jeux de données se composent de plusieurs séries chronologiques multidimensionnelles. Chaque jeu de données est divisé en sous-ensembles d’entraînement et de test. Chaque série chronologique provient d’un moteur différent, c’est-à-dire que les données peuvent être considérées comme provenant d’une flotte de moteurs du même type. Chaque moteur a un niveau d’usure initial différent et des variations de fabrication, que l’utilisateur ne connaît pas. Cette usure et ces variations sont considérées comme normales. Elles ne sont donc pas considérées comme étant des conditions d’erreurs. Trois paramètres opérationnels ont un effet important sur les performances du moteur. Ces paramètres sont également inclus dans les données. Les données sont contaminées par le bruit du capteur.
Le moteur fonctionne normalement au début de chaque série chronologique et développe une erreur à un moment donné. Dans le jeu d’apprentissage, la grandeur de l’erreur augmente jusqu’à la défaillance du système. Dans le jeu de test, la série chronologique se termine peu de temps avant la défaillance du système. L’objectif de cette comparaison est d’établir une prévision du nombre de cycles opérationnels restants avant que la défaillance survienne dans le jeu de test. Cela permettra de prévoir le nombre de cycles opérationnels après le dernier cycle pendant lesquels le moteur continuera de fonctionner. Un vecteur des valeurs réelles de la durée de vie restante est également fourni pour les données de test.
Comme les données a été publiées pour un concours, plusieurs méthodes de dérivation de modèles Machine Learning ont été publiées indépendamment. Nous avons constaté que l’étude des exemples est utile pour comprendre le processus et le raisonnement impliqués dans la création d’un modèle Machine Learning. Vous pouvez notamment consulter ces modèles :
Modèle de prévision de défaillance d’un moteur d’avion de l’utilisateur de GitHub jancervenka.
Dégradation d’un moteur à turboréacteur de l’utilisateur de GitHub hankroark.
Processus
L’image ci-dessous représente une synthèse des étapes de ce didacticiel :
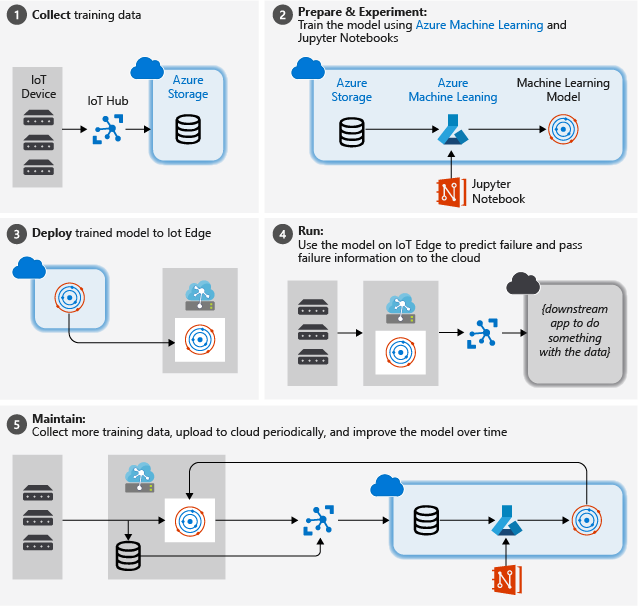
Collecte des données d’apprentissage : Le processus commence par collecter les données d’apprentissage. Dans certains cas, les données a déjà été collectées et sont disponibles dans une base de données, ou sous forme de fichiers de données. Dans d’autres cas, en particulier pour les scénarios IoT, les données doivent être collectées à partir des capteurs et appareils IoT et stockées dans le cloud.
Nous partons du principe que n’avez pas tout un stock de moteurs à turboréacteurs sous la main. Les fichiers de projet incluent donc un simulateur d’appareil facile à utiliser, qui transmet les données des appareils de la NASA vers le cloud.
Préparation des données : Dans la plupart des cas, les données brutes recueillies à partir d’appareils et de capteurs nécessiteront une préparation pour le Machine Learning. Cette étape peut comprendre le nettoyage des données, le reformatage des données ou le prétraitement pour injecter des informations supplémentaires que le Machine Learning peut exploiter.
Dans le cadre des données machine provenant des moteurs d’avion, la préparation des données consiste à calculer les délais avant chaque défaillance de façon explicite pour chaque point de données de l’échantillon à partir des observations réelles figurant dans les données. Ces informations permettent à l’algorithme Machine Learning de détecter des corrélations entre les données réelles des capteurs et la prévision de durée de vie restante du moteur. Cette étape est particulièrement spécifique à un domaine.
Développement d’un modèle Machine Learning : En nous basant sur les données préparées, nous pouvons maintenant faire des essais avec des algorithmes d’apprentissage et des paramétrages différents pour former des modèles et comparer les résultats entre eux.
Dans ce cas, pour le test, nous comparons la prévision calculée par le modèle avec le résultat réel observé sur un ensemble de moteurs. Dans Azure Machine Learning, nous pouvons gérer les différentes itérations de modèles que nous créons dans un registre de modèles.
Déploiement du modèle : Lorsque nous avons un modèle qui répond à nos critères de réussite, nous pouvons passer au déploiement. Cela implique l’inclusion dans un wrapper du modèle dans une application de service web pouvant être alimentée avec des données à l’aide d’appels REST. Cette dernière retourne ensuite les résultats de l’analyse. L’application de service web est ensuite empaquetée dans un conteneur Docker qui, à son tour, peut être déployé dans le cloud ou en tant que module IoT Edge. Dans cet exemple, nous optons pour un déploiement sur IoT Edge.
Mise à jour et affinage du modèle : Après le déploiement du modèle, notre travail continue. En règle générale, nous voulons poursuivre la collecte des données et télécharger régulièrement ces données vers le cloud. Nous pouvons ensuite utiliser ces données pour reformer et affiner notre modèle, que nous pouvons ensuite redéployer sur IoT Edge.
Nettoyer les ressources
Ce tutoriel fait partie d’une série où chaque article s’appuie sur le travail effectué dans les articles précédents. Ne nettoyez pas les ressources avant d’avoir terminé le dernier tutoriel.
Étapes suivantes
Ce didacticiel comprend les sections suivantes :
- Configurer votre machine de développement et les services Azure
- Générer les données d’apprentissage pour le module Machine Learning
- Effectuer l’apprentissage d’un modèle Machine Learning, puis le déployer
- Configurer un appareil IoT Edge en tant que passerelle transparente
- Créer et déployer des modules IoT Edge
- Transmettre des données à votre appareil IoT Edge
Passez à l’article suivant pour configurer un ordinateur de développement et des ressources Azure.