Exécuter des prédictions par lots à l’aide du concepteur Azure Machine Learning
Dans cet article, vous allez apprendre à utiliser le concepteur pour créer un pipeline de prédiction par lots. La prédiction par lots vous permet de noter en continu et à la demande des jeux de données volumineux via un service web qui peut être déclenché à partir de n'importe quelle bibliothèque HTTP.
Au cours de cette procédure, vous allez apprendre à effectuer les tâches suivantes :
- Créer et publier un pipeline d'inférence par lots
- Utiliser un point de terminaison de pipeline
- Gérer les versions d'un point de terminaison
Pour découvrir comment configurer les services de scoring par lot à l'aide du Kit de développement logiciel (SDK), consultez le didacticiel sur le scoring par lots du pipeline.
Prérequis
Cette procédure suppose que vous disposez déjà d'un pipeline de formation. Pour accéder à une présentation guidée du concepteur, suivez la première partie du tutoriel du concepteur.
Important
Si vous ne voyez pas les éléments graphiques mentionnés dans ce document, tels que les boutons dans Studio ou le concepteur, vous ne disposez peut-être pas du niveau d’autorisations approprié pour l’espace de travail. Contactez votre administrateur d’abonnement Azure pour vérifier que le niveau d’accès est correct. Pour plus d’informations, consultez Gérer les utilisateurs et les rôles.
Créer un pipeline d’inférence par lots
Votre pipeline de formation doit être exécuté au moins une fois pour créer un pipeline d'inférence.
Accédez à l'onglet Concepteur de votre espace de travail.
Sélectionnez le pipeline d’entraînement qui entraîne le modèle que vous voulez utiliser pour faire une prédiction.
Envoyez le pipeline.
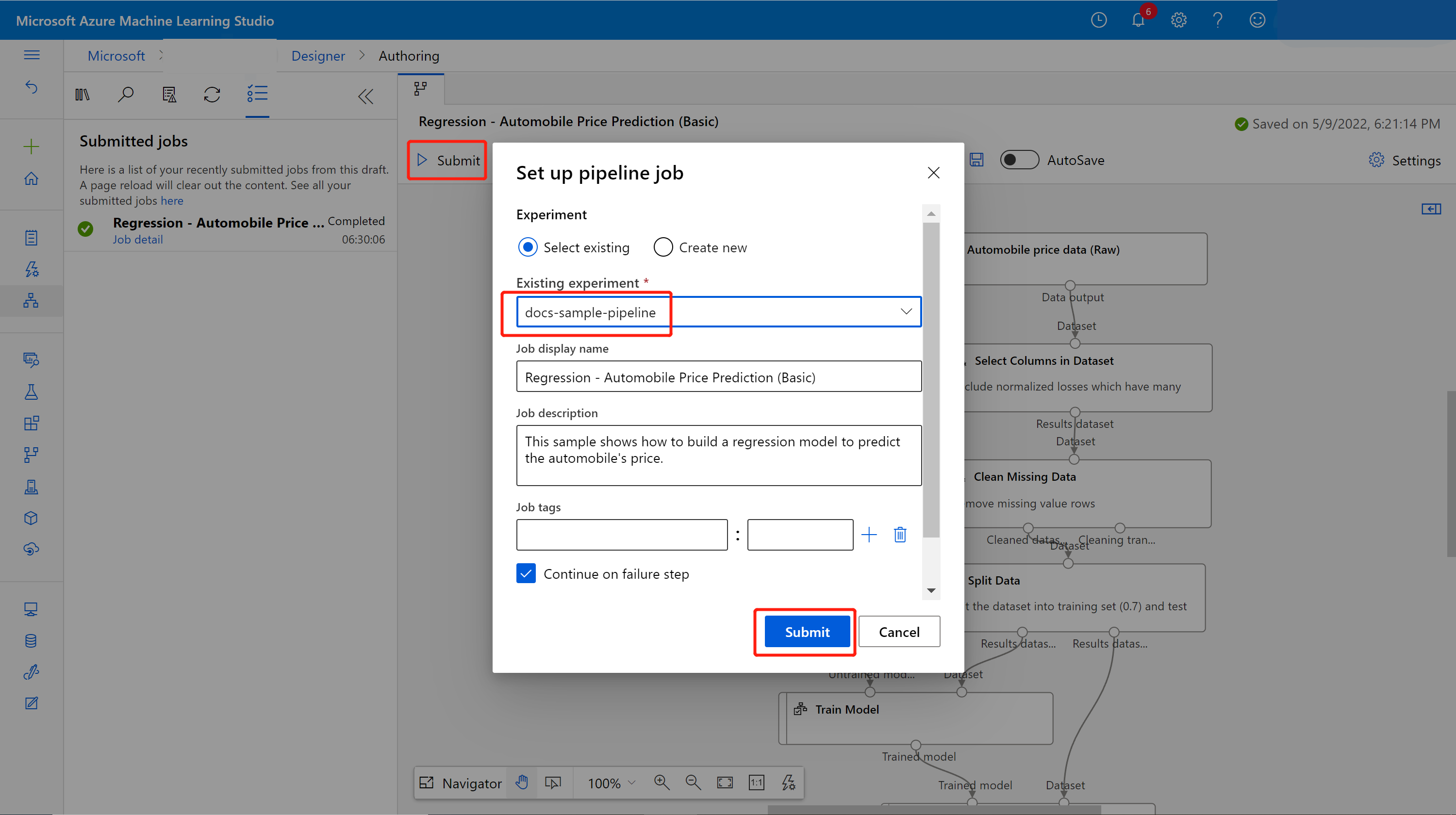

Vous verrez une liste de soumissions à gauche du panneau canevas. Vous pouvez sélectionner le lien des détails du travail pour accéder à la page contenant ceux-ci et, une fois le travail du pipeline d’apprentissage terminé, vous pouvez créer un pipeline d’inférence par lot.

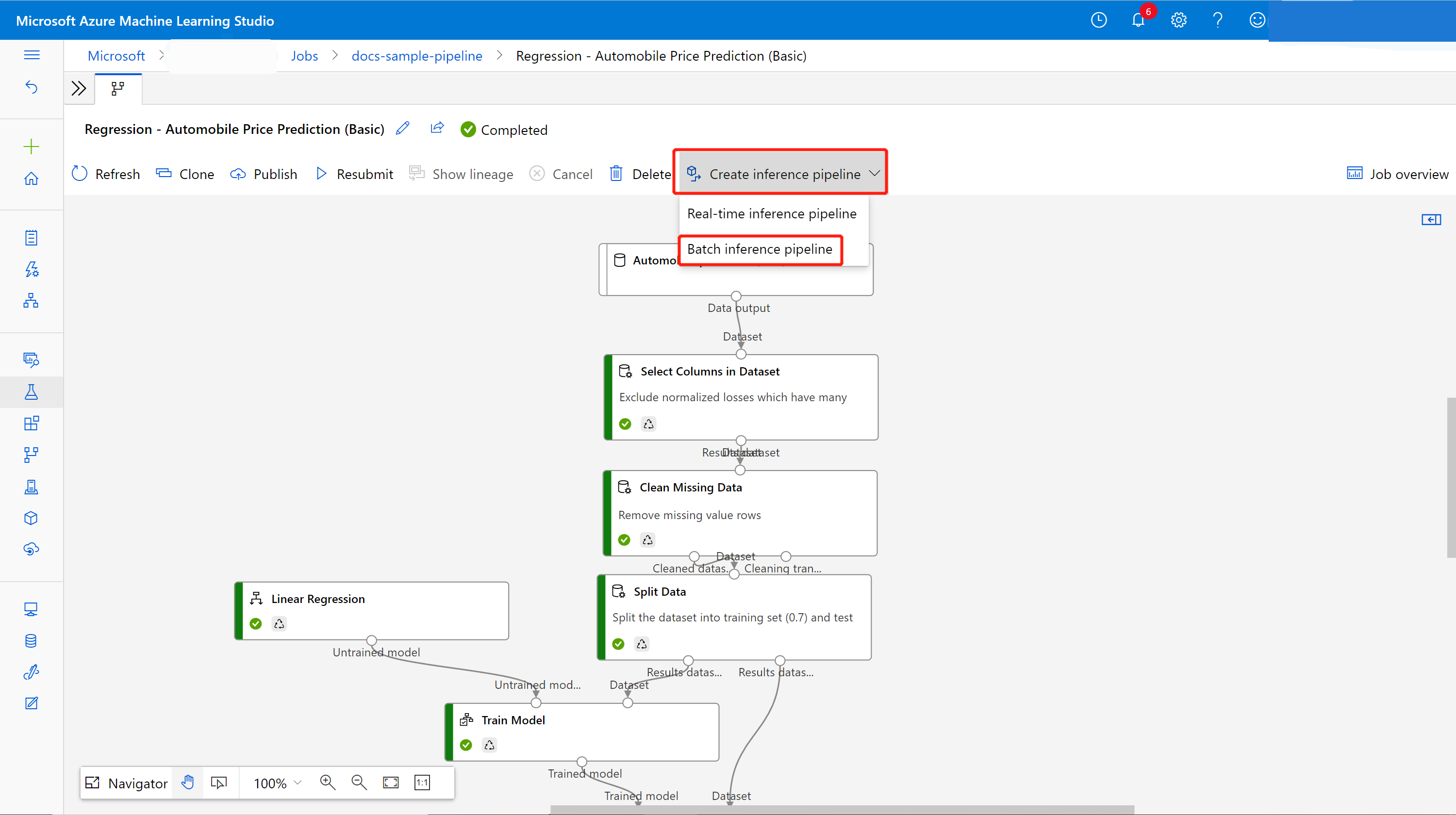
Dans la page des détails du travail, au-dessus du panneau canevas, sélectionnez la liste déroulante Créer un pipeline d’inférence. Sélectionnez Pipeline d'inférence par lots.
Notes
Actuellement, le pipeline d’inférence généré automatiquement fonctionne uniquement pour le pipeline d’apprentissage généré par les composants intégrés du concepteur.
Il crée un brouillon de pipeline d’inférence par lot pour vous. Le brouillon de pipeline d’inférence par lot utilise le modèle formé en tant que nœud MD-, et la transformation en tant que nœud TD- à partir du travail de pipeline d’apprentissage.
Vous pouvez également modifier ce brouillon de pipeline d’inférence pour mieux gérer vos données d’entrée pour l’inférence par lot.
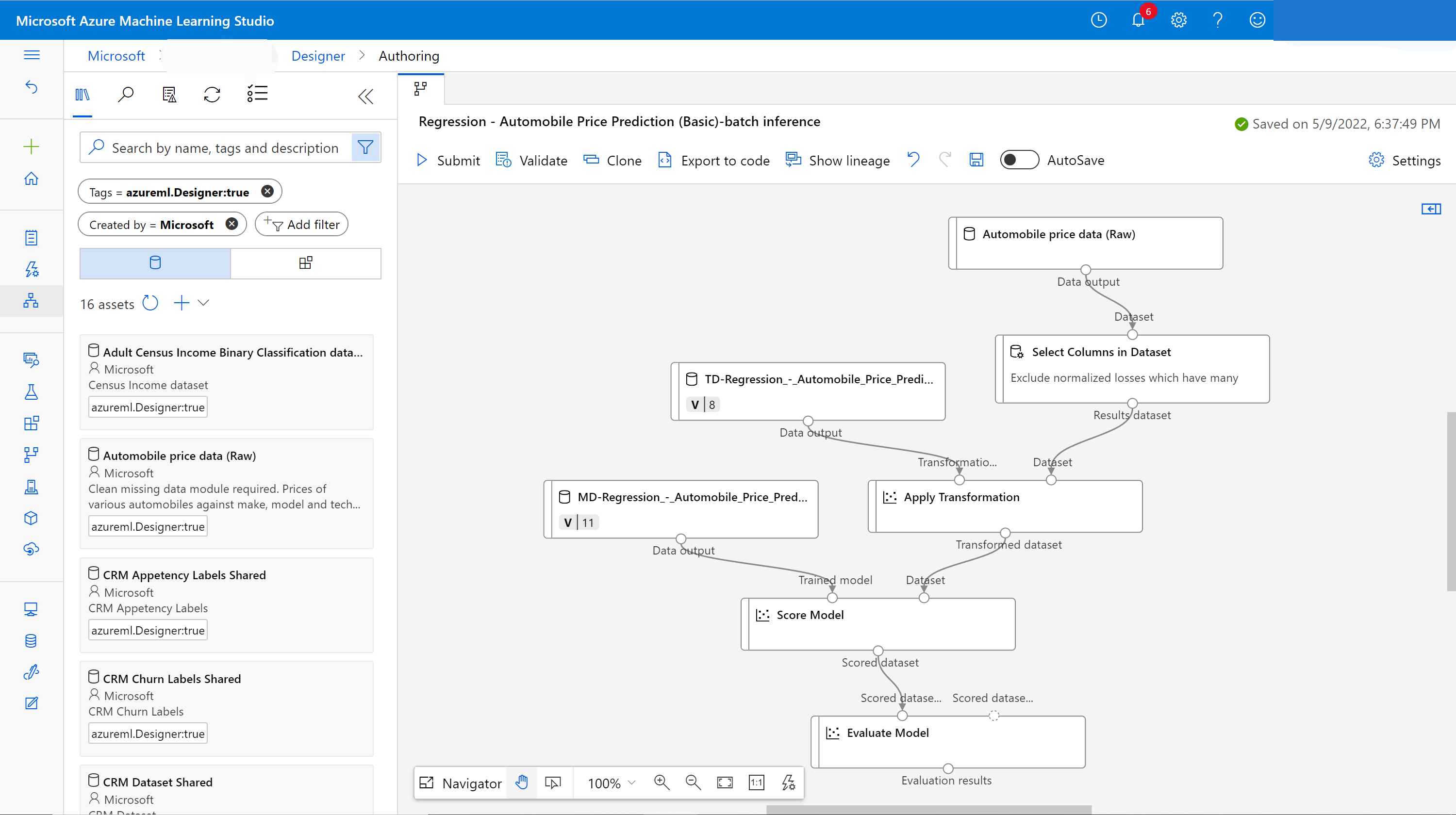


Ajouter un paramètre de pipeline
Pour créer des prédictions sur de nouvelles données, vous pouvez connecter manuellement un autre jeu de données dans le mode Brouillon de ce pipeline ou créer un paramètre pour votre jeu de données. Les paramètres vous permettent de modifier le comportement du processus d'inférence par lots lors de l'exécution.
Dans cette section, vous allez créer un paramètre de jeu de données afin de spécifier un autre jeu de données pour les prédictions.
Sélectionnez le composant Jeu de données.
Un volet s'affiche à droite du canevas. En bas du volet, sélectionnez Définir en tant que paramètre de pipeline.
Entrez un nom pour le paramètre, ou acceptez la valeur par défaut.

Soumettez le pipeline d’inférence par lot et accédez à la page des détails du travail en sélectionnant le lien du travail dans le volet gauche.

Publier votre pipeline d'inférence par lots
Vous êtes maintenant prêt à déployer le pipeline d'inférence. Cela permettra de déployer le pipeline et de le mettre à la disposition d'autres utilisateurs.
Cliquez sur le bouton Publier.
Dans la boîte de dialogue qui s'affiche, développez la liste déroulante Point de terminaison de pipeline et sélectionnez Nouveau point de terminaison de pipeline.
Attribuez un nom et une description (facultative) au point de terminaison.
Dans la partie inférieure de la boîte de dialogue, vous pouvez voir le paramètre que vous avez configuré avec une valeur par défaut de l'ID du jeu de données utilisé lors de la formation.
Sélectionnez Publier.

Utiliser un point de terminaison
Vous disposez maintenant d'un pipeline publié avec un paramètre de jeu de données. Le pipeline utilisera le modèle formé créé dans le pipeline de formation pour noter le jeu de données que vous fournissez en tant que paramètre.
Envoyer un travail de pipeline
Dans cette section, vous allez configurer un travail de pipeline manuel et modifier le paramètre du pipeline pour noter les nouvelles données.
Au terme du déploiement, accédez à la section Points de terminaison.
Sélectionnez Points de terminaison de pipeline.
Sélectionnez le nom du point de terminaison que vous avez créé.
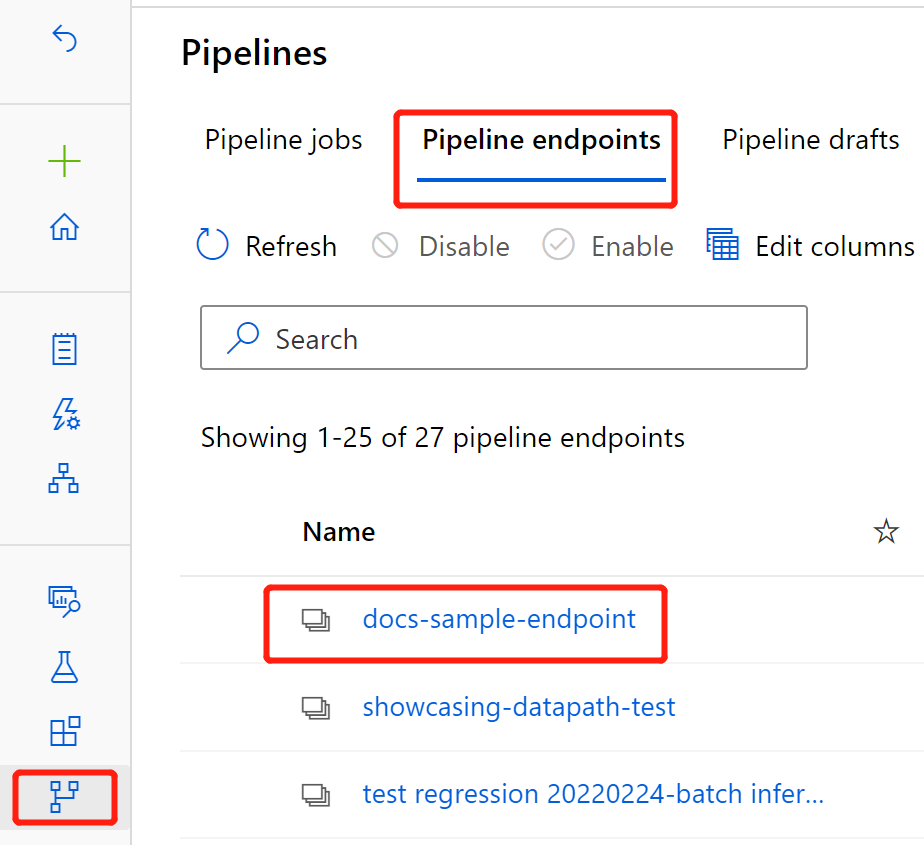
Sélectionnez Pipelines publiés.
Cet écran affiche tous les pipelines publiés sous ce point de terminaison.
Sélectionnez le pipeline que vous avez publié.
La page Détails du pipeline affiche l’historique détaillé des travaux ainsi que des informations sur les chaînes de connexion de votre pipeline.
Sélectionnez Envoyer pour créer une exécution manuelle du pipeline.

Modifiez le paramètre pour utiliser un autre jeu de données.
Sélectionnez Envoyer pour exécuter le pipeline.

Utiliser le point de terminaison REST
Pour plus d'informations sur l'utilisation des points de terminaison de pipeline et sur le pipeline publié, consultez la section Points de terminaison.
Vous trouverez le point de terminaison REST d’un point de terminaison de pipeline dans le panneau de présentation du travail. En appelant le point de terminaison, vous utilisez son pipeline publié par défaut.
Vous pouvez également utiliser un pipeline publié sur la page Pipelines publiés. Sélectionnez un pipeline publié. Vous pouvez y trouver le point de terminaison REST dans le volet Vue d’ensemble des pipelines publiés à droite du graphique.
Pour effectuer un appel REST, vous devez disposer d’un en-tête d’authentification de type porteur OAuth 2.0. Pour plus d’informations sur la configuration de l’authentification dans votre espace de travail et sur l’exécution d’un appel REST paramétrable, consultez ce tutoriel.
Contrôle de version des points de terminaison
Le concepteur attribue une version à chacun des pipelines ultérieurs que vous publiez sur un point de terminaison. Vous pouvez spécifier la version du pipeline que vous souhaitez exécuter en tant que paramètre dans votre appel REST. Si vous ne spécifiez aucun numéro de version, le concepteur utilisera le pipeline par défaut.
Lorsque vous publiez un pipeline, vous pouvez choisir de le définir comme nouveau pipeline par défaut du point de terminaison.
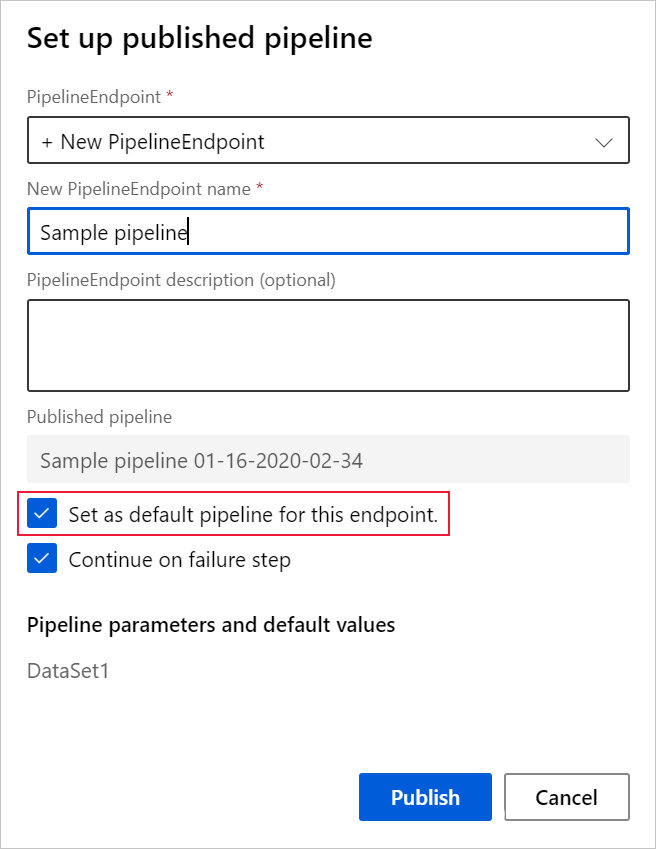
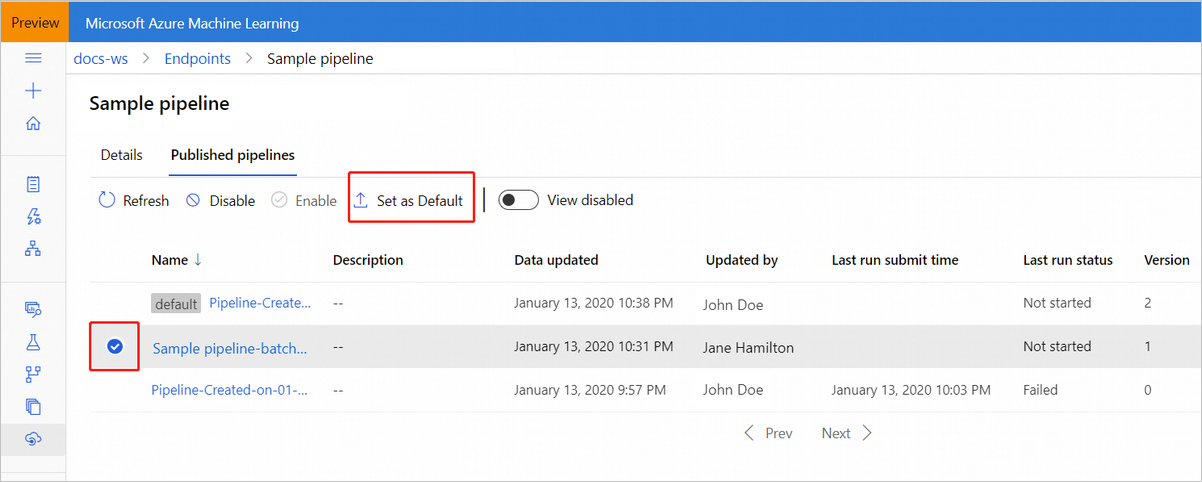
Vous pouvez également définir un nouveau pipeline par défaut sous l'onglet Pipelines publiés de votre point de terminaison.
Mettre à jour le point de terminaison de pipeline
Si vous apportez des modifications à votre pipeline d’apprentissage, vous pouvez mettre à jour le modèle nouvellement formé vers le point de terminaison du pipeline.
Une fois votre pipeline d’apprentissage modifié, accédez à la page des détails du travail.
Cliquez avec le bouton droit sur le composant Effectuer l'apprentissage du modèle, puis sélectionnez Inscrire les données
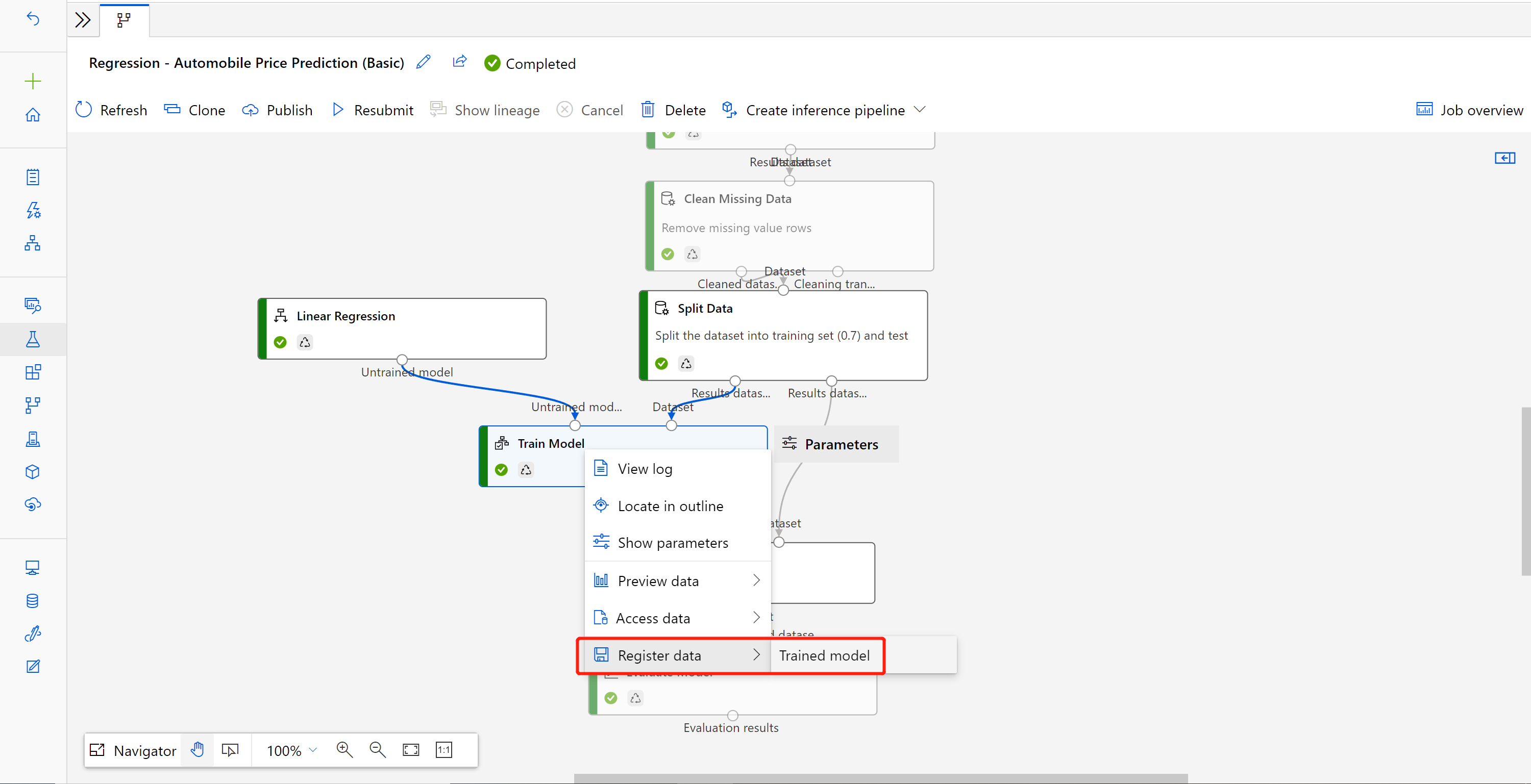
Entrez un nom et sélectionnez le type Fichier.
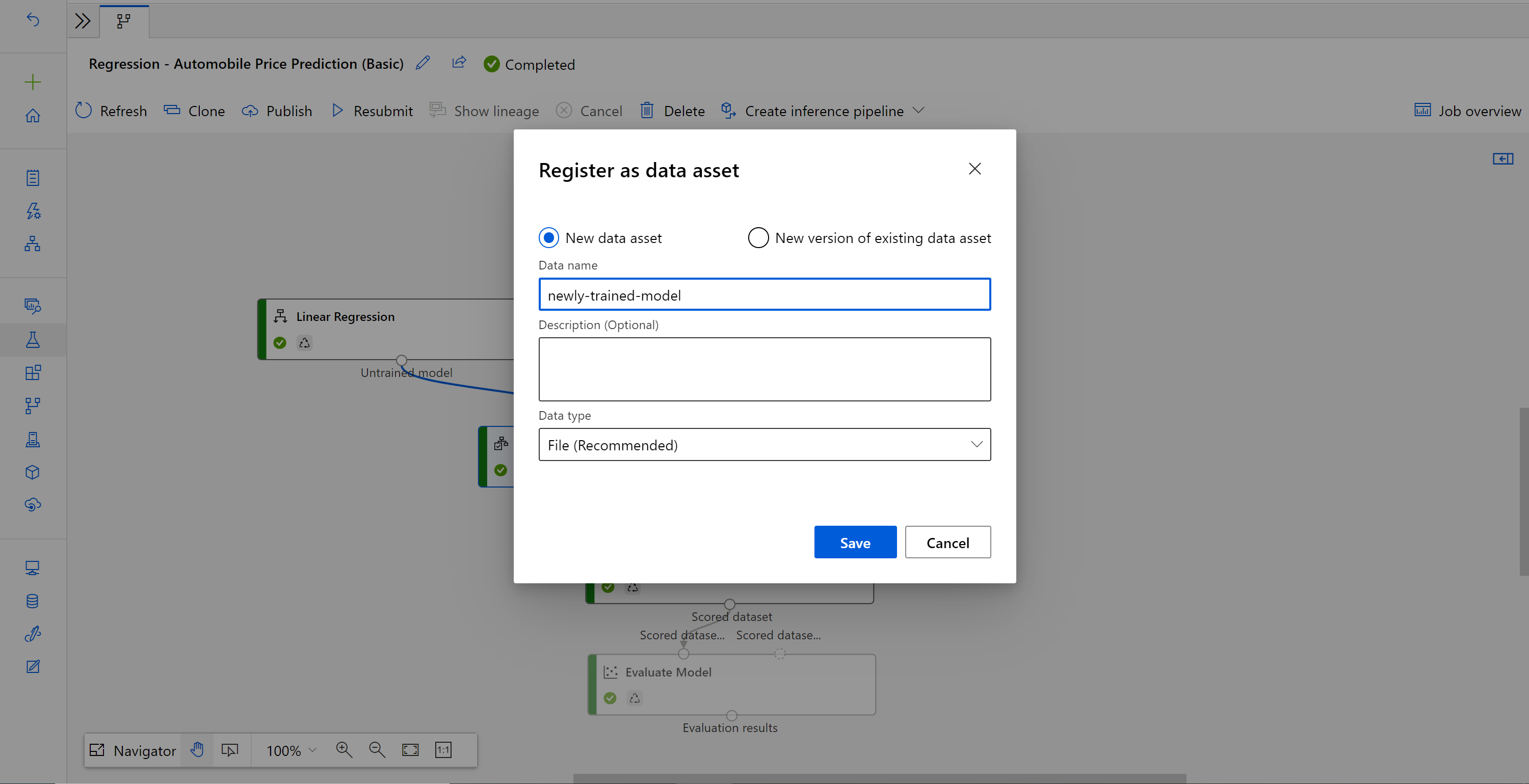
Recherchez le brouillon de pipeline d’inférence par lot précédent. Vous pouvez aussi simplement Cloner le pipeline publié dans un nouveau brouillon.
Remplacez le nœud MD- dans le brouillon de pipeline d’inférence par les données inscrites à l’étape ci-dessus.
La mise à jour du nœud de transformation de données TD- est identique à celle du modèle formé.
Vous pouvez ensuite soumettre le pipeline d’inférence avec le modèle et la transformation mis à jour, puis republier.


Étapes suivantes
- Suivez le tutoriel du concepteur pour effectuer l’apprentissage d’un modèle de régression et le déployer.
- Pour savoir comment publier et exécuter un pipeline publié à l’aide du Kit de développement logiciel (SDK) v1, consultez l’article Déploiement des pipelines.