Déployer un modèle sur un cluster Azure Kubernetes Service avec v1
Important
Cet article explique comment utiliser l’interface CLI Azure Machine Learning (v1) et le kit de développement logiciel (SDK) Azure Machine Learning pour Python (v1) pour déployer un modèle. Pour l’approche recommandée pour v2, consultez Déployer et évaluer un modèle de Machine Learning à l’aide d’un point de terminaison en ligne.
Découvrez comment utiliser Azure Machine Learning pour déployer un modèle en tant que service web sur Azure Kubernetes service (AKS). AKS convient aux déploiements de production à grande échelle. Utilisez AKS si vous avez besoin d’une ou plusieurs des fonctionnalités suivantes :
- Temps de réponse rapide
- Mise à l’échelle automatique du service déployé
- Logging
- Collection de données de modèle
- Authentification
- Arrêt TLS
- Options d’accélération matérielle telles que le GPU et les FPGA (Field-Programmable Gate Array)
Lors d’un déploiement sur AKS, vous déployez sur un cluster AKS qui est connecté à votre espace de travail. Pour en savoir plus sur la connexion d’un cluster AKS à votre espace de travail, consultez Créer et attacher un cluster Azure Kubernetes Service.
Important
Nous vous recommandons de procéder à un débogage local avant le déploiement sur le service web. Pour plus d’informations, consultez Résolution des problèmes avec un déploiement de modèle local.
Vous pouvez également consulter Déployer sur un notebook local sur GitHub.
Remarque
Les points de terminaison Azure Machine Learning (v2) offrent une expérience de déploiement plus simple et améliorée. Les points de terminaison prennent en charge les scénarios d’inférence en temps réel et par lot. Les points de terminaison fournissent une interface unifiée pour appeler et gérer des déploiements de modèle pour différents types de calcul. Voir Quels sont les points de terminaison Azure Machine Learning ?.
Prérequis
Un espace de travail Azure Machine Learning. Pour plus d’informations, voir la page Créer un espace de travail Azure Machine Learning.
Un modèle Machine Learning inscrit dans votre espace de travail. Si vous n’avez pas de modèle inscrit, consultez Déployer des modèles Machine Learning sur Azure.
L’extension Azure CLI (v1) pour Machine Learning service, le SDK Azure Machine Learning pour Python ou l’extension Azure Machine Learning pour Visual Studio Code.
Important
Certaines des commandes Azure CLI de cet article utilisent l’extension
azure-cli-ml, ou v1, pour Azure Machine Learning. La prise en charge de l’extension v1 se termine le 30 septembre 2025. Vous pourrez installer et utiliser l’extension v1 jusqu’à cette date.Nous vous recommandons de passer à l’extension
ml, ou v2, avant le 30 septembre 2025. Pour plus d’informations sur l’extension v2, consultez Extension Azure ML CLI et le SDK Python v2.Les extraits de code Python de cet article partent du principe que les variables suivantes sont définies :
ws– Sur votre espace de travail.model– Sur votre modèle inscrit.inference_config– Sur la configuration d’inférence pour le modèle.
Pour plus d’informations sur le paramétrage de ces variables, consultez la section Comment et où déployer des modèles ?
Les extraits de code CLI de cet article partent du principe que vous avez déjà créé un document inferenceconfig.json. Pour plus d’informations sur la création de ce document, consultez Déployer des modèles Machine Learning sur Azure.
Un cluster AKS connecté à votre espace de travail. Pour plus d’informations, consultez Créer et attacher un cluster Azure Kubernetes Service.
- Si vous souhaitez déployer des modèles sur des nœuds GPU ou FPGA (ou sur un produit spécifique), vous devez créer un cluster de la référence SKU en question. Il n'y a pas de prise en charge pour la création d'un pool de nœuds secondaires dans un cluster existant et le déploiement de modèles dans le pool de nœuds secondaires.
Comprendre les processus de déploiement
Le mot déploiement est utilisé à la fois dans Kubernetes et Azure Machine Learning. Déploiement a des significations différentes dans ces deux contextes. Dans Kubernetes, un déploiement est une entité concrète, spécifiée avec un fichier YAML déclaratif. Un déploiement Kubernetes a un cycle de vie défini et des relations concrètes avec d’autres entités Kubernetes, telles que Pods et ReplicaSets. Vous pouvez en savoir plus sur Kubernetes à partir des documents et des vidéos sur Qu’est-ce que Kubernetes ?.
Dans Azure Machine Learning, le déploiement est utilisé dans le sens le plus général pour mettre à disposition et nettoyer vos ressources de projet. Les étapes qu’Azure Machine Learning prend en compte dans le cadre du déploiement sont les suivantes :
- Compression des fichiers dans votre dossier de projet, en ignorant ceux spécifiés dans .amlignore ou .gitignore
- Mise à l’échelle de votre cluster de calcul (en relation avec Kubernetes)
- Création ou téléchargement du dockerfile sur le nœud de calcul (en relation avec Kubernetes)
- Le système calcule un code de hachage pour :
- l’image de base ;
- les étapes Docker personnalisées (voir Déployer un modèle à l’aide d’une image de base Docker personnalisée) ;
- la définition Conda YAML (voir Créer et utiliser des environnements logiciels dans Azure Machine Learning).
- Le système utilise ce code de hachage comme clé pour rechercher le Dockerfile dans l’espace de travail Azure Container Registry (ACR).
- Si le Dockerfile est introuvable, il recherche une correspondance dans l’ensemble d’ACR.
- Si le Dockerfile est introuvable, le système génère une nouvelle image qui est mise en cache et envoyée à l’espace de travail ACR.
- Le système calcule un code de hachage pour :
- Téléchargement de votre Fichier projet compressé vers le stockage temporaire sur le nœud de calcul
- Décompression du Fichier projet
- Nœud de calcul exécutant
python <entry script> <arguments> - Enregistrement des journaux, des fichiers de modèle et des autres fichiers écrits dans ./outputs dans le compte de stockage associé à l’espace de travail
- Scale down du calcul, notamment la suppression du stockage temporaire (en relation avec Kubernetes)
Routeur Azure Machine Learning
Le composant frontal (azureml-fe) qui achemine les demandes d’inférence entrantes vers les services déployés se met à l’échelle automatiquement selon les besoins. La mise à l’échelle du composant azureml-fe se fait en fonction de l’objet et de la taille (nombre de nœuds) du cluster AKS. L’objet et les nœuds du cluster sont configurés lorsque vous créez ou attachez un cluster AKS. Il y a un service azureml-fe par cluster, qui peut être exécuté sur plusieurs pods.
Important
Lorsque vous utilisez un cluster configuré comme dev-test, le processus de mise à l’échelle automatique est désactivé. Même pour les clusters FastProd/DenseProd, Self-Scaler est activé uniquement lorsque la télémétrie indique que cela est nécessaire.
Notes
La charge utile maximale d’une requête est de 100 Mo.
Azureml-fe met à l’échelle aussi bien verticalement, de façon à utiliser plus de cœurs, qu’horizontalement, de façon à utiliser plus de pods. En cas de choix d’un scale-up, on tient compte du temps nécessaire pour acheminer les demandes d’inférence entrantes. Si cette durée dépasse le seuil, un scale-up est effectué. Si le temps nécessaire pour acheminer les demandes entrantes continue de dépasser le seuil, un scale-out est effectué.
En cas de scale-down et de scale-in, on tient compte de l’utilisation du processeur. Si le seuil d’utilisation du processeur est atteint, c’est le serveur frontal qui est mis à l’échelle en premier lieu. Si l’utilisation du processeur tombe au seuil du scale-in, une opération de scale-in est effectuée. Les opérations de scale-up et de scale-out se produisent uniquement si le cluster dispose de ressources suffisantes.
Lors du scale-up/scale-down, les pods azureml-fe sont redémarrés pour appliquer les modifications de l’UC ou de la mémoire. Les redémarrages n’affectent pas les demandes d’inférence.
Comprendre les exigences de connectivité pour le cluster d’inférence AKS
Lorsqu’Azure Machine Learning crée ou rattache un cluster AKS, le cluster AKS est déployé avec l’un des deux modèles de réseau suivants :
- Mise en réseau Kubenet : les ressources réseau sont généralement créées et configurées quand le cluster AKS est déployé.
- Mise en réseau Azure CNI (Container Networking Interface) : le cluster AKS est connecté à des configurations et à une ressource de réseau virtuel existantes.
Pour la mise en réseau Kubenet, le réseau est créé et configuré correctement pour Azure Machine Learning service. Pour la mise en réseau CNI, vous devez comprendre les besoins de connectivité et garantir la résolution DNS et la connectivité sortante pour l’inférence AKS. Par exemple, vous utilisez peut-être un pare-feu pour bloquer le trafic réseau.
Le diagramme suivant montre les besoins de connectivité pour l’inférence AKS. Les flèches noires représentent la communication réelle et les flèches bleues représentent les noms de domaine. Vous devrez peut-être ajouter des entrées pour ces hôtes à votre pare-feu ou à votre serveur DNS personnalisé.
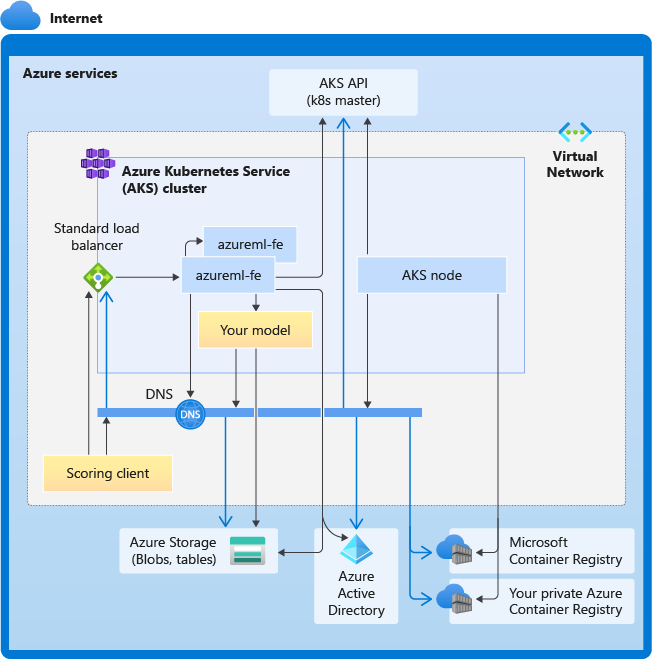
Pour connaître les exigences de connectivité AKS, consultez Limiter le trafic réseau avec le pare-feu Azure dans AKS.
Pour accéder aux services Azure Machine Learning derrière un pare-feu, consultez Configurer le trafic réseau entrant et sortant.
Exigences globales de la résolution DNS
La résolution DNS au sein d’un réseau virtuel existant est sous votre contrôle. Par exemple, un pare-feu ou un serveur DNS personnalisé. Les hôtes suivants doivent être accessibles :
| Nom de l’hôte | Utilisée par |
|---|---|
<cluster>.hcp.<region>.azmk8s.io |
Serveur d’API AKS |
mcr.microsoft.com |
Microsoft Container Registry (MCR) |
<ACR name>.azurecr.io |
Votre ACR (Azure Container Registry) |
<account>.table.core.windows.net |
Compte Stockage Azure (stockage Table) |
<account>.blob.core.windows.net |
Compte Stockage Azure (stockage Blob) |
api.azureml.ms |
Authentification Microsoft Entra |
ingest-vienna<region>.kusto.windows.net |
Point de terminaison Kusto pour le chargement des données de télémétrie |
<leaf-domain-label + auto-generated suffix>.<region>.cloudapp.azure.com |
Nom de domaine du point de terminaison, si vous l’avez généré automatiquement avec Azure Machine Learning. Si vous avez utilisé un nom de domaine personnalisé, vous n’avez pas besoin de cette entrée. |
Exigences de connectivité dans l’ordre chronologique
Dans le processus de création ou d’attachement d’AKS, le routeur Azure Machine Learning (azureml-fe) est déployé dans le cluster AKS. Pour déployer le routeur Azure Machine Learning, le nœud AKS doit être en mesure d’effectuer les opérations suivantes :
- Résoudre le DNS pour le serveur d’API AKS
- Résoudre le DNS pour MCR afin de télécharger des images Docker pour le routeur Azure Machine Learning
- Télécharger des images à partir de MCR, où une connectivité sortante est requise
Juste après le déploiement d’azureml-fe, il tente de démarrer et cela nécessite les opérations suivantes :
- Résoudre le DNS pour le serveur d’API AKS
- Interroger le serveur d’API AKS pour découvrir d’autres instances de lui-même (il s’agit d’un service à plusieurs pods)
- Se connecter à d’autres instances de soi-même
Une fois azureml-fe démarré, il nécessite la connectivité suivante pour fonctionner correctement :
- Se connecter à Stockage Azure pour télécharger la configuration dynamique
- Résoudre le DNS pour le serveur d’authentification Microsoft Entra api.azureml.ms et communiquer avec celui-ci lorsque le service déployé utilise l’authentification Microsoft Entra.
- Interroger le serveur d’API AKS pour découvrir les modèles déployés
- Communiquer avec les pods du modèle déployé
Au moment du déploiement du modèle, pour que le déploiement du modèle soit réussi, le nœud AKS doit être en mesure d’effectuer les opérations suivantes :
- Résoudre le DNS pour l’ACR du client
- Télécharger des images à partir de l’ACR du client
- Résoudre le DNS pour les Blobs Azure sur lesquels le modèle est stocké
- Télécharger des modèles à partir de Blobs Azure
Après le déploiement du modèle et le démarrage du service, azureml-fe le découvre automatiquement grâce à l’API AKS et est prêt à acheminer la demande vers celui-ci. Il doit pouvoir communiquer avec les pods du modèle.
Remarque
Si le modèle déployé requiert une connectivité (par exemple, pour l’interrogation d’une base de données externe ou d’un autre service REST ou le téléchargement d’un Blob), la résolution DNS et la communication sortante pour ces services doivent être activées.
Déployer sur AKS
Pour déployer un modèle sur AKS, créez une configuration de déploiement décrivant les ressources de calcul nécessaires. Par exemple, le nombre de cœurs et la mémoire. Vous avez également besoin d’une configuration d’inférence décrivant l’environnement nécessaire pour héberger le modèle et le service Web. Pour plus d’informations sur la création de la configuration d’inférence, consultez la section Comment et où déployer des modèles ?
Notes
Le nombre de modèles à déployer est limité à 1 000 modèles par déploiement (par conteneur).
S’APPLIQUE À : Kit de développement logiciel (SDK) Python azureml v1
Kit de développement logiciel (SDK) Python azureml v1
from azureml.core.webservice import AksWebservice, Webservice
from azureml.core.model import Model
from azureml.core.compute import AksCompute
aks_target = AksCompute(ws,"myaks")
# If deploying to a cluster configured for dev/test, ensure that it was created with enough
# cores and memory to handle this deployment configuration. Note that memory is also used by
# things such as dependencies and AML components.
deployment_config = AksWebservice.deploy_configuration(cpu_cores = 1, memory_gb = 1)
service = Model.deploy(ws, "myservice", [model], inference_config, deployment_config, aks_target)
service.wait_for_deployment(show_output = True)
print(service.state)
print(service.get_logs())
Pour plus d’informations sur les classes, les méthodes et les paramètres utilisés dans cet exemple, consultez les documents de référence suivants :
Mise à l’échelle automatique
S’APPLIQUE À :Kit de développement logiciel (SDK) Python azureml v1
Le composant qui gère la mise à l’échelle automatique pour les déploiements de modèles Azure Machine Learning est azureml-fe, qui est un routeur de requête intelligent. Étant donné que toutes les demandes d’inférence passent par lui, il possède les données nécessaires pour mettre à l’échelle automatiquement les modèles déployés.
Important
N’activez pas l’Autoscaler de pods horizontaux (HPA) Kubernetes pour les déploiements de modèles. Cela met en concurrence les deux composants de mise à l’échelle automatique. Azureml-fe est conçu pour mettre à l’échelle automatiquement les modèles déployés par Azure Machine Learning, dans lesquels HPA devrait deviner ou estimer l’utilisation du modèle à partir d’une mesure générique telle que l’utilisation du processeur ou une configuration de métrique personnalisée.
Azureml-fe ne met pas à l’échelle le nombre de nœuds d’un cluster AKS, car cela pourrait entraîner une augmentation inattendue du coût. Au lieu de cela, il met à l’échelle le nombre de réplicas du modèle dans les limites du cluster physique. Si vous devez mettre à l’échelle le nombre de nœuds au sein du cluster, vous pouvez mettre à l’échelle le cluster manuellement ou configurer le programme de mise à l’échelle automatique du cluster AKS.
La mise à l’échelle automatique peut être contrôlée en définissant les paramètres autoscale_target_utilization, autoscale_min_replicas et autoscale_max_replicas pour le service web AKS. L’exemple suivant montre comment activer la mise à l’échelle automatique :
aks_config = AksWebservice.deploy_configuration(autoscale_enabled=True,
autoscale_target_utilization=30,
autoscale_min_replicas=1,
autoscale_max_replicas=4)
La décision d’effectuer un scale-up ou un scale-down est basée sur l’utilisation des réplicas de conteneur actuels. Le nombre de réplicas occupés (qui traitent une demande) divisé par le nombre total de réplicas actuels donne l’utilisation en cours. Si ce nombre dépasse autoscale_target_utilization, d’autres réplicas sont créés. S’il est inférieur, des réplicas sont supprimés. Par défaut, le pourcentage d’utilisation ciblé est 70 %.
La décision d’ajouter des réplicas est hâtive et rapide (environ 1 seconde). La décision de supprimer des réplicas est prudente (environ 1 minute).
Vous pouvez calculer le nombre de réplicas nécessaires à l’aide du code suivant :
from math import ceil
# target requests per second
targetRps = 20
# time to process the request (in seconds)
reqTime = 10
# Maximum requests per container
maxReqPerContainer = 1
# target_utilization. 70% in this example
targetUtilization = .7
concurrentRequests = targetRps * reqTime / targetUtilization
# Number of container replicas
replicas = ceil(concurrentRequests / maxReqPerContainer)
Pour plus d’informations sur la configuration de autoscale_target_utilization, autoscale_max_replicas et autoscale_min_replicas, consultez les informations de référence sur le module AksWebservice.
Authentification de service web
Lors du déploiement sur Azure Kubernetes Service, l’authentification basée sur les clés est activée par défaut. Vous pouvez également activer l'authentification par jeton. L’authentification par jeton exige que les clients utilisent un compte Microsoft Entra pour demander un jeton d’authentification, qui est utilisé pour adresser des requêtes au service déployé.
Pour désactiver l’authentification, définissez le paramètre auth_enabled=False lors de la création de la configuration de déploiement. L’exemple suivant désactive l’authentification à l’aide du kit de développement logiciel (SDK) :
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, auth_enabled=False)
Pour plus d’informations sur l'authentification à partir d’une application cliente, consultez Utiliser un modèle Azure Machine Learning déployé en tant que service web.
Authentification avec des clés
Si l’authentification par clé est activée, vous pouvez utiliser la méthode get_keys pour récupérer des clés d’authentification primaire et secondaire :
primary, secondary = service.get_keys()
print(primary)
Important
Si vous devez régénérer une clé, utilisez service.regen_key.
Authentification avec des jetons
Pour activer l’authentification par jeton, utilisez le paramètre token_auth_enabled=True lorsque vous créez ou mettez à jour un déploiement. L’exemple suivant active l’authentification par jeton à l’aide du kit de développement logiciel (SDK) :
deployment_config = AksWebservice.deploy_configuration(cpu_cores=1, memory_gb=1, token_auth_enabled=True)
Si l’authentification par jeton est activée, vous pouvez utiliser la méthode get_token pour récupérer un jeton JWT et le délai d’expiration du jeton :
token, refresh_by = service.get_token()
print(token)
Important
Vous devez demander un nouveau jeton après l’heure de refresh_by du jeton.
Microsoft recommande vivement de créer votre espace de travail Azure Machine Learning dans la même région que celle de votre cluster AKS. Pour s’authentifier avec un jeton, le service web appelle la région dans laquelle votre espace de travail Azure Machine Learning est créé. Si la région de votre espace de travail est indisponible, vous ne pouvez pas extraire de jeton pour votre service web, même si votre cluster se trouve dans une région différente de celle de votre espace de travail. Cela a pour effet d'empêcher l'authentification par jeton tant que la région de votre espace de travail n'est pas disponible. Par ailleurs, plus la distance entre la région de votre cluster et celle de votre espace de travail est élevée, plus l’extraction de jeton prend de temps.
Pour récupérer un jeton, vous devez utiliser le Kit de développement logiciel (SDK) Azure Machine Learning ou la commande az ml service obten-access-token.
Analyse des vulnérabilités
Microsoft Defender pour cloud fournit une gestion unifiée de la sécurité et une protection avancée contre les menaces dans les charges de travail cloud hybrides. Vous devez autoriser Microsoft Defender pour le cloud à analyser vos ressources et à suivre ses recommandations. Pour plus d’informations, consultez Sécurité des conteneurs dans Microsoft Defender pour les conteneurs.
Contenu connexe
- Utiliser le contrôle d’accès en fonction du rôle Azure pour l’autorisation Kubernetes
- Sécuriser un environnement d’inférence Azure Machine Learning à l’aide de réseaux virtuels
- Utiliser un conteneur personnalisé pour déployer un modèle sur un point de terminaison en ligne
- Résolution des problèmes de déploiement de modèle distant
- Mettre à jour un service web déployé
- Utiliser TLS pour sécuriser un service web par le biais d’Azure Machine Learning
- Utiliser un modèle Azure Machine Learning déployé en tant que service web
- Superviser et collecter des données à partir des points de terminaison de service web Machine Learning
- Collecter des données pour des modèles en production