Migration à partir de StorSimple 1200 vers Azure File Sync
StorSimple série 1200 est une appliance virtuelle exécutée dans un centre de données local. Il est possible d’effectuer une migration des données de cette appliance vers un environnement Azure File Sync. Azure File Sync est le service Azure à long terme stratégique et par défaut vers lequel les appliances StorSimple peuvent être migrées. Cet article décrit les étapes à suivre pour effectuer correctement une migration vers Azure File Sync et fournit les connaissances générales nécessaires.
Notes
Le support du service StorSimple (notamment StorSimple Device Manager pour les séries 8000 et 1200 et StorSimple Data Manager) est terminé. La fin du support de StorSimple a fait l’objet d’une publication en 2019 sur les pages Stratégie de cycle de vie Microsoft et Communications Azure. Des notifications supplémentaires ont été envoyées par e-mail et publiées sur le portail Azure et dans la vue d’ensemble StorSimple. Pour obtenir des informations plus détaillées, contactez le Support Microsoft.
S’applique à
| Type de partage de fichiers | SMB | NFS |
|---|---|---|
| Partages de fichiers Standard (GPv2), LRS/ZRS | ||
| Partages de fichiers Standard (GPv2), GRS/GZRS | ||
| Partages de fichiers Premium (FileStorage), LRS/ZRS |
Azure File Sync
Azure File Sync est un service cloud Microsoft basé sur deux composants principaux :
- Synchronisation des fichiers et hiérarchisation cloud.
- Partages de fichiers comme stockage natif dans Azure, accessibles par le biais de différents protocoles comme SMB et File REST. Un partage de fichiers Azure est comparable à un partage de fichiers sur un serveur Windows Server, que vous pouvez monter comme lecteur réseau de façon native. Il prend en charge des aspects clés de la fidélité des fichiers comme les attributs, les autorisations et les horodatages. Aucun service/application n’est nécessaire pour interpréter les fichiers et dossiers stockés dans le cloud (comme c’est le cas avec StorSimple). Il s’agit de l’approche idéale et la plus flexible pour stocker des données de serveur de fichiers à usage général et certaines données d’application dans le cloud.
Cet article est consacré aux étapes de migration. Si vous souhaitez en savoir plus sur Azure File Sync avant d’effectuer la migration, consultez les articles suivants :
Objectifs de la migration
L’objectif consiste à garantir l’intégrité des données de production et la disponibilité. Garantir la disponibilité implique de garder les temps d’arrêt à un niveau minimal pour qu’ils respectent les fenêtres de maintenance habituelles ou ne les dépassent que légèrement.
Chemin de migration à partir de StorSimple 1200 vers Azure File Sync
L’exécution d’un agent Azure File Sync nécessite un serveur Windows Server local. Il doit s’agir au minimum d’un serveur 2012R2, la version idéale étant Windows Server 2019.
Il existe de nombreux chemins de migration possibles, et il serait trop long de tous les documenter dans un article et d’expliquer clairement les risques et inconvénients qu’ils présentent par rapport à celui que nous recommandons de privilégier dans cet article.
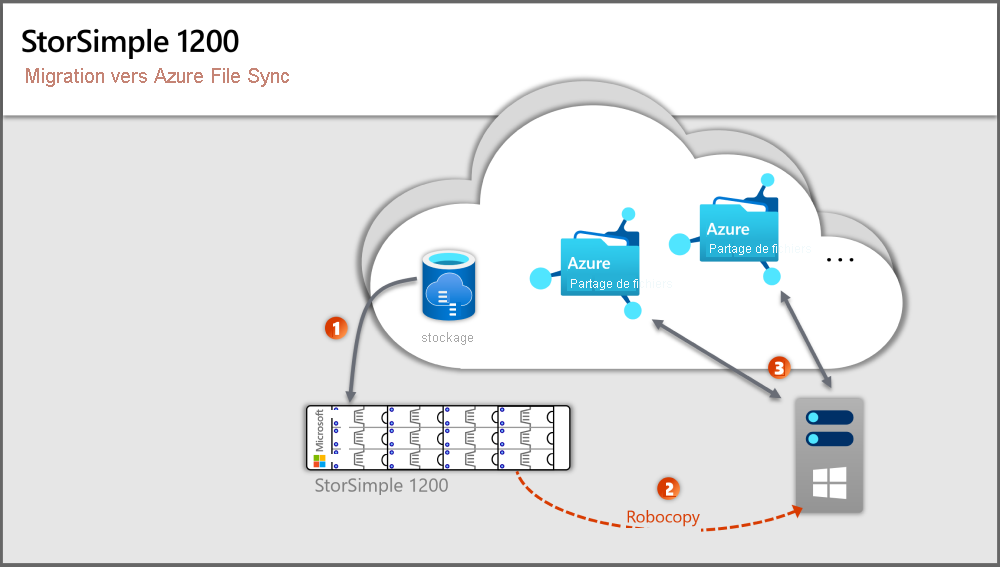
L’image précédente illustre les étapes correspondant aux sections de cet article.
Étape 1 : Provisionner le serveur Windows Server local et le stockage
- Créez un serveur Windows Server 2019 (ou au minimum 2012R2) comme machine virtuelle ou serveur physique. Un cluster de basculement Windows Server est également pris en charge.
- Provisionnez ou ajoutez un stockage DAS (Direct Attached Storage). Notez que les dispositifs de stockage NAS ne sont pas pris en charge. La taille du stockage Windows Server doit correspondre au minimum à la capacité disponible de l’appliance virtuelle StorSimple 1200.
Étape 2 : Configurer le stockage Windows Server
Dans le cadre de cette étape, vous allez mapper votre structure de stockage StorSimple (volumes et partages) à votre structure de stockage Windows Server. Si vous envisagez d’apporter des modifications à votre structure de stockage (nombre de volumes, association de dossiers de données aux volumes ou structure de sous-dossiers au-dessus ou en dessous de vos partages SMB/NFS actuels), vous devez y penser dès à présent. La modification de la structure de fichiers et de dossiers après la configuration d’Azure File Sync est particulièrement fastidieuses et doit être évitée. Cet article suppose que vous effectuez un mappage 1:1. Vous devez donc prendre en considération vos modifications de mappage à mesure que vous effectuez les étapes de cet article.
- Aucune de vos données de production ne doit se retrouver sur le volume système Windows Server. La hiérarchisation cloud n’est pas prise en charge sur les volumes système. Toutefois, cette fonctionnalité est nécessaire pour la migration et pour la continuité des opérations dans le cadre d’un remplacement de StorSimple.
- Provisionnez sur votre serveur Windows Server le même nombre de volumes que celui de votre appliance virtuelle StorSimple 1200.
- Configurez les rôles, fonctionnalités et paramètres Windows Server dont vous avez besoin. Nous vous recommandons d’accepter les mises à jour Windows Server pour garantir la sécurité de votre système d’exploitation et vous assurer qu’il est systématiquement à jour. De même, nous vous recommandons de vous abonner à Microsoft Update pour assurer la mise à jour des applications Microsoft et notamment de l’agent Azure File Sync.
- Ne configurez aucun dossier ou partage avant de prendre connaissance des étapes suivantes.
Étape 3 : Déployer la première ressource cloud Azure File Sync
Pour terminer cette étape, vous avez besoin des informations d’identification de votre abonnement Azure.
La ressource principale permettant de configurer Azure File Sync est un service de synchronisation de stockage. Nous vous recommandons d’en déployer un seul pour tous les serveurs synchronisant le même ensemble de fichiers maintenant ou à l’avenir. Ne créez plusieurs services de synchronisation de stockage que si vous avez des ensembles de serveurs distincts qui ne doivent jamais échanger de données. Par exemple, vous pouvez avoir des serveurs qui ne doivent jamais synchroniser le même partage de fichiers Azure. Dans le cas contraire, la meilleure pratique consiste à utiliser un seul service de synchronisation de stockage.
Pour votre service de synchronisation de stockage, choisissez une région Azure proche de votre emplacement. Toutes les autres ressources cloud doivent être déployées dans la même région. Afin de simplifier la gestion, créez un nouveau groupe de ressources dans votre abonnement pour héberger les ressources de synchronisation et de stockage.
Pour plus d’informations, consultez la section concernant le déploiement du service de synchronisation de stockage dans l’article sur le déploiement d’Azure File Sync. Suivez uniquement cette section de l’article. Des liens vers d’autres sections de l’article sont proposés dans des étapes ultérieures.
Étape 4 : Mettre en correspondance votre structure de dossiers et de volumes locale avec Azure File Sync et les ressources de partage de fichiers Azure
Dans cette étape, vous allez déterminer le nombre de partages de fichiers Azure dont vous avez besoin. Une seule instance Windows Server (ou cluster) peut synchroniser jusqu’à 30 partages de fichiers Azure.
Vous pouvez avoir plus de dossiers dans vos volumes que ce que vous partagez actuellement localement en tant que partages SMB pour vos utilisateurs et applications. La solution la plus simple pour décrire ce scénario consiste à envisager un mappage 1:1 entre un partage local et un partage de fichiers Azure. Si vous avez un nombre suffisamment petit de partages, inférieur à 30 pour une seule instance Windows Server, nous vous recommandons un mappage 1:1.
Si vous avez plus de 30 partages, il est souvent inutile de mapper un partage local 1:1 à un partage de fichiers Azure. Tenez compte des options suivantes.
Regroupement de partages
Par exemple, si votre service des ressources humaines (RH) a 15 partages, vous pouvez envisager de stocker toutes les données RH dans un seul partage de fichiers Azure. Le stockage de plusieurs partages locaux dans un partage de fichiers Azure ne vous empêche pas de créer les 15 partages SMB habituels sur votre instance locale de Windows Server. Cela signifie simplement que vous organisez les dossiers racine de ces 15 partages en sous-dossiers sous un dossier commun. Vous synchronisez ensuite ce dossier commun avec un partage de fichiers Azure. Ainsi, un seul partage de fichiers Azure dans le cloud est nécessaire pour ce groupe de partages locaux.
Synchronisation de volume
Azure File Sync prend en charge la synchronisation de la racine d’un volume avec un partage de fichiers Azure. Si vous synchronisez la racine du volume, tous les sous-dossiers et fichiers se retrouvent dans le même partage de fichiers Azure.
La synchronisation de la racine du volume n’est pas toujours la meilleure option. Il y a des avantages à synchroniser plusieurs emplacements. Par exemple, cela permet de maintenir un nombre d’éléments plus bas par étendue de synchronisation. Nous testons les partages de fichiers Azure et Azure File Sync avec 100 millions d’éléments (fichiers et dossiers) par partage. Cela dit, la bonne pratique est d’essayer de garder le nombre au-dessous de 20 ou 30 millions dans un même partage. La configuration d’Azure File Sync avec un nombre d’éléments inférieur n’est pas seulement avantageuse pour la synchronisation de fichiers. Un nombre inférieur d’éléments présente également des avantages pour d’autres scénarios comme :
- L’analyse initiale du contenu cloud peut se terminer plus rapidement, ce qui réduit l’attente de l’affichage de l’espace de noms sur un serveur activé pour Azure File Sync.
- La restauration côté cloud à partir d’un instantané de partage de fichiers Azure sera plus rapide.
- La reprise d’activité d’un serveur local peut être considérablement accélérée.
- Les modifications apportées directement dans un partage de fichiers Azure (en dehors de la synchronisation) peuvent être détectées et synchronisées plus rapidement.
Conseil
Si vous ne savez pas combien de fichiers et de dossiers vous avez, consultez l’outil d’arborescence de JAM Software GmbH.
Approche structurée d’un plan de déploiement
Avant de déployer un stockage cloud par la suite, vous devez créer un mappage entre des dossiers locaux et des partages de fichiers Azure. Ce mappage indique le nombre et la nature des ressources de groupe de synchronisation Azure File Sync à provisionner. Un groupe de synchronisation lie le partage de fichiers Azure et le dossier sur votre serveur et établit une connexion de synchronisation.
Pour déterminer le nombre de partages de fichiers Azure dont vous avez besoin, passez en revue les limites et bonnes pratiques suivantes. Cela vous permet d’optimiser votre mappage.
Un serveur sur lequel l’agent Azure File Sync est installé peut se synchroniser avec un maximum de 30 partages de fichiers Azure.
Un partage de fichiers Azure est déployé dans un compte de stockage. Cet arrangement fait du compte de stockage une cible de mise à l’échelle pour les chiffres des performances comme les IOPS et le débit.
Lors du déploiement de partages de fichiers Azure, soyez attentif aux limitations d’IOPS d’un compte de stockage. Dans l’idéal, une correspondance 1:1 doit être respectée entre les partages de fichiers et les comptes de stockage. Mais cela n’est pas toujours possible en raison des différentes limites et restrictions imposées par votre organisation et Azure. Lorsqu’il est impossible de déployer un seul partage de fichiers dans un seul compte de stockage, il convient d’identifier les partages qui seront plus ou moins actifs afin de veiller à ce que les plus actifs ne soient pas regroupés sur le même compte de stockage.
Si vous envisagez d’intégrer une application dans Azure qui utilisera le partage de fichiers Azure en mode natif, vous devrez peut-être augmenter les performances de votre partage de fichiers Azure. Si ce type d’utilisation est une éventualité, même future, il est préférable de créer un partage de fichiers Azure standard dans son propre compte de stockage.
Il existe une limite de 250 comptes de stockage par abonnement et par région Azure.
Conseil
Au vu de ces informations, il est souvent nécessaire de regrouper plusieurs dossiers de niveau supérieur sur vos volumes dans un nouveau répertoire racine commun. Vous synchronisez ensuite ce nouveau répertoire racine et tous les dossiers que vous y avez regroupés dans un seul partage de fichiers Azure. Cette technique vous permet de rester dans la limite de 30 synchronisations de partage de fichiers Azure par serveur.
Ce regroupement sous une racine commune n’affecte pas l’accès à vos données. Vos listes de contrôle d’accès restent telles quelles. Vous avez seulement besoin d’ajuster les chemins de partage (par exemple, des partages SMB ou NFS) que vous pouvez avoir sur les dossiers de serveur locaux et que vous avez maintenant changés en racine commune. Rien d’autre ne change.
Important
Le vecteur d’échelle le plus important pour Azure File Sync est le nombre d’éléments (fichiers et dossiers) qui doivent être synchronisés. Pour plus d’informations, consultez Cibles de mise à l’échelle Azure File Sync.
Il est recommandé de maintenir un petit nombre d’éléments par étendue de synchronisation. C’est un facteur important à prendre en compte quand vous mappez des dossiers aux partages de fichiers Azure. Azure File Sync est testé avec 100 millions d’éléments (fichiers et dossiers) par partage. Cela dit, il est souvent préférable de garder le nombre d’éléments au-dessous de 20 ou 30 millions dans un même partage. Fractionnez votre espace de noms en plusieurs partages si vous commencez à dépasser ces nombres. Vous pouvez continuer à regrouper plusieurs partages locaux dans le même partage de fichiers Azure, à condition que vous restiez plus ou moins en dessous de ces chiffres. Cette méthode vous donne de la marge pour évoluer.
Dans votre situation, il est possible qu’un ensemble de dossiers puisse logiquement se synchroniser avec le même partage de fichiers Azure (en utilisant la nouvelle approche de dossier racine commun mentionnée plus haut). Toutefois, il peut être préférable de regrouper les dossiers de manière à ce qu’ils se synchronisent avec deux partages de fichiers Azure au lieu d’un. Vous pouvez utiliser cette approche pour conserver l’équilibre entre le nombre de fichiers et de dossiers par partage de fichiers sur le serveur. Vous pouvez également diviser vos partages locaux et synchroniser sur d’autres serveurs locaux, en ajoutant la possibilité de synchroniser avec 30 autres partages de fichiers Azure par serveur supplémentaire.
Scénarios fréquents de synchronisation de fichiers et observations
| # | Scénario de synchronisation | Prise en charge | Observations (ou limitations) | Solution (ou solution de contournement) |
|---|---|---|---|---|
| 1 | Serveur de fichiers avec plusieurs disques/volumes et plusieurs partages sur le même partage de fichiers Azure cible (consolidation) | Non | Un partage de fichiers Azure cible (point de terminaison cloud) ne prend en charge la synchronisation qu’avec un seul groupe de synchronisation. Un groupe de synchronisation ne prend en charge qu’un seul point de terminaison de serveur par serveur inscrit. |
1) Commencez par synchroniser un disque (son volume racine) pour cibler le partage de fichiers Azure. Le fait de commencer par le disque/volume le plus important aidera à déterminer les besoins de stockage au niveau local. Configurez la hiérarchisation cloud pour répartir toutes les données sur le cloud, libérant ainsi de l’espace sur le disque du serveur de fichiers. Déplacez les données d’autres volumes/partages vers le volume actuel qui est synchronisé. Suivez les étapes une par une jusqu’à ce que toutes les données soient transférées vers le cloud ou migrées. 2) Ciblez un volume racine (disque) à la fois. Utilisez la hiérarchisation cloud pour répartir toutes les données dans le partage de fichiers Azure cible. Supprimez le point de terminaison de serveur du groupe de synchronisation, recréez le point de terminaison avec le volume/disque racine suivant, synchronisez et répétez le processus. Remarque : il peut être nécessaire de réinstaller l’agent. 3) Recommandez l’utilisation de plusieurs partages de fichiers Azure cibles (compte de stockage identique ou différent en fonction des exigences de performances) |
| 2 | Serveur de fichiers avec un volume unique et plusieurs partages sur le même partage de fichiers Azure cible (consolidation) | Oui | Impossible de synchroniser plusieurs points de terminaison de serveur par serveur inscrit avec le même partage de fichiers Azure cible (identique à celui ci-dessus) | Synchronisez la racine du volume contenant plusieurs partages ou dossiers de niveau supérieur. Pour plus d’informations, consultez Concept de regroupement de partages et Synchronisation du volume. |
| 3 | Serveur de fichiers avec plusieurs partages et/ou volumes vers plusieurs partages de fichiers Azure sous un seul compte de stockage (mappage de partage 1:1) | Oui | Une seule instance Windows Server (ou cluster) peut synchroniser jusqu’à 30 partages de fichiers Azure. Un compte de stockage est une cible de mise à l’échelle pour les performances. Les IOPS et le débit sont partagés entre les partages de fichiers. Conservez le nombre d’éléments par groupe de synchronisation dans les 100 millions d’éléments (fichiers et dossiers) par partage. Dans l’idéal, il est préférable de rester en dessous de 20 ou 30 millions par partage. |
1) Utilisez plusieurs groupes de synchronisation (nombre de groupes de synchronisation = nombre de partages de fichiers Azure à synchroniser). 2) Seuls 30 partages à la fois peuvent être synchronisés dans ce scénario. Si vous avez plus de 30 partages sur ce serveur de fichiers, utilisez le Concept de regroupement de partages et la Synchronisation du volume pour réduire le nombre de dossiers racine ou de niveau supérieur à la source. 3) Utilisez des serveurs File Sync supplémentaires locaux et fractionnez/déplacez les données vers ces serveurs pour contourner les limitations sur le serveur Windows source. |
| 4 | Serveur de fichiers avec plusieurs partages et/ou volumes vers plusieurs partages de fichiers Azure sous un compte de stockage différent (mappage de partage 1:1) | Oui | Une seule instance Windows Server (ou cluster) peut synchroniser jusqu’à 30 partages de fichiers Azure (compte de stockage identique ou différent). Conservez le nombre d’éléments par groupe de synchronisation dans les 100 millions d’éléments (fichiers et dossiers) par partage. Dans l’idéal, il est préférable de rester en dessous de 20 ou 30 millions par partage. |
Même approche que précédemment |
| 5 | Plusieurs serveurs de fichiers avec un seul (volume ou partage racine) sur le même partage de fichiers Azure cibles (consolidation) | Non | Un groupe de synchronisation ne peut pas utiliser le point de terminaison cloud (partage de fichiers Azure) déjà configuré dans un autre groupe de synchronisation. Bien qu’un groupe de synchronisation puisse avoir des points de terminaison de serveur sur des serveurs de fichiers différents, les fichiers ne peuvent pas être distincts. |
Suivez les instructions du scénario n° 1 ci-dessus en tenant compte de la nécessité de cibler un serveur de fichiers à la fois. |
Créer une table de mappage

Utilisez les informations précédentes pour déterminer le nombre de partages de fichiers Azure dont vous avez besoin, ainsi que les parties de vos données existantes finissant dans ces différents partages.
Créez un tableau regroupant vos réflexions pour pouvoir vous y référer quand vous en avez besoin. Veillez à rester organisé pour ne perdre aucun détail de votre plan de mappage quand vous approvisionnez simultanément un grand nombre de ressources Azure. Téléchargez le fichier Excel suivant à utiliser comme modèle pour vous aider à créer votre mappage.

|
Téléchargez un modèle de mappage d’espace de noms. |
Étape 5 : Provisionner les partages de fichiers Azure
Un partage de fichiers Azure est stocké dans le cloud dans un compte de stockage Azure. Les performances doivent être considérées à un autre niveau ici.
Si vous avez des partages très actifs (utilisés par de nombreux utilisateurs et/ou applications), la limite de performances d’un compte de stockage peut être atteinte avec deux partages de fichiers Azure.
Une meilleure pratique consiste à déployer les comptes de stockage avec un partage de fichiers pour chaque. Vous pouvez regrouper plusieurs partages de fichiers Azure dans le même compte de stockage s’ils sont destinés à l’archivage ou si vous pensez qu’ils feront l’objet d’une activité quotidienne réduite.
Ces considérations s’appliquent davantage à l’accès direct au cloud (par le biais d’une machine virtuelle Azure) qu’à Azure File Sync. Si vous envisagez d’utiliser Azure File Sync sur ces partages uniquement, le regroupement de plusieurs partages dans le même compte de stockage Azure est une bonne idée.
Si vous avez établi la liste de vos partages, vous devez mapper chaque partage au compte de stockage dans lequel il résidera.
Durant la phase précédente, vous avez déterminé le nombre de partages approprié. Au cours de cette étape, vous avez un mappage des comptes de stockage aux partages de fichiers. Déployez maintenant le nombre approprié de comptes de stockage Azure avec le nombre approprié de partages de fichiers Azure contenus.
Vérifiez que la région est la même pour tous vos comptes de stockage et qu’elle correspond à la région de la ressource de service de synchronisation de stockage que vous avez déjà déployée.
Attention
Si vous créez un partage de fichiers Azure limité à 100 Tio, il peut utiliser deux options de redondance seulement : un stockage localement redondant ou un stockage redondant interzone. Tenez compte de vos besoins en termes de redondance du stockage avant d’utiliser des partages de fichiers de 100 Tio.
Les partages de fichiers Azure sont toujours créés avec une limite de 5 Tio par défaut. Suivez les étapes de la section Créer un partage de fichiers Azure pour créer un partage de fichiers volumineux.
Quand vous déployez un compte de stockage, vous devez également tenir compte de la redondance du stockage Azure. Consultez Options de redondance de stockage Azure.
Le nom des ressources est également important. Par exemple, si vous regroupez plusieurs partages pour le service RH dans un compte de stockage Azure, vous devez nommer le compte de stockage de manière appropriée. De même, quand vous nommez vos partages de fichiers Azure, vous devez utiliser des noms similaires à ceux de leurs équivalents locaux.
Paramètres du compte de stockage
Différentes configurations peuvent être appliquées sur un compte de stockage. La liste de vérification suivante doit être utilisée pour les configurations de votre compte de stockage. Vous pouvez par exemple modifier la configuration de mise en réseau une fois la migration terminée.
- Partages de fichiers volumineux : activé. Les partages de fichiers volumineux améliorent les performances et vous permettent de stocker jusqu’à 100 Tio dans un partage.
- Pare-feu et réseaux virtuels : désactivés. Ne configurez pas de restrictions d’adresse IP ou ne limitez pas l’accès au compte de stockage à un réseau virtuel spécifique. Le point de terminaison public du compte de stockage est utilisé pendant la migration. Toutes les adresses IP des machines virtuelles Azure doivent être autorisées. Il est préférable de configurer les règles de pare-feu sur le compte de stockage après la migration.
- Points de terminaison privés : pris en charge. Vous pouvez activer des points de terminaison privés, mais le point de terminaison public est utilisé pour la migration et doit rester disponible.
Étape 6 : Configurer les dossiers Windows Server cibles
Dans le cadre des étapes précédentes, vous avez pris en compte tous les aspects qui détermineront les composants de vos topologies de synchronisation. À présent, vous devez préparer le serveur pour qu’il reçoive les fichiers à charger.
Créez tous les dossiers qui seront synchronisés avec leur propre partage de fichiers Azure. Il est important de suivre la structure de dossiers que vous avez documentée précédemment. Par exemple, si vous avez décidé de synchroniser plusieurs partages SMB locaux avec un même partage de fichiers Azure, vous devez les placer dans un dossier racine commun sur le volume. Créez ce dossier racine cible sur le volume dès à présent.
Le nombre de partages de fichiers Azure que vous avez provisionnés doit correspondre au nombre de dossiers que vous avez créés au cours de cette étape plus le nombre de volumes que vous allez synchroniser au niveau racine.
Étape 7 : Déployer l’agent Azure File Sync
Dans le cadre de cette section, vous allez installer l’agent Azure File Sync sur votre instance Windows Server.
Le Guide de déploiement explique que vous devez désactiver la configuration de sécurité renforcée d’Internet Explorer. Cette mesure de sécurité n’est pas applicable avec Azure File Sync. La désactivation de cette option vous permet de vous authentifier auprès d’Azure sans aucun problème.
Ouvrez PowerShell. Installez les modules PowerShell nécessaires à l’aide des commandes suivantes. Veillez à installer le module complet et le fournisseur NuGet quand vous y êtes invité.
Install-Module -Name Az -AllowClobber
Install-Module -Name Az.StorageSync
Si vous rencontrez des problèmes pour accéder à Internet à partir de votre serveur, vous devez les résoudre dès à présent. Azure File Sync peut utiliser n’importe quelle connexion réseau à Internet disponible. L’exigence d’un serveur proxy pour accéder à Internet est également prise en charge. Vous pouvez configurer un proxy au niveau des machines dès maintenant ou spécifier un proxy que la fonctionnalité Azure File Sync sera la seule à utiliser lors de l’installation de l’agent.
Si la configuration d’un proxy implique l’ouverture de vos pare-feu pour le serveur, cette approche est peut-être acceptable pour vous. À la fin de l’installation du serveur, une fois l’inscription du serveur effectuée, un rapport de connectivité réseau indique les URL de point de terminaison exactes dans Azure avec lesquelles Azure File Sync doit communiquer pour la région que vous avez sélectionnée. Le rapport indique également la raison pour laquelle la communication est nécessaire. Vous pouvez utiliser le rapport pour verrouiller les pare-feu autour du serveur sur des URL spécifiques.
Vous pouvez également adopter une approche plus conservatrice dans laquelle vous n’ouvrez pas les pare-feu en grand. Vous pouvez à la place limiter le serveur pour qu’il communique avec des espaces de noms DNS de niveau supérieur. Pour plus d’informations, consultez Paramètres de proxy et de pare-feu d’Azure File Sync. Appliquez vos bonnes pratiques relatives aux réseaux.
À la fin de l’Assistant Installation du serveur, un Assistant Inscription du serveur s’affiche. Inscrivez le serveur auprès de la ressource Azure de votre service de synchronisation du stockage déployée précédemment.
Le guide de déploiement décrit ces étapes plus en détail et traite notamment des modules PowerShell que vous devez installer en premier : Installation de l’agent Azure File Sync.
Utilisez l’agent le plus récent. Vous pouvez aussi le télécharger à partir du Centre de téléchargement Microsoft : Agent Azure File Sync.
Une fois l’installation et l’inscription du serveur terminées, vous pouvez confirmer que vous avez correctement accompli cette étape. Accédez à la ressource du service de synchronisation de stockage dans le portail Azure. Dans le menu de gauche, accédez à Serveurs inscrits. Votre serveur y est répertorié.
Étape 8 : Configurer la synchronisation
Cette étape lie l’ensemble des ressources et dossiers que vous avez configurés sur votre instance Windows Server au cours des étapes précédentes.
- Connectez-vous au portail Azure.
- Localisez votre ressource de service de synchronisation de stockage.
- Créez un groupe de synchronisation au sein de la ressource de service de synchronisation de stockage pour chaque partage de fichiers Azure. Dans la terminologie Azure File Sync, le partage de fichiers Azure devient un point de terminaison cloud dans la topologie de synchronisation que vous décrivez lors de la création d’un groupe de synchronisation. Lorsque vous créez le groupe de synchronisation, donnez-lui un nom familier qui vous permette de reconnaître le groupe de fichiers qui se synchronise ici. Veillez à référencer le partage de fichiers Azure avec un nom correspondant.
- Une fois que vous avez créé le groupe de synchronisation, une ligne apparaît pour lui dans la liste des groupes de synchronisation. Cliquez sur le nom (un lien) du groupe de synchronisation pour afficher son contenu. Votre partage de fichiers Azure apparaît sous Points de terminaison cloud.
- Recherchez le bouton Ajouter un point de terminaison de serveur. Le dossier situé sur le serveur local que vous avez approvisionné devient le chemin d’accès pour ce point de terminaison de serveur.
Avertissement
Veillez à activer la hiérarchisation cloud. Cette activation est nécessaire si votre serveur local ne dispose pas de l’espace suffisant pour stocker l’ensemble des données de votre stockage cloud StorSimple. Définissez votre stratégie de hiérarchisation pour un espace de volume libre de 99 % temporairement, pour la migration.
Suivez de nouveau les étapes permettant de créer un groupe de synchronisation et d’ajouter le dossier serveur correspondant comme point de terminaison de serveur pour tous les partages de fichiers/emplacements de serveur Azure à configurer pour la synchronisation.
Étape 9 : Copier vos fichiers
L’approche de migration de base consiste à effectuer une copie à partir de l’appliance virtuelle StorSimple vers le serveur Windows Server à l’aide de RoboCopy et à effectuer une synchronisation avec des partages de fichiers Azure à l’aide d’Azure File Sync.
Exécutez la première copie locale vers votre dossier Windows Server cible :
- Identifiez le premier emplacement sur votre appliance virtuelle StorSimple.
- Identifiez le dossier correspondant sur le serveur Windows Server sur lequel Azure File Sync est déjà configuré.
- Démarrer la copie à l’aide de RoboCopy
La commande RoboCopy suivante rappelle les fichiers de votre stockage Azure StorSimple sur votre stockage StorSimple local, puis les déplace vers le dossier Windows Server cible. Le serveur Windows Server va le synchroniser avec le(s) partage(s) de fichiers Azure. Quand le volume Windows Server local se remplit, la hiérarchisation cloud intervient et hiérarchise les fichiers qui ont déjà été correctement synchronisés. La hiérarchisation cloud génère suffisamment d’espace pour poursuivre la copie à partir de l’appliance virtuelle StorSimple. La hiérarchisation cloud effectue une vérification toutes les heures pour déterminer ce qui a été synchronisé et libérer de l’espace disque pour atteindre l’espace de volume libre de 99 %.
robocopy <SourcePath> <Dest.Path> /MT:20 /R:2 /W:1 /B /MIR /IT /COPY:DATSO /DCOPY:DAT /NP /NFL /NDL /XD "System Volume Information" /UNILOG:<FilePathAndName>
| Commutateur | Signification |
|---|---|
/MT:n |
Autorise Robocopy à fonctionner en multithread. La valeur par défaut de n est 8. La valeur maximale est de 128 threads. Bien qu’un nombre élevé de threads permette de saturer la bande passante disponible, cela ne signifie pas que votre migration sera toujours plus rapide avec plus de threads. Les tests avec Azure Files indiquent qu’entre 8 et 20 threads affichent des performances équilibrées pour une exécution de copie initiale. Les exécutions suivantes de /MIR sont progressivement affectées par le calcul disponible par rapport à la bande passante réseau disponible. Pour les exécutions suivantes, associez votre valeur de nombre de threads avec plus de précision au nombre de cœurs du processeur et au nombre de threads par cœur. Déterminez si les cœurs doivent être réservés pour les autres tâches qu’un serveur de production peut prendre en charge. Les tests avec Azure Files ont montré qu’un nombre maximal de 64 threads offraient de bonnes performances, mais uniquement si vos processeurs peuvent les maintenir actifs en même temps. |
/R:n |
Nombre maximal de tentatives pour un fichier dont la copie échoue à la première tentative. Robocopy s’y prendra à n reprises avant que la copie du fichier n’échoue définitivement lors de l’exécution. Vous pouvez optimiser les performances de votre exécution : choisissez une valeur de deux ou trois si vous pensez que des problèmes de dépassement de délai ont causé des défaillances dans le passé. Cela peut être plus courant sur les liaisons WAN. Choisissez de ne faire aucune nouvelle tentative ou choisissez la valeur 1 si vous pensez que le fichier n’a pas pu être copié parce qu’il était activement utilisé. Une nouvelle tentative quelques secondes plus tard risque de ne pas suffire pour que l’état d’utilisation du fichier change. Les utilisateurs ou les applications qui maintiennent le fichier ouvert peuvent avoir besoin de plus de temps. Dans ce cas, accepter que le fichier n’ait pas été copié et l’intercepter dans l’une de vos exécutions Robocopy ultérieures peut aboutir à la copie du fichier. Cela permet à l’exécution en cours de se terminer plus rapidement sans être prolongée par de nombreuses tentatives qui se terminent principalement en échecs de copie en raison de fichiers toujours ouverts au-delà du délai d’expiration de la nouvelle tentative. |
/W:n |
Spécifie la durée d’attente de Robocopy, avant de tenter la copie d’un fichier qui n’a pas pu être copié à la dernière tentative. n est le nombre de secondes d’attente entre les tentatives. /W:n est souvent utilisé avec /R:n. |
/B |
Exécute Robocopy dans le même mode qu’une application de sauvegarde. Ce commutateur permet à Robocopy de déplacer des fichiers pour lesquels l’utilisateur actuel n’a pas d’autorisations. Le commutateur de sauvegarde dépend de l’exécution de la commande Robocopy dans une console administrateur avec élévation de privilèges ou une fenêtre PowerShell. Si vous utilisez Robocopy pour Azure Files, veillez à monter le partage de fichiers Azure à l’aide de la clé d’accès du compte de stockage et d’une identité de domaine. Si vous ne le faites pas, les messages d’erreur peuvent ne pas vous amener à résoudre le problème de manière intuitive. |
/MIR |
(Mettre en miroir la source sur la cible) Permet à Robocopy de n’avoir à copier que les deltas entre la source et la cible. Les sous-répertoires vides sont copiés. Les éléments (fichiers ou dossiers) qui ont été modifiés ou qui n’existent pas sur la cible sont copiés. Les éléments qui existent sur la cible, mais pas sur la source, sont vidés (supprimés) de la cible. Lorsque vous utilisez ce commutateur, faites correspondre exactement les structures de dossiers source et cible. Correspondance signifie que vous copiez du niveau de source et de dossier qui convient vers le niveau de dossier correspondant sur la cible. C’est la conditions requise pour qu’une copie de « rattrapage » aboutisse. Si la source et la cible ne correspondent pas, l’utilisation de /MIR entraîne des suppressions et des recopies à grande échelle. |
/IT |
Garantit la fidélité dans certains scénarios de mise en miroir. Par exemple, si un fichier fait l’objet d’une modification de liste de contrôle d’accès et d’une mise à jour d’attribut entre deux exécutions de Robocopy, il est également marqué masqué. Sans /IT, la modification de la liste de contrôle d’accès peut être ignorée par Robocopy et pas transférée vers l’emplacement cible. |
/COPY:[copyflags] |
Fidélité de la copie de fichier. Par défaut : /COPY:DAT. Indicateurs de copie : D=Données, A=Attributs, T=Horodatages, S=Sécurité=ACL NTFS, O=Informations propriétaire, U=Informations aDdit. Les informations d’audit ne peuvent pas être stockées dans un partage de fichiers Azure. |
/DCOPY:[copyflags] |
Fidélité pour la copie de répertoires. Par défaut : /DCOPY:DA. Indicateurs de copie : D = Données, A = Attributs, T = Horodatages. |
/NP |
Spécifie que la progression de la copie de chaque fichier et dossier ne s’affiche pas. L’affichage de la progression réduit considérablement les performances de copie. |
/NFL |
Indique que les noms de fichiers ne sont pas enregistrés dans le journal. Améliore les performances de copie. |
/NDL |
Indique que les noms de répertoires ne sont pas enregistrés dans le journal. Améliore les performances de copie. |
/XD |
Spécifie les répertoires à exclure. Quand vous exécutez Robocopy à la racine d’un volume, envisagez d’exclure le dossier System Volume Information masqué. S’il est utilisé comme il a été conçu, toutes les informations contenues dans celui-ci sont spécifiques au volume exact sur ce système exact et peuvent être reconstruites à la demande. La copie de ces informations n’est pas utile dans le cloud ou lorsque les données sont recopiées sur un autre volume Windows. Le fait de laisser ce contenu ne doit pas être considéré comme une perte de données. |
/UNILOG:<file name> |
Écrit l’état dans le fichier journal au format Unicode. (Remplace le journal existant.) |
/L |
Seulement pour une série de tests Les fichiers sont seulement répertoriés. Ils ne sont pas copiés ni supprimés, et ne sont pas horodatées. Souvent utilisé avec /TEE pour la sortie de console. Les indicateurs de l’exemple de script, comme /NP, /NFL et /NDL, peuvent devoir être supprimés pour obtenir des résultats de tests dûment documentés. |
/LFSM |
Uniquement pour les cibles avec stockage hiérarchisé. Non pris en charge lorsque la destination est un partage distant avec le protocole SMB. Spécifie que Robocopy fonctionne en « mode espace libre faible ». Ce commutateur est utile uniquement pour les cibles avec stockage hiérarchisé, susceptibles de manquer de capacité locale avant que Robocopy ne s’achève. Il a été spécifiquement ajouté à des fins d’utilisation avec une cible de hiérarchisation cloud Azure File Sync activée. Il peut être utilisé indépendamment d’Azure File Sync. Dans ce mode, Robocopy s’interrompt chaque fois qu’une copie de fichier réduit l’espace libre du volume de destination en dessous d’une valeur « plancher ». Cette valeur peut être spécifiée par la forme /LFSM:n de l’indicateur. Le paramètre n est spécifié en base 2 : nKB, nMB ou nGB. Si /LFSM est spécifié sans valeur plancher explicite, le plancher est défini sur 10 % de la taille du volume de destination. Le mode d’espace libre faible n’est pas compatible avec /MT, /EFSRAW ou /ZB. La prise en charge de /B a été ajoutée à Windows Server 2022. Pour plus d’informations, consultez la section Windows Server 2022 et RoboCopy LFSM ci-dessous pour plus d’informations, notamment sur un bogue associé et une solution de contournement. |
/Z |
Utiliser avec prudenceCopie les fichiers en mode redémarrage. Ce commutateur est recommandé uniquement dans un environnement réseau instable. Elle réduit considérablement les performances de copie en raison d’une journalisation supplémentaire. |
/ZB |
Utiliser avec prudenceUtilise le mode redémarrage. En cas d’accès refusé, cette option utilise le mode de sauvegarde. Cette option réduit considérablement les performances de copie en raison des points de contrôle. |
Important
Nous vous recommandons d’utiliser un Windows Server 2022. Lors de l’utilisation d’un Windows Server 2019, vérifiez que le niveau de correctif le plus récent ou au minimum la mise à jour du système d’exploitation KB5005103 est installée. Celle-ci contient des correctifs importants pour certains scénarios RoboCopy.
Quand vous exécutez la commande RoboCopy pour la première fois, les utilisateurs et applications ont toujours accès aux fichiers et dossiers StorSimple et peuvent éventuellement les modifier. Il est possible que RoboCopy traite un répertoire, passe au répertoire suivant, puis qu’un utilisateur accédant à l’emplacement source (StorSimple) ajoute, modifie ou supprime un fichier qui ne sera pas traité durant cette exécution de RoboCopy. Bien sûr.
La première exécution consiste à déplacer la majeure partie des données vers l’emplacement local sur votre serveur Windows Server et à effectuer une sauvegarde dans le cloud à l’aide d’Azure File Sync. Ceci peut prendre beaucoup de temps selon les paramètres suivants :
- La bande passante de téléchargement
- La vitesse de rappel du service cloud StorSimple
- La bande passante de chargement
- Le nombre d’éléments (fichiers et dossiers) qui doivent être traités par l’un ou l’autre des services
Une fois l’exécution initiale terminée, réexécutez la commande.
Elle s’exécute plus rapidement la deuxième fois. En effet, elle doit déplacer uniquement les éléments modifiés depuis la dernière exécution. Les modifications sont récentes et sont donc généralement déjà effectuées localement sur StorSimple. Ceci réduit encore la durée d’exécution, car la nécessité de rappeler des fichiers à partir du cloud est moindre. Au cours de cette deuxième exécution, de nouvelles modifications peuvent toujours venir s’ajouter.
Répétez cette procédure jusqu’à ce que vous considériez que le temps d’arrêt impliqué par l’exécution est acceptable.
Dès lors que vous considérez que le temps d’arrêt est acceptable et que vous êtes prêt à mettre l’emplacement StorSimple hors connexion, effectuez l’opération : par exemple, supprimez le partage SMB pour qu’aucun utilisateur ne puisse accéder au dossier ou prenez toute autre mesure appropriée pour empêcher toute modification du contenu de ce dossier sur StorSimple.
Exécutez une dernière fois la commande RoboCopy pour traiter toutes les modifications qui n’ont pas encore été prises en compte. La durée de cette dernière étape dépend de la vitesse d’analyse de RoboCopy. Vous pouvez estimer la durée d’exécution (correspondant au temps d’arrêt) en mesurant la durée de l’exécution précédente.
Créez un partage dans le dossier Windows Server et, le cas échéant, ajustez votre déploiement DFS-N pour qu’il pointe vers celui-ci. Veillez à définir les mêmes autorisations au niveau du partage que celles de votre partage SMB StorSimple.
Vous avez terminé la migration d’un partage/groupe de partages vers une racine ou un volume commun (selon ce que vous avez mappé et décidé d’envoyer vers le même partage de fichiers Azure).
Vous pouvez essayer d’exécuter quelques-unes de ces copies en parallèle. Nous vous recommandons de traiter l’étendue d’un partage de fichiers Azure à la fois.
Avertissement
Quand vous avez déplacé toutes les données de votre stockage StorSimple vers Windows Server et que la migration est terminée : revenez à tous les groupes de synchronisation dans le portail Azure et définissez le pourcentage d’espace libre du volume assuré par la hiérarchisation cloud sur une valeur mieux adaptée à l’utilisation du cache, par exemple 20 %.
La stratégie de libération d’espace de volume par hiérarchisation cloud agit au niveau du volume avec potentiellement plusieurs points de terminaison pour la synchronisation à partir du volume. Si vous oubliez de définir l’espace libre sur un point de terminaison de serveur, la synchronisation continue d’appliquer la règle la plus restrictive et tente de conserver un espace disque disponible de 99 %. Dans ce cas, vous n’obtiendrez pas les performances attendues du cache local, sauf si vous souhaitez seulement disposer de l’espace de noms pour un volume contenant uniquement des données d’archivage auxquelles il est rarement fait accès.
Dépanner
Le problème que vous êtes le plus susceptible de rencontrer est un échec de la commande RoboCopy de type « Volume plein » côté Windows Server. Dans ce cas, la vitesse de téléchargement est probablement supérieure à la vitesse de chargement. Toutes les heures, la hiérarchisation cloud retire le contenu du disque Windows Server local, qui a été synchronisé.
Laissez la synchronisation s’effectuer et la hiérarchisation cloud libérer l’espace disque. Vous pouvez observer l’opération dans l’Explorateur de fichiers sur votre serveur Windows Server.
Quand la capacité disponible de votre serveur Windows Server est suffisante, réexécutez la commande pour résoudre le problème. Cette situation n’entraîne aucune dégradation. Vous pouvez poursuivre en toute confiance. La nécessité de réexécuter la commande représente le seul inconvénient.
D’autres problèmes liés à Azure File Sync peuvent survenir. Si tel est le cas, consultez Guide de résolution des problèmes pour Azure File Sync.
La vitesse et le taux de réussite d’une exécution de RoboCopy donnée dépendent de plusieurs facteurs :
- les IOPS sur le stockage source et le stockage cible ;
- la bande passante réseau disponible entre la source et la cible ;
- la capacité de traiter rapidement des fichiers et des dossiers dans un espace de noms ;
- le nombre de modifications entre les exécutions de RoboCopy.
- la taille et le nombre de fichiers que vous devez copier
Remarques relatives à la bande passante et aux IOPS
Dans cette catégorie, vous devez prendre en compte les capacités du stockage source, du stockage cible et du réseau qui les connecte. Le débit maximal possible est déterminé par le plus lent de ces trois composants. Vérifiez que votre infrastructure réseau est configurée pour prendre en charge des vitesses de transfert optimales au mieux de ses possibilités.
Attention
Si la copie la plus rapide est souvent la plus souhaitée, envisagez l’utilisation de votre réseau local et de votre appliance NAS pour d’autres tâches, généralement critiques pour l’entreprise.
Une copie aussi rapide que possible peut ne pas être souhaitable lorsqu’il existe un risque de monopolisation des ressources disponibles par la migration.
- Réfléchissez au moment qui sera le plus approprié dans votre environnement pour effectuer des migrations : dans la journée, pendant les heures creuses ou au cours des week-ends.
- Pensez également à la mise en réseau de la Qualité de service sur un serveur Windows pour limiter la vitesse de RoboCopy.
- Évitez les tâches inutiles pour les outils de migration.
RoboCopy peut insérer des délais inter-paquets, en spécifiant le commutateur /IPG:n, sachant que n est mesuré en millisecondes entre les paquets de Robocopy. L’utilisation de ce commutateur permet d’éviter la monopolisation des ressources à la fois sur les appareils limités en E/S et sur les liens réseau encombrés.
/IPG:n ne peut pas être utilisé pour limiter avec précision le réseau à un certain nombre de Mbits/s près. Utilisez plutôt la Qualité de service du réseau Windows Server. RoboCopy s’appuie entièrement sur le protocole SMB pour tous les besoins réseau. Cette utilisation de SMB est la raison pour laquelle RoboCopy ne peut pas influer sur le débit du réseau lui-même, par contre il peut ralentir son utilisation.
Un raisonnement similaire s’applique aux E/S par seconde (IOPS) observées sur l’appliance NAS. La taille du cluster sur le volume NAS, les tailles de paquets et un ensemble d’autres facteurs affectent les IOPS observées. L’introduction d’un délai entre des paquets constitue souvent le moyen le plus simple de contrôler la charge sur le NAS. Testez plusieurs valeurs, par exemple, à partir d’environ 20 millisecondes (n=20) jusqu’aux multiples de ce nombre. Dès lors qu’un délai est intercalé, vous pouvez évaluer si vos autres applications peuvent désormais fonctionner comme prévu. Cette stratégie d’optimisation vous permettra de trouver la vitesse optimale de RoboCopy dans votre environnement.
Vitesse de traitement
RoboCopy parcourra l’espace de noms qui lui est désigné et évaluera tous les fichiers et les dossiers en vue de leur copie. Chaque fichier sera évalué lors d’une copie initiale et au cours des copies de rattrapage. Prenons l’exemple des exécutions répétées de RoboCopy/MIR sur les mêmes emplacements de stockage source et cible. Ces exécutions répétées sont utiles pour réduire au minimum le temps d’interruption des utilisateurs et des applications, et pour améliorer le taux de réussite global des fichiers migrés.
Nous avons souvent tendance à considérer la bande passante comme le facteur le plus limitatif dans une migration, et cela peut être vrai. Toutefois, la possibilité d’énumérer un espace de noms peut influencer encore plus la durée totale de la copie pour les espaces de noms plus grands avec des fichiers de plus petite taille. Considérez que la copie de 1 Tio comportant des petits fichiers prendra beaucoup plus de temps que la copie de 1 Tio contenant des fichiers moins nombreux, mais plus volumineux, en supposant que toutes les autres variables restent identiques. Par conséquent, le transfert peut être lent si vous migrez un grand nombre de petits fichiers. Ce comportement est normal.
La cause de cette différence réside dans la puissance de traitement nécessaire pour parcourir un espace de noms. RoboCopy prend en charge les copies multithread par le biais du paramètre /MT:n, où n représente le nombre de threads à utiliser. Ainsi, lors du provisionnement d’une machine plus particulièrement destinée à RoboCopy, tenez compte du nombre de cœurs de processeur et de leur relation avec le nombre de threads qu’ils fournissent. Le plus souvent, il est question de deux threads par cœur. Le nombre de cœurs et de threads d’une machine constitue un point de données important pour déterminer les valeurs multithread /MT:n que vous devez spécifier. Tenez également compte du nombre de tâches de RoboCopy que vous prévoyez d’exécuter en parallèle sur une machine donnée.
Des threads plus nombreux copieront notre exemple de 1 Tio de petits fichiers beaucoup plus rapidement que des threads moins nombreux. En même temps, l’investissement en ressources supplémentaires sur notre 1 Tio de fichiers volumineux peut ne pas produire d’avantages, en proportion. Un nombre élevé de threads tentera de copier simultanément un plus grand nombre de fichiers volumineux sur le réseau. Cette activité réseau supplémentaire augmente la probabilité d’être limité par les IOPS de débit ou de stockage.
Pendant une première RoboCopy dans une cible vide ou une exécution différentielle avec un grand nombre de fichiers modifiés, vous êtes probablement limité par le débit de votre réseau. Démarrez avec un nombre élevé de threads pour une série initiale. Un nombre élevé de threads, même au-delà des threads actuellement disponibles sur votre machine, permet de saturer la bande passante réseau disponible. Les exécutions suivantes de /MIR sont affectées progressivement par les éléments traités. Un nombre moindre de modifications dans une exécution différentielle signifie moins de transport des données sur le réseau. Votre vitesse est désormais plus dépendante de votre capacité à traiter les éléments d’espace de noms que de leur déplacement sur la liaison réseau. Pour les exécutions suivantes, associez votre valeur de nombre de threads au nombre de cœurs du processeur et au nombre de threads par cœur. Déterminez si les cœurs doivent être réservés pour les autres tâches qu’un serveur de production peut prendre en charge.
Conseil
Règle générale : la première exécution de RoboCopy, qui déplace un grand nombre de données d’un réseau à latence plus élevée, bénéficie de l’approvisionnement excédentaire du nombre de threads (/MT:n). Les exécutions ultérieures copient moins de différences et vous êtes plus susceptible de passer du débit réseau limité au calcul limité. Dans ces circonstances, il est souvent préférable de faire correspondre le nombre de threads RoboCopy avec les threads réellement disponibles sur la machine. L’approvisionnement excédentaire dans ce scénario peut entraîner davantage de décalages de contexte dans le processeur, ce qui peut ralentir votre copie.
Éviter les tâches inutiles
Évitez les modifications à grande échelle dans votre espace de noms. Par exemple, le déplacement de fichiers entre des répertoires, la modification de propriétés à grande échelle ou la modification des autorisations (ACL NTFS). En particulier, les modifications de liste de contrôle d’accès (ACL, access-control list) peuvent avoir un impact important, car elles ont souvent un effet de modification en cascade sur les fichiers situés plus bas dans l’arborescence des dossiers. Les conséquences peuvent être les suivantes :
- Un temps d’exécution de la tâche RoboCopy prolongé, car chaque fichier et dossier concerné par une modification ACL doit être mis à jour
- La réutilisation de données déplacées auparavant demandera peut-être que celles-ci soient recopiées. Par exemple, une plus grande quantité de données devra être copiée lorsque des structures de dossiers seront modifiées après une copie de fichiers déjà effectuée antérieurement. Une tâche RoboCopy ne peut pas « lire » une modification d’espace de noms. La tâche suivante doit donc purger les fichiers précédemment transportés vers l’ancienne structure de dossiers, et charger de nouveau les fichiers dans la nouvelle structure de dossiers.
Un autre aspect important consiste à utiliser efficacement l’outil RoboCopy. Avec le script RoboCopy recommandé, vous allez créer et enregistrer un fichier journal d’erreurs. Des erreurs de copie peuvent se produire, cela est normal. Ces erreurs rendent souvent nécessaire l’exécution de plusieurs séquences d’un outil de copie tel que RoboCopy. Une exécution initiale, par exemple d’un appareil NAS vers DataBox ou d’un serveur vers un partage de fichiers Azure. À cela, ajouter une ou plusieurs exécutions supplémentaires avec le commutateur/MIR pour intercepter et refaire une tentative sur les fichiers qui n’ont pas été copiés.
Vous devez être prêt à exécuter plusieurs séquences de RoboCopy sur une étendue d’espace de noms déterminée. Les exécutions successives se terminent plus rapidement, car elles ont moins à copier, mais elles sont progressivement limitées par la vitesse de traitement de l’espace de noms. Lorsque vous exécutez plusieurs séquences, vous pouvez accélérer chacune d’elles en évitant que RoboCopy n’essaie exagérément de tout copier dans une exécution donnée. Ces commutateurs RoboCopy peuvent faire une grande différence :
/R:nn = fréquence à laquelle vous réessayez de copier un fichier ayant échoué et/W:nn = fréquence d’attente, en secondes, entre les tentatives
/R:5 /W:5 est un paramètre raisonnable que vous pouvez adapter à votre convenance. Dans cet exemple, un fichier ayant échoué sera retenté cinq fois, avec un délai d’attente de cinq secondes entre chaque tentative. Si la copie du fichier échoue toujours, la tâche RoboCopy suivante fera une nouvelle tentative. Souvent les fichiers en échec, du fait de leur utilisation en cours ou de problèmes de délai d’attente, peuvent au final être correctement copiés de cette façon.
Windows Server 2022 et RoboCopy LFSM
Le commutateur /LFSM RoboCopy peut être utilisé pour éviter l’échec d’un travail RoboCopy avec une erreur volume plein. RoboCopy s’interrompt chaque fois qu’une copie de fichier réduit l’espace libre du volume de destination en dessous d’une valeur « plancher ».
Utilisez RoboCopy avec Windows Server 2022. Seule cette version de RoboCopy contient des correctifs de bogues importants et des fonctionnalités qui rendent le commutateur compatible avec des indicateurs supplémentaires nécessaires dans la plupart des migrations. Par exemple, la compatibilité avec l’indicateur /B.
/B exécute RoboCopy dans le même mode qu’une application de sauvegarde. Ce commutateur permet à RoboCopy de déplacer des fichiers pour lesquels l’utilisateur actuel n’a pas d’autorisations.
Normalement, RoboCopy peut être exécuté sur la source, la destination ou une troisième machine.
Important
Si vous envisagez d’utiliser /LFSM, RoboCopy doit être exécuté sur le serveur Azure File Sync Windows Server 2022 cible.
Notez également qu’avec /LFSM, vous devez également utiliser un chemin local pour la destination, et non un chemin UNC. Par exemple, en tant que chemin de destination, vous devez utiliser E:\Foldername plutôt qu’un chemin UNC comme \\ServerName\FolderName.
Attention
La version actuellement disponible de RoboCopy sur Windows Server 2022 présente un bogue qui provoque le décompte des pauses dans le nombre d’erreurs par fichier. Appliquez la solution de contournement suivante.
Les indicateurs /R:2 /W:1 recommandés augmentent la probabilité qu’un fichier échoue en raison d’une pause provoquée par /LFSM. Dans cet exemple, un fichier qui n’a pas été copié après 3 pauses, car /LFSM a provoqué la pause, fait échouer RoboCopy de manière incorrecte pour le fichier. La solution de contournement consiste à utiliser des valeurs plus élevées pour /R:n et /W:n. Un bon exemple est /R:10 /W:1800 (10 nouvelles tentatives de 30 minutes chacune). Cela devrait donner à l'algorithme de hiérarchisation d'Azure File Sync le temps de créer de l'espace sur le volume de destination.
Ce bogue a été résolu, mais le correctif n’est pas encore disponible publiquement. Consultez ce paragraphe pour vérifier les informations à jour sur la disponibilité du correctif et son déploiement.
Notes
Vous avez des questions ou rencontrez des problèmes ? Nous sommes là pour vous aider : 
Liens pertinents
Contenu relatif à la migration :
Contenu relatif à Azure File Sync :