Événements
31 mars, 23 h - 2 avr., 23 h
Le plus grand événement d’apprentissage Fabric, Power BI et SQL. 31 mars au 2 avril. Utilisez le code FABINSIDER pour économiser 400 $.
Inscrivez-vous aujourd’huiCe navigateur n’est plus pris en charge.
Effectuez une mise à niveau vers Microsoft Edge pour tirer parti des dernières fonctionnalités, des mises à jour de sécurité et du support technique.
Ce tutoriel montre comment utiliser Synapse Studio pour créer des définitions de travaux Apache Spark et les envoyer à un pool Apache Spark serverless.
Ce tutoriel décrit les tâches suivantes :
Avant de commencer le didacticiel, veillez à disposer des éléments suivants :
Dans cette section, vous allez créer une définition de travail Apache Spark pour PySpark (Python).
Ouvrez Synapse Studio.
Vous pouvez accéder aux exemples de fichiers pour la création de définitions de travaux Apache Spark afin de télécharger des exemples de fichiers pour python.zip. Ensuite, vous pouvez décompresser le package puis extraire les fichiers wordcount.py et shakespeare.txt.
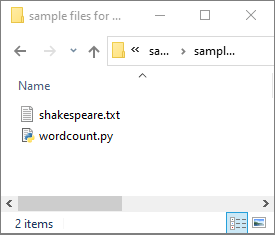
SélectionnezDonnées ->Liées ->Azure Data Lake Storage Gen2, puis chargez wordcount.py et shakespeare.txt dans votre système de fichiers ADLS Gen2.
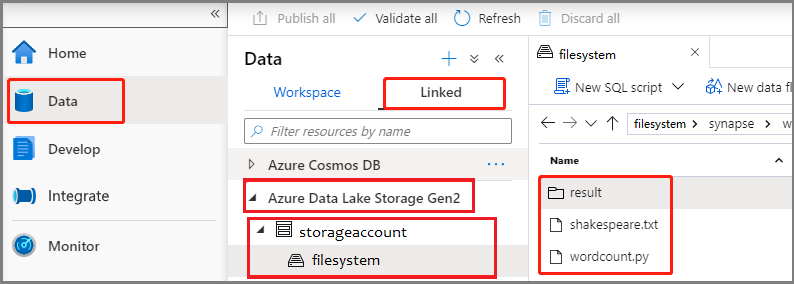
Sélectionnez le hub Développer, sélectionnez l’icône « + », puis sélectionnez Définition d’un travail Spark pour créer une définition de travail Spark.
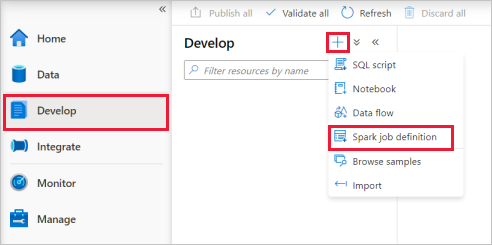
Sélectionnez PySpark (Python) dans la liste déroulante Langage de la fenêtre principale de la définition de travail Apache Spark.
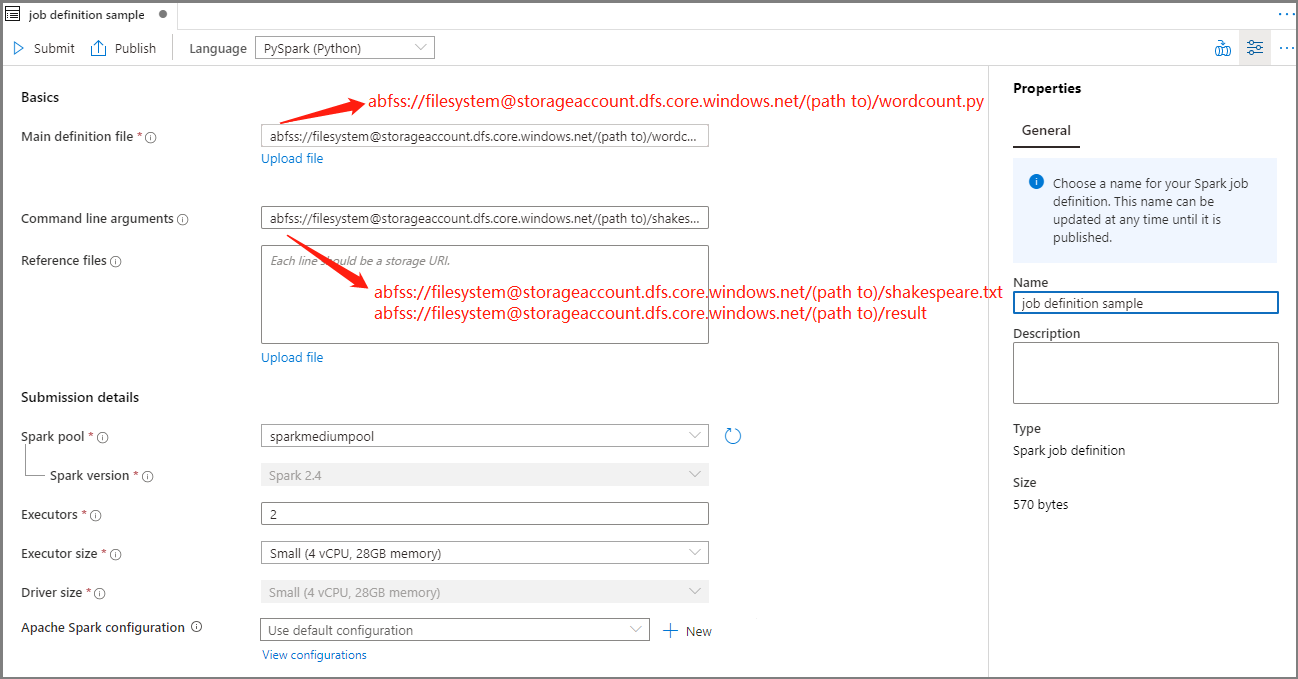
Renseignez les informations pour la définition de travail Apache Spark.
| Propriété | Description |
|---|---|
| Nom de la définition de travail | Entrez un nom pour votre définition de travail Apache Spark. Ce nom peut être mis à jour à tout moment jusqu’à ce qu’il soit publié. Exemple : job definition sample |
| Fichier de définition principal | Fichier principal utilisé pour le travail. Sélectionnez un fichier PY à partir de votre stockage. Vous pouvez sélectionner Charger le fichier pour charger le fichier sur un compte de stockage. Exemple : abfss://…/path/to/wordcount.py |
| Arguments de ligne de commande | Arguments facultatifs du travail. Exemple : abfss://…/path/to/shakespeare.txt abfss://…/path/to/result Remarque : Dans l’exemple de définition de travail, deux arguments sont séparés par un espace. |
| Fichiers de référence | Fichiers supplémentaires utilisés en guise de référence dans le fichier de définition principal. Vous pouvez sélectionner Charger le fichier pour charger le fichier sur un compte de stockage. |
| Pool Spark | Le travail sera envoyé au pool Apache Spark sélectionné. |
| Version de Spark | Version d’Apache Spark exécutée par le pool Apache Spark. |
| Exécuteurs | Nombre d’exécuteurs à attribuer dans le pool Apache Spark spécifié pour le travail. |
| Taille de l’exécuteur | Nombre de cœurs et mémoire à utiliser pour les exécuteurs dans le pool Apache Spark spécifié du travail. |
| Taille du pilote | Nombre de cœurs et mémoire à utiliser pour le pilote dans le pool Apache Spark spécifié du travail. |
| Configuration Apache Spark | Personnalisez les configurations en ajoutant les propriétés ci-dessous. Si vous n’ajoutez pas de propriété, Azure Synapse utilise la valeur par défaut, le cas échéant. |
Sélectionnez Publier pour enregistrer la définition de travail Apache Spark.

Dans cette section, vous allez créer une définition de travail Apache Spark pour Apache Spark(Scala).
Ouvrez Azure Synapse Studio.
Vous pouvez accéder aux exemples de fichiers pour la création de définitions de travaux Apache Spark afin de télécharger des exemples de fichiers pour scala.zip. Ensuite, vous pouvez décompresser le package puis extraire les fichiers wordcount.jar et shakespeare.txt.
SélectionnezDonnées ->Liées ->Azure Data Lake Storage Gen2, puis chargez wordcount.jar et shakespeare.txt dans votre système de fichiers ADLS Gen2.
Sélectionnez le hub Développer, sélectionnez l’icône « + », puis sélectionnez Définition d’un travail Spark pour créer une définition de travail Spark. L’exemple d’image est le même que celui de l’étape 4 de la section Créer une définition de travail Apache Spark (Python) pour PySpark.
Sélectionnez Spark(Scala) dans la liste déroulante Langage de la fenêtre principale de la définition de travail Apache Spark.
Renseignez les informations pour la définition de travail Apache Spark. Vous pouvez copier les exemples d’informations.
| Propriété | Description |
|---|---|
| Nom de la définition de travail | Entrez un nom pour votre définition de travail Apache Spark. Ce nom peut être mis à jour à tout moment jusqu’à ce qu’il soit publié. Exemple : scala |
| Fichier de définition principal | Fichier principal utilisé pour le travail. Sélectionnez un fichier JAR à partir de votre stockage. Vous pouvez sélectionner Charger le fichier pour charger le fichier sur un compte de stockage. Exemple : abfss://…/path/to/wordcount.jar |
| Main class name | Identificateur complet ou classe principale qui se trouve dans le fichier de définition principal. Exemple : WordCount |
| Arguments de ligne de commande | Arguments facultatifs du travail. Exemple : abfss://…/path/to/shakespeare.txt abfss://…/path/to/result Remarque : Dans l’exemple de définition de travail, deux arguments sont séparés par un espace. |
| Fichiers de référence | Fichiers supplémentaires utilisés en guise de référence dans le fichier de définition principal. Vous pouvez sélectionner Charger le fichier pour charger le fichier sur un compte de stockage. |
| Pool Spark | Le travail sera envoyé au pool Apache Spark sélectionné. |
| Version de Spark | Version d’Apache Spark exécutée par le pool Apache Spark. |
| Exécuteurs | Nombre d’exécuteurs à attribuer dans le pool Apache Spark spécifié pour le travail. |
| Taille de l’exécuteur | Nombre de cœurs et mémoire à utiliser pour les exécuteurs dans le pool Apache Spark spécifié du travail. |
| Taille du pilote | Nombre de cœurs et mémoire à utiliser pour le pilote dans le pool Apache Spark spécifié du travail. |
| Configuration Apache Spark | Personnalisez les configurations en ajoutant les propriétés ci-dessous. Si vous n’ajoutez pas de propriété, Azure Synapse utilise la valeur par défaut, le cas échéant. |
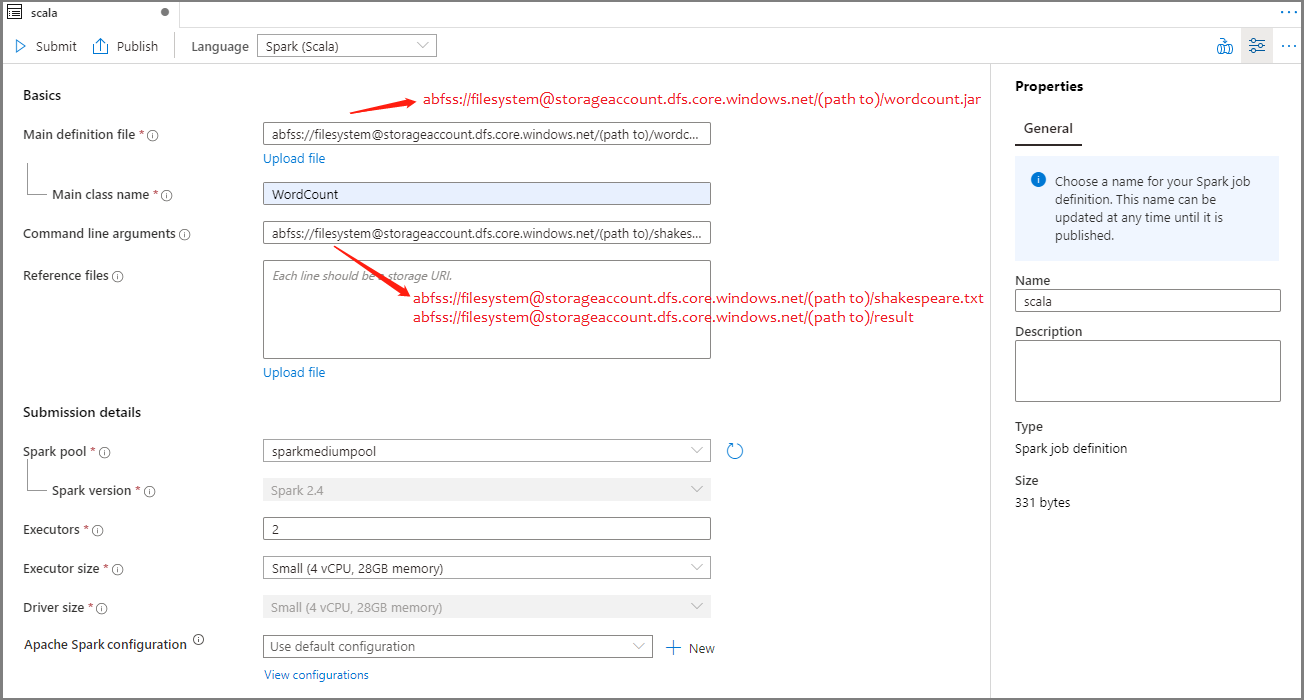
Sélectionnez Publier pour enregistrer la définition de travail Apache Spark.

Dans cette section, vous créez une définition de travail Apache Spark pour .NET Spark (C#/F#).
Ouvrez Azure Synapse Studio.
Vous pouvez accéder aux exemples de fichiers pour la création de définitions de travaux Apache Spark afin de télécharger des exemples de fichiers pour dotnet.zip. Ensuite, vous pouvez décompresser le package puis extraire les fichiers wordcount.zip et shakespeare.txt.
SélectionnezDonnées ->Liées ->Azure Data Lake Storage Gen2, puis chargez wordcount.zip et shakespeare.txt dans votre système de fichiers ADLS Gen2.
Sélectionnez le hub Développer, sélectionnez l’icône « + », puis sélectionnez Définition d’un travail Spark pour créer une définition de travail Spark. L’exemple d’image est le même que celui de l’étape 4 de la section Créer une définition de travail Apache Spark (Python) pour PySpark.
Sélectionnez .NET Spark(C#/F#) dans la liste déroulante Langage de la fenêtre principale Définition de travail Apache Spark.
Renseignez les informations pour la définition de travail Apache Spark. Vous pouvez copier les exemples d’informations.
| Propriété | Description |
|---|---|
| Nom de la définition de travail | Entrez un nom pour votre définition de travail Apache Spark. Ce nom peut être mis à jour à tout moment jusqu’à ce qu’il soit publié. Exemple : dotnet |
| Fichier de définition principal | Fichier principal utilisé pour le travail. Sélectionnez un fichier ZIP contenant votre application .NET pour Apache Spark (c’est-à-dire le fichier exécutable principal, les DLL contenant les fonctions définies par l’utilisateur et d’autres fichiers nécessaires) dans votre stockage. Vous pouvez sélectionner Charger le fichier pour charger le fichier sur un compte de stockage. Exemple : abfss://…/path/to/wordcount.zip |
| Fichier exécutable principal | Fichier exécutable principal dans le fichier ZIP de définition principal. Exemple : WordCount |
| Arguments de ligne de commande | Arguments facultatifs du travail. Exemple : abfss://…/path/to/shakespeare.txt abfss://…/path/to/result Remarque : Dans l’exemple de définition de travail, deux arguments sont séparés par un espace. |
| Fichiers de référence | Fichiers supplémentaires nécessaires aux nœuds Worker pour l’exécution de l’application .NET pour Apache Spark qui n’est pas incluse dans le fichier ZIP de définition principal (autrement dit, les fichiers jar dépendants, les DLL supplémentaires de fonctions définies par l’utilisateur et d’autres fichiers de configuration). Vous pouvez sélectionner Charger le fichier pour charger le fichier sur un compte de stockage. |
| Pool Spark | Le travail sera envoyé au pool Apache Spark sélectionné. |
| Version de Spark | Version d’Apache Spark exécutée par le pool Apache Spark. |
| Exécuteurs | Nombre d’exécuteurs à attribuer dans le pool Apache Spark spécifié pour le travail. |
| Taille de l’exécuteur | Nombre de cœurs et mémoire à utiliser pour les exécuteurs dans le pool Apache Spark spécifié du travail. |
| Taille du pilote | Nombre de cœurs et mémoire à utiliser pour le pilote dans le pool Apache Spark spécifié du travail. |
| Configuration Apache Spark | Personnalisez les configurations en ajoutant les propriétés ci-dessous. Si vous n’ajoutez pas de propriété, Azure Synapse utilise la valeur par défaut, le cas échéant. |
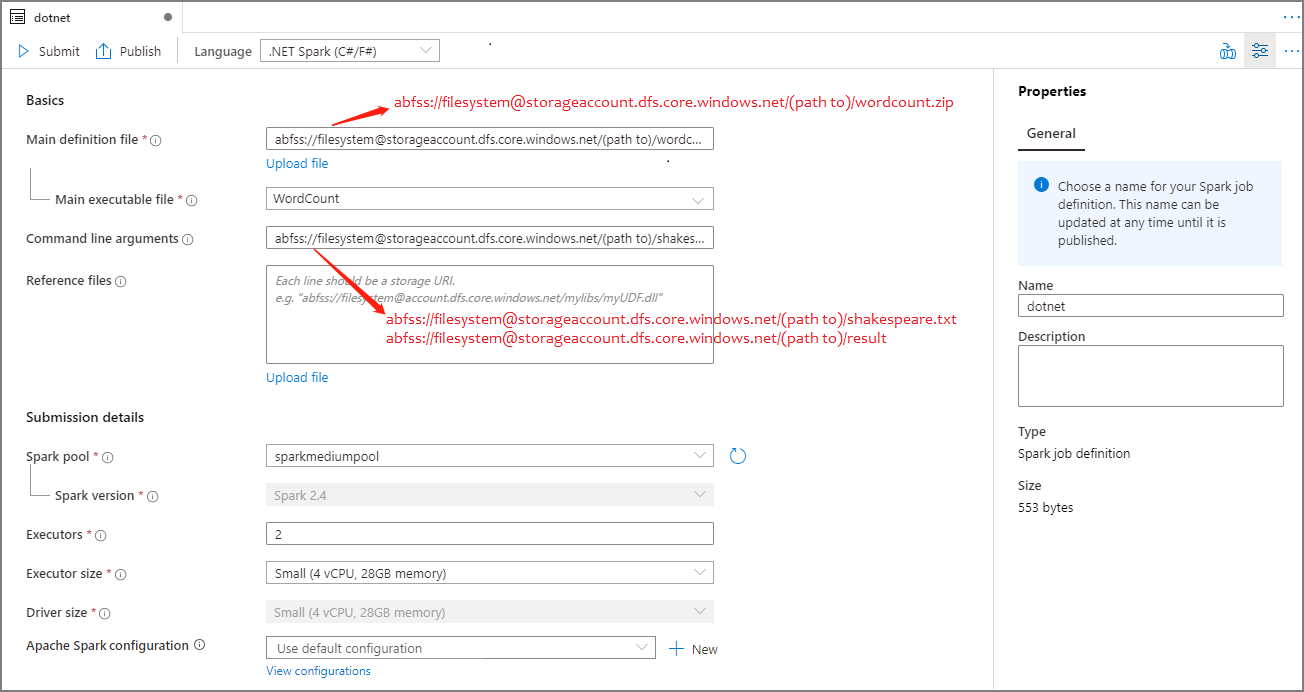
Sélectionnez Publier pour enregistrer la définition de travail Apache Spark.

Notes
Pour la configuration Apache Spark, si la définition de travail Apache Spark et Apache Spark ne fait rien de spécial, la configuration par défaut est utilisée lors de l’exécution du travail.
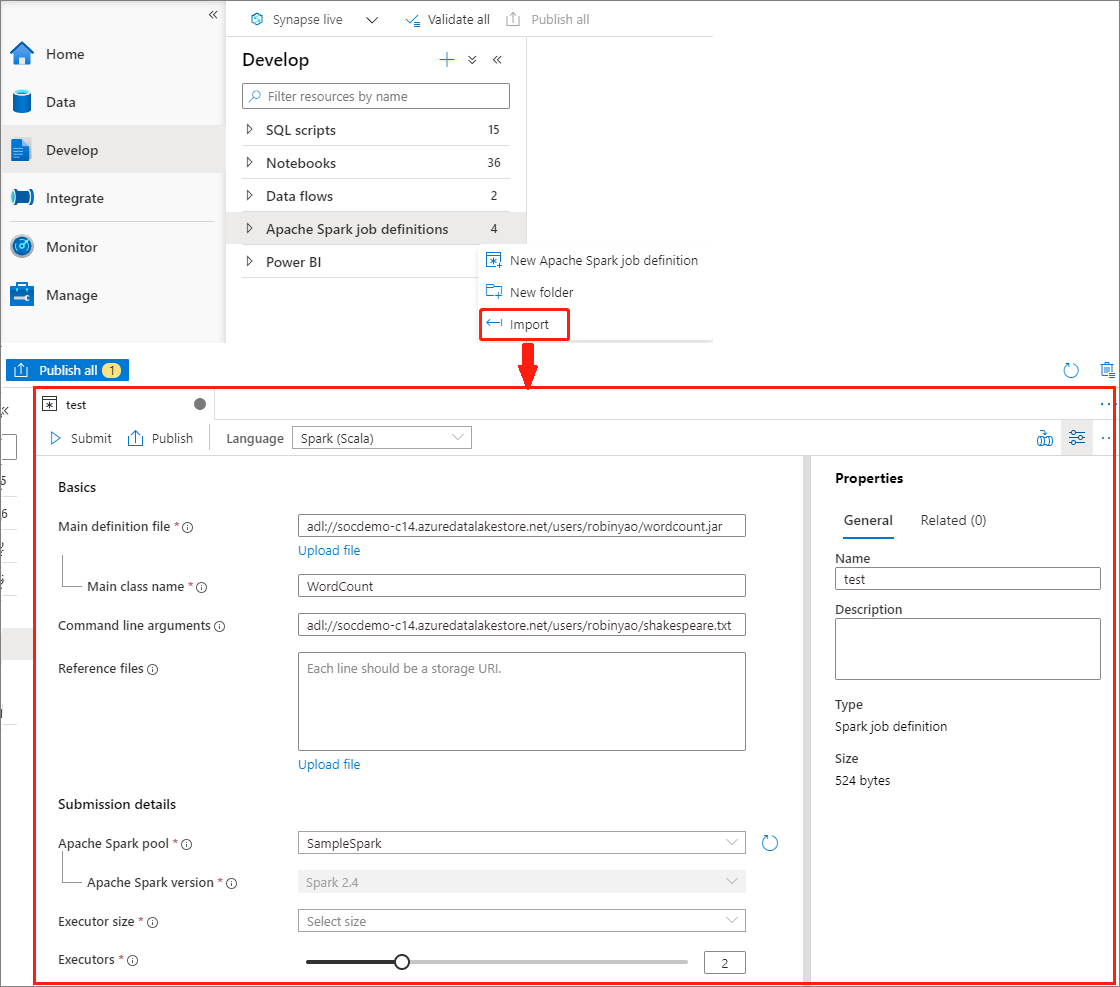
Vous pouvez importer un fichier JSON local existant dans l’espace de travail Azure Synapse à partir du menu Actions (...) de l’Explorateur de définition de travail Apache Spark pour créer une définition de travail Apache Spark.
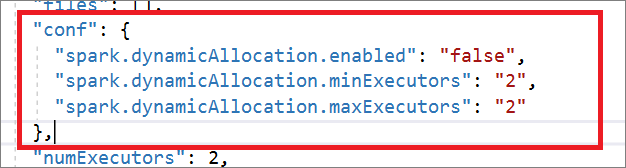
La définition de travail Spark est entièrement compatible avec l’API Livy. Vous pouvez ajouter des paramètres supplémentaires pour d’autres propriétés Livy (Documents Livy - API REST (apache.org) dans le fichier JSON local. Vous pouvez également spécifier les paramètres liés à la configuration Spark dans la propriété config, comme indiqué ci-dessous. Ensuite, vous pouvez réimporter le fichier JSON afin de créer une définition de travail Apache Spark pour votre traitement par lots. Exemple JSON pour l’importation de définitions Spark :
{
"targetBigDataPool": {
"referenceName": "socdemolarge",
"type": "BigDataPoolReference"
},
"requiredSparkVersion": "2.3",
"language": "scala",
"jobProperties": {
"name": "robinSparkDefinitiontest",
"file": "adl://socdemo-c14.azuredatalakestore.net/users/robinyao/wordcount.jar",
"className": "WordCount",
"args": [
"adl://socdemo-c14.azuredatalakestore.net/users/robinyao/shakespeare.txt"
],
"jars": [],
"files": [],
"conf": {
"spark.dynamicAllocation.enabled": "false",
"spark.dynamicAllocation.minExecutors": "2",
"spark.dynamicAllocation.maxExecutors": "2"
},
"numExecutors": 2,
"executorCores": 8,
"executorMemory": "24g",
"driverCores": 8,
"driverMemory": "24g"
}
}
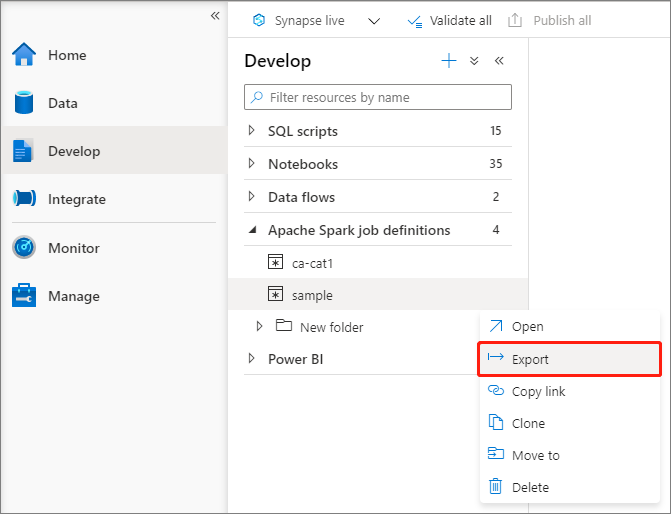
Vous pouvez exporter des fichiers de définition de travail Apache Spark existants vers un emplacement local à partir du menu Actions (...) de l’Explorateur de fichiers. Vous pouvez poursuivre la mise à jour du fichier JSON pour des propriétés Livy supplémentaires, puis le réimporter afin de créer une définition de travail, si nécessaire.
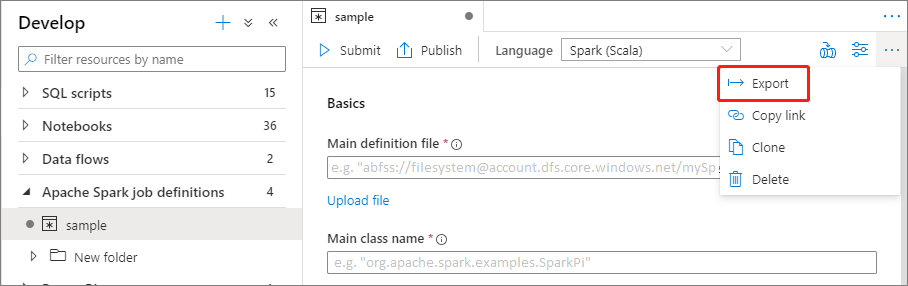
Après avoir créé une définition de travail Apache Spark, vous pouvez l’envoyer à un pool Apache Spark. Vérifiez que vous êtes bien le contributeur aux données Blob du stockage du système de fichiers ADLS Gen2 que vous souhaitez utiliser. Si ce n’est pas le cas, vous devez ajouter l’autorisation manuellement.
Ouvrez une fenêtre de définition de travail Apache Spark en sélectionnant la définition concernée.
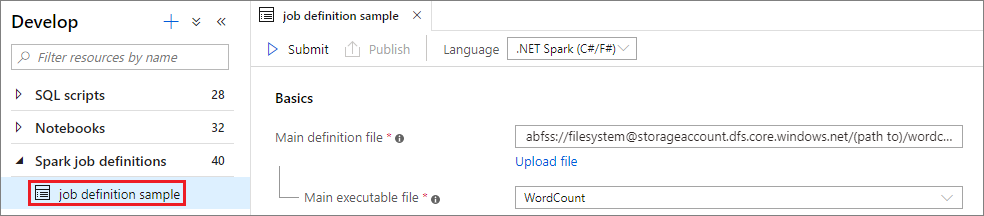
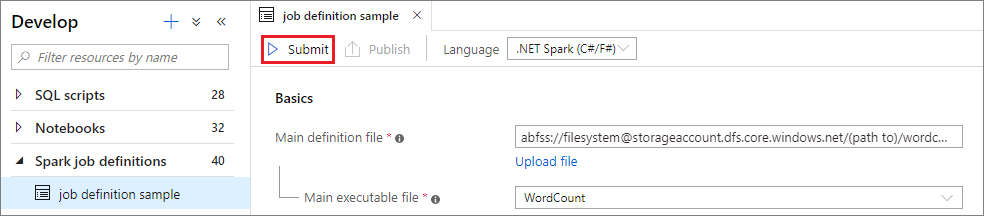
Sélectionnez le bouton Envoyer pour envoyer votre projet au pool Apache Spark sélectionné. Vous pouvez sélectionner l’URL de supervision Spark pour afficher les informations LogQuery de l’application Apache Spark.
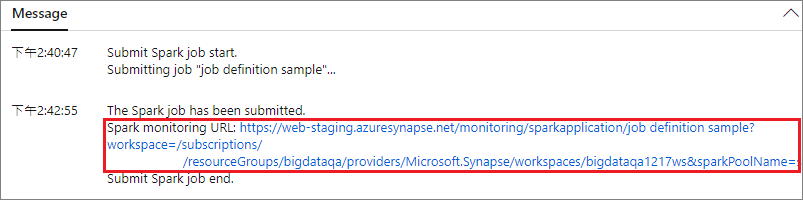
Sélectionnez Superviser, puis sélectionnez l’option Applications Apache Spark. Vous pouvez trouver l’application Apache Spark envoyée.
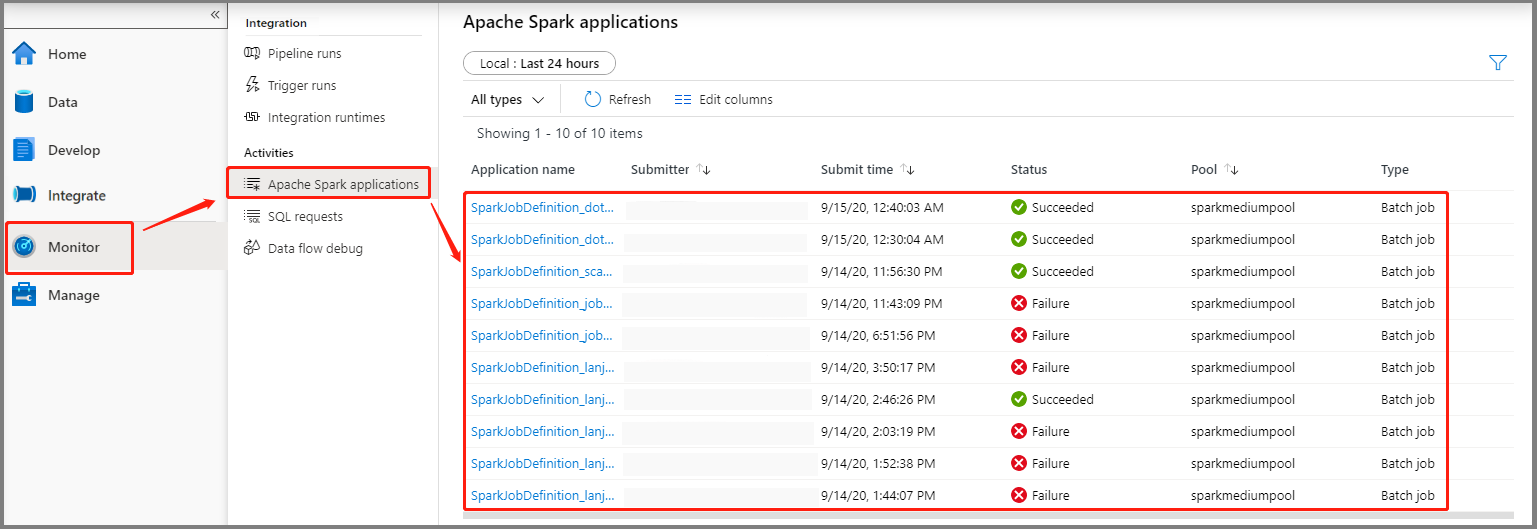
Ensuite, sélectionnez une application Apache Spark pour afficher la fenêtre du travail SparkJobDefinition. Vous pourrez y voir la progression de l’exécution du travail.
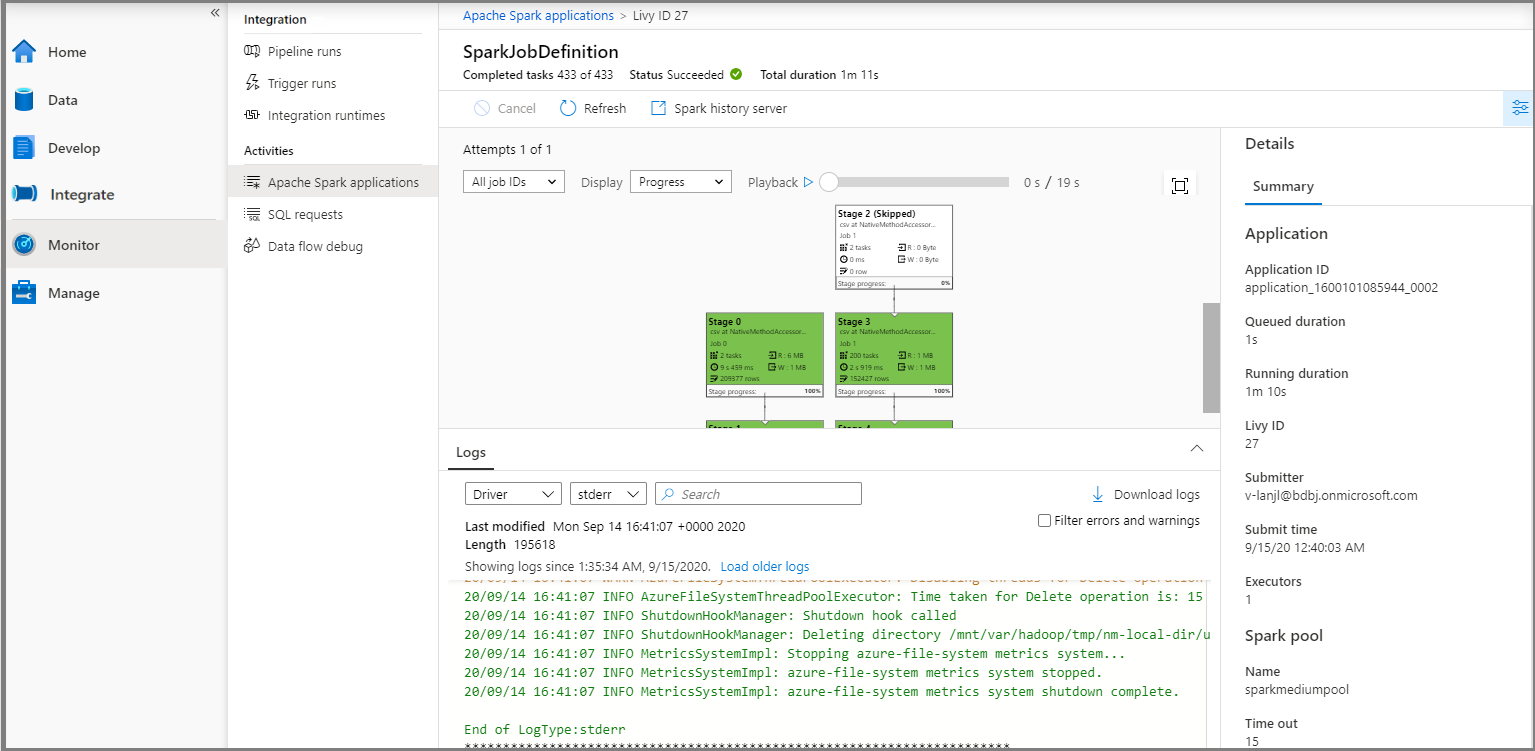
Sélectionnez Données ->Liées ->Azure Data Lake Storage Gen2 (hozhaobdbj), puis ouvrez le dossier result créé précédemment. Vous pouvez accéder au dossier result pour voir si la sortie a été générée.
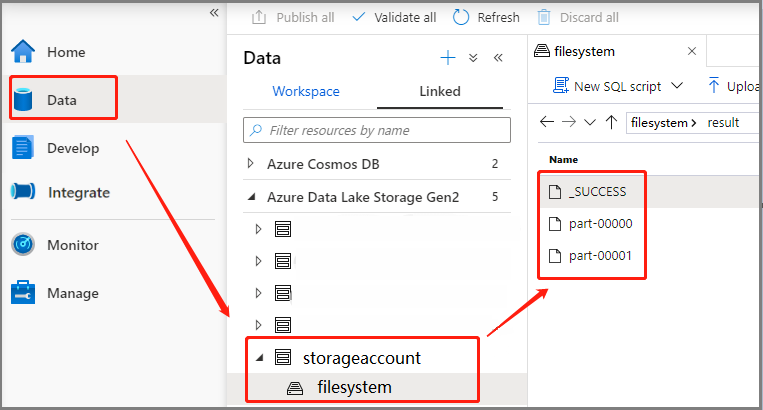
Dans cette section, vous allez ajouter une définition de travail Apache Spark dans le pipeline.
Ouvrez une définition de travail Apache Spark existante.
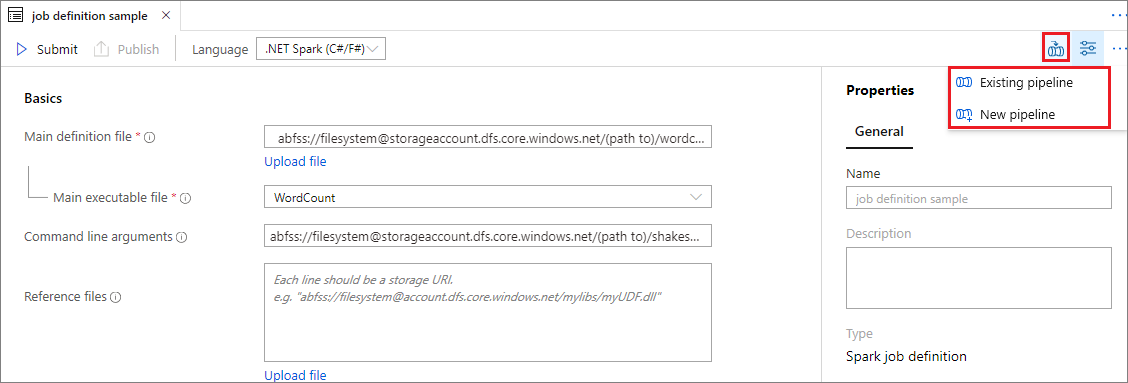
Sélectionnez l’icône en haut à droite de la définition de travail Apache Spark, puis choisissez Pipeline existant ou Nouveau pipeline. Vous pouvez consulter la page Pipeline pour plus d’informations.
À présent, vous pouvez utiliser Azure Synapse Studio pour créer des jeux de données Power BI et gérer des données Power BI. Pour en savoir plus, consultez l’article Liaison d’un espace de travail Power BI à un espace de travail Synapse.
Événements
31 mars, 23 h - 2 avr., 23 h
Le plus grand événement d’apprentissage Fabric, Power BI et SQL. 31 mars au 2 avril. Utilisez le code FABINSIDER pour économiser 400 $.
Inscrivez-vous aujourd’huiEntrainement
Module
Utiliser des notebooks Spark dans un pipeline Azure Synapse - Training
Ce module explique comment intégrer les notebooks Apache Spark dans un pipeline Azure Synapse Analytics.
Certification
Microsoft Certified : Azure Data Engineer Associate - Certifications
Faites la démonstration d’une compréhension des tâches d’engineering données courantes pour implémenter et gérer des charges de travail d’engineering données sur Microsoft Azure en utilisant un certain nombre de services Azure.