Principes de l’architecture
Conseil
Ce contenu est un extrait du livre électronique, Architect Modern Web Applications with ASP.NET Core and Azure (Architecturer des applications web modernes avec ASP.NET Core et Azure), disponible dans la documentation .NET ou en tant que PDF téléchargeable gratuitement qui peut être lu hors connexion.

« Si les bâtisseurs bâtissaient des bâtiments comme les programmeurs écrivent des programmes, le premier pivert passant par là détruirait la civilisation. »
- Gerald Weinberg
Quand vous architecturez et que vous concevez des solutions logicielles, vous devez penser à leur maintenabilité. Les principes présentés dans cette section peuvent vous aider à prendre des décisions en matière d’architecture aboutissant à des applications propres et maintenables. D’une façon générale, ces principes vous guident dans la création d’applications à partir de composants individuels qui ne sont pas étroitement couplés à d’autres parties de votre application, mais qui communiquent plutôt via des interfaces explicites ou des systèmes de messages.
Principes de conception communs
Séparation des responsabilités
Un principe à suivre lors du développement est la séparation des responsabilités. Selon ce principe, le logiciel doit être divisé en fonction des types des tâches qu’il effectue. Par exemple, considérez une application qui inclut une logique pour identifier les éléments dignes d’intérêt à afficher à l’utilisateur, et qui met en forme ces éléments d’une façon particulière afin de les rendre plus visibles. Le comportement responsable du choix des éléments à mettre en forme doit être distinct du comportement responsable de la mise en forme les éléments, car il s’agit de comportements distincts qui n’ont qu’un lien de coïncidence entre elles.
Du point de vue de l’architecture, les applications peuvent être créées de façon logique pour suivre ce principe, en séparant le comportement du cœur de métier de l’infrastructure et de la logique de l’interface utilisateur. Dans l’idéal, les règles et la logique métier doivent se trouver dans un projet distinct, qui ne doit pas dépendre d’autres projets dans l’application. Cette séparation permet de s’assurer que le modèle d’entreprise est facile à tester et qu’il peut évoluer sans être étroitement lié à des détails d’implémentation de bas niveau (elle est également utile si les préoccupations de l’infrastructure dépendent d’abstractions définies dans la couche d’entreprise). La séparation des responsabilités est un aspect fondamental de l’utilisation des couches dans les architectures d’applications.
Encapsulation
Vous devez utiliser l’encapsulation pour isoler les unes des autres les différentes parties d’une application. Les composants et les couches de l’application doivent pouvoir ajuster leur implémentation interne sans porter atteinte au fonctionnement de leurs collaborateurs dès lors que les contrats externes ne sont pas rompus. Une utilisation correcte de l’encapsulation permet d’atteindre un couplage faible et une modularité dans la conception des applications, car les objets et les packages peuvent être remplacés par d’autres implémentations tant que la même interface est conservée.
Dans les classes, l’encapsulation est obtenue en limitant l’accès externe à l’état interne de la classe. Si un acteur externe veut manipuler l’état de l’objet, il doit le faire via une fonction bien définie (ou via une méthode setter de propriété), au lieu d’avoir un accès direct à l’état privé de l’objet. De même, les composants d’application et les applications elles-mêmes doivent exposer des interfaces bien définies que leurs collaborateurs doivent utiliser, au lieu de permettre la modification directe de leur état. Cette approche vous permet de faire évoluer au fil du temps la conception interne de l’application sans craindre d’altérer le bon fonctionnement des collaborateurs tant que les contrats publics sont respectés.
L’état global mutable est antithétique pour l’encapsulation. Une valeur extraite d’un état global mutable dans une fonction ne peut pas être basée sur la même valeur dans une autre fonction (ou même plus loin dans la même fonction). Comprendre les préoccupations liées à l’état global mutable est l’une des raisons pour lesquelles les langages de programmation comme C# prennent en charge différentes règles d’étendue, qui sont utilisées partout, des instructions et des méthodes aux classes. Il est important de noter que les architectures pilotées par les données qui s’appuient sur une base de données centrale pour l’intégration au sein et entre les applications choisissent elles-mêmes de dépendre de l’état global mutable représenté par la base de données. Une considération clé dans la conception basée sur le domaine et l’architecture propre est la façon d’encapsuler l’accès aux données et comment garantir que l’état de l’application n’est pas rendu non valide par l’accès direct à son format de persistance.
Inversion des dépendances
Le sens de la dépendance au sein de l’application doit être celui de l’abstraction, et non pas des détails d’implémentation. La plupart des applications sont écrites de telle sorte que les dépendances de compilation aillent dans le sens de l’exécution du runtime, ce qui génère un graphique de dépendance directe. C’est-à-dire que si la classe A appelle une méthode de la classe B et que la classe B appelle une méthode de la classe C, alors, au moment de la compilation, la classe A dépendra de la classe B et la classe B dépendra de la classe C, comme le montre la figure 4-1.
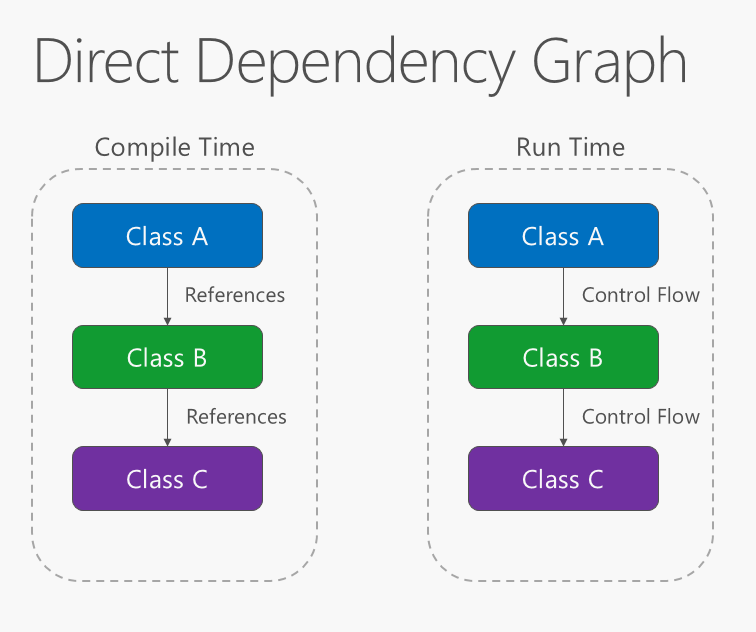
Figure 4-1. Graphe des dépendances directes.
L’application du principe d’inversion de dépendance permet à A d’appeler des méthodes sur une abstraction implémentée par B, ce qui permet à A d’appeler B à l’exécution, mais à B de dépendre d’une interface contrôlée par A au moment de la compilation (inversant ainsi la dépendance classique au moment de la compilation). À l’exécution, le flux de l’exécution du programme reste inchangé, mais l’introduction d’interfaces signifie que des implémentations différentes de ces interfaces peuvent facilement être connectées.
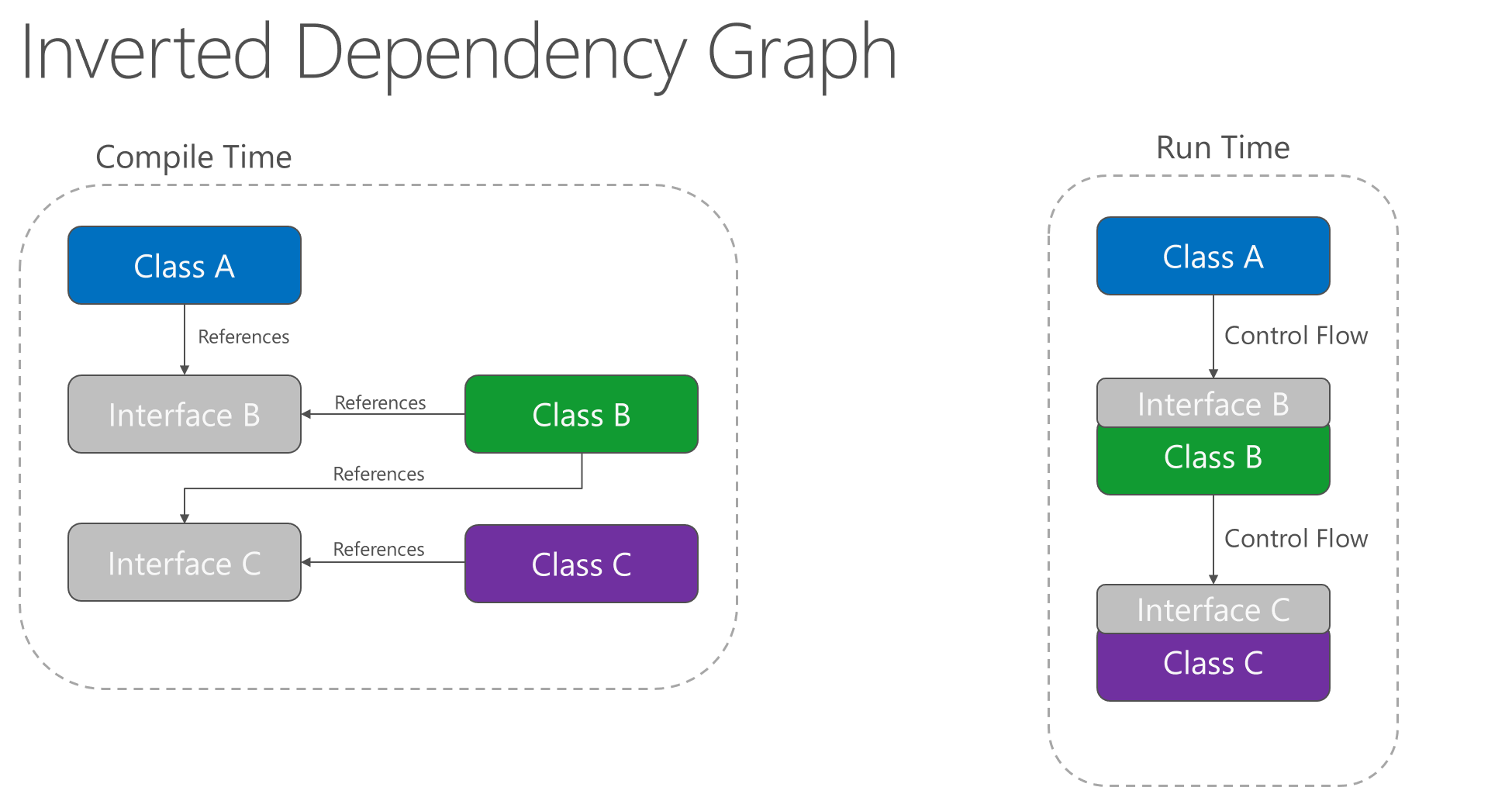
Figure 4-2. Graphe des dépendances inversées.
L’inversion des dépendances est une partie essentielle de la création d’applications faiblement couplées, car les détails d’implémentation peuvent être écrits de façon à dépendre d’abstractions de plus haut niveau et à les implémenter, et non pas l’inverse. Les applications qui en résultent sont plus faciles à tester, plus modulaires et plus maintenables. La pratique de l’injection de dépendances est rendue possible par le respect du principe d’inversion des dépendances.
Dépendances explicites
Les méthodes et les classes doivent demander explicitement tous les objets de collaboration dont ils ont besoin pour fonctionner correctement. On l’appelle le Principe des dépendances explicites. Les constructeurs de classe offrent une occasion pour les classes d’identifier les éléments dont ils ont besoin pour être dans un état valide et pour fonctionner correctement. Si vous définissez des classes qui peuvent être construites et appelées, mais qui fonctionnent correctement seulement si certains composants globaux ou d’infrastructure sont en place, ces classes trompent leurs clients. Le contrat du constructeur indique au client qu’il a seulement besoin des choses spécifiées (éventuellement de rien si la classe utilise seulement un constructeur sans paramètre), mais lors de l’exécution, il apparaît que l’objet avait en fait besoin d’autre chose.
En suivant le principe des dépendances explicites, vos classes et vos méthodes sont honnêtes avec leurs clients quant à ce dont elles ont besoin pour fonctionner. Suivre ce principe rend votre code mieux autodocumenté et vos contrats de codage plus conviviaux, car les utilisateurs leur font alors confiance dès lors qu’ils fournissent ce qui est nécessaire sous la forme de paramètres de méthode ou de constructeur, les objets avec lesquels ils travaillent se comportant alors correctement à l’exécution.
Responsabilité unique
Le principe de responsabilité unique s’applique à la conception orientée objet, mais il peut également être considéré comme un principe d’architecture similaire à la séparation des responsabilités. Il stipule que les objets ne doivent avoir qu’une seule responsabilité et qu’une seule raison de changer. Plus précisément, le seul cas où l’objet doit changer est quand la façon dont il effectue ce dont il est responsable doit être mise à jour. Suivre ce principe permet de produire des systèmes modulaires moins étroitement couplés, car de nombreux types de nouveaux comportements peuvent être implémentés sous forme de nouvelles classes, au lieu d’ajouter des responsabilités supplémentaires aux classes existantes. Ajouter de nouvelles classes est toujours plus sûr que modifier des classes existantes, car aucun code ne dépend déjà des nouvelles classes.
Dans une application monolithique, nous pouvons appliquer le principe de responsabilité unique à un haut niveau aux couches de l’application. La responsabilité de la présentation doit rester dans le projet d’interface utilisateur, alors que la responsabilité de l’accès aux données doit être conservée au sein d’un projet d’infrastructure. La logique métier doit être conservée dans le projet central de l’application, où elle peut être facilement testée et évoluer indépendamment des autres responsabilités.
Quand ce principe est appliqué à l’architecture d’une application et mené à son aboutissement logique, vous obtenez des microservices. Un microservice donné ne doit avoir qu’une seule responsabilité. Si vous devez étendre le comportement d’un système, il est généralement préférable de le faire en ajoutant des microservices supplémentaires, au lieu d’ajouter une responsabilité à un microservice existant.
En savoir plus sur l’architecture des microservices
Ne vous répétez pas (DRY)
L’application doit éviter de spécifier à plusieurs endroits un comportement lié à un concept particulier, car cette pratique est une source d’erreurs fréquente. À un moment donné, une modification des exigences nécessite de modifier ce comportement. Il est probable qu’au moins une instance du comportement ne soit pas mise à jour et que le système se comporte de manière incohérente.
Au lieu de dupliquer la logique, encapsulez-la dans une construction de programmation. Faites de cette construction la seule autorité sur ce comportement, et faites en sorte que toutes les autres parties de l’application qui ont besoin de ce comportement utilisent la nouvelle construction.
Notes
Évitez de lier ensemble des comportements qui sont répétitifs seulement par coïncidence. Par exemple, le simple fait que deux constantes différentes ont toutes les deux la même valeur ne signifie pas que vous ne devez avoir qu’une seule constante, dès lors qu’elles font conceptuellement référence à des choses différentes. La duplication est toujours préférable au couplage vers la mauvaise abstraction.
Ignorance de la persistance
L’ignorance de la persistance fait référence aux types qui doivent être stockés, mais dont le code n’est pas affecté par le choix de la technologie de stockage. Ces types dans .NET sont parfois appelés des OCT (objets CLR traditionnels), car ils n’ont pas besoin d’hériter d’une classe de base particulière ni d’implémenter une interface particulière. L’ignorance de la persistance est pratique, car elle permet au même modèle métier d’être stocké de plusieurs façons, ce qui offre davantage de flexibilité à l’application. Les choix de stockage peuvent changer au fil du temps, d’une technologie de base de données à une autre, ou bien d’autres formes de persistance peuvent être nécessaires en plus de ce avec quoi l’application a démarré (par exemple l’utilisation d’un cache Redis ou d’Azure Cosmos DB en plus d’une base de données relationnelle).
Voici quelques exemples de violation de ce principe :
Une classe de base obligatoire.
Une implémentation d’interface obligatoire.
Des classes responsables de leur propre enregistrement (comme le modèle Enregistrement actif).
Un constructeur sans paramètre obligatoire.
Des propriétés nécessitant un mot clé virtuel.
Des attributs obligatoires propres à la persistance.
La nécessité pour les classes de n’avoir aucune des caractéristiques ou aucun des comportements ci-dessus ajoute un couplage entre les types qui doivent être stockés et le choix de la technologie de stockage, ce qui rend difficile l’adoption de nouvelles stratégies d’accès aux données dans le futur.
Contextes délimités
Les contextes délimités sont un modèle essentiel dans la conception pilotée par le domaine. Elles offrent un moyen de maîtriser la complexité dans les applications ou les organisations de grande ampleur en la fractionnant en modules conceptuels distincts. Chaque module conceptuel représente alors un contexte qui est distinct des autres contextes (et donc délimités) et qui peut évoluer indépendamment. Chaque contexte délimité doit idéalement être libre de choisir ses propres noms pour les concepts qu’il contient, et doit avoir un accès exclusif à son propre magasin de persistance.
Au minimum, les applications web individuelles doivent s’efforcer d’être leur propre contexte délimité, avec leur propre magasin de persistance pour leur modèle métier, au lieu de partager une base de données avec d’autres applications. La communication entre des contextes délimités se fait via des interfaces de programmation et non pas via une base de données partagée, ce qui permet à la logique métier et aux événements de se dérouler en réponse aux modifications qui se produisent. Les contextes délimités correspondent étroitement aux microservices, qui dans l’idéal sont également implémentés sous la forme de leurs propre contexte délimité individuel.
Ressources supplémentaires
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour