Événements
31 mars, 23 h - 2 avr., 23 h
Le plus grand événement d’apprentissage Fabric, Power BI et SQL. 31 mars au 2 avril. Utilisez le code FABINSIDER pour économiser 400 $.
Inscrivez-vous aujourd’huiCe navigateur n’est plus pris en charge.
Effectuez une mise à niveau vers Microsoft Edge pour tirer parti des dernières fonctionnalités, des mises à jour de sécurité et du support technique.
Dans ce guide de démarrage rapide, vous allez générer un pipeline de données pour déplacer un exemple de jeu de données vers le Lakehouse. Cette expérience vous montre une démonstration rapide sur l’utilisation de l’activité de copie de pipeline et sur le chargement de données dans Lakehouse.
Pour commencer, vous devez remplir les conditions préalables suivantes :
Accédez à Power BI.
Sélectionnez l’icône Power BI en bas à gauche de l’écran, puis sélectionnez Fabric pour ouvrir la page d’accueil de Microsoft Fabric.
Accédez à votre espace de travail Microsoft Fabric. Si vous avez créé un espace de travail dans la section Prérequis précédente, utilisez celui-ci.
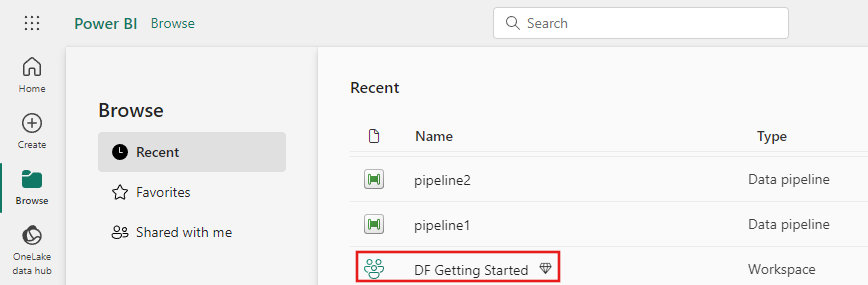
Sélectionnez Nouvel élément et choisissez Pipeline de données, puis saisissez un nom pour créer un pipeline.
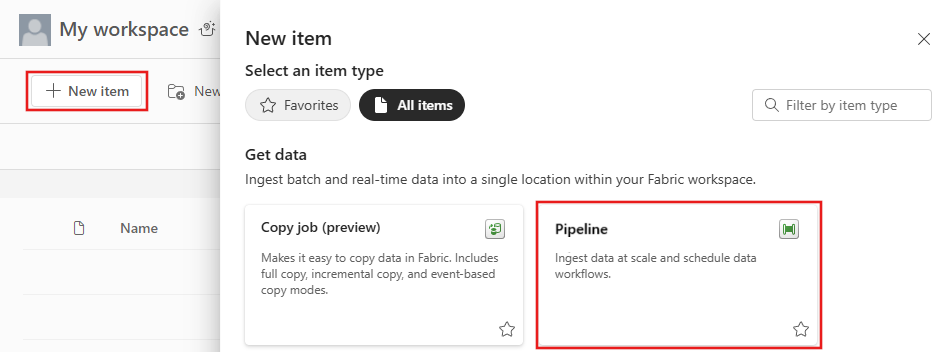

Dans cette session, vous commencez à générer votre premier pipeline en suivant les étapes ci-dessous sur la copie depuis un exemple de jeu de données fourni par le pipeline dans Lakehouse.
Après avoir sélectionné Assistant pour copier des données sur le canevas, l’outil Assistant de copie est ouvert pour démarrer.
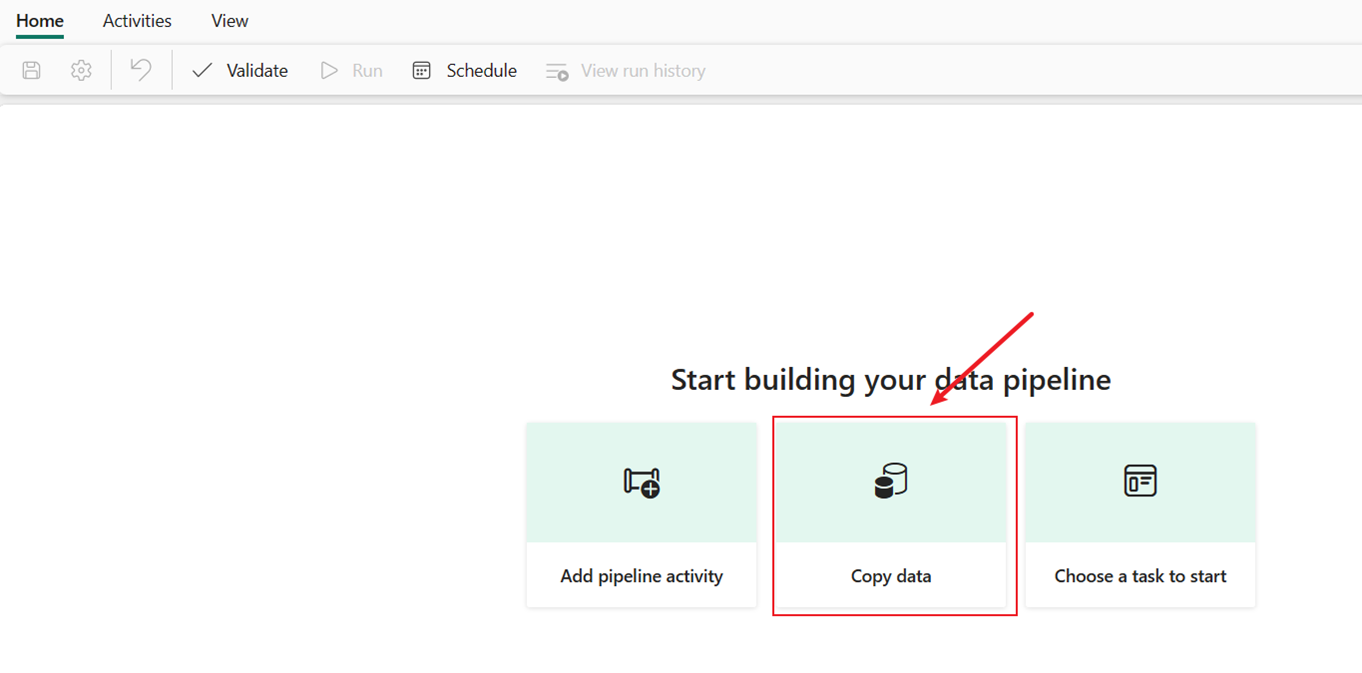
Choisissez l’onglet Exemples de données en haut de la page du navigateur de source de données, puis sélectionnez les exemples de données Jours fériés, puis Suivant.
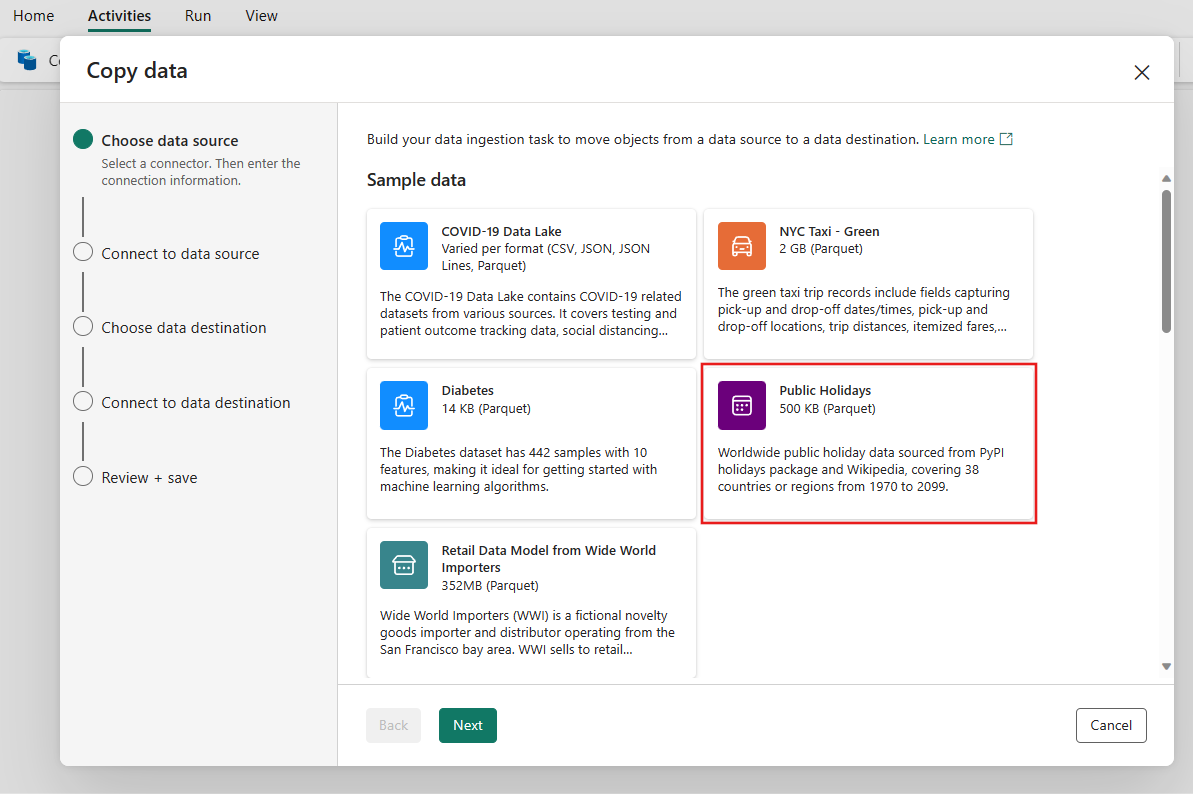
Sur la page Se connecter à la source de données de l’assistant, l’aperçu de l’échantillon de données Jours Fériés s’affiche, puis sélectionnez Suivant.
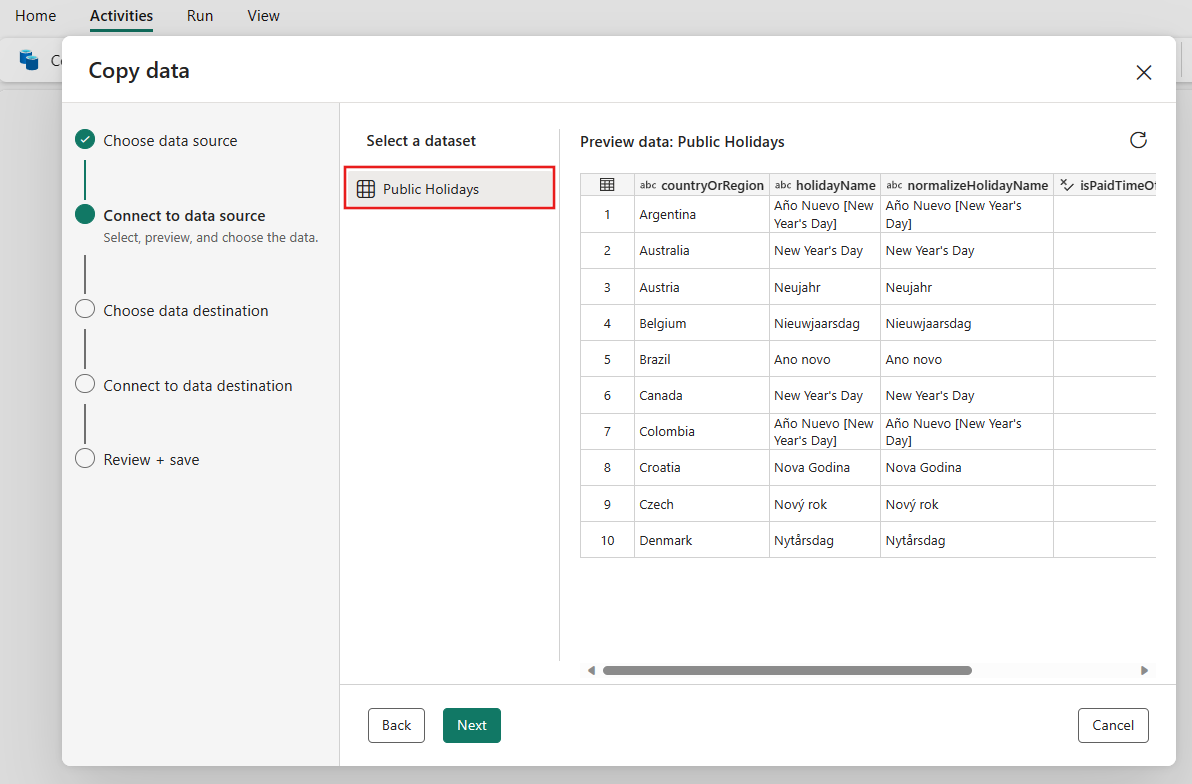
Sélectionnez Lakehouse, puis Suivant.
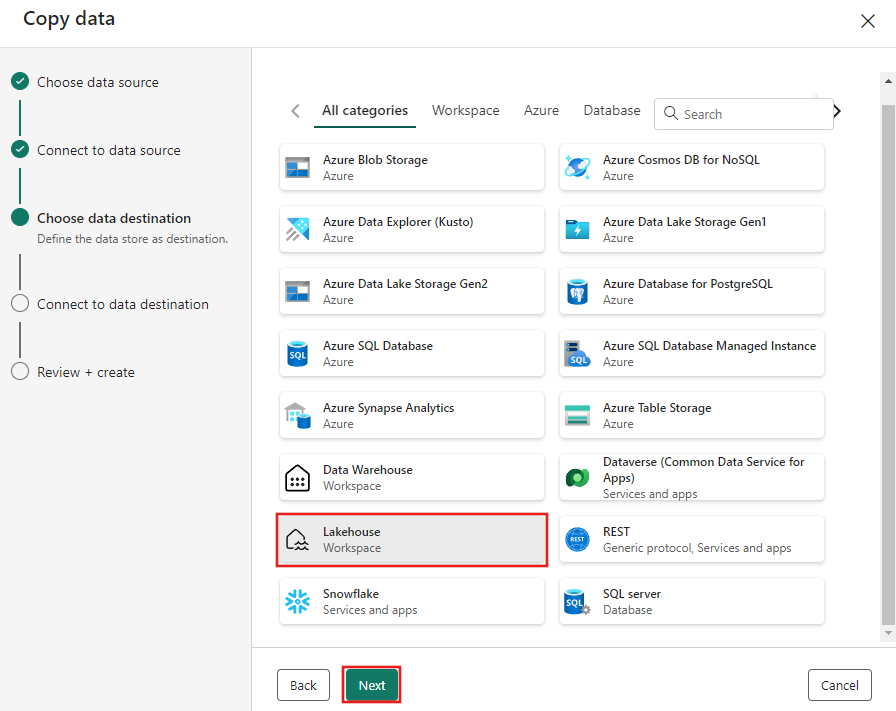
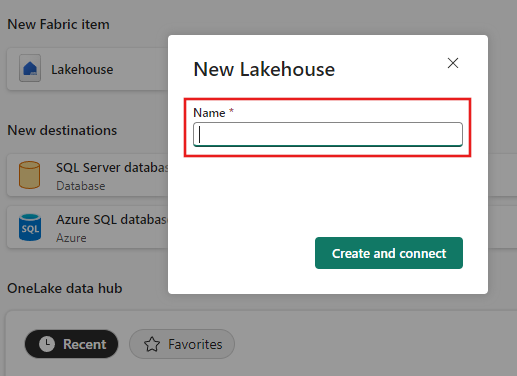
Entrez un nom de lakehouse, puis sélectionnez Créer et connecter.
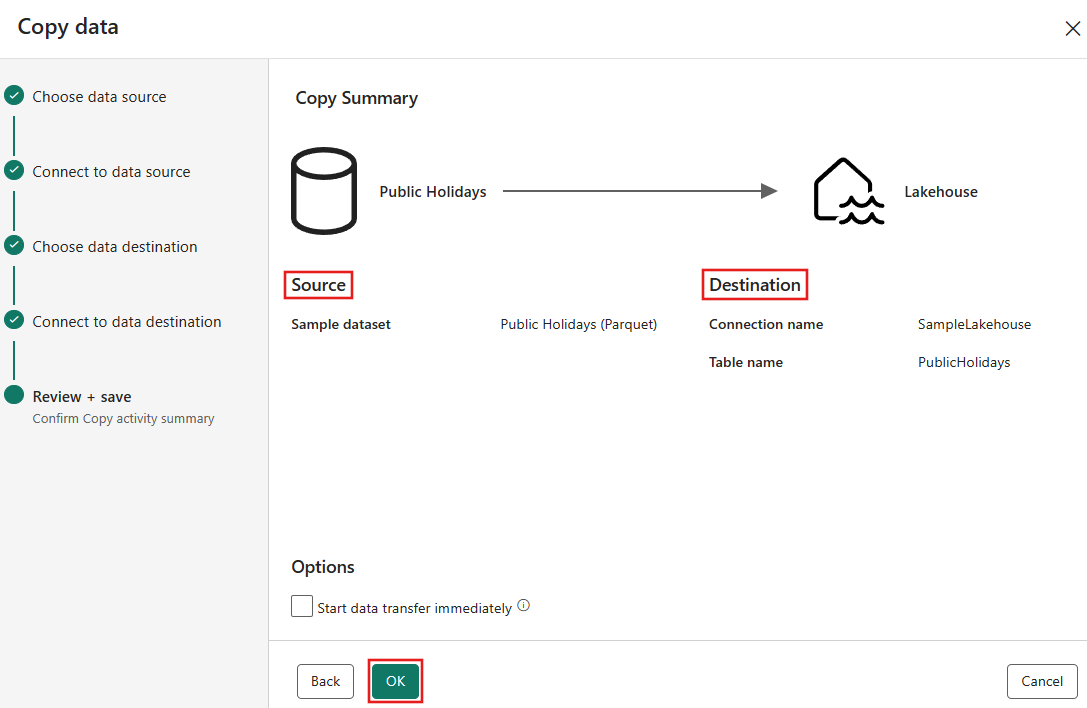
Configurez, puis mappez vos données sources sur la table Lakehouse de destination. Sélectionnez Tables pour le dossier racine et Charger dans une nouvelle table pour Paramètres de chargement. Indiquez un nom de table et sélectionnez Suivant.

Passez en revue vos paramètres d’activité Copy dans les étapes précédentes, puis sélectionnez Enregistrer + Exécuter pour terminer. Vous pouvez également revenir sur les étapes précédentes de l’outil pour modifier vos paramètres, si nécessaire. Si vous souhaitez simplement enregistrer, mais pas exécuter le pipeline, vous pouvez décocher immédiatement la case Démarrer le transfert de données immédiatement.
L’activité Copy est ajoutée à votre nouveau canevas de pipeline de données. Tous les paramètres, y compris les paramètres avancés pour l’activité, sont disponibles dans les onglets situés sous le canevas du pipeline lorsque l’activité Copier les données créée est sélectionnée.
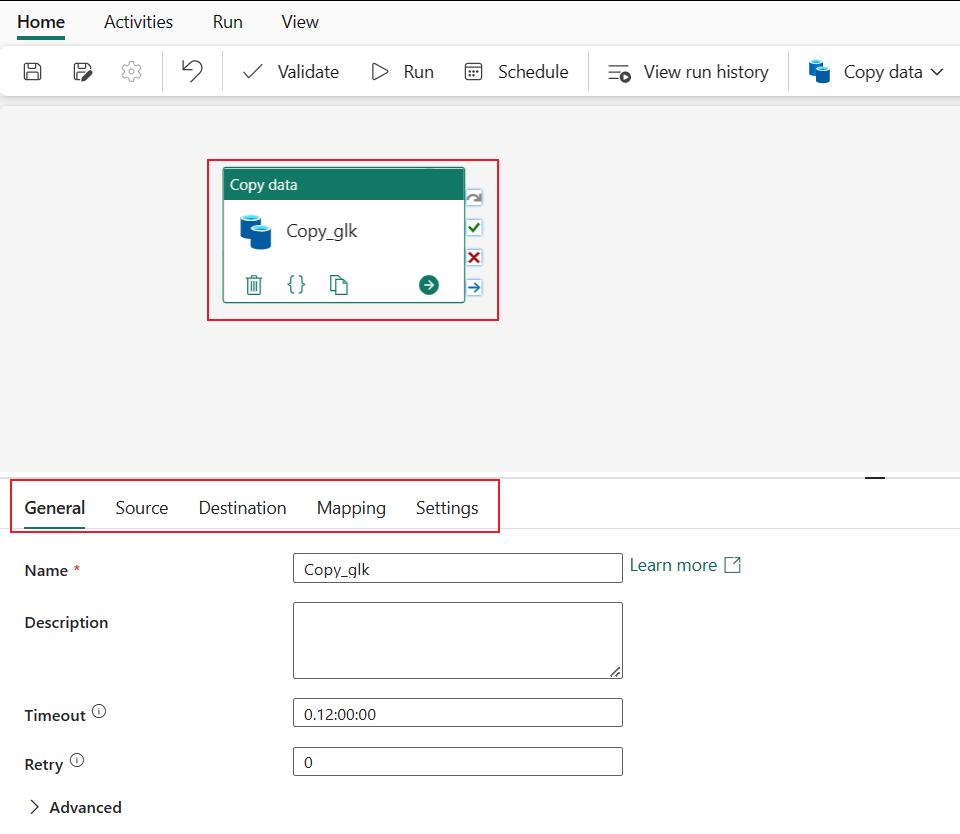
Si vous n’avez pas choisi d’enregistrer Enregistrer + Exécuter sur la page Vérifier + enregistrer de l’Assistant pour copier des données, basculez vers l’onglet Accueil et sélectionnez Exécuter. Une boîte de dialogue de confirmation s’affiche. Sélectionnez ensuite Enregistrer et exécuter pour démarrer l’activité.

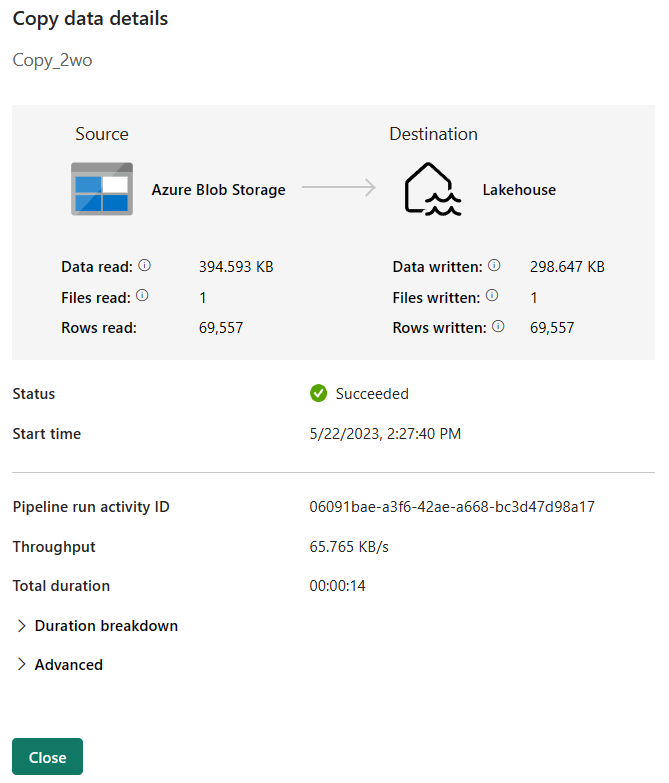
Vous pouvez superviser le processus en cours d’exécution, puis vérifier les résultats sous l’onglet Sortie sous le canevas du pipeline. Sélectionnez le lien correspondant au nom de l’activité dans votre sortie pour afficher les détails de l’exécution.

Les détails de l’exécution indiquent la quantité de données lues et écrites, ainsi que divers autres détails sur l’exécution.
Vous pouvez également planifier l’exécution du pipeline avec une fréquence spécifique si nécessaire. Voici un exemple montrant un programme pour le pipeline, prévu pour s'exécuter toutes les 15 minutes.

Le pipeline de cet exemple montre comment copier des exemples de données vers Lakehouse. Vous avez appris à :
Ensuite, avancez pour en savoir plus sur la surveillance des exécutions de votre pipeline.
Événements
31 mars, 23 h - 2 avr., 23 h
Le plus grand événement d’apprentissage Fabric, Power BI et SQL. 31 mars au 2 avril. Utilisez le code FABINSIDER pour économiser 400 $.
Inscrivez-vous aujourd’huiEntrainement
Module
Utiliser des pipelines Data Factory dans Microsoft Fabric - Training
Utiliser des pipelines Data Factory dans Microsoft Fabric
Certification
Certifié Microsoft : Fabric Data Engineer Associate - Certifications
En tant qu’ingénieur données fabric, vous devez avoir une expertise en matière de modèles de chargement de données, d’architectures de données et de processus d’orchestration.