Notes
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de vous connecter ou de modifier des répertoires.
L’accès à cette page nécessite une autorisation. Vous pouvez essayer de modifier des répertoires.
Les tables agrégées ou les ensembles de données agrégés sont des ensembles de données dénormalisés qui contiennent des valeurs de mesure agrégées (par exemple : émissions de CO2e, utilisation de l’eau ou déchets générés) à partir des tables du modèle de données environnementales, sociales et de gouvernance (ESG) pour un ensemble complet de dimensions, y compris la période de rapport. Les métriques ESG sont calculées depuis ces tables agrégées.
Cette fonctionnalité fournit un ensemble de notebooks prédéfinis que vous pouvez utiliser pour générer ces tables agrégées pour le calcul de métriques prédéfinies et personnalisées. Les notebooks contiennent la logique de calcul permettant de générer ces tables agrégées.
| Nom de table agrégée | Notebook prédéfini |
|---|---|
| EmissionsAggregate | CreateAggregateForEmissionsMetrics_INTB |
| EmployeeDataAggregate | CreateAggregateForEmployeeMetrics_INTB |
| EmployeeEventsAggregate | CreateAggregateForEmployeeEventMetrics_INTB |
| IncidentDataAggregate | CreateAggregateForIncidentMetrics_INTB |
| NetRevenueAggregate | CreateAggregateForNetRevenueMetrics_INTB |
| PreCalculatedMetricsAggregate | CreateAggregateForPreCalculatedMetrics_INTB |
| ResourceInflowsAggregate | CreateAggregateForResourceInflowMetrics_INTB |
| ResourceOutflowsAggregate | CreateAggregateForResourceOutflowMetrics_INTB |
| SustainabilityContentResourceInflowsAggregate | CreateAggregateForResourceInflowsSustainabilityContentMetrics_INTB |
| SustainabilityContentResourceOutflowsAggregate | CreateAggregateForResourceOutflowsSustainabilityContentMetrics_INTB |
| WasteQuantityAggregate | CreateAggregateForWasteMetrics_INTB |
| WaterStorageAggregate | CreateAggregateForWaterStorageMetrics_INTB |
| WaterUtilizationAggregate | CreateAggregateForWaterUtilizationMetrics_INTB |
| BoardMembersAggregate | CreateAggregateForBoardMembersMetrics_INTB |
Générer des tables agrégées
Reportez-vous à la bibliothèque de métriques prédéfinies pour sélectionner la métrique à calculer et déterminer la table d’agrégation requise à générer. Exécutez ensuite le notebook correspondant (à partir de la table précédente) séparément ou exécutez le pipeline ExecuteToCreateAggregates_DTPL en sélectionnant la table d’agrégation à générer dans le paramètre de pipeline.
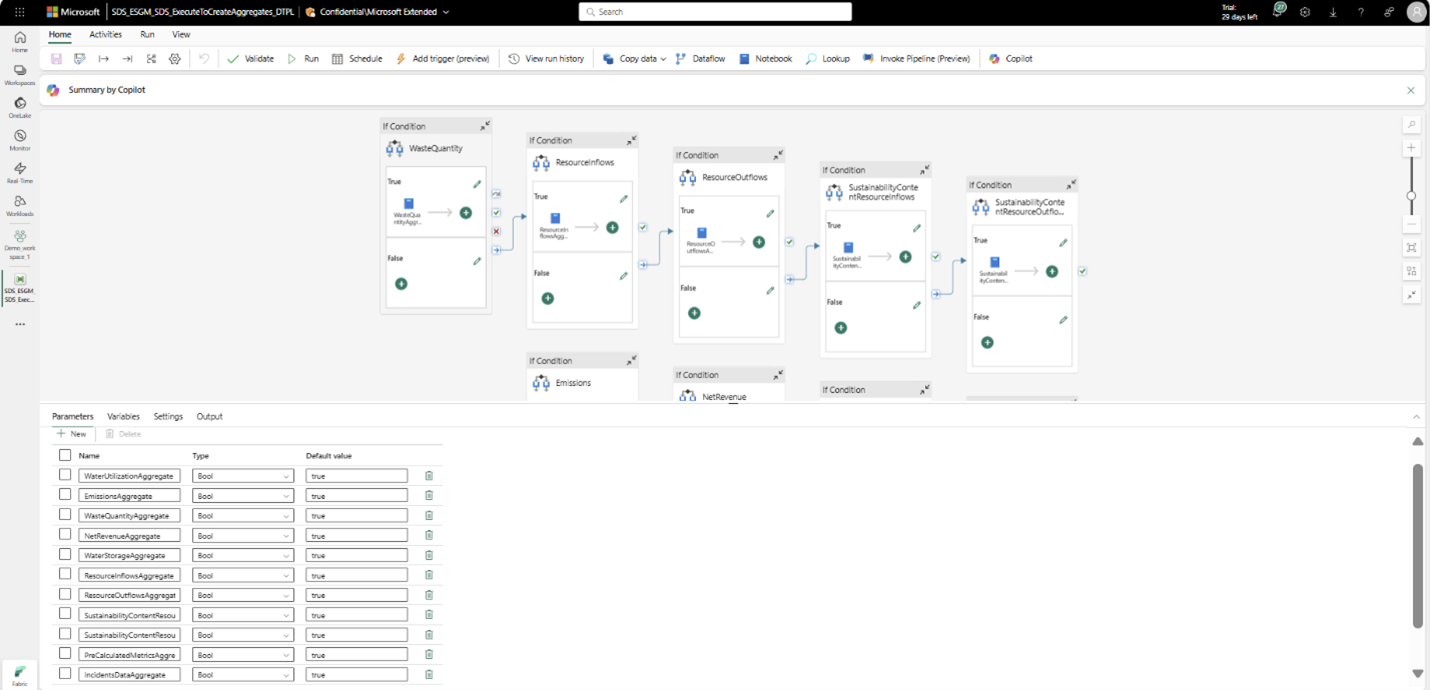
Nonte
Par défaut, le pipeline génère toutes les tables d’agrégation puisque les paramètres sont définis sur True. Si vous souhaitez générer des données uniquement pour une table d’agrégation spécifique, définissez la valeur de toutes les tables d’agrégation restantes sur false.
Lorsque le notebook ou le pipeline s’exécute correctement, la table d’agrégation doit être générée et stockée dans la lakehouse ComputedESGMetrics. Si la table d’agrégation existe déjà, elle est écrasée.
Nonte
Cette étape correspond à l’activité Créer des tables agrégées dans le pipeline ExecuteComputationForMetrics_DTPL. Le pipeline ExecuteToCreateAggregates_DTPL est appelé en tant qu’activité dans ce pipeline. Cela signifie que vous pouvez également exécuter l’activité Créer des tables agrégées pour générer les tables agrégées.
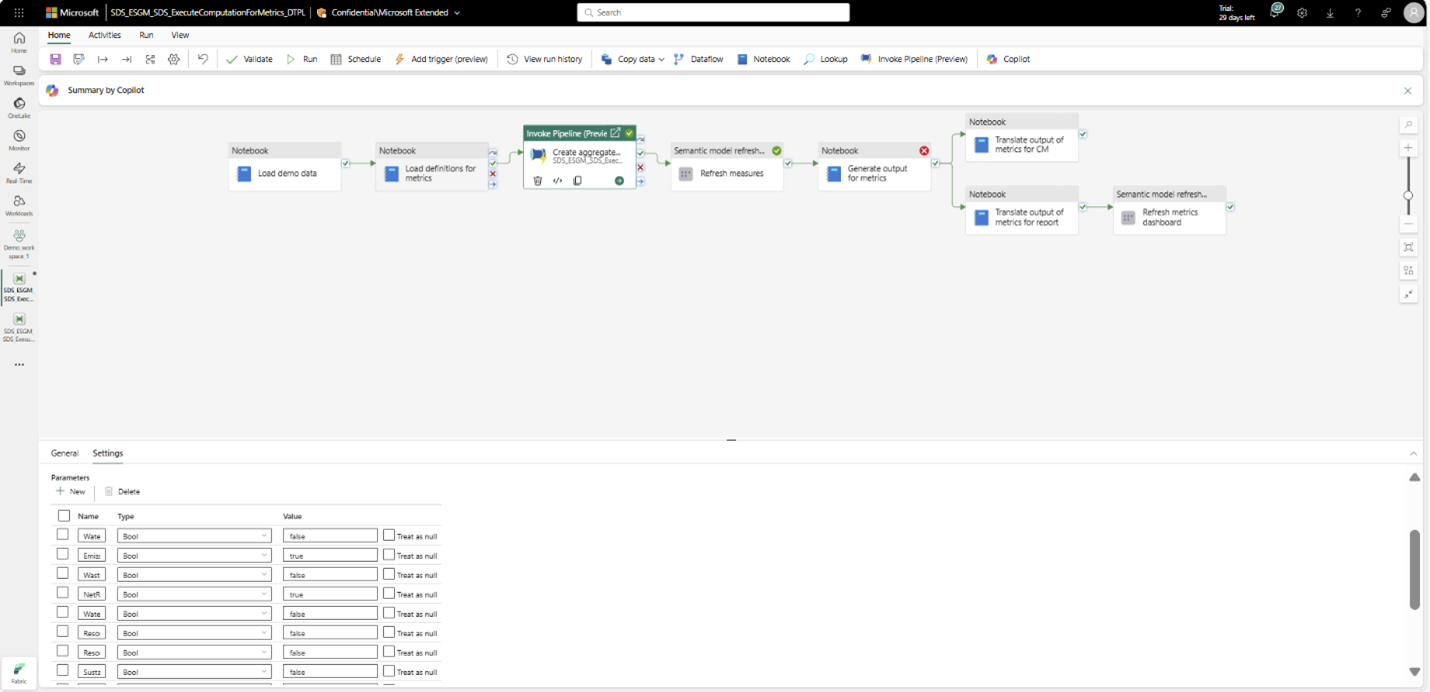
Actualisez le modèle sémantique des métriques (DatasetForMetricsMeasures_DTST) afin que les dernières données agrégées de la table soient mises à jour dans le modèle sémantique.
Pour la première actualisation, vous devez authentifier le modèle sémantique en créant une connexion. Pour plus d’informations, consultez Conditions préalables. Ensuite, ouvrez le modèle sémantique DatasetForMetricsMeasures_DTST à partir de la page de l’espace de travail et sélectionnez Actualiser maintenant dans le menu Actualiser pour actualiser le modèle sémantique.
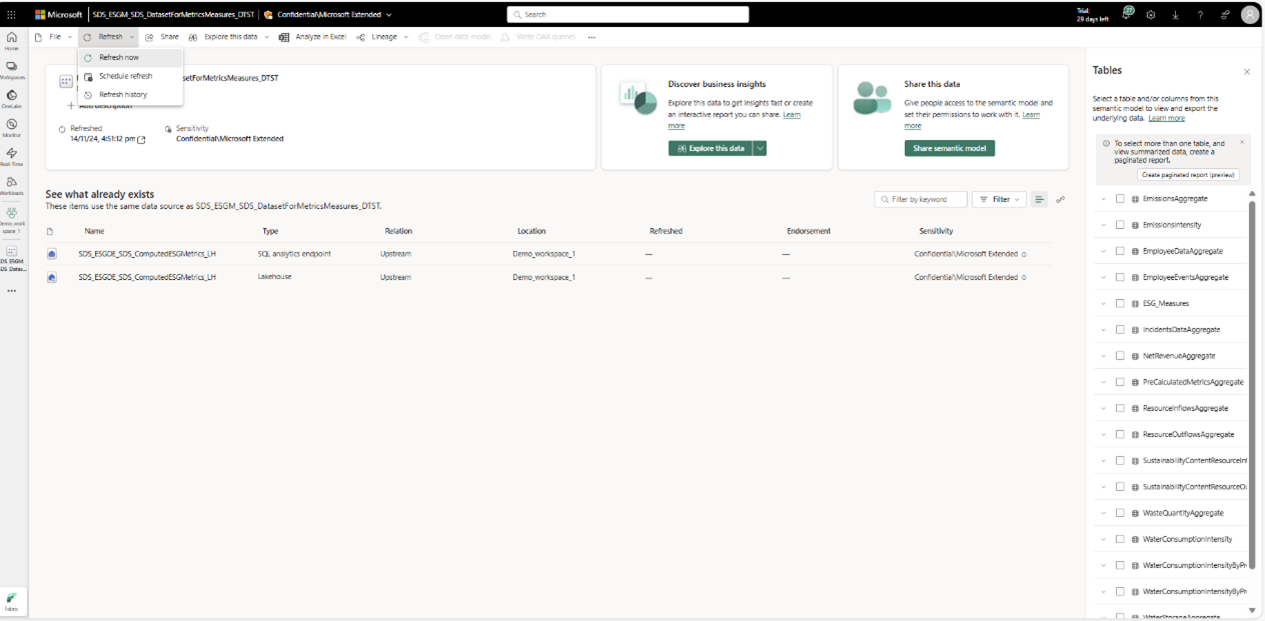
Une fois l’actualisation terminée, vous pouvez sélectionner Actualiser l’historique dans le menu Actualiser pour confirmer l’état de l’actualisation. S’il existe des erreurs, vous pouvez trouver les détails de l’erreur dans l’historique d’actualisation.
Cette étape correspond à l’activité Actualiser les métriques dans le pipeline ExecuteComputationForMetrics_DTPL. Vous pouvez également exécuter cette activité pour actualiser le modèle sémantique.
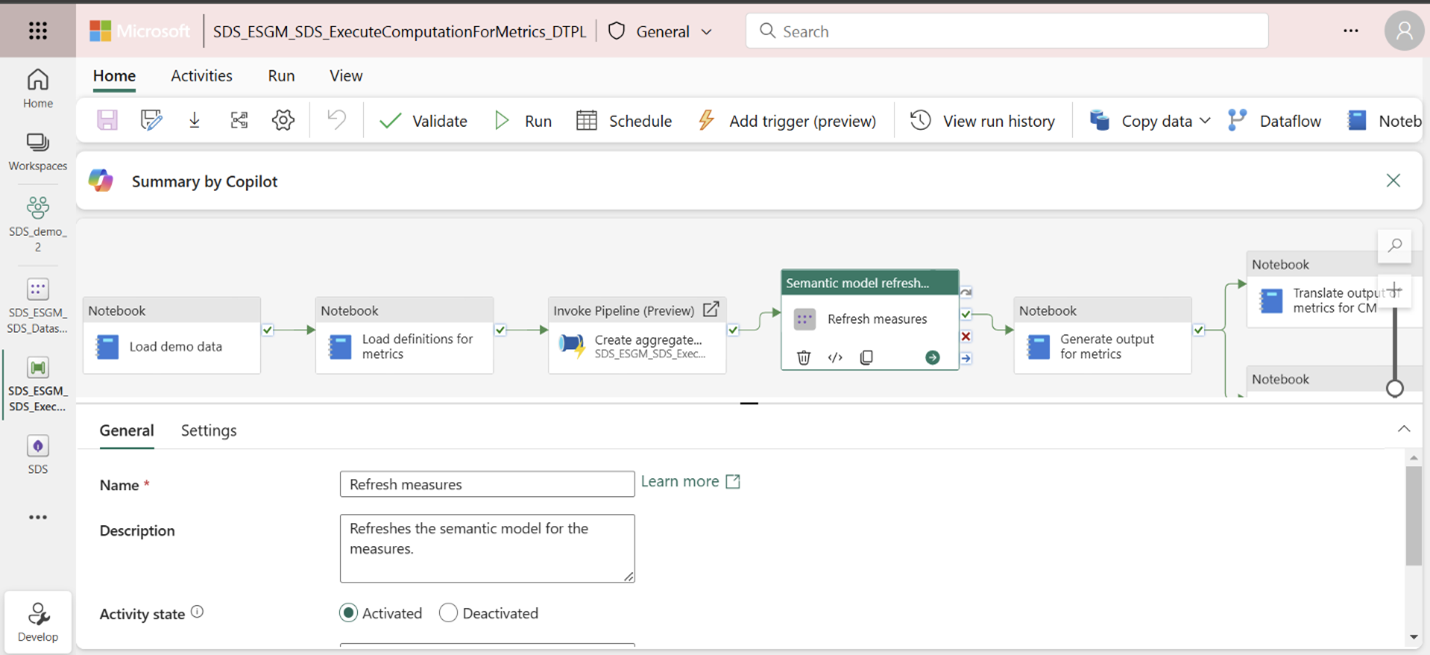
Si c’est la première fois que vous exécutez le pipeline, vous devez également configurer une connexion pour l’activité Actualiser les mesures du pipeline. Pour plus d’informations sur cette étape, reportez-vous aux conditions préalables mentionnées dans Découvrir les données de démonstration.




Une fois ces étapes exécutées correctement, la table agrégée doit apparaître sous les tables dans ComputedESGMetrics_LH et le modèle sémantique doit contenir les données mises à jour.
