Suivi des incidents
Les incidents ont un cycle de vie. Pour y répondre le plus efficacement possible, vous devez pouvoir suivre l’évolution de l’incident lui-même, et celle de votre réponse, dès le tout début de ce cycle de vie.
Évaluer ce que vous savez
Un bon moyen d’évaluer votre procédure de suivi d’incident en utilisant un incident spécifique consiste à vous poser une série de questions :
- Quand avez-vous eu connaissance du problème pour la première fois ? Si votre objectif est de réduire le temps nécessaire au rétablissement des services suite à des incidents, vous devez commencer à capturer des informations à partir du moment où vous prenez connaissance du problème.
- Comment avez-vous détecté le problème ? Votre système de supervision vous a-t-il averti de l’incident ? En avez-vous d’abord entendu parler par vos clients mécontents, soit directement, soit sur des réseaux sociaux ?
- Si vous venez juste de découvrir le problème, êtes-vous la première personne à en avoir connaissance ? Si oui, qui avez-vous besoin d’avertir ? Si non, qui d’autre est conscient du problème ?
- Si d’autres personnes savent, qu’est-ce qui est entrepris (le cas échéant) ? Est-ce que tout le monde part du principe qu’une personne s’en charge ou est-ce que quelqu’un a commencé à prendre des mesures pour y remédier ?
- Quelle est l’ampleur du problème ? Il est possible que nous n’ayons aucune idée de la gravité ou de l’impact du problème et il peut s’avérer difficile de le déterminer vraiment, ainsi que de savoir qui est affecté.
Il peut s’avérer difficile de répondre à ces questions si aucun suivi n’est en place.
Normaliser le suivi des informations sur l’incident
Vous pouvez conserver et partager votre liste d’incidents (en cours ou autres) et toutes les informations actuelles qui s’y rapportent à de nombreux emplacements possibles. Vous pouvez par exemple utiliser simplement une zone de fichiers partagés avec des documents Word ou avoir recours à des logiciels et services plus complexes et très spécialisés de suivi des incidents. Entre ces deux extrêmes se trouvent les systèmes de gestion de tickets et de suivi du travail dont vous pouvez vous servir pour cette tâche. Le système que vous choisissez est en réalité moins important que la manière dont vous l’utilisez. Quel que soit le système que vous utilisez, toute personne susceptible d’être concernée par les incidents (ingénieurs, support, direction, relations publiques, service juridique, etc.) doit savoir où se diriger pour accéder au système, comment signaler un incident et comment accéder aux données, le cas échéant. Une façon d’aller tout droit à l’échec en matière de suivi des incidents est de ne pas faire en sorte que les personnes en charge sachent comment accéder au système (« C’est quoi l’URL de notre système au fait ? ») quand elles en ont besoin.
Dans ce module, nous utilisons la fonctionnalité d’élément de travail dans Azure DevOps pour notre exemple de système de suivi.
Créer un mode de conversation
Pour répondre à certaines des questions évoquées dans la section Évaluer ce que vous savez précédente et pour démarrer le processus de réponse aux incidents, vous devez disposer d’un moyen de communiquer avec d’autres personnes sur l’incident. Dans l’idéal, il s’agit d’une sorte de moyen de communication électronique pour la « collaboration des équipes », même si les conférences téléphoniques fonctionnent également. Les appels/conférences téléphoniques sont moins pratiques, car il est plus difficile de revoir rétroactivement les communications sur les incidents (d’où le rôle de « Transcripteur » mentionné précédemment).
Quel que soit le moyen choisi, vous devez veiller à mettre en place un canal unique, strictement limité aux discussions sur cet incident et rien d’autre. Il est important d’écarter toute discussion hors sujet de ce canal, car vous avez besoin d’être en mesure d’extraire les données pour les analyser plus tard dans le cadre de votre examen post-incident.
Dans ce module, nous allons utiliser Microsoft Teams comme méthode de communication sur l’incident.
Automatiser le lancement du suivi des incidents
Récapitulons ce que nous avons rassemblé jusqu’à présent. Nous avons :
- Mettez sur une liste les personnes d’astreinte (et un roulement défini pour elles).
- Le rôle que nous pouvons affecter aux personnes travaillant sur un incident.
- Un emplacement spécifique pour déclarer l’incident et en effectuer le suivi.
- Un canal de communication unique pour les personnes qui travaillent sur cet incident et ont besoin d’en parler.
Vous pouvez créer et vous devez automatiser la création et la gestion de tous ces éléments dans toute la mesure du possible. En cas de problème urgent, vous n’avez pas le temps de redéfinir toutes les étapes nécessaires pour déclencher un incident, solliciter les bonnes personnes et effectuer le suivi du problème. Tout ce que vous voulez réellement faire, c’est lancer immédiatement le travail qui va résoudre le problème.
Utiliser Logic Apps pour une automatisation sans code
L’une des méthodes permettant d’automatiser votre réponse initiale consiste à utiliser Logic Apps pour simplifier le travail de planification, d’automatisation et d’orchestration des tâches, les processus métier et les workflows.
Logic Apps est un service cloud Azure qui permet de créer des solutions d’intégration. Il utilise des connecteurs pour créer des workflows automatisés. Des déclencheurs démarre l’application logique quand un événement spécifique se produit ou lorsque des données remplissent des critères spécifiés. Des actions correspondent aux opérations qui sont alors exécutées dans le workflow de l’application logique.
Pour notre exemple, nous allons utiliser les connecteurs d’application logique suivants pour le suivi des incidents :
- Azure Boards (composant d’Azure DevOps), que vous pouvez utiliser pour créer et suivre des problèmes/incidents.
- Stockage Azure dans lequel vous pouvez stocker et récupérer des informations sur les personnes d’astreinte afin d’affecter les bonnes personnes pour répondre à l’incident. Dans notre exemple, nous allons utiliser le service Stockage Table Azure, car il offre un magasin de type « clé-valeur » très simple qui facilite le stockage d’une liste d’ingénieurs et de leur statut d’astreinte.
- Microsoft Teams que vous pouvez utiliser pour créer un canal d’incident unique afin d’effectuer le suivi des conversations de vos équipes d’ingénieurs en temps réel au fur et à mesure qu’elles communiquent sur des incidents spécifiques. Cela vous permet de conserver une trace des interactions ayant eu lieu sur la chronologie des événements afin de vous y référer plus tard lors d’un examen postérieur à l’incident.
Nous allons maintenant combiner tout cela dans une application logique. Commençons par jeter un coup d’œil à l’application complète, comme elle se présente dans le Concepteur Logic Apps. Nous l’examinerons ensuite pas à pas.
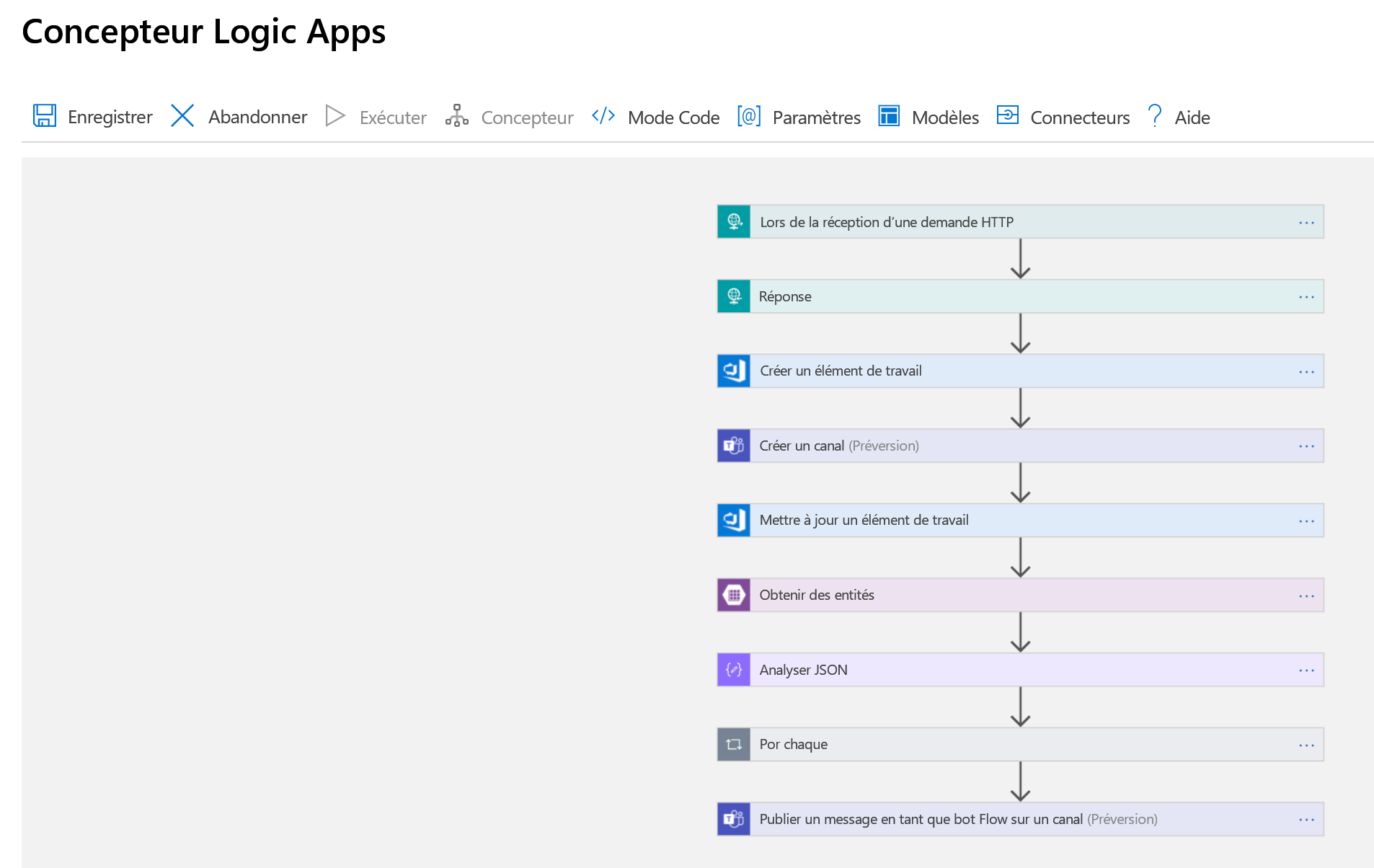
La première étape consiste à gérer un déclencheur, cette requête HTTP que nous avons mentionnée. Une requête HTTP POST est envoyée à notre application logique. Elle contient une charge utile JSON avec des informations sur l’incident que nous voulons déclarer. Nous analysons cette charge utile et renvoyons un accusé de réception pour confirmer que nous l’avons bien reçue :
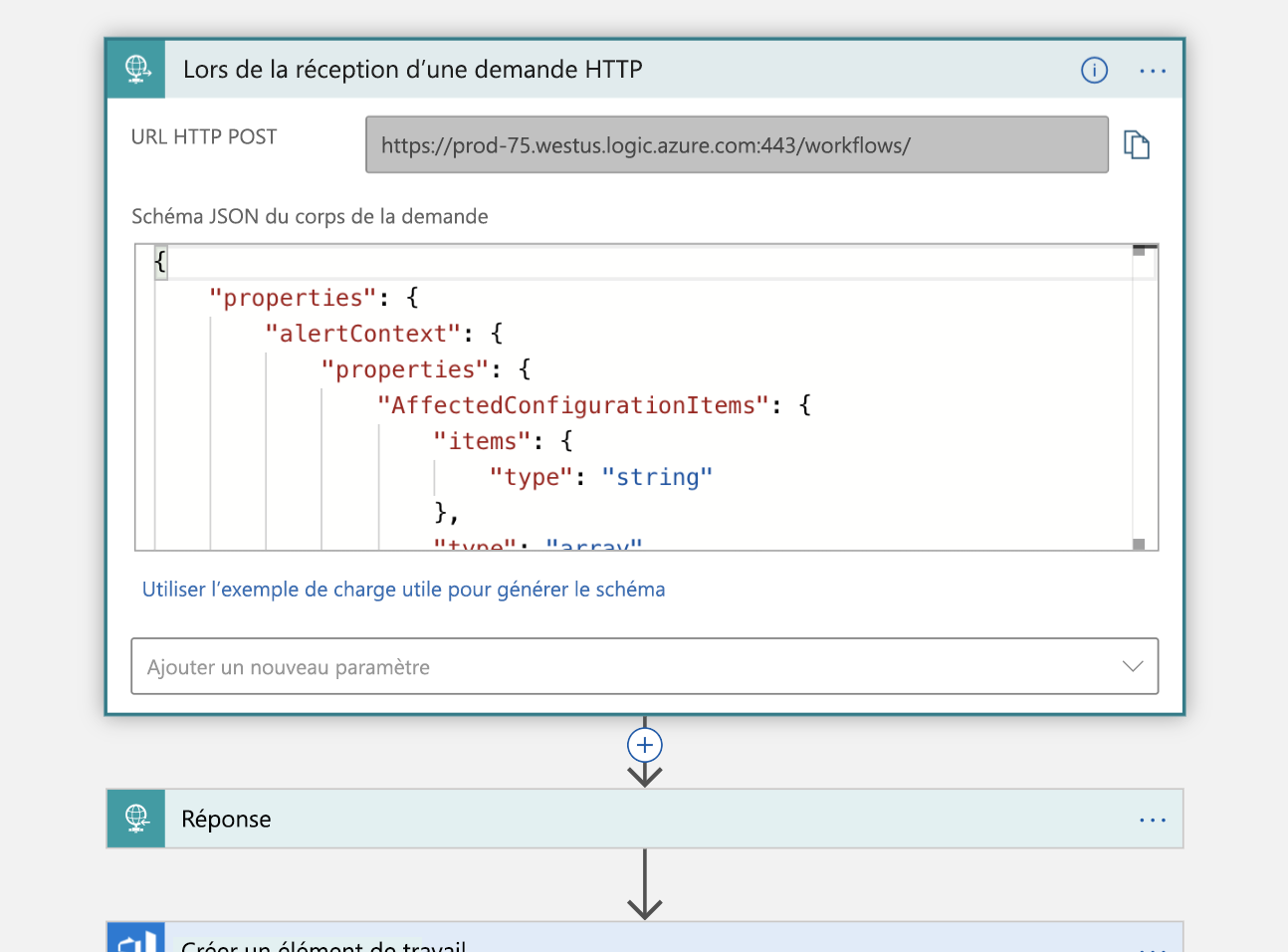
À l’aide de ces informations, nous créons un élément de travail dans notre organisation Azure DevOps qui représente cet incident.
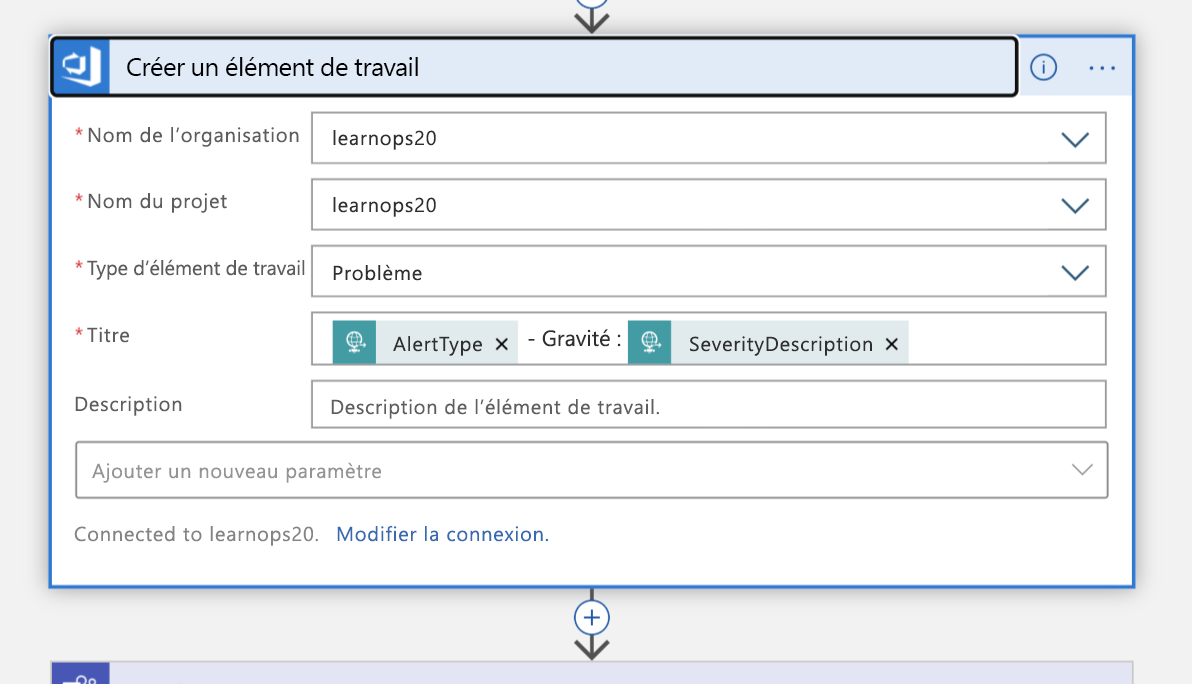
Un canal Teams sera alors créé pour l’incident :
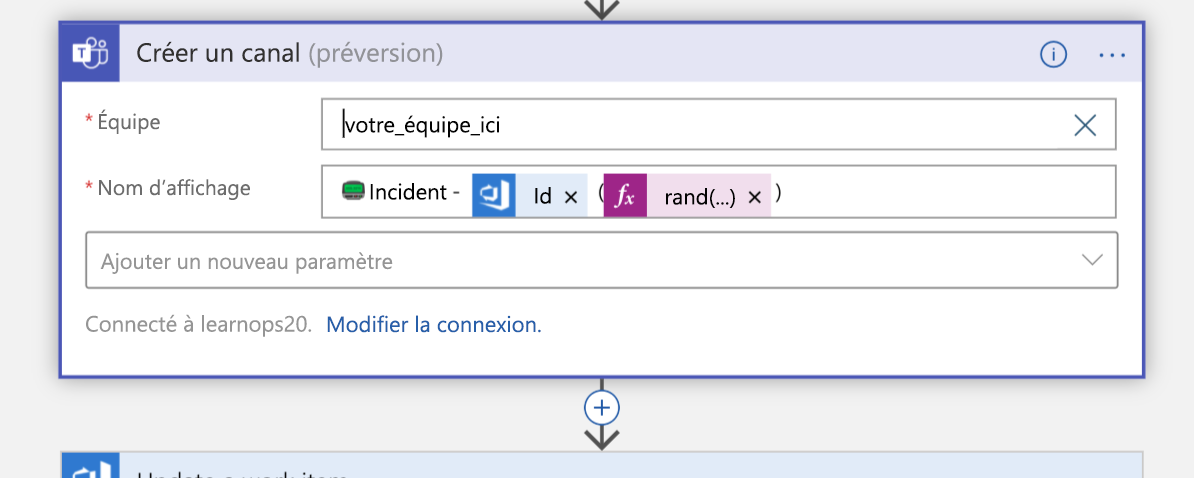
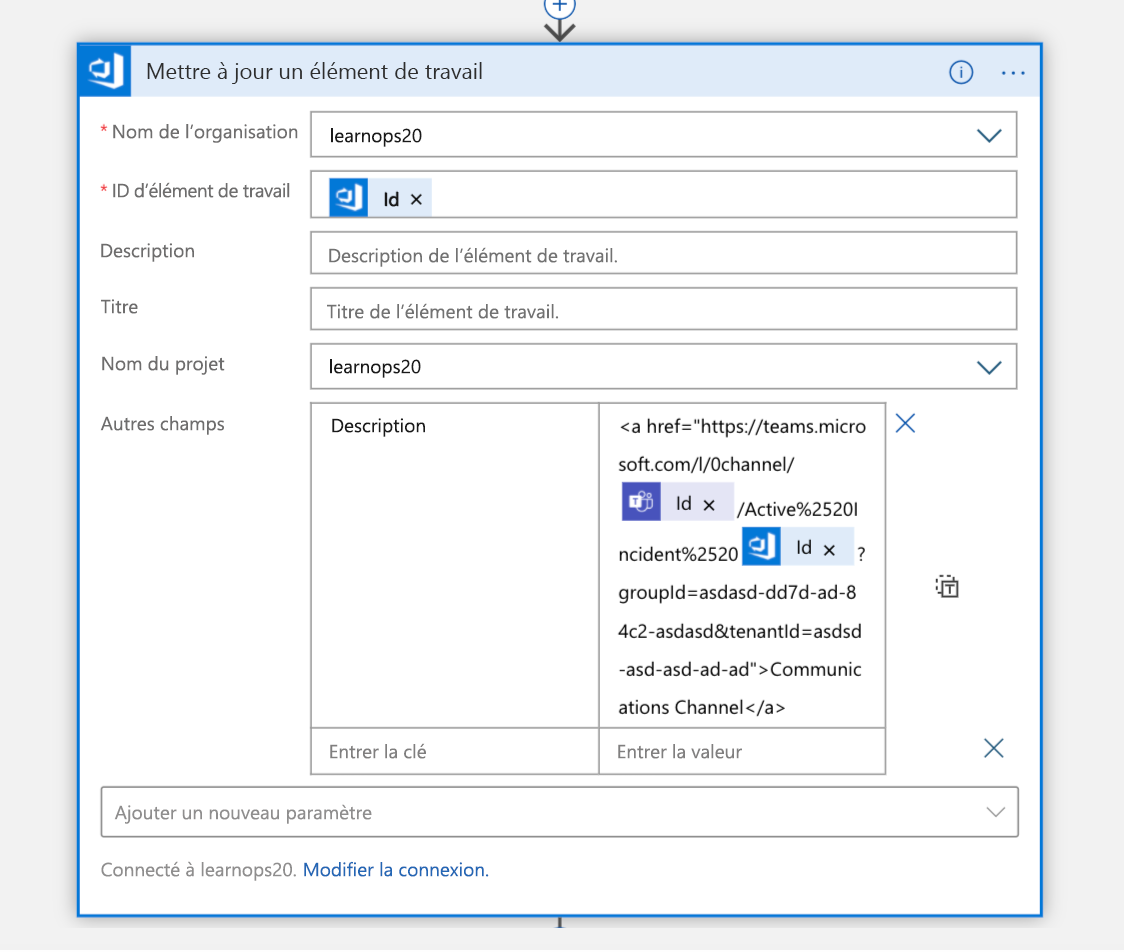
Une fois le canal créé, l’élément de travail que nous avons créé il y a un instant est mis à jour avec un lien vers le nouveau canal. Cela permet de conserver toutes les informations au même endroit (l’élément de travail) et les utilisateurs peuvent les consulter plus tard pour savoir où aller s’ils veulent rejoindre ce canal.
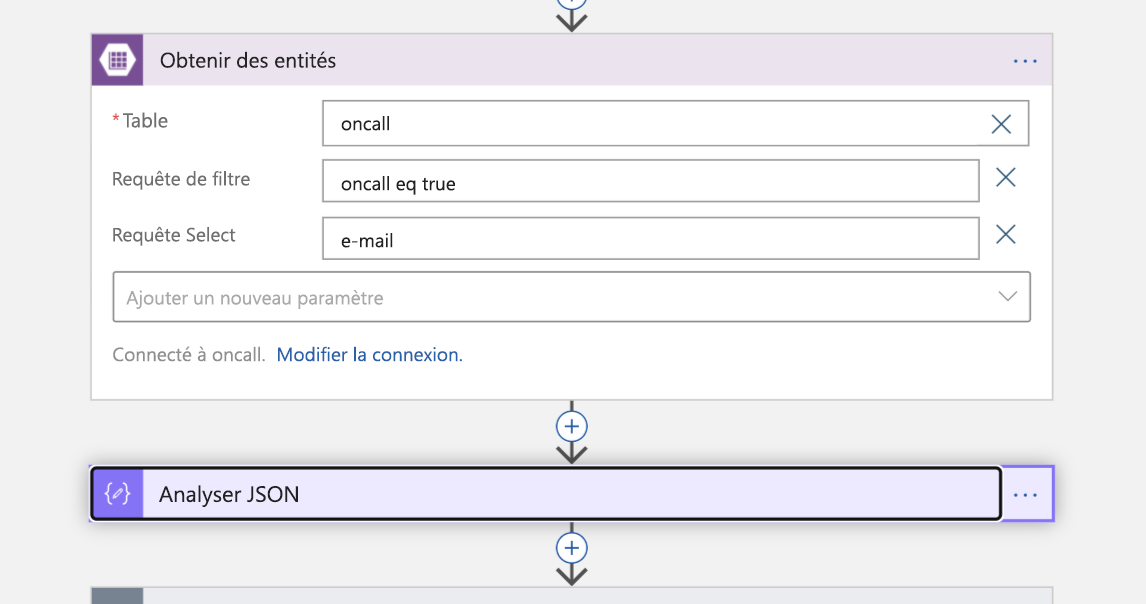
C’est lâ que la personne d’astreinte entre en scène. Nous effectuons une recherche dans Stockage Table Azure pour obtenir l’adresse e-mail de l’ingénieur listé comme étant d’astreinte. Cette action retourne une réponse JSON que nous allons analyser.
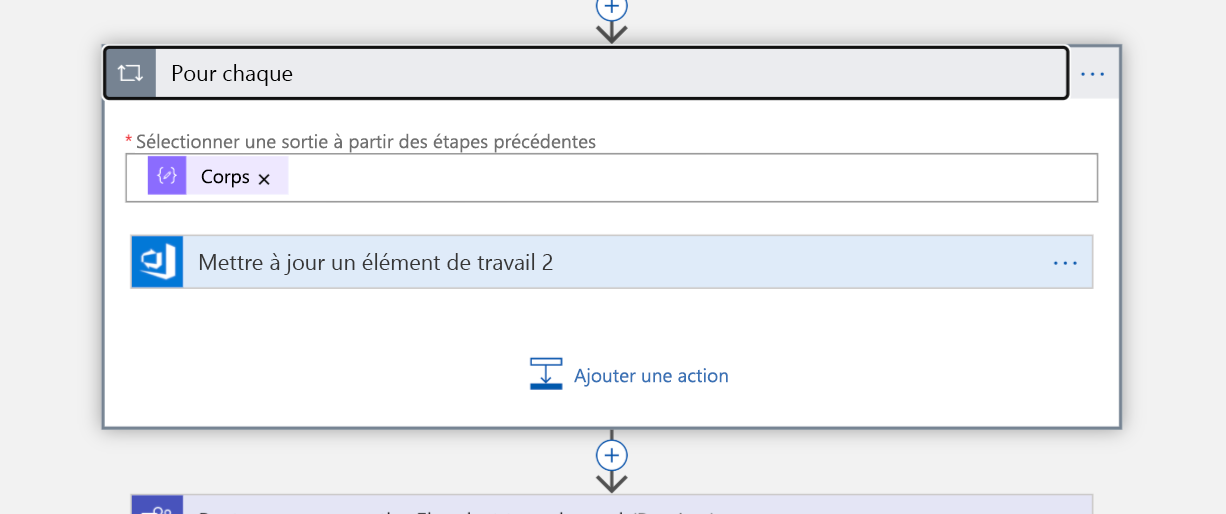
Comme notre requête va retourner une liste, nous avons besoin d’itérer sur chaque élément de cette liste à l’étape suivante. Nous attribuons l’élément de travail à chaque personne (ce sont désormais des « propriétaires » de l’incident).
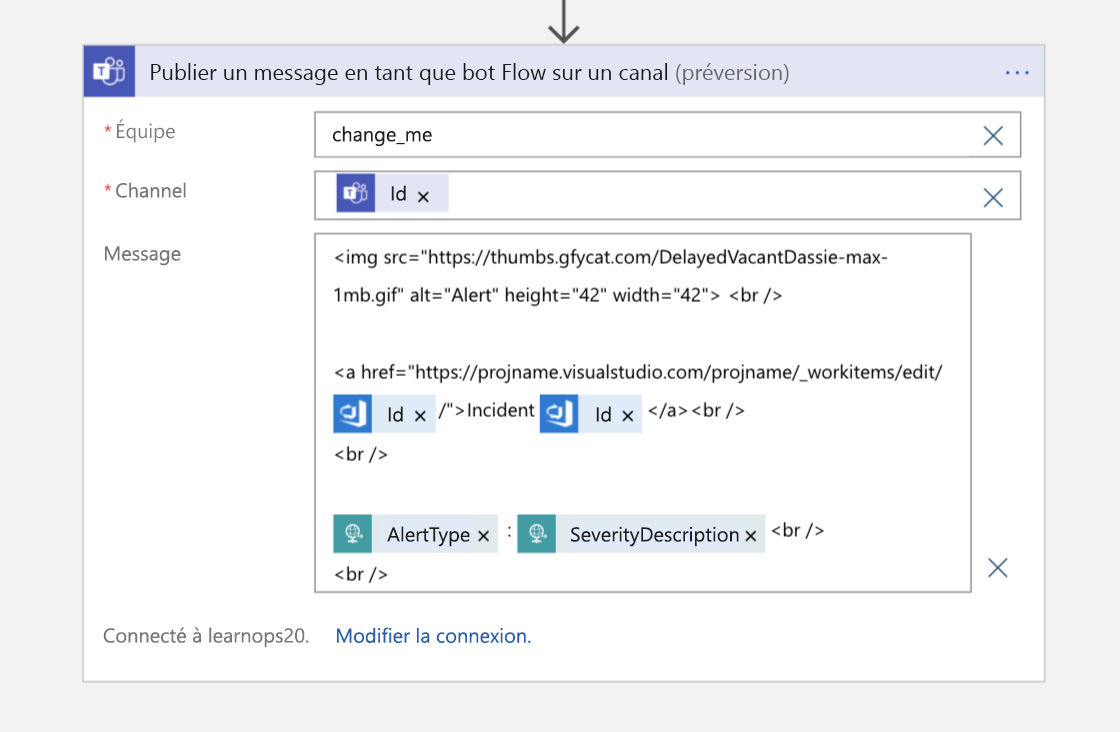
Ensuite, comme dernière étape, nous envoyons un message au canal Teams qui contient un pointeur vers l’élément de travail pour les personnes qui rejoignent le canal et veulent savoir où sont stockées les informations faisant autorité sur cet incident.
Cet exemple illustre donc la façon dont nous pouvons automatiser la configuration des mécanismes de suivi des incidents et de communication à leur sujet. Dans l’unité suivante, nous allons nous intéresser de plus près aux aspects de la communication sur un incident.