Résoudre les problèmes d’utilisation élevée du processeur dans SQL Server
S’applique à : SQL Server
Cet article fournit des procédures pour diagnostiquer et résoudre les problèmes engendrés par une utilisation élevée du processeur sur un ordinateur sous Microsoft SQL Server. Une utilisation élevée du processeur dans SQL Server peut être due à de nombreuses raisons, en particulier celles-ci :
- Lectures logiques intensives qui sont causées par des analyses de table ou d’index en raison des conditions suivantes :
- Statistiques obsolètes
- Index manquants
- Problèmes de plan sensible aux paramètres (PSP)
- Requêtes mal conçues
- Augmentation de la charge de travail
Effectuez la procédure suivante pour résoudre les problèmes d’utilisation élevée du processeur dans SQL Server.
Étape 1 : vérifier que SQL Server est à l’origine de l’utilisation élevée du processeur
Utilisez l’un des outils suivants pour vérifier si le processus SQL Server entraîne bien une utilisation élevée du processeur :
Gestionnaire des tâches : sous l’onglet Processus, vérifiez si la valeur de la colonne Processeur en regard de SQL Server Windows NT-64 Bit est proche de 100 %.
Moniteur de ressource et de performance (perfmon)
- Compteur :
Process/%User Time,% Privileged Time - Instance : sqlservr
- Compteur :
Vous pouvez utiliser le script PowerShell suivant pour collecter les données de compteur sur une période de 60 secondes :
$serverName = $env:COMPUTERNAME $Counters = @( ("\\$serverName" + "\Process(sqlservr*)\% User Time"), ("\\$serverName" + "\Process(sqlservr*)\% Privileged Time") ) Get-Counter -Counter $Counters -MaxSamples 30 | ForEach { $_.CounterSamples | ForEach { [pscustomobject]@{ TimeStamp = $_.TimeStamp Path = $_.Path Value = ([Math]::Round($_.CookedValue, 3)) } Start-Sleep -s 2 } }
Si % User Time est systématiquement supérieur à 90 % (% de temps utilisateur est la somme du temps processeur sur chaque processeur, sa valeur maximale est de 100 % * (aucun processeur)), le processus SQL Server entraîne une utilisation élevée du processeur. En revanche, s’il s’agit de la valeur % Privileged time qui dépasse constamment 90 %, l’utilisation élevée du processeur est due à votre logiciel antivirus, à d’autres pilotes ou à un autre composant du système d’exploitation de l’ordinateur. Vous devez travailler de pair avec votre administrateur système pour analyser la cause première de ce comportement.
Étape 2 : identifier les requêtes gourmandes en ressources du processeur
Si le processus Sqlservr.exe entraîne une utilisation élevée du processeur, dans l’écrasante majorité des cas, le coupable est tout désigné : il s’agit des requêtes SQL Server qui effectuent des analyses de tables ou d’index, suivies par des opérations de tri, de hachage et des boucles (opérateur de boucle imbriquée ou WHILE [T-SQL]). Pour avoir une idée des ressources de l’UC sollicitées par les requêtes actuellement, par rapport à la capacité totale de celui-ci, exécutez l’instruction suivante :
DECLARE @init_sum_cpu_time int,
@utilizedCpuCount int
--get CPU count used by SQL Server
SELECT @utilizedCpuCount = COUNT( * )
FROM sys.dm_os_schedulers
WHERE status = 'VISIBLE ONLINE'
--calculate the CPU usage by queries OVER a 5 sec interval
SELECT @init_sum_cpu_time = SUM(cpu_time) FROM sys.dm_exec_requests
WAITFOR DELAY '00:00:05'
SELECT CONVERT(DECIMAL(5,2), ((SUM(cpu_time) - @init_sum_cpu_time) / (@utilizedCpuCount * 5000.00)) * 100) AS [CPU from Queries as Percent of Total CPU Capacity]
FROM sys.dm_exec_requests
Pour identifier les requêtes qui sollicitent fortement l’UC, exécutez l’instruction suivante :
SELECT TOP 10 s.session_id,
r.status,
r.cpu_time,
r.logical_reads,
r.reads,
r.writes,
r.total_elapsed_time / (1000 * 60) 'Elaps M',
SUBSTRING(st.TEXT, (r.statement_start_offset / 2) + 1,
((CASE r.statement_end_offset
WHEN -1 THEN DATALENGTH(st.TEXT)
ELSE r.statement_end_offset
END - r.statement_start_offset) / 2) + 1) AS statement_text,
COALESCE(QUOTENAME(DB_NAME(st.dbid)) + N'.' + QUOTENAME(OBJECT_SCHEMA_NAME(st.objectid, st.dbid))
+ N'.' + QUOTENAME(OBJECT_NAME(st.objectid, st.dbid)), '') AS command_text,
r.command,
s.login_name,
s.host_name,
s.program_name,
s.last_request_end_time,
s.login_time,
r.open_transaction_count
FROM sys.dm_exec_sessions AS s
JOIN sys.dm_exec_requests AS r ON r.session_id = s.session_id CROSS APPLY sys.Dm_exec_sql_text(r.sql_handle) AS st
WHERE r.session_id != @@SPID
ORDER BY r.cpu_time DESC
Si les requêtes ne sollicitent pas l’UC pour l’instant, vous pouvez exécuter l’instruction suivante pour identifier les requêtes d’historique utilisant le processeur de manière intensive :
SELECT TOP 10 qs.last_execution_time, st.text AS batch_text,
SUBSTRING(st.TEXT, (qs.statement_start_offset / 2) + 1, ((CASE qs.statement_end_offset WHEN - 1 THEN DATALENGTH(st.TEXT) ELSE qs.statement_end_offset END - qs.statement_start_offset) / 2) + 1) AS statement_text,
(qs.total_worker_time / 1000) / qs.execution_count AS avg_cpu_time_ms,
(qs.total_elapsed_time / 1000) / qs.execution_count AS avg_elapsed_time_ms,
qs.total_logical_reads / qs.execution_count AS avg_logical_reads,
(qs.total_worker_time / 1000) AS cumulative_cpu_time_all_executions_ms,
(qs.total_elapsed_time / 1000) AS cumulative_elapsed_time_all_executions_ms
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(sql_handle) st
ORDER BY(qs.total_worker_time / qs.execution_count) DESC
Étape 3 : mettre à jour les statistiques
Une fois que vous avez identifié les requêtes les plus intensives, mettez à jour les statistiques des tables utilisées par ces requêtes. Vous pouvez utiliser la procédure stockée système sp_updatestats pour mettre à jour les statistiques de toutes les tables internes et définies par l’utilisateur dans la base de données actuelle. Par exemple :
exec sp_updatestats
Remarque
La procédure stockée système sp_updatestats exécute UPDATE STATISTICS par rapport à toutes les tables internes et définies par l’utilisateur dans la base de données actuelle. Assurez-vous que les statistiques restent à jour via les tâches de maintenance périodiques. Utilisez des solutions telles que la Adaptive Index Defrag pour gérer automatiquement la défragmentation des index et les mises à jour des statistiques pour une ou plusieurs bases de données. Cette procédure détermine automatiquement s’il faut reconstruire ou réorganiser un index en fonction de son niveau de fragmentation, entre autres paramètres, et met à jour les statistiques avec un seuil linéaire.
Pour plus dʼinformations sur sp_updatestats, consultez l’article sp_updatestats.
Si SQL Server utilise toujours toujours le processeur de manière intensive, passez à l’étape suivante.
Étape 4 : ajouter les index manquants
Les index manquants peuvent entraîner un ralentissement de l’exécution des requêtes et une utilisation élevée du processeur. Vous pouvez identifier les index manquants puis les créer pour améliorer l’impact sur les performances.
Exécutez la requête suivante pour identifier les requêtes qui entraînent une utilisation élevée du processeur et dont au moins un index est manquant dans le plan de requête :
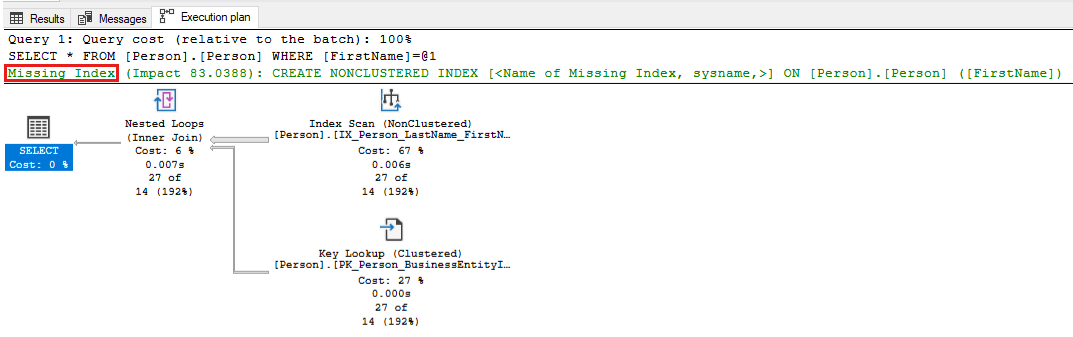
-- Captures the Total CPU time spent by a query along with the query plan and total executions SELECT qs_cpu.total_worker_time / 1000 AS total_cpu_time_ms, q.[text], p.query_plan, qs_cpu.execution_count, q.dbid, q.objectid, q.encrypted AS text_encrypted FROM (SELECT TOP 500 qs.plan_handle, qs.total_worker_time, qs.execution_count FROM sys.dm_exec_query_stats qs ORDER BY qs.total_worker_time DESC) AS qs_cpu CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q CROSS APPLY sys.dm_exec_query_plan(plan_handle) p WHERE p.query_plan.exist('declare namespace qplan = "http://schemas.microsoft.com/sqlserver/2004/07/showplan"; //qplan:MissingIndexes')=1Passez en revue les plans d’exécution des requêtes identifiées et affinez la requête en apportant les modifications requises. La capture d’écran suivante présente un exemple dans lequel SQL Server pointe un index manquant pour votre requête. Cliquez avec le bouton droit sur la partie Index manquant du plan de requête, puis sélectionnez Détails de l’index manquant pour créer l’index dans une autre fenêtre de SQL Server Management Studio.
Utilisez la requête suivante pour rechercher les index manquants et appliquer tous les index recommandés qui ont des valeurs de mesure d’amélioration élevées. Commencez par les 5 ou 10 premières recommandations de la sortie avec la valeur improvement_measure la plus élevée. Il s’agit des index dont l’effet positif sur les performances est le plus significatif. Déterminez si vous souhaitez appliquer ces index et vérifiez que des tests de performances sont effectués pour l’application. Continuez ensuite à appliquer les recommandations d’index manquants jusqu’à obtenir les résultats souhaités au niveau des performances d’application. Pour plus d’informations sur ce sujet, consultez l’article Optimiser les index non-cluster avec les suggestions d’index manquants.
SELECT CONVERT(VARCHAR(30), GETDATE(), 126) AS runtime, mig.index_group_handle, mid.index_handle, CONVERT(DECIMAL(28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) AS improvement_measure, 'CREATE INDEX missing_index_' + CONVERT(VARCHAR, mig.index_group_handle) + '_' + CONVERT(VARCHAR, mid.index_handle) + ' ON ' + mid.statement + ' (' + ISNULL(mid.equality_columns, '') + CASE WHEN mid.equality_columns IS NOT NULL AND mid.inequality_columns IS NOT NULL THEN ',' ELSE '' END + ISNULL(mid.inequality_columns, '') + ')' + ISNULL(' INCLUDE (' + mid.included_columns + ')', '') AS create_index_statement, migs.*, mid.database_id, mid.[object_id] FROM sys.dm_db_missing_index_groups mig INNER JOIN sys.dm_db_missing_index_group_stats migs ON migs.group_handle = mig.index_group_handle INNER JOIN sys.dm_db_missing_index_details mid ON mig.index_handle = mid.index_handle WHERE CONVERT (DECIMAL (28, 1), migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans)) > 10 ORDER BY migs.avg_total_user_cost * migs.avg_user_impact * (migs.user_seeks + migs.user_scans) DESC

Étape 5 : examiner et résoudre les problèmes de sensibilité aux paramètres
Vous pouvez utiliser la commande DBCC FREEPROCCACHE pour libérer le cache du plan et vérifier si cela permet de résoudre le problème d’utilisation élevée de l’UC. Si le problème est résolu, il s’agit d’un problème sensible aux paramètres (PSP, également appelé « problème de détection de paramètres »).
Remarque
L’utilisation de la commande DBCC FREEPROCCACHE sans paramètres supprime tous les plans compilés du cache du plan. Les nouvelles exécutions de requêtes devront donc être compilées à nouveau et prendront plus de temps. La meilleure approche consiste à utiliser DBCC FREEPROCCACHE ( plan_handle | sql_handle ) pour identifier la ou les requêtes à l’origine du problème. Vous pouvez ensuite tenter de les résoudre.
Pour atténuer les problèmes de sensibilité aux paramètres, procédez comme suit : Chaque méthode possède ses avantages et inconvénients.
Utilisez l’indicateur de requête RECOMPILE. Vous pouvez ajouter un indicateur de requête
RECOMPILEà une ou plusieurs des requêtes gourmandes en ressources de l’UC identifiées à l’étape 2. Cet indicateur permet d’équilibrer la légère augmentation de l’utilisation de l’UC lors de la compilation en offrant des performances optimales pour chaque exécution de requête. Pour plus d’informations, consultez les sections Paramètres et réutilisation des plans d’exécution, Sensibilité aux paramètres et Indicateur de requête RECOMPILE.Voici un exemple de la façon dont vous pouvez appliquer cet indicateur à votre requête.
SELECT * FROM Person.Person WHERE LastName = 'Wood' OPTION (RECOMPILE)Utilisez l’indicateur de requête OPTIMIZE FOR pour remplacer la valeur de paramètre réelle par une valeur de paramètre standard qui englobe la plupart des valeurs présentes dans les données. En procédant ainsi, vous devez connaître les valeurs de paramètre optimal et les caractéristiques du plan associé. Voici un exemple d’utilisation de cet indicateur dans votre requête.
DECLARE @LastName Name = 'Frintu' SELECT FirstName, LastName FROM Person.Person WHERE LastName = @LastName OPTION (OPTIMIZE FOR (@LastName = 'Wood'))Utilisez l’indicateur de requête OPTIMIZE FOR UNKNOWN pour remplacer la valeur de paramètre réelle par la moyenne du vecteur de densité. Vous pouvez également effectuer cette opération en capturant les valeurs de paramètres entrantes dans des variables locales, puis en utilisant ces variables locales dans des prédicats à la place des paramètres. Pour cette correction, la densité moyenne peut être suffisante pour fournir des performances acceptables.
Utilisez l’indicateur de requête DISABLE_PARAMETER_SNIFFING pour désactiver entièrement la détection de paramètres. Voici un exemple d’utilisation dans une requête :
SELECT * FROM Person.Address WHERE City = 'SEATTLE' AND PostalCode = 98104 OPTION (USE HINT ('DISABLE_PARAMETER_SNIFFING'))Utilisez l’indicateur de requête KEEPFIXED PLAN pour empêcher les recompilations dans le cache. Cette solution de contournement suppose que le plan courant « suffisant » est celui qui se trouve déjà dans le cache. Vous pouvez également désactiver les mises à jour de statistiques automatiques afin de réduire le risque d’éviction du plan suffisant et de compilation d’un plan insuffisant.
Utilisez la commande DBCC FREEPROCCACHE comme solution temporaire jusqu’à ce que le code de l’application soit corrigé. Vous pouvez utiliser la commande
DBCC FREEPROCCACHE (plan_handle)pour supprimer uniquement le plan à l’origine du problème. Par exemple, pour rechercher les plans de requête qui font référence au tableauPerson.Persondans AdventureWorks, vous pouvez utiliser cette requête pour rechercher le handle de la requête. Vous pouvez ensuite libérer le plan de requête spécifique du cache à l’aide de la commandeDBCC FREEPROCCACHE (plan_handle)qui est produit dans la deuxième colonne des résultats de la requête.SELECT text, 'DBCC FREEPROCCACHE (0x' + CONVERT(VARCHAR (512), plan_handle, 2) + ')' AS dbcc_freeproc_command FROM sys.dm_exec_cached_plans CROSS APPLY sys.dm_exec_query_plan(plan_handle) CROSS APPLY sys.dm_exec_sql_text(plan_handle) WHERE text LIKE '%person.person%'
Étape 6 : examiner et résoudre les problèmes liés à RRAGability
Un prédicat dans une requête est considéré comme SARGable (capable d’utiliser un argument de recherche) lorsque le moteur SQL Server peut utiliser une recherche d’index pour accélérer l’exécution de la requête. De nombreuses conceptions de requêtes empêchent les prédicats d’être SARGable, ce qui entraîne des analyses de tables ou d’index et une utilisation élevée du processeur. Considérez la requête suivante par rapport à la base de données AdventureWorks, où chaque élément ProductNumber doit être récupéré et se voir appliquer la fonction SUBSTRING(), avant d’être comparé à une valeur de littéral de chaîne. Comme vous pouvez le voir, vous devez d’abord extraire toutes les lignes de la table, puis appliquer la fonction avant de pouvoir effectuer une comparaison. L’extraction de toutes les lignes de la table consiste en une analyse de table ou d’index, ce qui entraîne une utilisation plus élevée du processeur.
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE SUBSTRING(ProductNumber, 0, 4) = 'HN-'
L’application d’une fonction ou d’un calcul sur la ou les colonnes dans le prédicat de recherche rend généralement la requête non SARGable et entraîne une consommation plus élevée du processeur. Pour résoudre ce problème, il faut généralement réécrire les requêtes de manière créative afin de les rendre SARGable. La réécriture suivante permet de résoudre cet exemple : la fonction est supprimée du prédicat de la requête, une autre colonne est recherchée et les mêmes résultats sont obtenus :
SELECT ProductID, Name, ProductNumber
FROM [Production].[Product]
WHERE Name LIKE 'Hex%'
Voici un autre exemple, où un responsable commercial décide d’octroyer une commission de 10 % sur les commandes importantes. Il veut également savoir quelles commandes auront une commission supérieure à 300 $. Pour ce faire, voici la méthode logique, mais non SARGable.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice * 0.10 > 300
Voici une réécriture possible de la requête, moins intuitive mais SARGable, dans laquelle le calcul est déplacé de l’autre côté du prédicat.
SELECT DISTINCT SalesOrderID, UnitPrice, UnitPrice * 0.10 [10% Commission]
FROM [Sales].[SalesOrderDetail]
WHERE UnitPrice > 300/0.10
La capacité d’utiliser un argument de recherche s’applique non seulement aux clauses WHERE, mais aussi aux clauses JOINs, HAVING, GROUP BY et ORDER BY. Souvent, les requêtes ne sont pas SARGable à cause des fonctions CONVERT(), CAST(), ISNULL(), COALESCE() utilisées dans les clauses WHERE ou JOIN qui conduisent à l’analyse des colonnes. Dans les cas de conversion de type de données (CONVERT ou CAST), la solution peut consister à vérifier que vous comparez les mêmes types de données. Voici un exemple où la colonne T1.ProdID est explicitement convertie en type de données INT dans une clause JOIN. La conversion rend inutile l’utilisation d’un index sur la colonne de jointure. Le même problème se produit lors de la conversion implicite, où les types de données sont différents et où SQL Server convertit l’un d’entre eux pour effectuer la jointure.
SELECT T1.ProdID, T1.ProdDesc
FROM T1 JOIN T2
ON CONVERT(int, T1.ProdID) = T2.ProductID
WHERE t2.ProductID BETWEEN 200 AND 300
Pour éviter une analyse de la table T1, vous pouvez modifier le type de données sous-jacent de la colonne ProdID après une planification et une conception appropriées, puis joindre les deux colonnes sans utiliser la fonction CONVERT ON T1.ProdID = T2.ProductID.
Une autre solution consiste à créer une colonne calculée dans T1 qui utilise la même fonction CONVERT(), puis à créer un index sur celle-ci. Cela permettra à l’optimiseur de requête d’utiliser cet index sans que vous ayez besoin de modifier votre requête.
ALTER TABLE dbo.T1 ADD IntProdID AS CONVERT (INT, ProdID);
CREATE INDEX IndProdID_int ON dbo.T1 (IntProdID);
Dans certains cas, les requêtes ne peuvent pas être réécrites facilement afin de les rendre SARGable. Dans ces situations, vérifiez si la colonne calculée avec un index dessus peut vous aider. Vous pouvez également garder la requête en l’état, mais sachez que cela peut entraîner une utilisation plus élevée du processeur.
Étape 7 : désactiver le traçage d’activités SQL intensives
Vérifiez si le traçage SQL Trace ou XEvent affecte les performances de SQL Server et entraîne une utilisation élevée du processeur. Par exemple, l’utilisation des événements suivants peut entraîner une utilisation élevée du processeur si vous tracez une activité SQL Server intensive :
- Événements XML de plan de requête (
query_plan_profile,query_post_compilation_showplan,query_post_execution_plan_profile,query_post_execution_showplan,query_pre_execution_showplan) - Événements au niveau des instructions (
sql_statement_completed,sql_statement_starting,sp_statement_starting,sp_statement_completed) - Événements de connexion et de déconnexion (
login,process_login_finish,login_event,logout) - Événements de verrouillage (
lock_acquired,lock_cancel,lock_released) - Événements d’attente (
wait_info,wait_info_external) - Événements d’audit SQL (en fonction du groupe audité et de l’activité SQL Server dans ce groupe)
Exécutez les requêtes suivantes pour identifier les traces XEvent ou SQL Server actives :
PRINT '--Profiler trace summary--'
SELECT traceid, property, CONVERT(VARCHAR(1024), value) AS value FROM::fn_trace_getinfo(
default)
GO
PRINT '--Trace event details--'
SELECT trace_id,
status,
CASE WHEN row_number = 1 THEN path ELSE NULL end AS path,
CASE WHEN row_number = 1 THEN max_size ELSE NULL end AS max_size,
CASE WHEN row_number = 1 THEN start_time ELSE NULL end AS start_time,
CASE WHEN row_number = 1 THEN stop_time ELSE NULL end AS stop_time,
max_files,
is_rowset,
is_rollover,
is_shutdown,
is_default,
buffer_count,
buffer_size,
last_event_time,
event_count,
trace_event_id,
trace_event_name,
trace_column_id,
trace_column_name,
expensive_event
FROM
(SELECT t.id AS trace_id,
row_number() over(PARTITION BY t.id order by te.trace_event_id, tc.trace_column_id) AS row_number,
t.status,
t.path,
t.max_size,
t.start_time,
t.stop_time,
t.max_files,
t.is_rowset,
t.is_rollover,
t.is_shutdown,
t.is_default,
t.buffer_count,
t.buffer_size,
t.last_event_time,
t.event_count,
te.trace_event_id,
te.name AS trace_event_name,
tc.trace_column_id,
tc.name AS trace_column_name,
CASE WHEN te.trace_event_id in (23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180) THEN CAST(1 as bit) ELSE CAST(0 AS BIT) END AS expensive_event FROM sys.traces t CROSS APPLY::fn_trace_geteventinfo(t.id) AS e JOIN sys.trace_events te ON te.trace_event_id = e.eventid JOIN sys.trace_columns tc ON e.columnid = trace_column_id) AS x
GO
PRINT '--XEvent Session Details--'
SELECT sess.NAME 'session_name', event_name, xe_event_name, trace_event_id,
CASE WHEN xemap.trace_event_id IN(23, 24, 40, 41, 44, 45, 51, 52, 54, 68, 96, 97, 98, 113, 114, 122, 146, 180)
THEN Cast(1 AS BIT)
ELSE Cast(0 AS BIT)
END AS expensive_event
FROM sys.dm_xe_sessions sess
JOIN sys.dm_xe_session_events evt
ON sess.address = evt.event_session_address
INNER JOIN sys.trace_xe_event_map xemap
ON evt.event_name = xemap.xe_event_name
GO
Étape 8 : Corriger l’utilisation élevée du processeur causée par une contention de verrouillage tournant
Pour résoudre les problèmes courants d’utilisation élevée du processeur causée par une contention de verrouillage tournant, consultez les sections suivantes.
SOS_CACHESTORE contention de verrouillage tournant
Si votre SQL Server instance rencontre une contention importante SOS_CACHESTORE de verrouillage tournant ou si vous remarquez que vos plans de requête sont souvent supprimés sur des charges de travail de requête non planifiées, consultez l’article suivant et activez l’indicateur T174 de trace à l’aide de la DBCC TRACEON (174, -1) commande :
Si la condition d’utilisation élevée du processeur est résolue à l’aide de T174, utilisez le Gestionnaire de configuration SQL Server pour l’activer en tant que paramètre de démarrage.
Utilisation élevée aléatoire du processeur en raison de SOS_BLOCKALLOCPARTIALLIST contention de verrouillage tournant sur des machines à mémoire volumineuse
Si votre SQL Server instance rencontre une utilisation élevée aléatoire du processeur en raison d’une SOS_BLOCKALLOCPARTIALLIST contention de verrouillage tournant, nous vous recommandons d’appliquer la mise à jour cumulative 21 pour SQL Server 2019. Pour plus d’informations sur la résolution du problème, consultez la référence de bogue 2410400 et DBCC DROPCLEANBUFFERS qui fournit une atténuation temporaire.
Utilisation élevée du processeur en raison d’une contention de verrouillage tournant sur XVB_list sur des machines haut de gamme
Si votre SQL Server instance rencontre un scénario de processeur élevé provoqué par une contention de verrouillage tournant sur les XVB_LIST machines à configuration élevée (systèmes haut de gamme avec un grand nombre de processeurs de nouvelle génération), activez l’indicateur de trace TF8102 avec TF8101.
Remarque
Une utilisation élevée du processeur peut résulter d’une contention de verrouillage tournant sur de nombreux autres types de verrouillage tournant. Pour plus d’informations sur les verrouillages tournants, consultez Diagnostiquer et résoudre la contention de verrouillage tournant sur SQL Server.
Étape 9 : Configurer votre machine virtuelle
Si vous utilisez une machine virtuelle, veillez à ne pas surapprovisionner les processeurs et à ce qu’ils soient correctement configurés. Pour plus d’informations, consultez l’article Résolution des problèmes de performances des machines virtuelles ESX/ESXi (2001003).
Étape 10 : Augmenter l’échelle du système pour utiliser plus de processeurs
Si les instances de requête individuelles utilisent un faible pourcentage des capacités du processeur, mais que la charge de travail globale de toutes les requêtes réunies entraîne une consommation élevée de ce dernier, envisagez d’augmenter l’échelle de votre ordinateur en ajoutant d’autres processeurs. À l’aide de la requête suivante, recherchez le nombre de requêtes ayant dépassé un certain seuil au niveau de la consommation moyenne et maximale du processeur par exécution et ayant été exécutées plusieurs fois sur le système (veillez à modifier les valeurs des deux variables pour qu’elles correspondent à votre environnement) :
-- Shows queries where Max and average CPU time exceeds 200 ms and executed more than 1000 times
DECLARE @cputime_threshold_microsec INT = 200*1000
DECLARE @execution_count INT = 1000
SELECT qs.total_worker_time/1000 total_cpu_time_ms,
qs.max_worker_time/1000 max_cpu_time_ms,
(qs.total_worker_time/1000)/execution_count average_cpu_time_ms,
qs.execution_count,
q.[text]
FROM sys.dm_exec_query_stats qs CROSS APPLY sys.dm_exec_sql_text(plan_handle) AS q
WHERE (qs.total_worker_time/execution_count > @cputime_threshold_microsec
OR qs.max_worker_time > @cputime_threshold_microsec )
AND execution_count > @execution_count
ORDER BY qs.total_worker_time DESC
Voir aussi
- Une utilisation du processeur ou des allocations de mémoire élevées peuvent survenir avec des requêtes qui utilisent une boucle imbriquée optimisée ou un tri par lots
- Mises à jour et options de configuration recommandées pour SQL Server avec des charges de travail hautes performances
- Mises à jour et options de configuration recommandées pour SQL Server 2017 et 2016 avec des charges de travail hautes performances
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour