Vue d’ensemble de l’analyse de l'
Les API InkAnalysis fournissent aux développeurs tablet PC des outils puissants pour examiner par programmation les entrées manuscrites. L’API classifie l’entrée manuscrite en catégories significatives telles que les mots, les lignes, les paragraphes et les dessins.
Vous pouvez utiliser chaque classification de différentes façons, notamment en améliorant les résultats de reconnaissance pour l’écriture manuscrite.
Principes de base de l’analyse de l’entrée manuscrite
Cette section présente la technologie d’analyse de l’encre de la plateforme Tablet PC et explique quand et comment l’utiliser.
Les API InkAnalysis combinent efficacement deux technologies distinctes mais complémentaires : la reconnaissance de l’écriture manuscrite et la classification de la disposition. La combinaison de ces deux technologies donne des résultats définitivement supérieurs aux parties prises seules.
La reconnaissance de l’écriture manuscrite est l’analyse informatique de l’encre numérique manuscrite pour renvoyer l’interprétation basée sur les caractères dans une langue donnée. Autrement dit, la reconnaissance de l’écriture manuscrite est la façon dont l’ordinateur « lit » l’écriture manuscrite d’une personne.
L’analyse de l’entrée manuscrite peut être décomposée en classification d’encre et en analyse de la disposition. La classification d’encre est la division numérique de l’encre en unités sémantiquement significatives, telles que les paragraphes, les lignes, les mots et les dessins. L’analyse de la disposition est l’examen informatique de l’entrée manuscrite pour déterminer la position de l’entrée manuscrite sur la surface d’entrée manuscrite et la façon dont les traits sont liés spatialement et même sémantiquement. Par exemple, l’analyse de la disposition peut vous indiquer qu’un élément d’encre particulier est une annotation ou un appel.
Reconnaissance
L’amélioration des résultats de la reconnaissance est un exemple de la façon dont la combinaison de la reconnaissance avec l’analyse de l’entrée manuscrite dans l’API InkAnalysis aide le développeur. Les moteurs de reconnaissance de l’écriture manuscrite Tablet PC ont été principalement conçus pour reconnaître une seule ligne d’entrée manuscrite horizontale. Toutefois, les utilisateurs ont tendance à écrire plusieurs lignes lors de la prise de notes, et ces lignes ne sont pas garanties d’être horizontales par rapport à la page. Avec l’API InkAnalysis, l’encre est prétraitée par l’analyseur d’encre avant d’être envoyée au module de reconnaissance. L’encre analysée est transformée en horizontale avant d’être reconnue, ce qui améliore les résultats de la reconnaissance.
D’autres avantages de la reconnaissance sont dérivés du fait que l’analyseur d’encre corrige les informations d’ordre de trait incorrectes avant d’envoyer l’entrée manuscrite au module de reconnaissance. En outre, les résultats de la reconnaissance sont désormais disponibles de manière sélective. Autrement dit, le développeur peut récupérer rapidement les résultats de la reconnaissance d’un mot, d’une seule ligne ou d’un seul paragraphe dans un appel.
Classification des entrées manuscrites
Il existe, bien sûr, différents scénarios dans lesquels vous pouvez conserver les données manuscrites intactes, au lieu de les convertir immédiatement en texte. L’analyse de l’entrée manuscrite offre également des avantages. Plus précisément, les API InkAnalysis permettent de fractionner les traits d’encre selon qu’ils sont en écriture ou en dessin. Les traits d’encre classés comme écriture sont ceux qui composent un mot ou des caractères. Tous les autres traits sont des dessins. Cela vous offre une nouvelle façon d’accéder aux données manuscrites, ce qui permet de nouveaux scénarios utilisateur. Pour instance, vous pouvez implémenter la sélection afin qu’elle soit différente en fonction du type de trait sur lequel l’utilisateur appuie. Si un utilisateur appuie sur un trait d’écriture, l’application sélectionne l’ensemble des traits qui composent le mot, si l’utilisateur appuie sur une touche de dessin, l’application sélectionne uniquement ce trait.
Analyse de la disposition
L’analyse de disposition utile va en fait bien au-delà de la répartition relativement simple de l’entrée manuscrite en composants d’écriture et de dessin.
L’analyse de l’encre inclut également une répartition plus riche des traits d’écriture et de dessin. À titre d’exemple très simple, prenez un objet blob d’entrée manuscrite, comme illustré dans l’illustration suivante.

Une fois que la plateforme a analysé ces traits, elle retourne une arborescence de ces traits, comme illustré dans l’illustration suivante. Dans ce cas simple, l’arborescence contient uniquement des informations sur les paragraphes, les lignes et les mots, mais la richesse de cette arborescence augmente à mesure que la complexité du document manuscrit augmente.
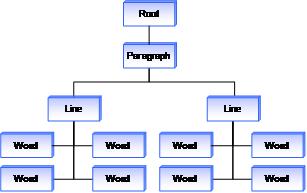
Étant donné que ces informations sont désormais séparées en unités gérables, vous pouvez désormais créer des fonctionnalités plus puissantes. Par exemple, l’application peut étendre la fonctionnalité dans laquelle l’utilisateur appuie pour sélectionner un mot dans une fonctionnalité dans laquelle l’utilisateur appuie une fois pour sélectionner le mot, appuie deux fois pour sélectionner la ligne entière et appuie trois fois pour sélectionner l’intégralité du paragraphe. En tirant parti de l’arborescence retournée par l’opération d’analyse, l’application peut lier la zone exploitée à un trait dans l’arborescence. Une fois que l’application a trouvé un trait, elle peut remonter l’arborescence pour déterminer comment et quels traits voisins sélectionner.
La sélection d’une ligne entière est un exemple simpliste des avantages de l’analyse de l’encre, mais les possibilités deviennent grandes lorsque l’on considère les différents types de structures hiérarchiques que l’analyseur d’encre est capable de détecter :
- Listes triées et non ordonnées
- Formes
- Commentaires annotatifs écrits en ligne avec le texte
Les types de fonctionnalités varient d’une application à l’autre et sont basés sur les exigences et les moteurs d’analyse d’entrée manuscrite et de reconnaissance disponibles.
Principales fonctionnalités d’analyse d’entrée manuscrite
Les fonctionnalités clés de l’API InkAnalysis incluent les fonctionnalités suivantes :
- Analyse incrémentielle
- Persistance
- Proxy de données
- Rapprochement
- Extensibilité
Analyse incrémentielle
Lorsque les utilisateurs finaux travaillent avec des entrées manuscrites, ils la traitent généralement comme une écriture manuscrite. L’entrée manuscrite est continuellement soumise à des opérations d’édition telles que l’ajout de nouvelles entrées manuscrites, la suppression de l’encre existante et la modification des propriétés d’encre, le tout de la même façon que l’écriture manuscrite est continuellement modifiée. Ces opérations de modification affectent les résultats de l’analyse. Lorsque des modifications se produisent, elles peuvent généralement être isolées dans des sections du document à des moments spécifiques. Par exemple, supposons qu’un utilisateur écrit cinq lignes d’encre. La façon standard pour les applications d’analyser l’entrée manuscrite consiste à attendre que l’utilisateur ait fini d’écrire les cinq lignes d’encre (un paragraphe, pour instance), puis d’analyser les résultats de manière synchrone ou asynchrone.
Vous pouvez optimiser le temps total consacré à l’analyse de ces cinq lignes en isolant les zones analysées au fur et à mesure de leur écriture, puis en réanalysant uniquement les parties des résultats qui ont changé. Une fois la première ligne analysée, elle ne sera plus jamais reconnue, sauf si elle est modifiée par l’utilisateur final. La reconnaissance de la deuxième ligne est traitée comme une opération de reconnaissance indépendante.
Cette approche incrémentielle fonctionne bien au niveau de la ligne pour les opérations de reconnaissance, mais elle doit fonctionner à un niveau supérieur pour l’opération d’analyse d’entrée manuscrite. Étant donné que l’analyseur d’encre peut détecter différentes classifications de niveau supérieur pour ces cinq lignes d’encre (par exemple, il peut s’agir d’un paragraphe standard ou de cinq éléments dans une liste), l’approche incrémentielle de l’analyseur d’encre est qu’il doit analyser ces structures supérieures. Autrement dit, une fois que l’analyseur d’encre a classifié la première ligne d’encre en tant que ligne, il vérifie qu’il s’agit toujours d’une ligne lorsqu’il classifie la deuxième ligne. Toutefois, l’analyseur d’encre isole cette vérification double dans le paragraphe et ignore le premier paragraphe lors de l’analyse d’un deuxième paragraphe, en traitant le deuxième paragraphe comme une opération d’analyseur d’encre indépendante. Cette approche incrémentielle de l’analyse permet de réduire considérablement le temps de traitement lorsque de grandes quantités d’encre existent déjà dans l’application.
Persistance
L’analyse incrémentielle fonctionne bien dans une session donnée ou instance d’un objet InkAnalyzer. Toutefois, les API de plateforme Tablet PC de première génération ne peuvent pas effectuer d’analyse incrémentielle une fois l’entrée manuscrite persistante sur le disque. L’API InkAnalysis permet d’enregistrer l’entrée manuscrite sur le disque, ainsi qu’une forme persistante des résultats d’analyse. Les résultats de l’analyse peuvent être chargés lorsque l’encre est chargée et peuvent être injectés dans une nouvelle instance d’un InkAnalyzer. Une nouvelle instance de l’objet InkAnalyzer a ensuite le même état de résultats qu’auparavant et peut maintenant accepter toutes les modifications comme des modifications incrémentielles apportées à l’état existant, au lieu de tout analyser à nouveau.
Proxy de données
De nombreuses applications ont déjà une sorte de structure de document existante dans leurs applications ; pour instance, un graphique ou une base de données. InkAnalyzer présente également les résultats sous une forme structurée, dans une arborescence d’objets ContextNode. La structure InkAnalyzer et la structure existante de l’application doivent interagir dans deux directions : les résultats sont extraits de l’inkAnalyzer dans l’application et l’état est poussé de l’application vers InkAnalyzer.
Si l’extraction des résultats d’InkAnalyzer dans la structure de l’application suffisait, cela serait relativement simple. Les applications effectuent une itération au sein de l’arborescence des résultats et copient (intègrent) tous les éléments des résultats dont elles ont besoin dans leur structure de données existante. Toutefois, étant donné que de nombreuses applications horizontales nécessitent une analyse incrémentielle et une persistance sur le disque, le problème devient bidirectionnel. L’état (résultats passés) doit être extrait de la structure de l’application et poussé dans InkAnalyzer.
Pour répondre à cette exigence, InkAnalyzer contient une série d’événements qu’il déclenche au moment approprié lors d’une opération d’analyse pour permettre aux applications de renvoyer par proxy la demande de données à leurs structures existantes. Ces événements sont déclenchés uniquement pour les objets ContextNode requis par l’opération incrémentielle.
Rapprochement
La plupart des applications souhaitent analyser l’entrée manuscrite en arrière-plan pour limiter au minimum les interruptions de l’interface utilisateur. Toutefois, l’analyse de l’entrée manuscrite en arrière-plan entraîne des problèmes si l’utilisateur modifie l’entrée manuscrite (ou l’entrée manuscrite voisine) en cours d’analyse. Par exemple, si l’utilisateur supprime l’entrée manuscrite pendant l’opération en arrière-plan, la structure résultante reflète l’état du document au démarrage de l’opération en arrière-plan, plutôt qu’au moment où elle a été terminée.
Pour aider les applications, InkAnalyzer rapproche les différences d’état du document entre le début et la fin de l’opération d’analyse. Les modifications apportées par l’utilisateur ou l’application pendant l’exécution de l’analyse en arrière-plan remplacent toujours les résultats calculés en arrière-plan. Après le rapprochement, seules les parties de la structure des résultats qui n’entrent pas en conflit avec les modifications de document sont signalées, et les traits en conflit sont marqués pour une analyse ultérieure. La prochaine fois que l’opération d’analyse en arrière-plan est exécutée, les résultats sont recalculés en fonction du nouvel état.
Le schéma qui suit présente ce processus. Le temps est exprimé linéairement de haut en bas dans le diagramme.
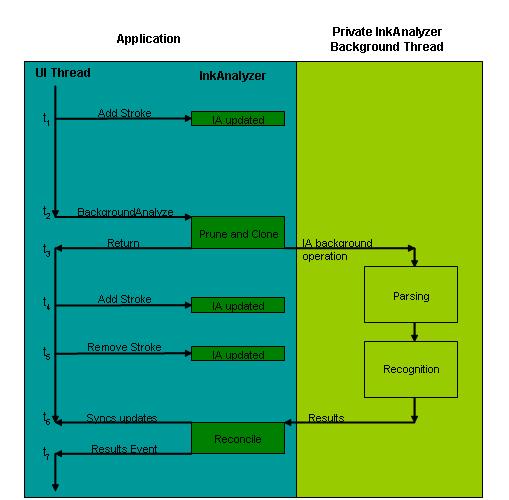
- À l’heure 1 (t1), l’application collecte l’entrée manuscrite de l’utilisateur final, y compris tout type de modification d’entrée manuscrite, telle que l’ajout, la suppression ou la modification.
- À t2, l’application appelle l’opération d’analyse en arrière-plan. InkAnalyzer détermine quelle entrée manuscrite n’a pas de résultats et quelle entrée manuscrite doit être doublement vérifiée. Il copie les données manuscrites nécessaires pour permettre au thread d’arrière-plan de s’exécuter indépendamment.
- À t3, InkAnalyzer retourne l’exécution du thread d’interface utilisateur à l’application. InkAnalyzer crée un deuxième thread, le thread d’analyse d’arrière-plan, et les moteurs d’analyse d’encre et de reconnaissance analysent les données manuscrites copiées.
- Pendant que l’opération d’analyse se produit sur le deuxième thread d’arrière-plan, l’utilisateur final continue à modifier le document, en ajoutant et en supprimant des données de trait, à t4 et t5. Ces modifications peuvent entrer en conflit avec le travail en cours de traitement en arrière-plan.
- À t6, le thread d’arrière-plan a terminé l’opération d’analyse et les résultats sont prêts. Avant de communiquer les résultats à l’application, InkAnalyzer exécute un algorithme de rapprochement pour déterminer si les modifications apportées par l’utilisateur pendant le calcul de l’opération d’analyse (t4 et t5) sont en conflit avec les résultats. Si des collisions sont détectées, les traits en collision sont marqués pour une nouvelle analyse, qui se produit la prochaine fois que l’application appelle l’opération d’analyse en arrière-plan.
- Enfin, à t7, avec toutes les collisions détectées, inkAnalyzer présente les résultats à l’application.
Extensibilité
Les API InkAnalysis permettent aux applications d’utiliser de nouveaux types de moteurs d’analyse, afin d’éviter que l’application n’ait à réécrire tous les avantages de l’API InkAnalysis, notamment le rapprochement, le proxy de données, la persistance et l’analyse incrémentielle.
Rubriques connexes
Commentaires
Bientôt disponible : Tout au long de 2024, nous allons supprimer progressivement GitHub Issues comme mécanisme de commentaires pour le contenu et le remplacer par un nouveau système de commentaires. Pour plus d’informations, consultez https://aka.ms/ContentUserFeedback.
Envoyer et afficher des commentaires pour