Virtuális gépek monitorozása az Azure Monitorral: Riasztások
Ez a cikk a virtuális gépek és számítási feladataik monitorozása az Azure Monitorban című útmutató része. Az Azure Monitor riasztásai proaktív módon értesítik Önt a figyelési adatok érdekes adatairól és mintáiról. A virtuális gépekre nincsenek előre konfigurált riasztási szabályok, de az Azure Monitor Agentből gyűjtött adatok alapján létrehozhatja a sajátját. Ez a cikk a virtuális gépekre vonatkozó riasztási fogalmakat és a más Azure Monitor-ügyfelek által használt gyakori riasztási szabályokat ismerteti.
Ez a forgatókönyv bemutatja, hogyan implementálhatja az Azure- és hibrid virtuálisgép-környezet teljes monitorozását:
Az első Azure-beli virtuális gép monitorozásának megkezdéséhez tekintse meg az Azure-beli virtuális gépek monitorozását ismertető témakört.
Az ajánlott riasztások gyors engedélyezéséhez lásd : Ajánlott riasztási szabályok engedélyezése Azure-beli virtuális gépeken.
Fontos
A legtöbb riasztási szabály költsége a szabály típusától, a benne lévő dimenzióktól és a futtatás gyakoriságától függ. Mielőtt riasztási szabályokat hoz létre, tekintse meg az Azure Monitor díjszabásának Riasztási szabályok szakaszát.
Adatgyűjtés
A riasztási szabályok ellenőrzik az Azure Monitorban már összegyűjtött adatokat. Mielőtt riasztási szabályt hoz létre, gondoskodnia kell arról, hogy egy adott forgatókönyv adatai legyenek összegyűjtve. Lásd: Virtuális gépek monitorozása az Azure Monitorral: Adatgyűjtés a különböző forgatókönyvek adatgyűjtésének konfigurálásához, beleértve a jelen cikkben szereplő összes riasztási szabályt.
Ajánlott riasztási szabályok
Az Azure Monitor olyan ajánlott riasztási szabályokat biztosít, amelyeket gyorsan engedélyezhet bármely Azure-beli virtuális gépen. Ezek a szabályok kiváló kiindulópontot jelentenek az alapszintű monitorozáshoz. Egyedül azonban a legtöbb vállalati implementációhoz nem biztosítanak elegendő riasztást a következő okokból:
- Az ajánlott riasztások csak az Azure-beli virtuális gépekre vonatkoznak, a hibrid gépekre nem.
- Az ajánlott riasztások csak gazdagépmetrikákat tartalmaznak, vendégmetrikákat és naplókat nem. Ezek a metrikák hasznosak a gép állapotának figyeléséhez. Ezek azonban minimális betekintést nyújtanak a gépen futó számítási feladatokba és alkalmazásokba.
- Az ajánlott riasztások olyan gépekhez vannak társítva, amelyek túlzott számú riasztási szabályt hoznak létre. Ahelyett, hogy minden gép esetében erre a módszerre támaszkodik, tekintse meg a riasztási szabályok méretezését a több gépre vonatkozó minimális számú riasztási szabály használatára vonatkozó stratégiákhoz.
Riasztástípusok
Az Azure Monitor leggyakoribb riasztási típusai a metrikariasztások és a naplókeresési riasztások. Az adott forgatókönyvhöz létrehozott riasztási szabály típusa attól függ, hogy a riasztásban szereplő adatok hol találhatók.
Előfordulhat, hogy egy adott riasztási forgatókönyv adatai a metrikákban és a naplókban is elérhetők. Ha igen, meg kell határoznia, hogy melyik szabálytípust használja. Emellett rugalmasan gyűjthet bizonyos adatokat, és hagyhatja, hogy a riasztási szabály típusának döntése döntsön az adatgyűjtési módszerről.
Metrikariasztások
A metrikariasztások gyakori felhasználási módjai:
- Riasztás, ha egy adott metrika túllép egy küszöbértéket. Ilyen például, ha egy gép processzora magasan fut.
Adatforrások metrikariasztásokhoz:
- Az Azure-beli virtuális gépek gazdagépmetrikái, amelyeket automatikusan gyűjtünk
- Az Azure Monitor Agent által a vendég operációs rendszerből gyűjtött metrikák
Naplókeresési riasztások
A naplókeresési riasztások gyakori felhasználási módjai:
- Riasztás, ha egy adott esemény vagy eseményminta található a Windows-eseménynaplóból vagy a Syslogból. Ezek a riasztási szabályok általában a lekérdezésből visszaadott táblasorokat mérik.
- Riasztás több gép numerikus adatainak kiszámítása alapján. Ezek a riasztási szabályok általában egy numerikus oszlop számítását mérik a lekérdezés eredményeiben.
A naplókeresési riasztások adatforrásai:
- A Log Analytics-munkaterületen gyűjtött összes adat
Riasztási szabályok skálázása
Mivel sok olyan virtuális gépe lehet, amely ugyanazt a monitorozást igényli, nem kell külön riasztási szabályokat létrehoznia mindegyikhez. Azt is meg szeretné győződni, hogy a szabály típusától függően különböző stratégiák vannak a kezelendő riasztási szabályok számának korlátozására. Ezen stratégiák mindegyike a riasztási szabály célerőforrásának megértésétől függ.
Metrika riasztási szabályai
A virtuális gépek több erőforrásmetrika riasztási szabályát támogatják a Több erőforrás monitorozása című cikkben leírtak szerint. Ezzel a képességgel egyetlen metrikariasztási szabályt hozhat létre, amely egy erőforráscsoportban vagy előfizetésben lévő összes virtuális gépre érvényes ugyanabban a régióban.
Kezdje az ajánlott riasztásokkal , és hozzon létre egy megfelelő szabályt mindegyikhez úgy, hogy az előfizetést vagy egy erőforráscsoportot használja célerőforrásként. Ismétlődő szabályokat kell létrehoznia minden régióhoz, ha több régióban vannak gépek.
A több metrikariasztási szabály követelményeinek azonosításakor kövesse ezt a stratégiát úgy, hogy egy előfizetést vagy erőforráscsoportot használ a célerőforrással:
- Minimalizálja a kezelni kívánt riasztási szabályok számát.
- Győződjön meg arról, hogy automatikusan alkalmazva vannak az új gépekre.
Naplókeresési riasztási szabályok
Ha egy naplókeresési riasztási szabály célerőforrását egy adott gépre állítja be, a lekérdezések a géphez társított adatokra korlátozódnak, ami egyedi riasztásokat ad hozzá. Ehhez az elrendezéshez minden géphez külön riasztási szabály szükséges.
Ha a naplókeresési riasztási szabály célerőforrását Log Analytics-munkaterületre állítja, akkor az adott munkaterület összes adatához hozzáférhet. Ezért egyetlen szabmánnyal riasztást készíthet a munkacsoport összes gépéről származó adatokról. Ezzel az elrendezéssel egyetlen riasztást hozhat létre az összes géphez. Ezután dimenziókkal külön riasztást hozhat létre az egyes gépekhez.
Előfordulhat például, hogy riasztást szeretne kapni, ha egy hibaeseményt bármely gép létrehoz a Windows eseménynaplójában. Először létre kell hoznia egy adatgyűjtési szabályt az Események és teljesítményszámlálók összegyűjtése virtuális gépekről az Azure Monitor Agent használatával című cikkben leírtak szerint, hogy ezeket az eseményeket a Event Log Analytics-munkaterület táblájába küldje. Ezután létrehoz egy riasztási szabályt, amely lekérdezi ezt a táblát úgy, hogy a munkaterületet használja célerőforrásként, és az alábbi képen látható feltételt.
A lekérdezés egy rekordot ad vissza bármely gépen megjelenő hibaüzenetekhez. Használja a Dimenziók szerinti felosztás lehetőséget, és adja meg a _ResourceId , hogy utasítsa a szabályt, hogy hozzon létre riasztást minden géphez, ha több gépet adnak vissza az eredményekben.
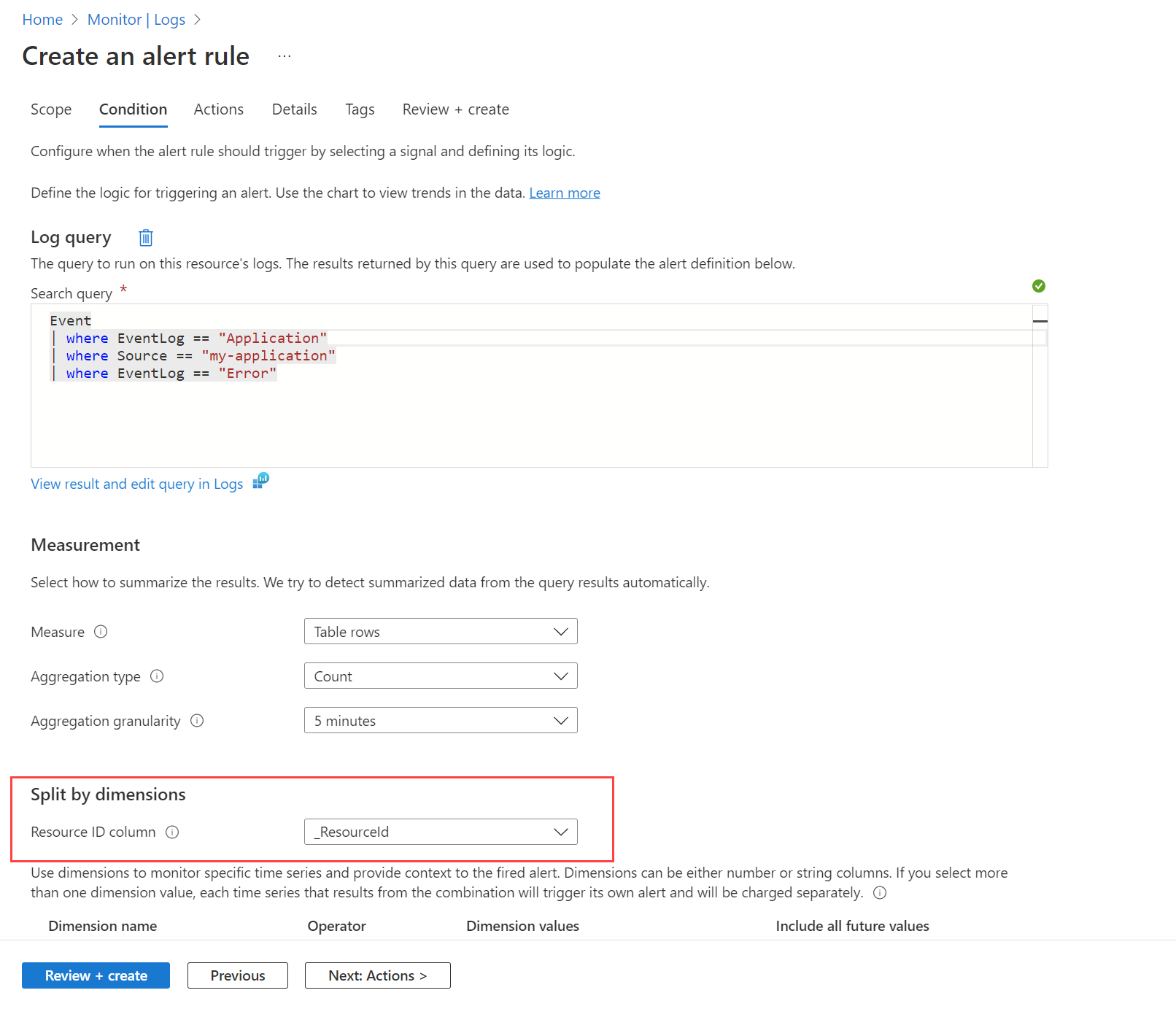
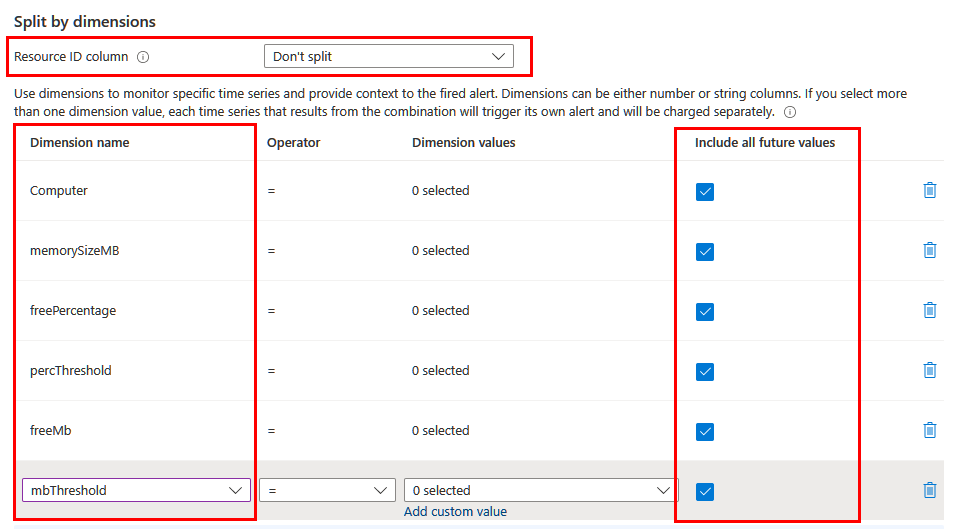
Dimenziók
A riasztásban szerepeltetni kívánt információktól függően előfordulhat, hogy különböző dimenziók használatával kell felosztania. Ebben az esetben győződjön meg arról, hogy a szükséges dimenziók a projekt vagy a kiterjesztő operátor használatával jelennek meg a lekérdezésben. Állítsa az Erőforrás-azonosító oszlop mezőjét úgy, hogy ne legyen felosztva , és vegye fel az összes fontos dimenziót a listában. Győződjön meg arról, hogy az Összes jövőbeli érték belefoglalása beállítás ki van választva, hogy a lekérdezésből visszaadott érték szerepeljen benne.
Dinamikus küszöbértékek
A naplókeresési riasztási szabályok használatának másik előnye, hogy összetett logikát is belefoglalhat a lekérdezésbe a küszöbérték meghatározásához. A küszöbértéket kódolhatja, az összes erőforrásra alkalmazhatja, vagy dinamikusan kiszámíthatja egy mező vagy számított érték alapján. A küszöbérték csak meghatározott feltételek szerint lesz alkalmazva az erőforrásokra. Létrehozhat például egy riasztást a rendelkezésre álló memória alapján, de csak bizonyos mennyiségű teljes memóriával rendelkező gépek esetén.
Gyakori riasztási szabályok
Az alábbi szakasz az Azure Monitorban lévő virtuális gépek általános riasztási szabályait sorolja fel. A metrikariasztások és a naplókeresési riasztások részletei mindegyikhez meg vannak adva. A használni kívánt riasztás típusával kapcsolatos útmutatásért tekintse meg a Riasztástípusok című témakört. Ha nem ismeri az Azure Monitorban a riasztási szabályok létrehozásának folyamatát, tekintse meg az új riasztási szabály létrehozásához szükséges utasításokat.
Feljegyzés
Az itt megadott naplókeresési riasztások részletei a virtuálisgép-Elemzések által gyűjtött adatokat használják, amely az ügyfél operációs rendszerének általános teljesítményszámlálóit biztosítja. Ez a név független az operációs rendszer típusától.
A gép nem érhető el
A virtuális gépek egyik leggyakoribb monitorozási követelménye, hogy riasztást hozzon létre, ha az nem fut. A legjobb módszer egy metrikariasztási szabály létrehozása az Azure Monitorban a virtuális gép rendelkezésre állási metrikájának használatával, amely jelenleg nyilvános előzetes verzióban érhető el. A metrikáról további információt az Azure-beli virtuális gépek rendelkezésre állási riasztási szabályának létrehozása című témakörben talál.
A skálázási riasztási szabályok szerint hozzon létre egy rendelkezésre állási riasztási szabályt úgy, hogy egy előfizetést vagy erőforráscsoportot használ célerőforrásként. A szabály több virtuális gépre vonatkozik, beleértve a riasztási szabály után létrehozott új gépeket is.
Ügynök szívverése
Az ügynök szívverése kissé eltér a gép által nem elérhető riasztástól, mivel az Azure Monitor Agentre támaszkodik a szívverés küldéséhez. Az ügynök szívverése riasztást adhat, ha a gép fut, de az ügynök nem válaszol.
Metrika riasztási szabályai
Minden Log Analytics-munkaterület tartalmaz egy Szívverés nevű metrikát. A munkaterülethez csatlakoztatott virtuális gépek percenként szívverési metrikaértéket küldenek. Mivel a számítógép a metrika dimenziója, riasztást küldhet, ha egy számítógép nem küld szívverést. Az aggregáció típusátállítsa a Darabszám és a Küszöbérték értékre a kiértékelési részletességnek megfelelő értékre.
Naplókeresési riasztási szabályok
A naplókeresési riasztások a Szívverés táblát használják, amelynek percenként szívverési rekordot kell létrehoznia az egyes gépekről.
Használjon egy szabályt a következő lekérdezéssel:
Heartbeat
| summarize TimeGenerated=max(TimeGenerated) by Computer, _ResourceId
| extend Duration = datetime_diff('minute',now(),TimeGenerated)
| summarize MinutesSinceLastHeartbeat = min(Duration) by Computer, bin(TimeGenerated,5m), _ResourceId
CPU-riasztások
Ez a szakasz a CPU-riasztásokat ismerteti.
Metrika riasztási szabályai
| Cél | Metrika |
|---|---|
| Gazdagép | Százalékos processzorhasználat (az ajánlott riasztásokban szerepel) |
| Windows-vendég | \Processzoradatok(_Total)% processzoridő |
| Linux-vendég | processzor/usage_active |
Naplókeresési riasztási szabályok
CPU-kihasználtság
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Processor" and Name == "UtilizationPercentage"
| summarize CPUPercentageAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Memóriariasztások
Ez a szakasz a memóriariasztásokat ismerteti.
Metrika riasztási szabályai
| Cél | Metrika |
|---|---|
| Gazdagép | Rendelkezésre álló memória bájtok (előzetes verzió) (az ajánlott riasztásokban szerepel) |
| Windows-vendég | \Memory% Committed Bytes in use \Memory\Available Bytes |
| Linux-vendég | mem/available mem/available_percent |
Naplókeresési riasztási szabályok
Rendelkezésre álló memória MB-ban
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| summarize AvailableMemoryInMBAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Rendelkezésre álló memória százalékban
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Memory" and Name == "AvailableMB"
| extend TotalMemory = toreal(todynamic(Tags)["vm.azm.ms/memorySizeMB"]) | extend AvailableMemoryPercentage = (toreal(Val) / TotalMemory) * 100.0
| summarize AvailableMemoryInPercentageAverage = avg(AvailableMemoryPercentage) by bin(TimeGenerated, 15m), Computer, _ResourceId
Lemezriasztások
Ez a szakasz a lemezriasztásokat ismerteti.
Metrika riasztási szabályai
| Cél | Metrika |
|---|---|
| Windows-vendég | \Logikai lemez(_Total)% szabad terület \Logikai lemez(_Total)\Szabad megabájt |
| Linux-vendég | lemez/szabad lemez/free_percent |
Naplókeresési riasztási szabályok
Használt logikai lemez – az egyes számítógépek összes lemeze
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Használt logikai lemez – különálló lemezek
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "FreeSpacePercentage"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize LogicalDiskSpacePercentageFreeAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Logikai lemez IOPS
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "TransfersPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskIOPSAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Logikai lemez adatsebessége
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "LogicalDisk" and Name == "BytesPerSecond"
| extend Disk=tostring(todynamic(Tags)["vm.azm.ms/mountId"])
| summarize DiskBytesPerSecondAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, Disk
Hálózati riasztások
Metrika riasztási szabályai
| Cél | Metrika |
|---|---|
| Gazdagép | Network In Total, Network Out Total (az ajánlott riasztásokban szerepel) |
| Windows-vendég | \Hálózati adapter\Másodpercenként küldött bájtok \Logikai lemez(_Total)\Szabad megabájt |
| Linux-vendég | lemez/szabad lemez/free_percent |
Naplókeresési riasztási szabályok
Fogadott hálózati adapterek bájtjai – minden adapter
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| summarize BytesReceivedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Fogadott hálózati adapterek bájtjai – egyedi adapterek
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "ReadBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesReceievedAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Elküldött hálózati adapterek bájtjai – minden adapter
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId
Küldött hálózati adapterek bájtjai – egyedi adapterek
InsightsMetrics
| where Origin == "vm.azm.ms"
| where Namespace == "Network" and Name == "WriteBytesPerSecond"
| extend NetworkInterface=tostring(todynamic(Tags)["vm.azm.ms/networkDeviceId"])
| summarize BytesSentAverage = avg(Val) by bin(TimeGenerated, 15m), Computer, _ResourceId, NetworkInterface
Windows- és Linux-események
Az alábbi minta riasztást hoz létre egy adott Windows-esemény létrehozásakor. Metrikamérési riasztási szabályt használ, hogy minden számítógéphez külön riasztást hozzon létre.
Riasztási szabály létrehozása egy adott Windows-eseményen. Ez a példa egy eseményt mutat be az alkalmazásnaplóban. Adjon meg 0-nál nagyobb küszöbértéket és 0-nál nagyobb egymást követő behatolásokat.
Event | where EventLog == "Application" | where EventID == 123 | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)Hozzon létre egy riasztási szabályt egy adott súlyossággal rendelkező Syslog-eseményekhez. Az alábbi példa a hibaengedélyezési eseményeket mutatja be. Adjon meg 0-nál nagyobb küszöbértéket és 0-nál nagyobb egymást követő behatolásokat.
Syslog | where Facility == "auth" | where SeverityLevel == "err" | summarize NumberOfEvents = count() by Computer, bin(TimeGenerated, 15m)
Egyéni teljesítményszámlálók
Hozzon létre egy riasztást a számláló maximális értékéről.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = max(CounterValue) by ComputerHozzon létre egy riasztást egy számláló átlagos értékéről.
Perf | where CounterName == "My Counter" | summarize AggregatedValue = avg(CounterValue) by Computer