Request Units in Azure Cosmos DB
A KÖVETKEZŐKRE VONATKOZIK: ![]() Nosql
Nosql ![]() MongoDB
MongoDB ![]() Cassandra
Cassandra ![]() Gremlin
Gremlin ![]() Táblázat
Táblázat
Az Azure Cosmos DB számos API-t támogat, például sql, MongoDB, Cassandra, Gremlin és Table. Minden API saját adatbázisműveletekkel rendelkezik. Ezek a műveletek az egyszerű pontolvasástól és írástól az összetett lekérdezésekig terjednek. Minden adatbázis-művelet a művelet összetettsége alapján használja fel a rendszererőforrásokat.
Az Azure Cosmos DB normalizálja az összes adatbázis-művelet költségét a kérelemegységek (röviden kérelemegységek) használatával, és az átviteli sebesség alapján méri a költségeket (kérelemegységek másodpercenként, RU/s).
A kérelemegység olyan teljesítmény-pénznem, amely az Azure Cosmos DB által támogatott adatbázis-műveletek végrehajtásához szükséges rendszererőforrásokat, például a CPU-t, az IOPS-t és a memóriát absztrakciós pénznemként használja. Függetlenül attól, hogy az adatbázis-művelet írás, pontolvasás vagy lekérdezés, a műveletek mindig kérelemegységekben vannak mérve. Egy 1 KB-os elem pontolvasása (egy elem beolvasása az azonosító és a partíciókulcs értéke alapján) például egy kérelemegység (vagy egy RU), függetlenül attól, hogy melyik API-t használja az Azure Cosmos DB-tárolóval való interakcióhoz. Az átviteli sebesség költségeit az Azure Cosmos DB kapacitáskalkulátorával modellezheti.
The following image shows the high-level idea of RUs:
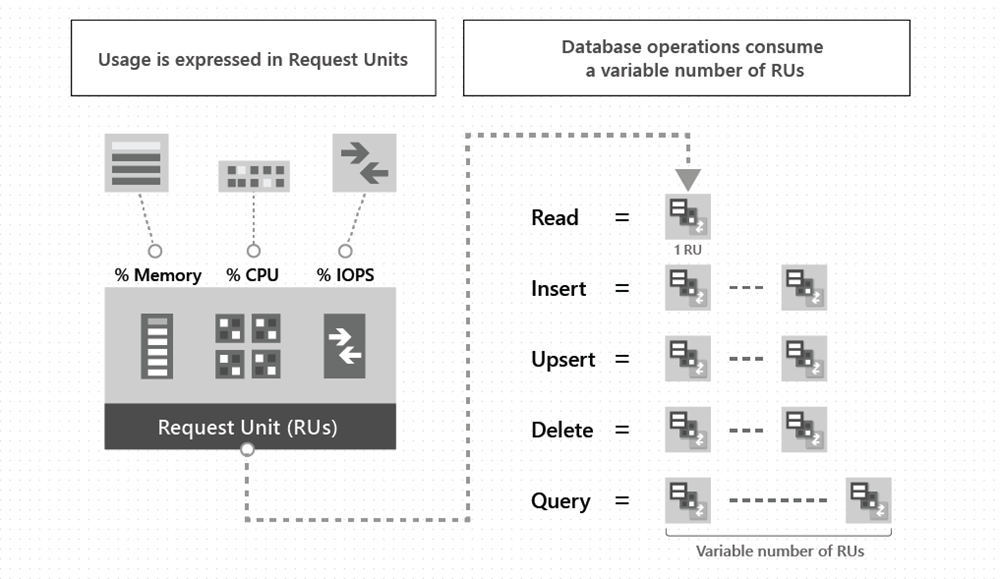
To manage and plan capacity, Azure Cosmos DB ensures that the number of RUs for a given database operation over a given dataset is deterministic. A válaszfejlécet megvizsgálva nyomon követheti az adatbázis-műveletek által felhasznált kérelemegységek számát. When you understand the factors that affect RU charges and your application's throughput requirements, you can run your application cost effectively.
The type of Azure Cosmos DB account you're using determines the way consumed RUs get charged. There are three modes in which you can create an account:
Kiosztott átviteli mód: Ebben a módban az alkalmazás kérelemegységeinek számát másodpercenként 100 kérelemegység/másodperces növekményben rendeli hozzá. To scale the provisioned throughput for your application, you can increase or decrease the number of RUs at any time in increments or decrements of 100 RUs. You can make your changes either programmatically or by using the Azure portal. You're billed on an hourly basis for the number of RUs per second you've provisioned. To learn more, see the Provisioned throughput article.
You can assign throughput at two distinct granularities:
- Tárolók: További információ: Átviteli sebesség hozzárendelése egy Azure Cosmos DB-tárolóhoz.
- Adatbázisok: További információ: Átviteli sebesség hozzárendelése egy Azure Cosmos DB-adatbázishoz.
Kiszolgáló nélküli mód: Ebben a módban nem kell átviteli sebességet hozzárendelnie az Erőforrások létrehozásakor az Azure Cosmos DB-fiókban. At the end of your billing period, you get billed for the number of Request Units consumed by your database operations. To learn more, see the Serverless throughput article.
Automatikus skálázási mód: Ebben a módban automatikusan és azonnal skálázhatja az adatbázis vagy tároló átviteli sebességét (RU/s) a használat alapján. This scaling operation doesn't affect the availability, latency, throughput, or performance of the workload. Ez a mód jól használható olyan kritikus fontosságú számítási feladatokhoz, amelyek változó vagy kiszámíthatatlan forgalmi mintákkal rendelkeznek, és nagy teljesítményű és skálázott SLA-kat igényelnek. To learn more, see the autoscale throughput article.
A kérelemegységekkel kapcsolatos megfontolások
Miközben megbecsüli a számítási feladat által felhasznált kérelemegységek számát, vegye figyelembe a következő tényezőket:
Elemméret: Az elem méretének növekedésével az elem olvasásához vagy írásához felhasznált kérelemegységek száma is nő.
Elemindexelés: Alapértelmezés szerint minden elem automatikusan indexel. Kevesebb kérelemegység lesz felhasználva, ha egy tárolóban egyes elemeket nem indexel.
Elemtulajdonságok száma: Feltéve, hogy az alapértelmezett indexelés az összes tulajdonságon történik, az elem írásához felhasznált kérelemegységek száma növekszik az elemtulajdonságok számának növekedésével.
Indexelt tulajdonságok: Az egyes tárolók indexelési szabályzata határozza meg, hogy mely tulajdonságok legyenek alapértelmezés szerint indexelve. Ha csökkenteni szeretné az írási műveletek fogyasztását, korlátozza az indexelt tulajdonságok számát.
Adatkonzisztencia: Az erős és korlátozott elavultsági konzisztenciaszintek körülbelül kétszer több kérelemegységet használnak fel, miközben olvasási műveleteket hajtanak végre a többi nyugodt konzisztenciaszinthez képest.
Olvasási típus: A pontolvasások kevesebb kérelemegységbe kerülnek, mint a lekérdezések.
Lekérdezési minták: A lekérdezések összetettsége befolyásolja, hogy egy művelet hány kérelemegységet használ fel. A lekérdezési műveletek költségét befolyásoló tényezők többek között:
- A lekérdezési eredmények száma
- A predikátumok száma
- A predikátumok természete
- Felhasználó által definiált függvények száma
- A forrásadat mérete
- Az eredményhalmaz mérete
- Leképezések
Ugyanazon adatok ugyanazon lekérdezése mindig ugyanannyi kérelemegységbe kerül ismétlődő végrehajtás esetén.
Szkripthasználat: A lekérdezésekhez hasonlóan a tárolt eljárások és az eseményindítók is a végrehajtott műveletek összetettsége alapján használják fel a kérelemegységeket. Az alkalmazás fejlesztése során vizsgálja meg a kérelemdíj fejlécet, hogy pontosabb képet kapjon arról, hány kérelemegységet fogyasztanak az egyes műveletek.
Kérelemegységek és több régió
Ha "R" kérelemegységeket rendel egy Azure Cosmos DB-tárolóhoz (vagy adatbázishoz), az Azure Cosmos DB biztosítja, hogy az "R" kérelemegységek elérhetők legyenek az Azure Cosmos DB-fiókhoz társított minden régióban. A kérelemegységeket nem lehet szelektíven hozzárendelni egy adott régióhoz. Az Azure Cosmos DB-tárolón (vagy adatbázisban) kiépített kérelemegységek az Azure Cosmos DB-fiókhoz társított összes régióban ki vannak építve.
Feltételezve, hogy az Azure Cosmos DB-tároló "R" kérelemegységekkel van konfigurálva, és az Azure Cosmos DB-fiókhoz tartozó "N" régiók vannak társítva, a tárolón globálisan elérhető összes kérelemegység = R x N.
A konzisztenciamodell kiválasztása az átviteli sebességet is befolyásolja. A nyugodtabb konzisztenciaszintek (munkamenet, konzisztens előtag és végleges konzisztencia) körülbelül 2-szeres olvasási átviteli sebességét érheti el az erősebb konzisztenciaszintekhez képest (korlátozott elavultság vagy erős konzisztencia).
További lépések
- További információ arról, hogyan rendelhet hozzá átviteli sebességet az Azure Cosmos DB-tárolókhoz és -adatbázisokhoz.
- További információ a kiszolgáló nélküli Azure Cosmos DB-ről.
- További információ a logikai partíciókról