Számos nagy léptékű megoldásban az adatok partíciókra vannak osztva, amelyek külön kezelhetők és érhetők el. A particionálás javíthatja a skálázhatóságot, csökkentheti a versengést és optimalizálhatja a teljesítményt. Egy olyan mechanizmust is kínálhat, amellyel az adatokat fel lehet osztani a használati minták mentén. Például a régebbi adatok olcsóbb adattárolókban archiválhatók.
A particionálási stratégiát azonban gondosan kell kiválasztani az előnyök maximalizálása érdekében, a káros hatások minimalizálása mellett.
Megjegyzés
Ebben a cikkben a particionálás kifejezés alatt az adatok külön adattárakba való fizikai felosztásának folyamatát értjük. Ez nem ugyanaz, mint az SQL Server táblaparticionálása.
Miért kell particionálni az adatokat?
A skálázhatóság javítása. Az önálló adatbázisrendszerek vertikális felskálázásakor a rendszer végül eléri a fizikai hardver korlátait. Ha több partícióra osztja az adatokat, és mindegyik külön kiszolgálón fut, szinte határozatlan időre felskálázhatja a rendszert.
Javítja a teljesítményt. Az egyes partíciókon az adatelérési műveletek kisebb mennyiségű adatot érintenek. A megfelelő módon végzett particionálás hatékonyabbá teheti a rendszert. Az egyszerre több partíciót érintő műveletek párhuzamosan futtathatóak.
A biztonság javítása. Bizonyos esetekben a bizalmas és nem érzékeny adatokat különböző partíciókra különítheti el, és különböző biztonsági vezérlőket alkalmazhat a bizalmas adatokra.
A működési rugalmasság megteremtése. A particionálás számos lehetőséget kínál a műveletek finomhangolására, a felügyeleti hatékonyság maximalizálására és a költségek minimalizálására. Például különböző stratégiák határozhatók meg a felügyelethez, a monitorozáshoz, a biztonsági mentéshez és helyreállításhoz, valamint egyéb felügyeleti tevékenységekhez az egyes partíciók adatainak fontossága alapján.
A használati mintának megfelelő adattárak használata. A particionálás révén az egyes partíciók különböző típusú adattárakban futtathatóak az ilyen adattárak költségei és beépített szolgáltatásai alapján. A nagy bináris adatok például blobtárolóban tárolhatók, míg strukturáltabb adatok tárolhatók egy dokumentum-adatbázisban. Lásd: A megfelelő adattároló kiválasztása.
A rendelkezésre állás javítása. Az adatok több kiszolgálóra való leosztásával kiküszöbölhető az egypontos meghibásodás kockázata. Ha egy példány meghibásodik, csak az abban a partícióban lévő adatok nem érhetők el. A többi partíción folytatódhatnak a műveletek. A felügyelt PaaS-adattárak esetében ez a szempont kevésbé releváns, mivel ezek a szolgáltatások beépített redundanciával vannak kialakítva.
Partíciók tervezése
Az adatok particionálásának három tipikus stratégiája van:
Horizontális particionálás (vagy más néven horizontális skálázás). Ebben a stratégiában minden partíció külön adattár, de minden partíció ugyanazzal a sémával rendelkezik. Minden partíciót szegmensnek nevezünk, és az adatok egy adott részhalmazát tárolja, például egy adott ügyfélcsoport összes megrendelését.
Vertikális particionálás. Ebben a stratégiában mindegyik partíció az adattárban tárolt elemek mezőinek egy alhalmazát tartalmazza. A mezők a használati mintáik alapján vannak felosztva. Például a gyakran használt mezők az egyik, a kevésbé gyakran használtak egy másik partícióba kerülhetnek.
Funkcionális particionálás. Ebben a stratégiában az adatok összesítése az alapján történik, hogy a rendszer egyes körülhatárolt kontextusai hogyan használják őket. Egy e-kereskedelmi rendszer például az egyik partícióban tárolhatja a számlaadatokat, a termékleltár adatait pedig egy másikban.
Ezek a stratégiák kombinálhatók, és azt javasoljuk, hogy a particionálási sémák tervezésekor vegye figyelembe őket. Például az adatokat először feloszthatja szegmensekre, majd az egyes szegmensekben lévő adatokat vertikálisan tovább particionálhatja.
Horizontális particionálás
Az 1. ábra vízszintes particionálást vagy horizontális horizontális skálázást mutat be. Ebben a példában a készletadatok termékkulcs alapján vannak szegmensekre bontva. Minden egyes szegmens a szegmenskulcsok betűrend szerint egybefüggő tartományát (A–G és H–Z) tartalmazza. A horizontális horizontális skálázás több számítógépen is elosztja a terhelést, ami csökkenti a versengést és javítja a teljesítményt.
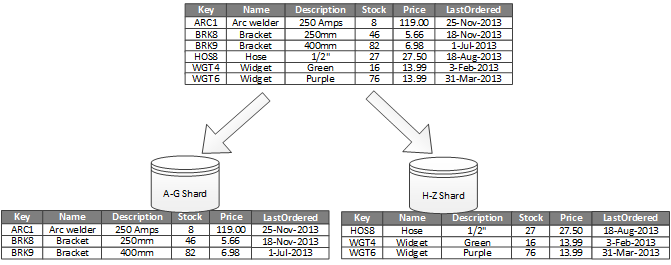
1. ábra – Adatok horizontális particionálása (horizontális particionálása) partíciókulcs alapján.
A legfontosabb tényező a horizontálisan skálázási kulcs kiválasztása. A rendszer beüzemelését követően a kulcs nehezen módosítható. A kulcsnak biztosítania kell az adatok particionálását, hogy a számítási feladat a lehető leg egyenletesen oszlhasson el a szegmensekben.
A szegmenseknek nem kell azonos méretűnek lenniük. A kérések számának kiegyenlítése sokkal fontosabb. Egyes szegmensek nagyon nagyok lehetnek, de mindegyik elemhez kevés hozzáférési művelet tartozik. Más szegmensek esetleg kisebbek ugyan, de az egyes elemeket többször érik el. Azt is fontos biztosítani, hogy egyetlen szegmens ne lépje túl az adattár skálázási korlátait (a kapacitás és a feldolgozási erőforrások tekintetében).
Kerülje a "gyakori elérésű" partíciók létrehozását, amelyek hatással lehetnek a teljesítményre és a rendelkezésre állásra. Az ügyfél nevének első betűjének használata például kiegyensúlyozatlan eloszlást eredményez, mivel egyes betűk gyakoribbak. Ehelyett használjon egy ügyfélazonosító kivonatát az adatok egyenletesebb elosztásához a partíciók között.
Válasszon egy horizontálisan skálázási kulcsot, amely minimálisra csökkenti a jövőbeli követelményeket a nagy szegmensek felosztásához, a kis szegmensek nagyobb partíciókra való felosztásához vagy a séma módosításához. Az ilyen műveletek nagyon időigényesek lehetnek, és a végrehajtásuk során esetleg néhány szegmenst le is kell állítani.
Ha a szegmensek replikálva vannak, a replikák némelyike esetleg online tartható, amíg a többi felosztása, egyesítése vagy átkonfigurálása folyik. Előfordulhat azonban, hogy a rendszernek korlátoznia kell az újrakonfigurálás során végrehajtható műveleteket. Előfordulhat például, hogy a replikákban lévő adatok írásvédettként vannak megjelölve, hogy megakadályozzák az adatelkonyultságokat.
A horizontális particionálásról további információt a horizontális particionálási minta című témakörben talál.
Vertikális particionálás
A vertikális particionálás leggyakoribb felhasználási célja a gyakran használt elemek lekérésével kapcsolatos I/O- és teljesítményköltségek csökkentése. A 2. ábrán a vertikális particionálás egy példája látható. Ebben a példában egy elem különböző tulajdonságai különböző partíciókban vannak tárolva. Az egyik partíció a gyakrabban elérhető adatokat tartalmazza, beleértve a termék nevét, leírását és árát. Egy másik partíció készletadatokat tárol: a készletszámot és az utolsóként rendezett dátumot.
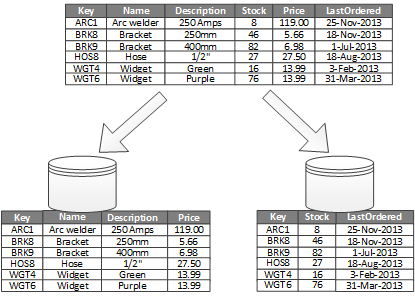
2. ábra – Az adatok függőleges particionálása a használati mintája alapján.
Ebben a példában az alkalmazás rendszeresen lekérdezi a termékek nevét, leírását és árát, amikor megjeleníti a termékek részleteit az ügyfelek számára. A készletszám és az utolsóként rendezett dátum egy külön partícióban van tárolva, mivel ezt a két elemet gyakran használják együtt.
A függőleges particionálás egyéb előnyei:
A viszonylag lassan mozgó adatok (terméknév, leírás és ár) elválaszthatók a dinamikusabb adatoktól (készletszint és utolsó rendelés dátuma). Az adatok lassú áthelyezése jó választás az alkalmazások számára a memóriában való gyorsítótárazáshoz.
A bizalmas adatok külön partíción, további biztonsági vezérlőkkel tárolhatók.
A függőleges particionálás csökkentheti a szükséges egyidejű hozzáférés mennyiségét.
A vertikális particionálás az entitások szintjén működik a tárolóban, részlegesen normalizálja az entitásokat, és széles elemekből keskeny elemekké bontja le azokat. Kiválóan alkalmazható oszlopalapú, például HBase és Cassandra adattárakhoz. Ha az oszlopok egy gyűjteményében lévő adatok valószínűleg nem változnak majd, megpróbálhat oszloptárolókat is használni az SQL Serverben.
Funkcionális particionálás
Ha egy alkalmazás minden különálló üzleti területének határos környezete azonosítható, a funkcionális particionálással javítható az elkülönítés és az adathozzáférés teljesítménye. A funkcionális particionálás másik gyakori felhasználási célja az olvasási-írási adatok és a csak olvasható adatok elkülönítése. A 3. ábrán a funkcionális particionálás áttekintése látható egy példán, ahol a készletadatok elkülönülnek az ügyféladatoktól.
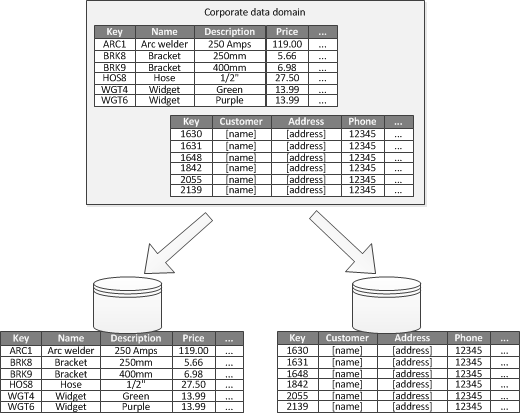
3. ábra – Adatok funkcionális particionálása kötött környezet vagy altartomány szerint.
Ez a particionálási stratégia csökkentheti az adatelérési versengést a rendszer egyes részei között.
Partíciók tervezése skálázhatóságra
Elengedhetetlen az egyes partíciók méretének és munkaterhelésének mérlegelése és kiegyensúlyozása, hogy az adatok megfelelően legyenek elosztva a maximális skálázhatóság érdekében. Azonban az adatok particionálása során arra is figyelni kell, hogy ne haladják meg az egypartíciós tárolók skálázási korlátait.
A partíciók skálázhatóságra tervezése során kövesse az alábbi lépéseket:
- Az alkalmazás elemzésével ismerje meg a hozzáférési mintákat, például az egyes lekérdezések által visszaadott eredményhalmazok méretét, az adatelérési gyakoriságot, az eredendő késést és a kiszolgálóoldali számítási feldolgozás követelményeit. Sok esetben néhány nagyobb entitás igényli a szükséges erőforrások többségét.
- Az elemzés segítségével határozza meg az aktuális és a jövőbeli skálázhatósági célokat, például az adatok méretét és a munkaterhelést. Ezután ossza el az adatokat a partíciók közt a skálázhatósági célok teljesítéséhez. A horizontális particionáláshoz fontos a megfelelő szegmenskulcs kiválasztása, hogy a elosztás egyenletes legyen. További információkért lásd a horizontális skálázási mintát.
- Győződjön meg arról, hogy minden partíció rendelkezik elegendő erőforrással a méretezhetőségi követelmények kezeléséhez az adatméret és az átviteli sebesség tekintetében. Az adattártól függően a partíciónkénti tárhely, a feldolgozási teljesítmény vagy a hálózati sávszélesség korlátozott lehet. Ha a követelmények valószínűleg túllépik ezeket a korlátokat, előfordulhat, hogy finomítania kell a particionálási stratégiát, vagy további adatokat kell felosztania, esetleg két vagy több stratégiát kombinálva.
- Monitorozza a rendszert annak ellenőrzéséhez, hogy az adatok a várt módon oszlanak-e el, és hogy a partíciók képesek-e kezelni a terhelést. A tényleges használat nem mindig egyezik meg azzal, amit egy elemzés előre jelez. Ha igen, lehetséges a partíciók újraegyensúlyozása, vagy a rendszer egyes részeinek újratervezése a szükséges egyensúly eléréséhez.
Egyes felhőkörnyezetek az infrastruktúra határait tekintve foglalnak le erőforrásokat. Bizonyosodjon meg róla, hogy a kiválasztott határ korlátai elegendő teret biztosítanak az adatmennyiség várható növekedéséhez az adattárolás, a feldolgozási teljesítmény és a sávszélesség tekintetében.
Ha például Azure Table Storage-t használ, a kérések mennyisége korlátozott, amelyet egyetlen partíció kezelhet egy adott időszakban. (További információ: Az Azure Storage méretezhetősége és teljesítménycéljai.) Az elfoglalt szegmensek több erőforrást igényelhetnek, mint amennyit egyetlen partíció képes kezelni. Ha igen, előfordulhat, hogy a szegmenst újra kell particionolni a terhelés szétosztásához. Ha ezeknek a tábláknak a teljes mérete vagy átviteli sebessége meghaladja egy tárfiók kapacitását, előfordulhat, hogy további tárfiókokat kell létrehoznia, és el kell osztania a táblákat ezeken a fiókokon.
Partíciók tervezése lekérdezési teljesítményre
A lekérdezési teljesítmény gyakran kisebb adatkészletek használatával és a lekérdezések párhuzamos futtatásával növelhető. Mindegyik partíciónak a teljes adatkészlet egy kis részét kell tartalmaznia. A mennyiség csökkenésével javulhat a lekérdezések teljesítménye. A particionálás azonban nem váltja ki az adatbázis megfelelő kialakítását és konfigurálását. Győződjön meg például arról, hogy rendelkezik a szükséges indexek helyével.
A partíciók lekérdezési teljesítményre tervezése során kövesse az alábbi lépéseket:
Vizsgálja meg az alkalmazás követelményeit és teljesítményét:
- Az üzleti követelmények segítségével meghatározhatja azokat a kritikus lekérdezéseket, amelyeknek mindig gyorsan végre kell hajtaniuk.
- A rendszer monitorozásával azonosítsa a mindig lassan lefutó lekérdezéseket.
- Keresse meg, hogy mely lekérdezések végrehajtása a leggyakrabban történik. Még ha egyetlen lekérdezés minimális költséggel is rendelkezik, az összesített erőforrás-felhasználás jelentős lehet.
Particionálja a teljesítményt csökkentő adatokat:
- Korlátozza az egyes partíciók méretét, hogy a lekérdezések válaszideje a célon belül maradjon.
- Ha vízszintes particionálást használ, úgy tervezheti meg a szegmenskulcsot, hogy az alkalmazás egyszerűen kiválaszthassa a megfelelő partíciót. Így a lekérdezésnek nem kell az összes partíciót átvizsgálnia.
- Mérlegelje a partíciók elhelyezését. Ha lehetséges, próbálja az adatokat olyan partíciókban tárolni, amelyek földrajzilag közel helyezkednek el az adatokhoz hozzáférő alkalmazásokhoz és felhasználókhoz.
Ha egy entitás a feldolgozási sebességre vagy lekérdezési teljesítményre vonatkozó követelményekkel rendelkezik, alkalmazzon funkcionális particionálást az adott entitás alapján. Ha ez még mindig nem elégíti ki a követelményeket, alkalmazzon horizontális particionálást is. A legtöbb esetben elegendő egyetlen particionálási stratégia, de bizonyos esetekben hatékonyabb mindkét stratégia kombinálása.
Fontolja meg a lekérdezések párhuzamos futtatását a partíciók között a teljesítmény javítása érdekében.
Partíciók tervezése rendelkezésre állásra
Az adatok particionálásával javítható az alkalmazások rendelkezésre állása, mivel így a teljes adatkészlet nem jelent egypontos meghibásodási helyet, és az adatkészlet egyes részhalmazai egymástól függetlenül kezelhetők.
Vegye figyelembe az alábbi tényezőket, amelyek befolyásolják a rendelkezésre állást:
Mennyire kritikusak az adatok az üzleti tevékenységek szempontjából. Határozza meg, hogy mely adatok a kritikus üzleti információk, például a tranzakciók, és mely adatok kevésbé kritikus operatív adatok, például naplófájlok.
Fontolja meg a kritikus adatok magas rendelkezésre állású partíciókban való tárolását egy megfelelő biztonsági mentési tervvel.
Külön felügyeleti és monitorozási eljárásokat hozhat létre a különböző adathalmazokhoz.
Az ugyanolyan kritikusságú adatokat helyezze ugyanabba a partícióba, hogy megfelelő gyakorisággal egyszerre készíthessen biztonsági másolatot róluk. Előfordulhat például, hogy a tranzakciós adatokat tartalmazó partíciókról gyakrabban kell biztonsági másolatot készíteni, mint a naplózási vagy nyomkövetési adatokat tartalmazó partíciókról.
Hogyan felügyelhetőek az egyes partíciók. A partíciók a független felügyeletet és karbantartást biztosító kialakítása több előnnyel is jár. Például:
Ha egy partíció meghibásodik, az önállóan helyreállítható anélkül, hogy az alkalmazások más partíciókban lévő adatokat férnek hozzá.
Az adatok földrajzi területek szerinti particionálásával az ütemezett karbantartás minden helyen a csúcsidőn kívül végezhető el. Győződjön meg arról, hogy a partíciók nem túl nagyok ahhoz, hogy megakadályozzák a tervezett karbantartások befejezését ebben az időszakban.
Érdemes-e a kritikus fontosságú adatokat a partíciók közt replikálni. Ez a stratégia javíthatja a rendelkezésre állást és a teljesítményt, de konzisztenciaproblémákat is okozhat. Időbe telik a módosítások szinkronizálása minden replikával. Ez alatt az idő alatt az adatértékek a különböző partíciókban különbözőek lesznek.
Alkalmazáskialakítási szempontok
A particionálás összetettebbé teszi a rendszer tervezését és fejlesztését. A particionálást a rendszer alapvető részeként kell tekinteni a tervezés során, még ha a rendszer eleinte csak egyetlen partícióval rendelkezik is. Ha utógondolatként kezeli a particionálást, az nagyobb kihívást jelent, mert már rendelkezik egy élő rendszerrel, amely karbantartható:
- Az adatelérési logikát módosítani kell.
- Előfordulhat, hogy nagy mennyiségű meglévő adatot kell migrálni, hogy eloszthassa azokat a partíciók között.
- A felhasználók várhatóan továbbra is használhatják a rendszert a migrálás során.
Esetenként a particionálást nem tekintik fontosnak, mivel kezdetben még kisméretű az adatkészlet, és egy kiszolgáló könnyen képes kezelni azt. Ez egyes számítási feladatokra igaz lehet, de számos kereskedelmi rendszernek bővülnie kell a felhasználók számának növekedésével.
Ráadásul nem csak a nagy méretű adattárak élvezik a particionálás előnyeit. Például egy kisméretű adattárnak is lehet intenzív forgalma több száz egyidejű ügyfél irányában. Ilyen esetben az adatok particionálása segíthet csökkenteni a versengést és növelni a teljesítményt.
Az adatparticionálási sémák kialakításakor vegye figyelembe a következő szempontokat:
A partíciók közötti adathozzáférési műveletek minimalizálása. Amikor csak lehetséges, a leggyakrabban használt adatbázis-műveletekben érintett adatokat tartsa együtt az egyes partíciókban a több partíciót érintő adatelérési műveletek minimalizálása érdekében. A partíciók közötti lekérdezések időigényesebbek lehetnek, mint egy partíción belüli lekérdezések, de a partíciók optimalizálása egy lekérdezéskészlethez hátrányosan befolyásolhatja a többi lekérdezéskészletet. Ha a partíciók között kell lekérdezést végeznie, minimalizálja a lekérdezési időt párhuzamos lekérdezések futtatásával és az eredmények összesítésével az alkalmazásban. (Előfordulhat, hogy ez a megközelítés bizonyos esetekben nem lehetséges, például amikor az egyik lekérdezés eredményét használja a következő lekérdezés.)
Fontolja meg a statikus referenciaadatok replikálását. Ha a lekérdezések viszonylag statikus referenciaadatokat, például irányítószámtáblákat vagy terméklistákat használnak, fontolja meg az adatok replikálását az összes partíción, hogy csökkentse a különböző partíciókban a különálló keresési műveleteket. Ez a megközelítés csökkentheti annak valószínűségét is, hogy a referenciaadatok "gyakori" adathalmazokká váljanak, és a teljes rendszerből nagy forgalom keljen meg. A referenciaadatok módosításainak szinkronizálása azonban további költségekkel jár.
A partíciók közötti illesztések minimalizálása. Ahol csak lehetséges, a vertikális és funkcionális partíciókban minimalizálja a hivatkozásintegritás-igényeket. Ezekben a sémákban az alkalmazás felelős a hivatkozási integritás fenntartásáért a partíciók között. Az adatokat több partíción összekapcsoló lekérdezések nem hatékonyak, mert az alkalmazásnak általában egy kulcs, majd egy idegen kulcs alapján kell egymást követő lekérdezéseket végrehajtania. Ehelyett érdemes replikálni a vonatkozó adatokat vagy megszüntetni azok normalizáltságát. Ha partíciók közötti illesztésekre van szükség, futtasson párhuzamos lekérdezéseket a partíciókon, és csatlakoztassa az adatokat az alkalmazáson belül.
Végső konzisztencia támogatása. Mérje fel, hogy az erős konzisztencia valóban követelmény-e. Az elosztott rendszerek egyik gyakori megközelítése a végleges konzisztencia megvalósítása. Az egyes partíciók adatainak frissítése külön történik, és az alkalmazáslogika biztosítja, hogy a frissítések mind sikeresen mennek végbe. A logika emellett a végül konzisztens műveletek keretében futtatott adatlekérdezésekből eredő esetleges inkonzisztenciákat is kezeli.
Mérlegelje, hogyan találják meg a lekérdezések a megfelelő partíciót. Ha egy lekérdezésnek az összes partíciót át kell vizsgálnia a szükséges adatok megtalálásához, az jelentős mértékben kihathat a teljesítményre, még akkor is, ha több párhuzamos lekérdezés fut. Függőleges és funkcionális particionálás esetén a lekérdezések természetesen meg tudják adni a partíciót. A vízszintes particionálás viszont megnehezítheti az elemek keresését, mivel minden szegmens ugyanazt a sémát használja. Tipikus megoldás egy térkép karbantartására, amely adott elemek szegmenshelyének keresésére szolgál. Ez a térkép az alkalmazás horizontális particionálási logikájában valósítható meg, vagy az adattár is karbantarthatja, ha támogatja a transzparens horizontális particionálást.
Fontolja meg a szegmensek rendszeres újraegyensúlyozását. Horizontális particionálás esetén a szegmensek újraegyensúlyozása lehetővé teheti az adatok egyenletes elosztását méret és számítási feladat alapján a hotspotok minimalizálása, a lekérdezési teljesítmény maximalizálása és a fizikai tárolási korlátozások megkerülése érdekében. Ez azonban egy összetett feladat, amelyhez általában egy egyéni eszköz vagy folyamat használata szükséges.
Partíciók replikálása. Ha mindegyik partíciót replikálja, ez további védelmet biztosít a meghibásodások ellen. Ha egyetlen replika meghibásodik, a lekérdezések egy működő példány felé irányíthatók.
Ha eléri valamely particionálási stratégia fizikai korlátait, érdemes lehet a skálázhatóságot egy másik szintre kiterjeszteni. Például ha a particionálás az adatbázis szintjén valósul meg, a partíciókat esetleg több adatbázisban szükséges elhelyezni vagy replikálni. Ha a particionálás már eleve az adatbázis szintjén van megvalósítva, és a fizikai korlátok problémát jelentenek, ez jelezheti azt, hogy a partíciókat esetleg több üzemeltetési fiókban szükséges elhelyezni vagy replikálni.
Kerülje a több partícióban lévő adatokat használó tranzakciókat. Egyes adattárak tranzakció-konzisztenciát és integritást valósítanak meg az adatokat módosító műveletekre, de csak abban az esetben, ha az adatok egyetlen partíción találhatóak. Ha több partícióra kiterjedő tranzakciótámogatás szükséges, ezt valószínűleg az alkalmazáslogika részeként kell megvalósítania, mivel a legtöbb particionálási rendszer ezt natív módon nem támogatja.
Minden adattárhoz bizonyos üzemeltetési felügyeleti és monitorozási tevékenységeket is végezni kell. Ilyen feladat lehet az adatok betöltése, az adatok biztonsági mentése és helyreállítása, az adatok átrendezése, valamint a rendszer megfelelő és hatékony működésének biztosítása.
Mérlegelje az üzemeltetési felügyeletet befolyásoló alábbi tényezőket:
Hogyan valósíthatóak meg a megfelelő felügyeleti és üzemeltetési feladatok az adatok particionálása esetén. Ilyen feladatok lehetnek a biztonsági mentés és visszaállítás, az adatok archiválása, a rendszer monitorozása, valamint egyéb felügyeleti feladatok. Például a logikai konzisztencia fenntartása a biztonsági mentési és visszaállítási műveletek során kihívást jelenthet.
Hogyan tölthetőek be az adatok több partícióba, és hogyan adhatók hozzá a külső forrásokból érkező új adatok. Egyes eszközök és segédprogramok esetleg nem támogatják a horizontálisan particionált adatműveleteket, például az adatok a megfelelő partícióba való betöltését.
Hogyan oldható meg az adatok rendszeres archiválása és törlése. A partíciók túlzott növekedésének megakadályozása érdekében rendszeresen (például havonta) kell archiválnia és törölnie az adatokat. Szükség lehet az adatok egy másik archiválási sémának megfelelő átalakítására.
Hogyan találhatók meg az adatintegritási problémák. Érdemes lehet rendszeres folyamat futtatásával megkeresni az adatintegritási problémákat, például az egyik partícióban lévő adatokat, amelyek a hiányzó információkra hivatkoznak egy másikban. A folyamat megpróbálhatja automatikusan kijavítani ezeket a problémákat, vagy létrehozhat egy jelentést manuális felülvizsgálatra.
Partíciók kiegyenlítése
A rendszer kifejlettségével előfordulhat, hogy módosítania kell a particionálási sémát. Előfordulhat például, hogy az egyes partíciók aránytalan mennyiségű forgalmat kezdenek el kapni, és gyakorivá válnak, ami túlzott versengéshez vezet. Vagy előfordulhat, hogy alábecsülte bizonyos partíciók adatmennyiségét, ami miatt egyes partíciók megközelítik a kapacitáskorlátokat.
Egyes adattárak, például az Azure Cosmos DB automatikusan újraegyensúlyozhatják a partíciókat. Más esetekben az újraegyensúlyozás egy két szakaszból álló felügyeleti feladat:
Új particionálási stratégia meghatározása.
- Mely partíciókat kell felosztani (vagy esetleg kombinálni)?
- Mi az új partíciókulcs?
Adatok áttelepítése a régi particionálási sémából az új partíciókészletbe.
Az adattártól függően előfordulhat, hogy használat közben is áttelepíthet adatokat a partíciók között. Ezt nevezzük online migrálásnak. Ha ez nem lehetséges, előfordulhat, hogy a partíciókat elérhetetlenné kell tennie az adatok áthelyezése közben (offline migrálás).
Offline migrálás
Az offline migrálás általában egyszerűbb, mert csökkenti a versengés esélyét. Az offline migrálás elméletileg a következőképpen működik:
- A partíció megjelölése offline állapotban.
- Egyesítés felosztása és az adatok áthelyezése az új partíciókra.
- Az adatok ellenőrzése.
- Az új partíciók online állapotba helyezése.
- Távolítsa el a régi partíciót.
Ha szeretné, az 1. lépésben megjelölhet egy partíciót írásvédettként, így az alkalmazások továbbra is olvashatják az adatokat az áthelyezés során.
Online migrálás
Az online migrálás összetettebb, de kevésbé zavaró. A folyamat hasonló az offline migráláshoz, azzal a kivétellel, hogy az eredeti partíció nincs offline állapotban megjelölve. A migrálási folyamat részletességétől függően (például elemenként és szegmensenként skálázva) előfordulhat, hogy az ügyfélalkalmazások adatelérési kódjának kezelnie kell a két helyen, az eredeti partíción és az új partíción tárolt adatok olvasását és írását.
Következő lépések
- Megismerheti az egyes Azure-szolgáltatások particionálási stratégiáit. Lásd: Adatparticionálási stratégiák.
- Az Azure Storage méretezhetőségi és teljesítménycéljai
Kapcsolódó források (lehet, hogy a cikkek angol nyelvűek)
A következő tervezési minták lehetnek relevánsak a forgatókönyvhöz:
A horizontális skálázási minta az adatok horizontális skálázásának néhány gyakori stratégiáját ismerteti.
Az indextábla mintája bemutatja, hogyan hozhat létre másodlagos indexeket adatokon keresztül. Az alkalmazás ezzel a megközelítéssel gyorsan kérheti le az adatokat olyan lekérdezések használatával, amelyek nem hivatkoznak a gyűjtemények elsődleges kulcsára.
A materializált nézetminta leírja, hogyan hozhat létre előre feltöltött nézeteket, amelyek összegzik az adatokat a gyors lekérdezési műveletek támogatásához. Ez a megközelítés akkor lehet hasznos a particionált tárolókban, ha az összegzendő adatokat tartalmazó partíciók több helyre vannak osztva.