Másolási tevékenység teljesítményének hibaelhárítása
A következőkre vonatkozik: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Tipp.
Próbálja ki a Data Factoryt a Microsoft Fabricben, amely egy teljes körű elemzési megoldás a nagyvállalatok számára. A Microsoft Fabric az adattovábbítástól az adatelemzésig, a valós idejű elemzésig, az üzleti intelligenciáig és a jelentéskészítésig mindent lefed. Ismerje meg, hogyan indíthat új próbaverziót ingyenesen!
Ez a cikk bemutatja, hogyan háríthatja el a másolási tevékenység teljesítményével kapcsolatos problémákat az Azure Data Factoryben.
A másolási tevékenység futtatása után a másolási tevékenység figyelési nézetben összegyűjtheti a futtatási eredményeket és a teljesítménystatisztikákat. Például:
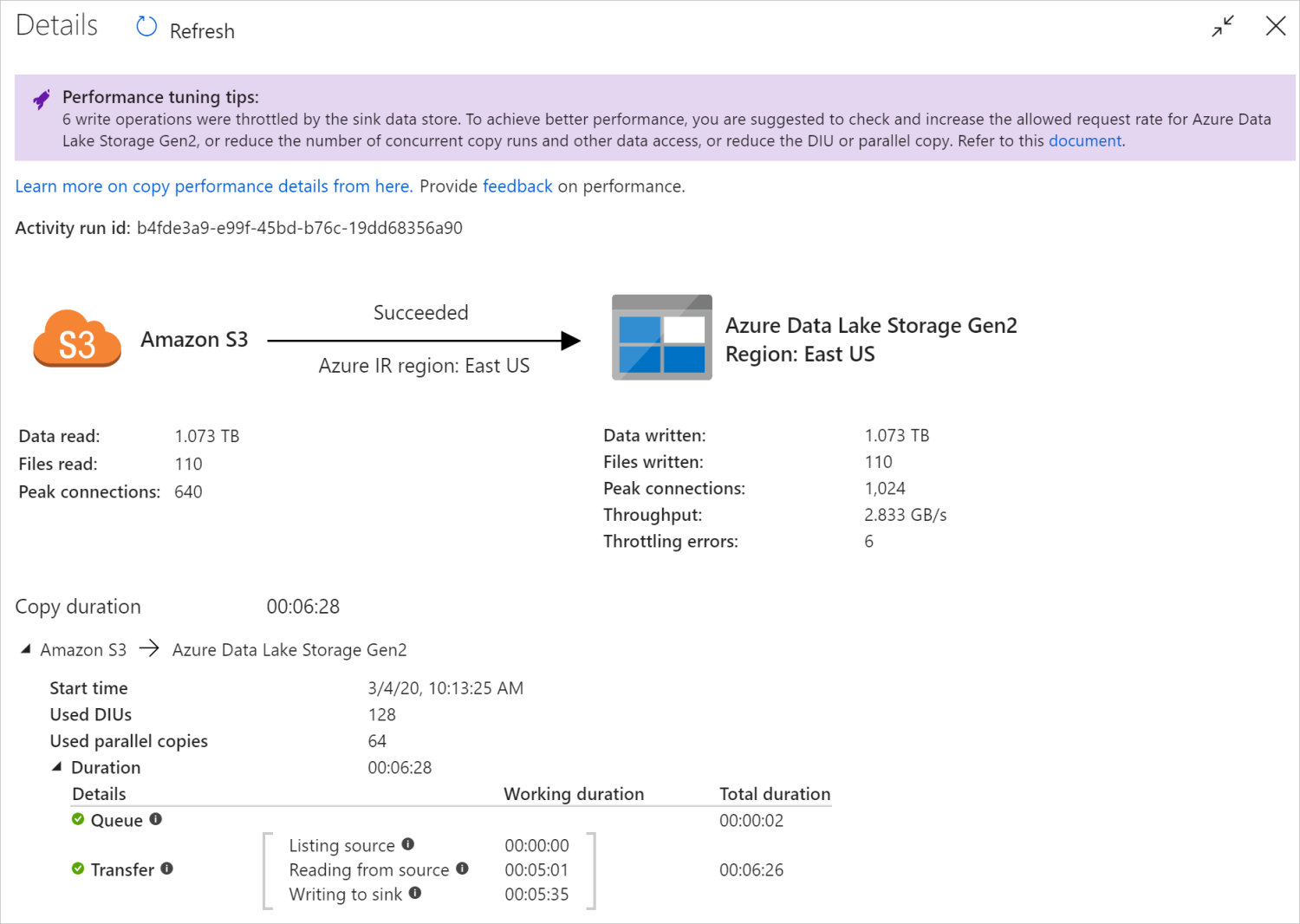
Teljesítmény-finomhangolási tippek
Bizonyos esetekben a másolási tevékenység futtatásakor felül a "Teljesítményhangolási tippek" felirat jelenik meg, ahogyan az a fenti példában is látható. A tippekből megtudhatja, hogy a szolgáltatás milyen szűk keresztmetszetet észlelt az adott példány futtatásához, valamint javaslatot ad a másolás átviteli sebességének növelésére. Próbálkozzon az ajánlott módosítással, majd futtassa újra a másolatot.
Referenciaként jelenleg a teljesítményhangolási tippek a következő esetekben nyújtanak javaslatokat:
| Kategória | Teljesítmény-finomhangolási tippek |
|---|---|
| Adattár-specifikus | Adatok betöltése az Azure Synapse Analyticsbe: ha nincs használatban, javasoljuk a PolyBase vagy a COPY utasítás használatát. |
| Adatok másolása az Azure SQL Database-ből vagy az Azure SQL Database-be: ha a DTU magas kihasználtság alatt áll, javasoljuk, hogy frissítsen magasabb szintre. | |
| Adatok másolása az Azure Cosmos DB-ből vagy az Azure Cosmos DB-be: ha a ru nagy kihasználtság alatt áll, javasoljuk, hogy frissítsen nagyobb ru-ra. | |
| Adatok másolása az SAP-táblából: nagy mennyiségű adat másolásakor javasolja az SAP-összekötő partícióbeállításának használatát a párhuzamos terhelés engedélyezéséhez és a maximális partíciószám növeléséhez. | |
| Adatok betöltése az Amazon Redshiftből: ha nincs használatban, javasoljuk a UNLOAD használatát. | |
| Adattár-szabályozás | Ha az adattár a másolás során számos olvasási/írási műveletet szabályoz, javasoljuk, hogy ellenőrizze és növelje az adattár engedélyezett kérési arányát, vagy csökkentse az egyidejű számítási feladatot. |
| Integrációs modul | Ha önkiszolgáló integrációs modult (IR) használ, és a másolási tevékenység hosszú ideig várakozik az üzenetsorban, amíg az integrációs modul nem rendelkezik elérhető erőforrással a végrehajtáshoz, javasoljuk az integrációs modul horizontális felskálázását/felfelé történő felskálázását. |
| Ha olyan Azure Integration Runtime-t használ, amely nem optimális régióban található, és lassú olvasást/írást eredményez, javasoljuk, hogy konfiguráljon egy integrációs modul használatát egy másik régióban. | |
| Hibatűrés | Ha a hibatűrést konfigurálja, és a nem kompatibilis sorok kihagyása lassú teljesítményt eredményez, javasolja a forrás- és fogadóadatok kompatibilitásának biztosítását. |
| Szakaszos másolat | Ha a szakaszos másolat konfigurálva van, de nem hasznos a forrás-fogadó pár számára, javasoljuk, hogy távolítsa el. |
| Folytatás | Ha a másolási tevékenység az utolsó hibaponttól folytatódik, de az eredeti futtatás után módosítja a DIU-beállítást, vegye figyelembe, hogy az új DIU-beállítás nem lép érvénybe. |
A másolási tevékenység végrehajtásának részleteinek ismertetése
A másolási tevékenység figyelési nézetének alján található végrehajtási adatok és időtartamok a másolási tevékenység főbb szakaszait ismertetik (lásd a cikk elején található példát), amely különösen hasznos a másolási teljesítmény hibaelhárításához. A másolási futtatás szűk keresztmetszete a leghosszabb időtartamú. Tekintse meg az egyes szakaszok definíciójának alábbi táblázatát, és ismerje meg, hogyan háríthatja el a másolási tevékenységeket az Azure IR-ben , és hogyan háríthatja el a saját üzemeltetésű integrációs modul másolási tevékenységeit ilyen információkkal.
| Szakasz | Leírás |
|---|---|
| Várakozási sor | Az eltelt idő, amíg a másolási tevékenység ténylegesen el nem indul az integrációs futtatókörnyezetben. |
| Szkript előzetes másolása | Az integrációs modultól kezdődő másolási tevékenység és a másolási tevékenység közötti eltelt idő, amely befejezi az előmásolási szkript végrehajtását a fogadó adattárban. Alkalmazza az adatbázis-fogadók előzetes másolási szkriptjének konfigurálásakor, például amikor adatokat ír az Azure SQL Database-be, az új adatok másolása előtt törölje a műveletet. |
| Transfer | Az előző lépés vége és az összes adat forrásból fogadóba történő átvitele közötti eltelt idő. Figyelje meg, hogy az átvitel alatt álló allépések párhuzamosan futnak, és néhány művelet most nem jelenik meg, például fájlformátum elemzése/generálása. - Első bájtig eltelt idő: Az előző lépés vége és az az idő, amikor az integrációs modul megkapja az első bájtot a forrásadattárból. Nem fájlalapú forrásokra vonatkozik. - Forrás felsorolása: A forrásfájlok vagy adatpartíciók számbavételével töltött idő. Ez utóbbi az adatbázis-források partíciós beállításainak konfigurálásakor érvényes, például amikor adatokat másol az olyan adatbázisokból, mint az Oracle/SAP HANA/Teradata/Netezza/stb. -Olvasás forrásból: Az adatok forrásadattárból való beolvasásával töltött idő. - Írás fogadóba: Az adatok fogadó adattárba való írásával töltött idő. Vegye figyelembe, hogy egyes összekötők jelenleg nem rendelkeznek ezzel a metrikával, például az Azure AI Search, az Azure Data Explorer, az Azure Table Storage, az Oracle, az SQL Server, a Common Data Service, a Dynamics 365, a Dynamics CRM, a Salesforce/Salesforce Service Cloud. |
Másolási tevékenység hibaelhárítása az Azure IR-ben
Kövesse a teljesítményhangolási lépéseket a forgatókönyv teljesítménytesztjének megtervezéséhez és elvégzéséhez.
Ha a másolási tevékenység teljesítménye nem felel meg a vártnak, az Azure Integration Runtime-on futó egyetlen másolási tevékenység hibaelhárításához, ha teljesítményhangolási tippek jelennek meg a másolásfigyelési nézetben, alkalmazza a javaslatot, és próbálkozzon újra. Ellenkező esetben ismerje meg a másolási tevékenység végrehajtásának részleteit, ellenőrizze, hogy melyik szakaszban van a leghosszabb időtartam, és alkalmazza az alábbi útmutatást a másolási teljesítmény növelése érdekében:
A "másolás előtti szkript" hosszú időtartamot élt át: ez azt jelenti, hogy a fogadó adatbázisban futó előmásolási szkript végrehajtása hosszú időt vesz igénybe. Finomhangolja a megadott, másolás előtti szkriptlogikát a teljesítmény növelése érdekében. Ha további segítségre van szüksége a szkript fejlesztéséhez, forduljon az adatbázis-csapathoz.
A "Transfer – Time to first byte" (Átvitel – Első bájtig) hosszú munkaidőt tapasztalt: ez azt jelenti, hogy a forrás lekérdezés hosszú időt vesz igénybe az adatok visszaadásához. Ellenőrizze és optimalizálja a lekérdezést vagy a kiszolgálót. Ha további segítségre van szüksége, forduljon az adattár csapatához.
Az "Átvitel – Forrás listázása" hosszú munkaidőt tapasztalt: azt jelenti, hogy a forrásfájlok vagy a forrásadatbázis adatpartícióinak felsorolása lassú.
Ha fájlalapú forrásból másol adatokat, ha helyettesítő karaktert használ a mappa elérési útján vagy fájlnevén (
wildcardFolderPathvagywildcardFileName), vagy a legutóbb módosított időszűrőt használja (modifiedDatetimeStartvagymodifiedDatetimeEnd), vegye figyelembe, hogy az ilyen szűrő azt eredményezné, hogy a másolási tevékenység felsorolja a megadott mappa összes fájlját az ügyféloldalon, majd alkalmazza a szűrőt. Az ilyen fájlok számbavétele szűk keresztmetszetté válhat, különösen akkor, ha csak kis fájlok halmaza felel meg a szűrőszabálynak.Ellenőrizze, hogy másolhat-e fájlokat a datetime particionált fájl elérési útja vagy neve alapján. Így nem terheli meg a forrásoldalt.
Ellenőrizze, hogy használhatja-e inkább az adattár natív szűrőjét, pontosabban az Amazon S3/Azure Blob Storage/Azure Files", az ADLS Gen1 "listAfter/listBefore" előtagját. Ezek a szűrők az adattár kiszolgálóoldali szűrői, és sokkal jobb teljesítménnyel rendelkeznek.
Fontolja meg egyetlen nagy adatkészlet több kisebb adatkészletre való felosztását, és hagyja, hogy a másolási feladatok egyidejűleg fussanak az adatok egy részének kezelése érdekében. Ezt a Lookup/GetMetadata + ForEach + Copy billentyűkombinációval teheti meg. Általános példaként tekintse meg a fájlok másolását több tárolóból , vagy az adatok migrálását az Amazon S3-ból az ADLS Gen2-megoldássablonokba .
Ellenőrizze, hogy a szolgáltatás szabályozási hibát jelez-e a forráson, vagy hogy az adattár magas kihasználtsági állapotban van-e. Ha igen, csökkentse a számítási feladatokat az adattárban, vagy forduljon az adattár rendszergazdájához, hogy növelje a szabályozási korlátot vagy az elérhető erőforrást.
Használja az Azure IR-t a forrásadattár régiójában vagy közelében.
Az "Átvitel – olvasás forrásból" hosszú munkaideje volt:
Az összekötőkre vonatkozó adatbetöltési ajánlott eljárások alkalmazása. Ha például adatokat másol az Amazon Redshiftből, konfigurálja a Redshift UNLOAD használatát.
Ellenőrizze, hogy a szolgáltatás szabályozási hibát jelez-e a forráson, vagy hogy az adattár magas kihasználtság alatt áll-e. Ha igen, csökkentse a számítási feladatokat az adattárban, vagy forduljon az adattár rendszergazdájához, hogy növelje a szabályozási korlátot vagy az elérhető erőforrást.
Ellenőrizze a másolási forrást és a fogadómintát:
Ha a másolási minta 4-nél nagyobb adatintegráció egységeket (DIU-kat) támogat, tekintse meg ezt a részleteket ismertető szakaszt, általában megpróbálhatja növelni a DIU-kat a jobb teljesítmény érdekében.
Ellenkező esetben érdemes lehet egyetlen nagy adatkészletet több kisebb adatkészletre osztani, és hagyni, hogy a másolási feladatok egyidejűleg fussanak az adatok egy részén. Ezt a Lookup/GetMetadata + ForEach + Copy billentyűkombinációval teheti meg. Általános példaként tekintse meg a Fájlok másolása több tárolóból, az Adatok migrálása az Amazon S3-ból az ADLS Gen2-be vagy a Tömeges másolás vezérlőtábla-megoldássablonokkal című témakört.
Használja az Azure IR-t a forrásadattár régiójában vagy közelében.
A "Transzfer - írás fogadóba" hosszú munkaidőt tapasztalt:
Az összekötőkre vonatkozó adatbetöltési ajánlott eljárások alkalmazása. Ha például adatokat másol az Azure Synapse Analyticsbe, használja a PolyBase vagy a COPY utasítást.
Ellenőrizze, hogy a szolgáltatás szabályozási hibát jelez-e a fogadóban, vagy hogy az adattár magas kihasználtságban van-e. Ha igen, csökkentse a számítási feladatokat az adattárban, vagy forduljon az adattár rendszergazdájához, hogy növelje a szabályozási korlátot vagy az elérhető erőforrást.
Ellenőrizze a másolási forrást és a fogadómintát:
Ha a másolási minta 4-nél nagyobb adatintegráció egységeket (DIU-kat) támogat, tekintse meg ezt a részleteket ismertető szakaszt, általában megpróbálhatja növelni a DIU-kat a jobb teljesítmény érdekében.
Ellenkező esetben fokozatosan hangolja be a párhuzamos másolatokat, vegye figyelembe, hogy túl sok párhuzamos másolat még a teljesítményt is ronthatja.
Használja az Azure IR-t a fogadó adattár régiójában vagy közelében.
Másolási tevékenység hibaelhárítása saját üzemeltetésű integrációs modulon
Kövesse a teljesítményhangolási lépéseket a forgatókönyv teljesítménytesztjének megtervezéséhez és elvégzéséhez.
Ha a másolási teljesítmény nem felel meg a vártnak, az Azure Integration Runtime-on futó egyetlen másolási tevékenység hibaelhárításához, ha teljesítményhangolási tippek jelennek meg a másolásfigyelési nézetben, alkalmazza a javaslatot, és próbálkozzon újra. Ellenkező esetben ismerje meg a másolási tevékenység végrehajtásának részleteit, ellenőrizze, hogy melyik szakaszban van a leghosszabb időtartam, és alkalmazza az alábbi útmutatást a másolási teljesítmény növelése érdekében:
A "queue" hosszú időtartamot tapasztalt: ez azt jelenti, hogy a másolási tevékenység hosszú ideig várakozik az üzenetsorban, amíg a saját üzemeltetésű integrációs modul rendelkezik végrehajtandó erőforrásokkal. Ellenőrizze az integrációs modul kapacitását és használatát, és skálázza fel vagy skálázza ki a számítási feladatnak megfelelően.
A "Transfer – Time to first byte" (Átvitel – Első bájtig) hosszú munkaidőt tapasztalt: ez azt jelenti, hogy a forrás lekérdezés hosszú időt vesz igénybe az adatok visszaadásához. Ellenőrizze és optimalizálja a lekérdezést vagy a kiszolgálót. Ha további segítségre van szüksége, forduljon az adattár csapatához.
Az "Átvitel – Forrás listázása" hosszú munkaidőt tapasztalt: azt jelenti, hogy a forrásfájlok vagy a forrásadatbázis adatpartícióinak felsorolása lassú.
Ellenőrizze, hogy a saját üzemeltetésű integrációs modul gépe alacsony késéssel csatlakozik-e a forrásadattárhoz. Ha a forrás az Azure-ban található, akkor ezzel az eszközzel ellenőrizheti a saját üzemeltetésű integrációs modultól az Azure-régióig való késést, annál kevésbé.
Ha fájlalapú forrásból másol adatokat, ha helyettesítő karaktert használ a mappa elérési útján vagy fájlnevén (
wildcardFolderPathvagywildcardFileName), vagy a legutóbb módosított időszűrőt használja (modifiedDatetimeStartvagymodifiedDatetimeEnd), vegye figyelembe, hogy az ilyen szűrő azt eredményezné, hogy a másolási tevékenység felsorolja a megadott mappa összes fájlját az ügyféloldalon, majd alkalmazza a szűrőt. Az ilyen fájlok számbavétele szűk keresztmetszetté válhat, különösen akkor, ha csak kis fájlok halmaza felel meg a szűrőszabálynak.Ellenőrizze, hogy másolhat-e fájlokat a datetime particionált fájl elérési útja vagy neve alapján. Így nem terheli meg a forrásoldalt.
Ellenőrizze, hogy használhatja-e inkább az adattár natív szűrőjét, pontosabban az Amazon S3/Azure Blob Storage/Azure Files", az ADLS Gen1 "listAfter/listBefore" előtagját. Ezek a szűrők az adattár kiszolgálóoldali szűrői, és sokkal jobb teljesítménnyel rendelkeznek.
Fontolja meg egyetlen nagy adatkészlet több kisebb adatkészletre való felosztását, és hagyja, hogy a másolási feladatok egyidejűleg fussanak az adatok egy részének kezelése érdekében. Ezt a Lookup/GetMetadata + ForEach + Copy billentyűkombinációval teheti meg. Általános példaként tekintse meg a fájlok másolását több tárolóból , vagy az adatok migrálását az Amazon S3-ból az ADLS Gen2-megoldássablonokba .
Ellenőrizze, hogy a szolgáltatás szabályozási hibát jelez-e a forráson, vagy hogy az adattár magas kihasználtsági állapotban van-e. Ha igen, csökkentse a számítási feladatokat az adattárban, vagy forduljon az adattár rendszergazdájához, hogy növelje a szabályozási korlátot vagy az elérhető erőforrást.
Az "Átvitel – olvasás forrásból" hosszú munkaideje volt:
Ellenőrizze, hogy a saját üzemeltetésű integrációs modul gépe alacsony késéssel csatlakozik-e a forrásadattárhoz. Ha a forrás az Azure-ban található, akkor ezzel az eszközzel ellenőrizheti a helyi integrációs modult futtató gép és az Azure-régiók közötti késést, annál kevésbé.
Ellenőrizze, hogy a saját üzemeltetésű integrációs modul gépe rendelkezik-e elegendő bejövő sávszélességmel az adatok hatékony olvasásához és átviteléhez. Ha a forrásadattár az Azure-ban található, ezzel az eszközzel ellenőrizheti a letöltés sebességét.
Tekintse meg a saját üzemeltetésű integrációs modul processzor- és memóriahasználati trendjét az Azure Portalon –> az adat-előállítóban vagy a Synapse-munkaterületen –> áttekintő oldalon. Fontolja meg az integrációs modul fel- és felskálázását, ha a processzorhasználat magas, vagy a rendelkezésre álló memória alacsony.
Az összekötőkre vonatkozó adatbetöltési ajánlott eljárások alkalmazása. Például:
Az Oracle, a Netezza, a Teradata, az SAP HANA, az SAP Table és az SAP Open Hub adatainak másolásakor engedélyezze az adatpartíciós beállításokat az adatok párhuzamos másolásához.
Amikor adatokat másol a HDFS-ből, konfigurálja a DistCp használatát.
Amikor adatokat másol az Amazon Redshiftből, konfigurálja a Redshift UNLOAD használatát.
Ellenőrizze, hogy a szolgáltatás szabályozási hibát jelez-e a forráson, vagy hogy az adattár magas kihasználtság alatt áll-e. Ha igen, csökkentse a számítási feladatokat az adattárban, vagy forduljon az adattár rendszergazdájához, hogy növelje a szabályozási korlátot vagy az elérhető erőforrást.
Ellenőrizze a másolási forrást és a fogadómintát:
Ha partícióbeállítás-kompatibilis adattárakból másol adatokat, fontolja meg a párhuzamos másolatok fokozatos finomhangolását, vegye figyelembe, hogy a túl sok párhuzamos másolat még a teljesítményt is ronthatja.
Ellenkező esetben érdemes lehet egyetlen nagy adatkészletet több kisebb adatkészletre osztani, és hagyni, hogy a másolási feladatok egyidejűleg fussanak az adatok egy részén. Ezt a Lookup/GetMetadata + ForEach + Copy billentyűkombinációval teheti meg. Általános példaként tekintse meg a Fájlok másolása több tárolóból, az Adatok migrálása az Amazon S3-ból az ADLS Gen2-be vagy a Tömeges másolás vezérlőtábla-megoldássablonokkal című témakört.
A "Transzfer - írás fogadóba" hosszú munkaidőt tapasztalt:
Az összekötőkre vonatkozó adatbetöltési ajánlott eljárások alkalmazása. Ha például adatokat másol az Azure Synapse Analyticsbe, használja a PolyBase vagy a COPY utasítást.
Ellenőrizze, hogy a saját üzemeltetésű integrációs modul gépe alacsony késéssel csatlakozik-e a fogadó adattárhoz. Ha a fogadó az Azure-ban van, akkor ezzel az eszközzel ellenőrizheti a saját üzemeltetésű integrációs modul gépétől az Azure-régióig való késést, annál kevésbé.
Ellenőrizze, hogy a saját üzemeltetésű integrációs modul gépe rendelkezik-e elegendő kimenő sávszélességmel az adatok hatékony átviteléhez és írásához. Ha a fogadóadattár az Azure-ban található, ezzel az eszközzel ellenőrizheti a feltöltés sebességét.
Ellenőrizze, hogy a saját üzemeltetésű integrációs modul processzor- és memóriahasználati trendje az Azure Portalon –> az adat-előállítóban vagy a Synapse-munkaterületen –> áttekintő oldalon található-e. Fontolja meg az integrációs modul fel- és felskálázását, ha a processzorhasználat magas, vagy a rendelkezésre álló memória alacsony.
Ellenőrizze, hogy a szolgáltatás szabályozási hibát jelez-e a fogadóban, vagy hogy az adattár magas kihasználtságban van-e. Ha igen, csökkentse a számítási feladatokat az adattárban, vagy forduljon az adattár rendszergazdájához, hogy növelje a szabályozási korlátot vagy az elérhető erőforrást.
Fontolja meg a párhuzamos példányok fokozatos finomhangolását, vegye figyelembe, hogy túl sok párhuzamos másolat még a teljesítményt is ronthatja.
Csatlakozás or és integrációs modul teljesítménye
Ez a szakasz néhány teljesítmény-hibaelhárítási útmutatót ismertet az adott összekötőtípushoz vagy integrációs modulhoz.
A tevékenységek végrehajtási ideje az Azure IR és az Azure VNet IR használatával változik
A tevékenység végrehajtásának időtartama változó, ha az adathalmaz különböző integrációs modulon alapul.
Tünetek: Az adathalmaz társított szolgáltatás legördülő listájának összesítése ugyanazokat a folyamattevékenységeket hajtja végre, de drasztikusan eltérő futtatási időket tartalmaz. Ha az adathalmaz a felügyelt virtuális hálózati integrációs modulon alapul, átlagosan több időt vesz igénybe, mint az alapértelmezett integrációs modulon alapuló futtatás.
Ok: A folyamatfuttatások részleteinek ellenőrzésekor láthatja, hogy a lassú folyamat felügyelt virtuális hálózat (virtuális hálózat) integrációs modulján fut, míg a normál az Azure IR-en fut. A felügyelt virtuális hálózatok integrációs modulja kialakítás szerint hosszabb várakozási időt vesz igénybe, mint az Azure IR, mivel szolgáltatáspéldányonként nem foglalunk le egy számítási csomópontot, ezért minden másolási tevékenységnek be kell indulnia, és ez elsősorban az Azure IR helyett a VNet-csatlakozáson történik.
Alacsony teljesítmény az adatok Azure SQL Database-be való betöltésekor
Tünetek: Az adatok Azure SQL Database-be való másolása lassúvá válik.
Ok: A probléma kiváltó okát többnyire az Azure SQL Database-oldal szűk keresztmetszete okozza. Az alábbiakban néhány lehetséges oka lehet:
Az Azure SQL Database szintje nem elég magas.
Az Azure SQL Database DTU-használata közel 100%. Figyelheti a teljesítményt, és megfontolhatja az Azure SQL Database-szint frissítését.
Az indexek nincsenek megfelelően beállítva. Távolítsa el az összes indexet az adatbetöltés előtt, és hozza létre újra őket a betöltés után.
A WriteBatchSize nem elég nagy a sémasor méretéhez. Próbálja meg kibővíteni a probléma tulajdonságát.
A tömeges beszúrás helyett tárolt eljárást használnak, amely várhatóan rosszabb teljesítményt nyújt.
Időtúllépés vagy lassú teljesítmény nagy Excel-fájl elemzésekor
Tünetek:
Amikor Excel-adatkészletet hoz létre, és sémát importál a kapcsolatból/tárból, az előnézeti adatokból, a listákból vagy a munkalapok frissítéséből, időtúllépési hibát tapasztalhat, ha az Excel-fájl mérete nagy.
Ha másolási tevékenység használatával másol adatokat nagy Excel-fájlból (>= 100 MB) más adattárakba, lassú teljesítménybeli vagy OOM-problémát tapasztalhat.
Cause:
Az olyan műveletek esetében, mint a séma importálása, az adatok előnézete és a munkalapok felsorolása az Excel-adathalmazon, az időtúllépés 100 s és statikus. Nagy Excel-fájl esetén előfordulhat, hogy ezek a műveletek nem fejeződnek be az időtúllépési értéken belül.
A másolási tevékenység beolvassa a teljes Excel-fájlt a memóriába, majd megkeresi a megadott munkalapot és cellákat az adatok olvasásához. Ez a viselkedés a szolgáltatás alapjául szolgáló SDK-nak köszönhető.
Megoldás:
Séma importálásához létrehozhat egy kisebb mintafájlt, amely az eredeti fájl egy részhalmaza, és a "séma importálása a mintafájlból" lehetőséget választja a "séma importálása kapcsolatból/tárolóból" helyett.
A munkalap listázásához a munkalap legördülő listájában kattintson a "Szerkesztés" gombra, és írja be helyette a munkalap nevét/indexét.
Ha nagy excelfájlt (>100 MB) szeretne más áruházba másolni, használhatja Adatfolyam Excel-forrást, amely a sportstreamelést olvassa, és jobban teljesít.
A nagyméretű JSON-/Excel-/XML-fájlok olvasásával kapcsolatos OOM-probléma
Tünetek: Ha nagy JSON-/Excel-/XML-fájlokat olvas, a tevékenység végrehajtása során a memóriahiány (OOM) problémát tapasztalja.
Cause:
- Nagy XML-fájlok esetén: A nagy XML-fájlok olvasásával kapcsolatos OOM-probléma tervezésből áll. Ennek az az oka, hogy a teljes XML-fájlt be kell olvasni a memóriába, mivel az egyetlen objektum, majd a séma kikövetkeztetett, és az adatok lekérése történik.
- Nagy Excel-fájlok esetén: A nagyméretű Excel-fájlok olvasásának OOM-problémája tervezésből áll. Ennek az az oka, hogy a használt SDK-nak (POI/NPOI) be kell olvasnia a teljes Excel-fájlt a memóriába, majd ki kell következtetnie a sémát, és adatokat kell lekérnie.
- Nagy JSON-fájlok esetén: A nagy JSON-fájlok olvasásának OOM-problémája tervezésből áll, ha a JSON-fájl egyetlen objektum.
Javaslat: A probléma megoldásához alkalmazza az alábbi lehetőségek egyikét.
- 1. lehetőség: Regisztráljon egy online, saját üzemeltetésű integrációs modult nagy teljesítményű géppel (magas PROCESSZOR/memória) a nagy fájlból származó adatok másolási tevékenységen keresztüli beolvasásához.
- 2. lehetőség: Optimalizált memória és nagy méretű fürt (például 48 mag) használatával adatokat olvashat a nagy fájlból a leképezési adatfolyam-tevékenységen keresztül.
- 3. lehetőség: A nagyméretű fájl felosztása kisebbekre, majd másolási vagy leképezési adatfolyam-tevékenységgel olvassa be a mappát.
- 4. lehetőség: Ha az XML/Excel/JSON mappa másolása során elakadt vagy az OOM-problémát tapasztalja, használja a foreach tevékenység + másolási/leképezési adatfolyam-tevékenységet a folyamatban az egyes fájlok vagy almappák kezeléséhez.
- 5. lehetőség: Egyéb:
- XML esetén a jegyzetfüzet-tevékenység és a memóriaoptimalizált fürt használatával olvasson be adatokat a fájlokból, ha mindegyik fájl ugyanazzal a sémával rendelkezik. A Spark jelenleg különböző implementációkkal rendelkezik az XML kezeléséhez.
- JSON esetén használjon különböző dokumentuműrlapokat (például egy dokumentumot, egysoros dokumentumot és dokumentumtömböt) a JSON-beállításokban az adatfolyam-forrás leképezése alatt. Ha a JSON-fájl tartalma dokumentumonként, akkor nagyon kevés memóriát használ fel.
Egyéb referenciák
Íme néhány támogatott adattár teljesítményfigyelési és hangolási hivatkozásai:
- Azure Blob Storage: A Blob Storage méretezhetőségi és teljesítménycéljai, valamint a Blob Storage teljesítmény- és méretezhetőségi ellenőrzőlistája.
- Azure Table Storage: A Table Storage méretezhetőségi és teljesítménycéljai, valamint a Table Storage teljesítmény- és méretezhetőségi ellenőrzőlistája.
- Azure SQL Database: Figyelheti a teljesítményt , és ellenőrizheti az adatbázis-tranzakciós egység (DTU) százalékos arányát.
- Azure Synapse Analytics: A képessége az adattárházegységekben (DWU-kban) mérhető. Lásd: Számítási teljesítmény kezelése az Azure Synapse Analyticsben (áttekintés).
- Azure Cosmos DB: Teljesítményszintek az Azure Cosmos DB-ben.
- SQL Server: Figyelheti és hangolhatja a teljesítményt.
- Helyszíni fájlkiszolgáló: A fájlkiszolgálók teljesítményhangolása.
Kapcsolódó tartalom
Lásd a többi másolási tevékenységről szóló cikket: