Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
Ez a cikk a jegyzetfüzet számítási erőforrásainak lehetőségeit ismerteti. Jegyzetfüzetet futtathat egy teljes körű számítási erőforráson, kiszolgáló nélküli számításon, vagy SQL-parancsokhoz használhat sql-raktárat, amely az SQL Analyticshez optimalizált számítási típus. A számítási típusokról további információt a Számításicímű témakörben talál.
Kiszolgáló nélküli számítás jegyzetfüzetekhez
A kiszolgáló nélküli számítással gyorsan csatlakoztathatja jegyzetfüzetét az igény szerinti számítási erőforrásokhoz.
A kiszolgáló nélküli számításhoz való csatoláshoz kattintson a Csatlakozás legördülő menüre a jegyzetfüzetben, és válassza Kiszolgáló nélkülilehetőséget.
További információkért tekintse meg a jegyzetfüzetek kiszolgáló nélküli számítását .
Automatizált munkamenet-visszaállítás kiszolgáló nélküli jegyzetfüzetekhez
A kiszolgáló nélküli számítás tétlen leállása a folyamatban lévő munka, például a Python változóértékek elvesztését okozhatja a jegyzetfüzetekben. Ennek elkerülése érdekében engedélyezze az automatikus munkamenet-visszaállítást kiszolgáló nélküli jegyzetfüzetekhez.
- Kattintson a felhasználónevére a munkaterület jobb felső sarkában, majd a legördülő listában kattintson a Beállítások gombra.
- A Beállítások oldalsávon válassza a Fejlesztőopciót.
- A Kísérleti funkciók alatt kapcsolja be a kiszolgáló nélküli jegyzetfüzetek automatikus munkamenet-visszaállításának beállítását.
A beállítás engedélyezésével a Databricks pillanatképet állíthat be a kiszolgáló nélküli jegyzetfüzet memóriaállapotára az inaktív állapot megszüntetése előtt. Amikor tétlenség miatti kapcsolat bontás után visszatér egy jegyzetfüzethez, megjelenik egy értesítés a lap tetején. A munkaállapot visszaállításához kattintson az Újracsatlakozás gombra .
Az újracsatlakozáskor a Databricks visszaállítja a teljes munkakörnyezetet, beleértve a következőket:
- Python-változók, függvények és osztálydefiníciók: A jegyzetfüzet Python-oldala megmarad, így nem kell újraimportálnia vagy újraklarálnia.
- Spark-adatkeretek, gyorsítótárazott és ideiglenes nézetek: A betöltött, átalakított vagy gyorsítótárazott adatok (az ideiglenes nézeteket is beleértve) megmaradnak, így elkerülheti a költséges újratöltést vagy az újraszámítást.
- Spark-munkamenet állapota: A Rendszer menti a Spark-szintű konfigurációs beállításokat, az ideiglenes nézeteket, a katalógus módosításait és a felhasználó által definiált függvényeket (UDF-eket), így nem kell alaphelyzetbe állítania őket.
Ez a funkció korlátozásokkal rendelkezik, és nem támogatja a következők visszaállítását:
- 4 napnál régebbi Spark-állapotok
- 50 MB-nál nagyobb Spark-állapotok
- SQL-szkriptekkel kapcsolatos adatok
- Fájlleírók
- Zárolások és egyéb egyidejűségi elemi egységek
- Hálózati kapcsolatok
Jegyzetfüzet csatolása egy teljes célú számítási erőforráshoz
Ha egy jegyzetfüzetet egy általános célú számítási erőforráshoz szeretne csatolni, szüksége van a CSATOLHATÓ engedélyre a számítási erőforráson.
Fontos
Mindaddig, amíg egy jegyzetfüzet egy számítási erőforráshoz van csatolva, minden olyan felhasználó, aki rendelkezik FUTTATÁSI engedéllyel rendelkezik a jegyzetfüzeten, implicit engedéllyel rendelkezik a számítási erőforrás eléréséhez.
Ha jegyzetfüzetet szeretne csatolni egy számítási erőforráshoz, kattintson a jegyzetfüzet eszköztárában lévő számítási választóra , és válassza ki az erőforrást a legördülő menüből.
A menüben a közelmúltban vagy éppen futó, teljes körű számítási és SQL-raktárak közül választhat.

Ha az összes elérhető számítás közül szeretne választani, kattintson a Továbbiak...gombra. Válasszon az elérhető általános számítási vagy SQL-raktárak közül.
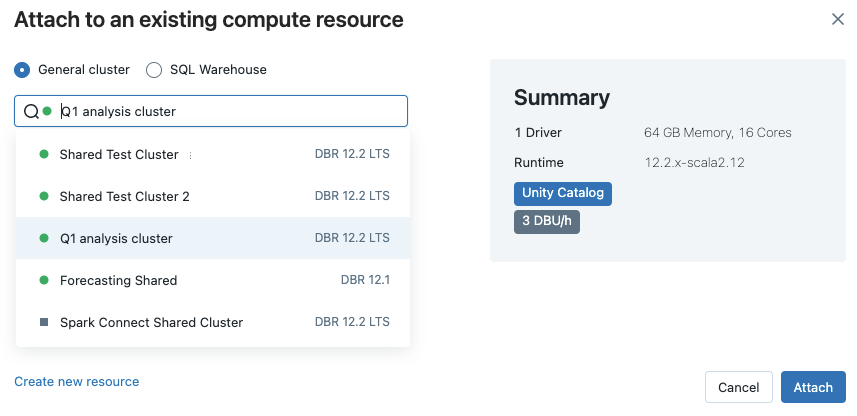
Új, teljes célú számítási erőforrás
Fontos
A csatolt jegyzetfüzetekben a következő Apache Spark-változók vannak definiálva.
| Osztály | Változó neve |
|---|---|
SparkContext |
sc |
SQLContext/HiveContext |
sqlContext |
SparkSession (Spark 2.x) |
spark |
Ne hozzon létre SparkSession, SparkContextvagy SQLContext. Ez inkonzisztens viselkedéshez vezet.
Jegyzetfüzet használata SQL-raktárral
Ha egy jegyzetfüzet egy SQL-raktárhoz van csatolva, sql- és Markdown-cellákat futtathat. Ha bármilyen más nyelven (például Python vagy R) futtat egy cellát, az hibát jelez. Az SQL-raktáron végrehajtott SQL-cellák megjelennek az SQL Warehouse lekérdezési előzményeiben. A lekérdezést végrehajtó felhasználó a kimenet alján lévő eltelt időre kattintva megtekintheti a jegyzetfüzet lekérdezési profilját .
Az SQL Warehouse-hoz csatolt jegyzetfüzetek támogatják az SQL Warehouse-munkameneteket, amelyek lehetővé teszik változók definiálását, ideiglenes nézetek létrehozását és állapotának megőrzését több lekérdezési futtatás során. Ez lehetővé teszi, hogy az SQL-logikát iteratív módon hozza létre anélkül, hogy egyszerre kellene futtatnia az összes utasítást. Lásd : Mik azok az SQL Warehouse-munkamenetek?.
A jegyzetfüzetek futtatásához profi vagy kiszolgáló nélküli SQL-raktárra van szükség. Hozzáféréssel kell rendelkeznie a munkaterülethez és az SQL Warehouse-hoz.
Jegyzetfüzet SQL-raktárhoz való csatolásához tegye a következőket:
Kattintson a számítási választóra a jegyzetfüzet eszköztárán. A legördülő menüben az aktuálisan futó vagy a közelmúltban használt számítási erőforrások láthatók. Az SQL-raktárak jelölése a következővel
 van megjelölve: .
van megjelölve: .A menüben válasszon ki egy SQL Warehouse-t.
Az összes elérhető SQL-raktár megtekintéséhez válassza az Egyebek... lehetőséget a legördülő menüben. Megjelenik egy párbeszédpanel, amelyen a jegyzetfüzethez elérhető számítási erőforrások láthatók. Válassza az SQL Warehouse lehetőséget, válassza ki a használni kívánt raktárat, és kattintson a Csatolás gombra.
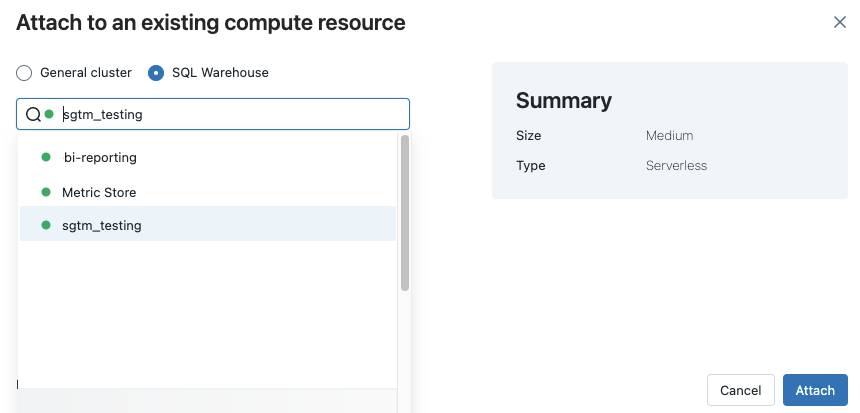
Sql-tárolót is kiválaszthat számítási erőforrásként egy SQL-jegyzetfüzethez munkafolyamat vagy ütemezett feladat létrehozásakor.
SQL Warehouse-korlátozások
További információkért tekintse meg a Databricks-jegyzetfüzetek ismert korlátozásait .