Alkalmazás-Elemzések telemetriai naplók elemzése az Apache Spark on HDInsighttal
Megtudhatja, hogyan elemezheti az Application Insights telemetriai adatait az Apache Spark on HDInsight használatával.
A Visual Studio Application Elemzések egy elemzési szolgáltatás, amely figyeli a webalkalmazásokat. Az Alkalmazás Elemzések által létrehozott telemetriai adatok exportálhatók az Azure Storage-ba. Miután az adatok az Azure Storage-ban találhatók, a HDInsight használható az elemzéshez.
Előfeltételek
Alkalmazás Elemzések használatára konfigurált alkalmazás.
Linux-alapú HDInsight-fürt létrehozásának ismerete. További információ: Apache Spark létrehozása a HDInsighton.
Egy webböngésző.
A dokumentum fejlesztéséhez és teszteléséhez a következő erőforrásokat használták:
Az alkalmazás Elemzések telemetriai adatok az alkalmazás Elemzések használatára konfigurált Node.js webalkalmazással jöttek létre.
Az adatok elemzésére linuxos Spark on HDInsight-fürt 3.5-ös verzióját használták.
Architektúra és tervezés
Az alábbi ábra a példa szolgáltatásarchitektúráját mutatja be:
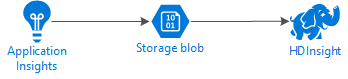
Azure Storage
Az alkalmazás Elemzések konfigurálható úgy, hogy folyamatosan exportálja a telemetriai adatokat a blobokba. A HDInsight ezután képes olvasni a blobokban tárolt adatokat. Van azonban néhány követelmény, amelyet be kell tartania:
Hely: Ha a tárfiók és a HDInsight különböző helyeken található, az növelheti a késést. Emellett növeli a költségeket is, mivel a kimenő díjak a régiók közötti adatforgalomra vonatkoznak.
Figyelmeztetés
A HDInsighttól eltérő helyen lévő tárfiók használata nem támogatott.
Blob típusa: A HDInsight csak a blokkblobokat támogatja. Az alkalmazás alapértelmezés szerint Elemzések blokkblobok használatára, ezért alapértelmezés szerint a HDInsighttal kell működnie.
További információ a tárterület meglévő fürthöz való hozzáadásáról: További tárfiókok hozzáadása dokumentum.
Adatséma
Az alkalmazás Elemzések a blobokra exportált telemetriai adatformátum adatmodelljének adatait tartalmazza. A dokumentum lépései a Spark SQL használatával működnek együtt az adatokkal. A Spark SQL automatikusan létrehozhat egy sémát az alkalmazás Elemzések által naplózott JSON-adatstruktúrához.
Telemetriai adatok exportálása
Kövesse a Folyamatos exportálás konfigurálása című témakör lépéseit az alkalmazás Elemzések konfigurálásához telemetriai adatok Azure Storage-blobba való exportálásához.
A HDInsight konfigurálása az adatok eléréséhez
HDInsight-fürt létrehozásakor adja hozzá a tárfiókot a fürt létrehozásakor.
Az Azure Storage-fiók meglévő fürthöz való hozzáadásához használja a További tárfiókok hozzáadása dokumentumban található információkat.
Az adatok elemzése: PySpark
Egy webböngészőből lépjen arra a
https://CLUSTERNAME.azurehdinsight.net/jupyterhelyre, ahol a FÜRTNÉV a fürt neve.A Jupyter lap jobb felső sarkában válassza az Új, majd a PySpark lehetőséget. Megnyílik egy Python-alapú Jupyter Notebookot tartalmazó új böngészőlap.
A lap első mezőjébe (más néven cellába) írja be a következő szöveget:
sc._jsc.hadoopConfiguration().set('mapreduce.input.fileinputformat.input.dir.recursive', 'true')Ez a kód úgy konfigurálja a Sparkot, hogy rekurzívan hozzáférjen a bemeneti adatok könyvtárszerkezetéhez. Az alkalmazás Elemzések telemetria a következőhöz hasonló címtárstruktúrába
/{telemetry type}/YYYY-MM-DD/{##}/van naplózva.A kód futtatásához használja a SHIFT+ENTER billentyűkombinációt . A cella bal oldalán egy "*" jelenik meg a zárójelek között, amely azt jelzi, hogy a cellában lévő kód végrehajtása folyamatban van. Ha a folyamat befejeződött, a "*" számra változik, és a következő szöveghez hasonló kimenet jelenik meg a cella alatt:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 pyspark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Az első alatt létrejön egy új cella. Írja be a következő szöveget az új cellába. Cserélje le
CONTAINERazSTORAGEACCOUNTAlkalmazás Elemzések adatokat tartalmazó Azure Storage-fiók és blobtároló nevét.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/A cella végrehajtásához használja a SHIFT+ENTER billentyűkombinációt . Az alábbi szöveghez hasonló eredmény jelenik meg:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831A visszaadott wasbs elérési út az alkalmazás Elemzések telemetriai adatok helye. Módosítsa a
hdfs dfs -lscella sorát a visszaadott wasbs elérési út használatára, majd a SHIFT+ENTER billentyűkombinációval futtassa újra a cellát. Az eredményeknek ezúttal a telemetriai adatokat tartalmazó könyvtáraknak kell megjelennie.Feljegyzés
A szakasz lépéseinek hátralévő részében a
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestskönyvtár volt használatban. A címtár szerkezete eltérő lehet.A következő cellába írja be a következő kódot: Cserélje le
WASB_PATHaz előző lépés elérési útjára.jsonFiles = sc.textFile('WASB_PATH') jsonData = sqlContext.read.json(jsonFiles)Ez a kód létrehoz egy adatkeretet a folyamatos exportálási folyamat által exportált JSON-fájlokból. A cella futtatásához használja a SHIFT+ENTER billentyűkombinációt .
A következő cellába írja be és futtassa a következőt a JSON-fájlokhoz létrehozott Spark-séma megtekintéséhez:
jsonData.printSchema()Az egyes telemetriatípusok sémája eltérő. Az alábbi példa a webes kérelmekhez (az
Requestsalkönyvtárban tárolt adatokhoz) létrehozott séma:root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Az alábbi módon regisztrálhatja az adatkeretet ideiglenes táblaként, és lekérdezést futtathat az adatokon:
jsonData.registerTempTable("requests") df = sqlContext.sql("select context.location.city from requests where context.location.city is not null") df.show()Ez a lekérdezés az első 20 rekord városadatait adja vissza, ahol a context.location.city nem null értékű.
Feljegyzés
A környezeti struktúra megtalálható az Alkalmazás Elemzések által naplózott összes telemetriában. Előfordulhat, hogy a városelemet nem tölti ki a naplókban. A sémával azonosíthatja azokat az elemeket, amelyek a naplók adatait tartalmazhatják.
Ez a lekérdezés az alábbi szöveghez hasonló adatokat ad vissza:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Az adatok elemzése: Scala
Egy webböngészőből lépjen arra a
https://CLUSTERNAME.azurehdinsight.net/jupyterhelyre, ahol a FÜRTNÉV a fürt neve.A Jupyter lap jobb felső sarkában válassza az Új, majd a Scala lehetőséget. Megjelenik egy Scala-alapú Jupyter Notebookot tartalmazó új böngészőlap.
A lap első mezőjébe (más néven cellába) írja be a következő szöveget:
sc.hadoopConfiguration.set("mapreduce.input.fileinputformat.input.dir.recursive", "true")Ez a kód úgy konfigurálja a Sparkot, hogy rekurzívan hozzáférjen a bemeneti adatok könyvtárszerkezetéhez. Az alkalmazás telemetriai Elemzések a rendszer egy, a rendszer által hasonló könyvtárstruktúrába naplózza.
/{telemetry type}/YYYY-MM-DD/{##}/A kód futtatásához használja a SHIFT+ENTER billentyűkombinációt . A cella bal oldalán egy "*" jelenik meg a zárójelek között, amely azt jelzi, hogy a cellában lévő kód végrehajtása folyamatban van. Ha a folyamat befejeződött, a "*" számra változik, és a következő szöveghez hasonló kimenet jelenik meg a cella alatt:
Creating SparkContext as 'sc' ID YARN Application ID Kind State Spark UI Driver log Current session? 3 application_1468969497124_0001 spark idle Link Link ✔ Creating HiveContext as 'sqlContext' SparkContext and HiveContext created. Executing user code ...Az első alatt létrejön egy új cella. Írja be a következő szöveget az új cellába. Cserélje le és
STORAGEACCOUNTírja beCONTAINERaz Azure Storage-fiók nevét és a blobtároló nevét, amely alkalmazásnaplókat Elemzések tartalmaz.%%bash hdfs dfs -ls wasbs://CONTAINER@STORAGEACCOUNT.blob.core.windows.net/A cella végrehajtásához használja a SHIFT+ENTER billentyűkombinációt . Az alábbi szöveghez hasonló eredmény jelenik meg:
Found 1 items drwxrwxrwx - 0 1970-01-01 00:00 wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_2bededa61bc741fbdee6b556571a4831A visszaadott wasbs elérési út az alkalmazás Elemzések telemetriai adatok helye. Módosítsa a
hdfs dfs -lscella sorát a visszaadott wasbs elérési út használatára, majd a SHIFT+ENTER billentyűkombinációval futtassa újra a cellát. Az eredményeknek ezúttal a telemetriai adatokat tartalmazó könyvtáraknak kell megjelennie.Feljegyzés
A szakasz lépéseinek hátralévő részében a
wasbs://appinsights@contosostore.blob.core.windows.net/contosoappinsights_{ID}/Requestskönyvtár volt használatban. Ez a könyvtár csak akkor létezik, ha a telemetriai adatok webalkalmazáshoz vannak.A következő cellába írja be a következő kódot: Cserélje le
WASB\_PATHaz előző lépés elérési útjára.var jsonFiles = sc.textFile('WASB_PATH') val sqlContext = new org.apache.spark.sql.SQLContext(sc) var jsonData = sqlContext.read.json(jsonFiles)Ez a kód létrehoz egy adatkeretet a folyamatos exportálási folyamat által exportált JSON-fájlokból. A cella futtatásához használja a SHIFT+ENTER billentyűkombinációt .
A következő cellába írja be és futtassa a következőt a JSON-fájlokhoz létrehozott Spark-séma megtekintéséhez:
jsonData.printSchemaAz egyes telemetriatípusok sémája eltérő. Az alábbi példa a webes kérelmekhez (az
Requestsalkönyvtárban tárolt adatokhoz) létrehozott séma:root |-- context: struct (nullable = true) | |-- application: struct (nullable = true) | | |-- version: string (nullable = true) | |-- custom: struct (nullable = true) | | |-- dimensions: array (nullable = true) | | | |-- element: string (containsNull = true) | | |-- metrics: array (nullable = true) | | | |-- element: string (containsNull = true) | |-- data: struct (nullable = true) | | |-- eventTime: string (nullable = true) | | |-- isSynthetic: boolean (nullable = true) | | |-- samplingRate: double (nullable = true) | | |-- syntheticSource: string (nullable = true) | |-- device: struct (nullable = true) | | |-- browser: string (nullable = true) | | |-- browserVersion: string (nullable = true) | | |-- deviceModel: string (nullable = true) | | |-- deviceName: string (nullable = true) | | |-- id: string (nullable = true) | | |-- osVersion: string (nullable = true) | | |-- type: string (nullable = true) | |-- location: struct (nullable = true) | | |-- city: string (nullable = true) | | |-- clientip: string (nullable = true) | | |-- continent: string (nullable = true) | | |-- country: string (nullable = true) | | |-- province: string (nullable = true) | |-- operation: struct (nullable = true) | | |-- name: string (nullable = true) | |-- session: struct (nullable = true) | | |-- id: string (nullable = true) | | |-- isFirst: boolean (nullable = true) | |-- user: struct (nullable = true) | | |-- anonId: string (nullable = true) | | |-- isAuthenticated: boolean (nullable = true) |-- internal: struct (nullable = true) | |-- data: struct (nullable = true) | | |-- documentVersion: string (nullable = true) | | |-- id: string (nullable = true) |-- request: array (nullable = true) | |-- element: struct (containsNull = true) | | |-- count: long (nullable = true) | | |-- durationMetric: struct (nullable = true) | | | |-- count: double (nullable = true) | | | |-- max: double (nullable = true) | | | |-- min: double (nullable = true) | | | |-- sampledValue: double (nullable = true) | | | |-- stdDev: double (nullable = true) | | | |-- value: double (nullable = true) | | |-- id: string (nullable = true) | | |-- name: string (nullable = true) | | |-- responseCode: long (nullable = true) | | |-- success: boolean (nullable = true) | | |-- url: string (nullable = true) | | |-- urlData: struct (nullable = true) | | | |-- base: string (nullable = true) | | | |-- hashTag: string (nullable = true) | | | |-- host: string (nullable = true) | | | |-- protocol: string (nullable = true)Az alábbi módon regisztrálhatja az adatkeretet ideiglenes táblaként, és lekérdezést futtathat az adatokon:
jsonData.registerTempTable("requests") var city = sqlContext.sql("select context.location.city from requests where context.location.city isn't null limit 10").show()Ez a lekérdezés az első 20 rekord városadatait adja vissza, ahol a context.location.city nem null értékű.
Feljegyzés
A környezeti struktúra megtalálható az Alkalmazás Elemzések által naplózott összes telemetriában. Előfordulhat, hogy a városelemet nem tölti ki a naplókban. A sémával azonosíthatja azokat az elemeket, amelyek a naplók adatait tartalmazhatják.
Ez a lekérdezés az alábbi szöveghez hasonló adatokat ad vissza:
+---------+ | city| +---------+ | Bellevue| | Redmond| | Seattle| |Charlotte| ... +---------+
Következő lépések
Az Apache Spark azure-beli adatokkal és szolgáltatásokkal való használatára vonatkozó további példákért tekintse meg a következő dokumentumokat:
- Apache Spark bi-val: Interaktív adatelemzés végrehajtása a Spark in HDInsight használatával BI-eszközökkel
- Apache Spark gépi Tanulás: A Spark használata a HDInsightban az épülethőmérséklet HVAC-adatokkal történő elemzéséhez
- Apache Spark gépi Tanulás: A Spark használata a HDInsightban az élelmiszer-ellenőrzési eredmények előrejelzéséhez
- Webhelynapló-elemzés az Apache Spark használatával a HDInsightban
A Spark-alkalmazások létrehozásával és futtatásával kapcsolatos információkért tekintse meg a következő dokumentumokat: