Szemantikai rangsorolás az Azure AI Searchben
Az Azure AI Searchben a szemantikai rangsorolás mérhetően javítja a keresés relevanciáját a keresési eredmények nyelvfelismeréssel történő ismételt felhasználásával. Ez a cikk egy magas szintű bevezetés. A végén található szakasz a rendelkezésre állást és a díjszabást ismerteti.
A szemantikai rangsoroló egy prémium szolgáltatás, amelyet használat alapján számlázunk ki. Ezt a cikket a háttérhez ajánljuk, de ha inkább az első lépéseket szeretné elvégezni, kövesse az alábbi lépéseket:
- Regionális rendelkezésre állás ellenőrzése
- Jelentkezzen be az Azure Portalra annak ellenőrzéséhez, hogy a keresési szolgáltatás alapszintű vagy magasabb szintű-e
- Szemantikai rangsorolás engedélyezése és díjszabási csomag kiválasztása
- Szemantikai konfiguráció beállítása keresési indexben
- Lekérdezések beállítása szemantikai képaláírás és kiemelések visszaadására
- Ha szükséges, szemantikai válaszokat ad vissza
Feljegyzés
A szemantikai rangsorolás nem használ generatív AI-t vagy vektorokat. Ha vektortámogatást és hasonlósági keresést keres? Részletekért tekintse meg az Azure AI Search vektorkeresését.
Mi az a szemantikai rangsor?
A szemantikai rangsoroló olyan lekérdezéssel kapcsolatos képességek gyűjteménye, amelyek javítják a szövegalapú lekérdezések kezdeti BM25- vagy RRF-rangsorolt keresési eredményeinek minőségét. Ha engedélyezi a keresési szolgáltatásban, a szemantikai rangsorolás kétféleképpen terjeszti ki a lekérdezés-végrehajtási folyamatot:
Először másodlagos rangsort ad hozzá egy kezdeti eredményhalmazhoz, amelyet BM25 vagy RRF használatával pontoznak. Ez a másodlagos rangsor a Microsoft Bingből adaptált többnyelvű mélytanulási modelleket használja a szemantikailag legrelevánsabb eredmények népszerűsítéséhez.
Másodszor kinyeri és visszaadja a válaszban szereplő képaláírás és válaszokat, amelyeket megjeleníthet egy keresési oldalon a felhasználó keresési élményének javítása érdekében.
Íme a szemantikai reranker képességei.
| Funkció | Leírás |
|---|---|
| Szemantikai rangsorolás | A lekérdezés kontextusát vagy szemantikai jelentését használja egy új relevanciapont kiszámításához az előre megadott eredményekhez. |
| Szemantikai képaláírás és kiemelések | Szó szerinti mondatokat és kifejezéseket nyer ki egy dokumentumból, amely a legjobban összefoglalja a tartalmat, és kiemeli a főbb részeket a könnyű vizsgálat érdekében. Az eredményeket összegző feliratok akkor hasznosak, ha az egyes tartalommezők túl sűrűek a keresési eredmények oldalához. A kiemelt szöveg megemeli a legrelevánsabb kifejezéseket és kifejezéseket, hogy a felhasználók gyorsan megállapíthassák, miért tekintették relevánsnak egyezést. |
| Szemantikai válaszok | Egy szemantikai lekérdezésből visszaadott opcionális és extra alstruktúra. Közvetlen választ ad egy kérdésnek tűnő lekérdezésre. Megköveteli, hogy egy dokumentumnak a válasz jellemzőivel rendelkező szöveggel kell rendelkeznie. |
A szemantikai rangsoroló működése
A szemantikai rangsorolás lekérdezéseket és eredményeket ad a Microsoft által üzemeltetett nyelvfelismerési modellekhez, és jobb találatokat keres.
Az alábbi ábra a koncepciót ismerteti. Vegye figyelembe a "tőke" kifejezést. Különböző jelentéssel rendelkezik attól függően, hogy a kontextus pénzügyi, jogi, földrajzi vagy nyelvtani. A nyelvi megértés révén a szemantikai rangsoroló képes észlelni a kontextust, és előléptetni a lekérdezési szándéknak megfelelő eredményeket.
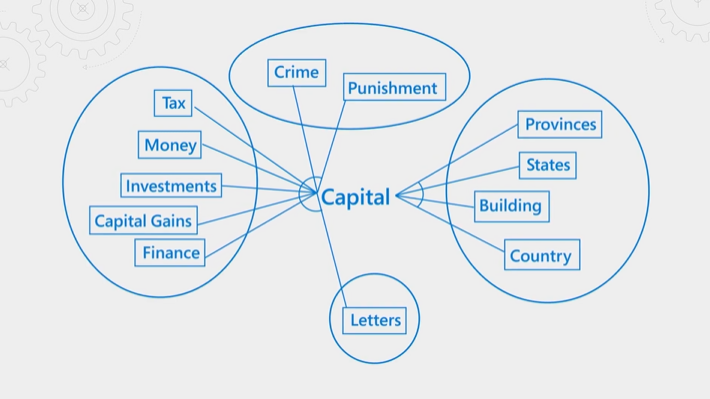
A szemantikai rangsorolás erőforrás- és időigényes is. Annak érdekében, hogy a lekérdezési művelet várt késésén belül befejeződjön a feldolgozás, a szemantikai rangsoroló bemenetei összevonódnak és csökkennek, hogy az újrarankálási lépés a lehető leggyorsabban befejeződhessen.
A szemantikai rangsorolásnak két lépése van: összegzés és pontozás. A kimenetek ismételten rögzített eredményekből, képaláírás és válaszokból állnak.
A bemenetek gyűjtése és összegzése
A szemantikai rangsorolásban a lekérdezési alrendszer a keresési eredményeket adja át az összegzési és rangsorolási modellek bemeneteként. Mivel a rangsorolási modellek bemeneti méretkorlátokkal rendelkeznek, és intenzíven dolgoznak fel, a keresési eredményeknek méretezve és strukturálva kell lenniük (összegezve) a hatékony kezelés érdekében.
A szemantikai rangsorolás egy szöveges lekérdezésből származó BM25-rangsorolt eredménnyel kezdődik, vagy egy hibrid lekérdezés RRF-rangsorolt eredményével . Az újraküldési gyakorlatban csak szövegmezőket használnak, és csak az első 50 találat halad át a szemantikai rangsorolásig, még akkor is, ha az eredmények 50-nél több találatot tartalmaznak. A szemantikai rangsorban használt mezők általában tájékoztatóak és leíróak.
A keresési eredményekben szereplő összesítő modell legfeljebb 2000 tokent fogad el, ahol egy jogkivonat körülbelül 10 karakterből áll. A bemenetek a szemantikai konfigurációban felsorolt "title", "keyword" és "content" mezőkből állnak össze.
A túlzottan hosszú sztringek levágása biztosítja, hogy a teljes hossz megfeleljen az összegzési lépés bemeneti követelményeinek. Ez a vágási gyakorlat miatt fontos mezőket hozzáadni a szemantikai konfigurációhoz prioritási sorrendben. Ha nagyon nagy méretű dokumentumokkal rendelkezik, amelyekben nagy a szöveges mezők száma, a maximális korlátot követő összes dokumentum figyelmen kívül lesz hagyva.
Szemantikai mező Jogkivonat korlátja "cím" 128 token "kulcsszavak 128 token "tartalom" fennmaradó jogkivonatok Az összegző kimenet egy összegző sztring minden dokumentumhoz, amely az egyes mezők legfontosabb információiból áll. Az összefoglaló sztringek a rangsorolóhoz kerülnek a pontozáshoz, valamint a gépi olvasási szövegértési modellekhez képaláírás és válaszok esetében.
A szemantikai rangsorolónak átadott összes generált összesítő sztring maximális hossza 256 jogkivonat.
Szemantikai rangsoroló kimenetei
Az összesítő sztringben a gépi olvasási szövegértési modellek a leginkább reprezentatív részeket találják meg.
A kimenetek a következők:
Szemantikai képaláírás a dokumentumhoz. Minden képaláírás egyszerű szöveges és kiemelt verzióban érhető el, és dokumentumonként gyakran kevesebb, mint 200 szó.
Nem kötelező szemantikai válasz, feltéve, hogy megadta a
answersparamétert, a lekérdezés kérdésként jelent meg, és egy szakasz található a hosszú sztringben, amely valószínűleg választ ad a kérdésre.
A feliratok és válaszok mindig szó szerinti szövegként jelennek meg az indexből. Ebben a munkafolyamatban nincs olyan generatív AI-modell, amely új tartalmat hoz létre vagy állít össze.
Összegzések pontszámának beállítása
A pontozás a képaláírás, valamint az összegző sztring minden olyan tartalma, amely kitölti a 256-os jogkivonat hosszát.
A feliratok a megadott lekérdezéshez képest fogalmi és szemantikai relevancia alapján lesznek kiértékelve.
Minden dokumentumhoz egy @search.rerankerScore van hozzárendelve a dokumentum szemantikai relevanciája alapján az adott lekérdezéshez. A pontszámok 4 és 0 között (magastól alacsonyig) terjednek, ahol a magasabb pontszám nagyobb relevanciát jelez.
Az egyezések csökkenő sorrendben jelennek meg pontszám alapján, és szerepelnek a lekérdezési válasz hasznos adatai között. A hasznos adatok közé tartoznak a válaszok, az egyszerű szöveg és a kiemelt képaláírás, valamint a beolvashatóként megjelölt vagy a kijelölési záradékban megadott mezők.
Feljegyzés
2023 . július 14-től a @search.rerankerScore eloszlása módosul. A pontszámokra gyakorolt hatás csak teszteléssel határozható meg. Ha a választulajdonsághoz szigorú küszöbérték-függőség kapcsolódik, futtassa újra a teszteket, hogy megértse, mi legyen az új érték a küszöbértékhez.
Szemantikai képességek és korlátozások
A szemantikai rangsoroló egy újabb technológia, ezért fontos elvárásokat támasztani azzal kapcsolatban, hogy mit tehet és mit nem. A következő műveletekre képes:
Az eredeti lekérdezés szándékához szemantikusan közelebb álló egyezések előléptetése.
Keresse meg a képaláírás és válaszként használandó sztringeket. A válaszban feliratok és válaszok jelennek meg, és megjeleníthetők a keresési eredmények oldalán.
Amit a szemantikai rangsorolás nem tud megtenni, az az, hogy újrafuttassa a lekérdezést a teljes korpuszon, hogy szemantikailag releváns eredményeket találjon. A szemantikai rangsorolás a meglévő eredményhalmazt irányítja át, amely az alapértelmezett rangsorolási algoritmus által elért 50 legjobb eredményből áll. Emellett a szemantikai rangsorolás nem hozhat létre új információkat vagy sztringeket. A feliratok és válaszok szó szerint kinyerhetők a tartalomból, így ha az eredmények nem tartalmaznak válaszszerű szöveget, a nyelvi modellek nem hoznak létre egyet.
Bár a szemantikai rangsorolás nem minden esetben előnyös, bizonyos tartalmak jelentősen kihasználhatják képességeiket. A szemantikai rangsorban szereplő nyelvi modellek a legjobban az információban gazdag és prózaként strukturált kereshető tartalmakon működnek a legjobban. Egy leíró tartalmat tartalmazó tudásbázis, online dokumentáció vagy dokumentum a szemantikai rangsorolási képességekből származó legnagyobb nyereséget látja.
Az alapul szolgáló technológia a Bing és a Microsoft Research szolgáltatásból származik, és bővítményként integrálható az Azure AI Search-infrastruktúrába. A szemantikai rangsorolást alátámasztó kutatásokkal és AI-befektetéssel kapcsolatos további információkért lásd : Hogyan működik a Bing AI-ból az Azure AI Search (Microsoft Research Blog).
Az alábbi videó áttekintést nyújt a képességekről.
Rendelkezésre állás és díjszabás
A szemantikai rangsoroló az alapszintű és a magasabb szintű keresési szolgáltatásokban érhető el, a regionális rendelkezésre állás függvényében.
Ha engedélyezi a szemantikai rangsorolót, válasszon egy tarifacsomagot a funkcióhoz:
- Alacsonyabb lekérdezési kötetek esetén (havonta 1000 alatt) a szemantikai rangsor ingyenes.
- Nagyobb lekérdezési kötetek esetén válassza ki a standard tarifacsomagot.
Az Azure AI Search díjszabási oldala a különböző pénznemek és intervallumok számlázási arányát mutatja.
A szemantikai rangsorolás díjai akkor merülnek fel, ha a lekérdezési kérések belefoglalnak queryType=semantic , és a keresési sztring nem üres (például search=pet friendly hotels in New York). Ha a keresési sztring üres (search=*), akkor sem kell fizetnie, még akkor sem, ha a queryType szemantikai értékre van állítva.