Apache Spark-feladatdefiníció létrehozása a Fabricben
Ebben az oktatóanyagban megtudhatja, hogyan hozhat létre Spark-feladatdefiníciót a Microsoft Fabricben.
Előfeltételek
A kezdés előtt a következőkre lesz szüksége:
- Aktív előfizetéssel rendelkező Fabric-bérlői fiók. Fiók ingyenes létrehozása.
Tipp.
A Spark-feladatdefiníciós elem futtatásához rendelkeznie kell egy fődefiníciós fájllal és az alapértelmezett lakehouse-környezettel. Ha nem rendelkezik tóházzal, létrehozhat egyet a Tóház létrehozása című témakörben leírt lépéseket követve.
Spark-feladatdefiníció létrehozása
A Spark-feladatdefiníció létrehozásának folyamata gyors és egyszerű; az első lépések többféleképpen is elérhetők.
Spark-feladatdefiníció létrehozásának lehetőségei
A létrehozási folyamat többféleképpen is elkezdhető:
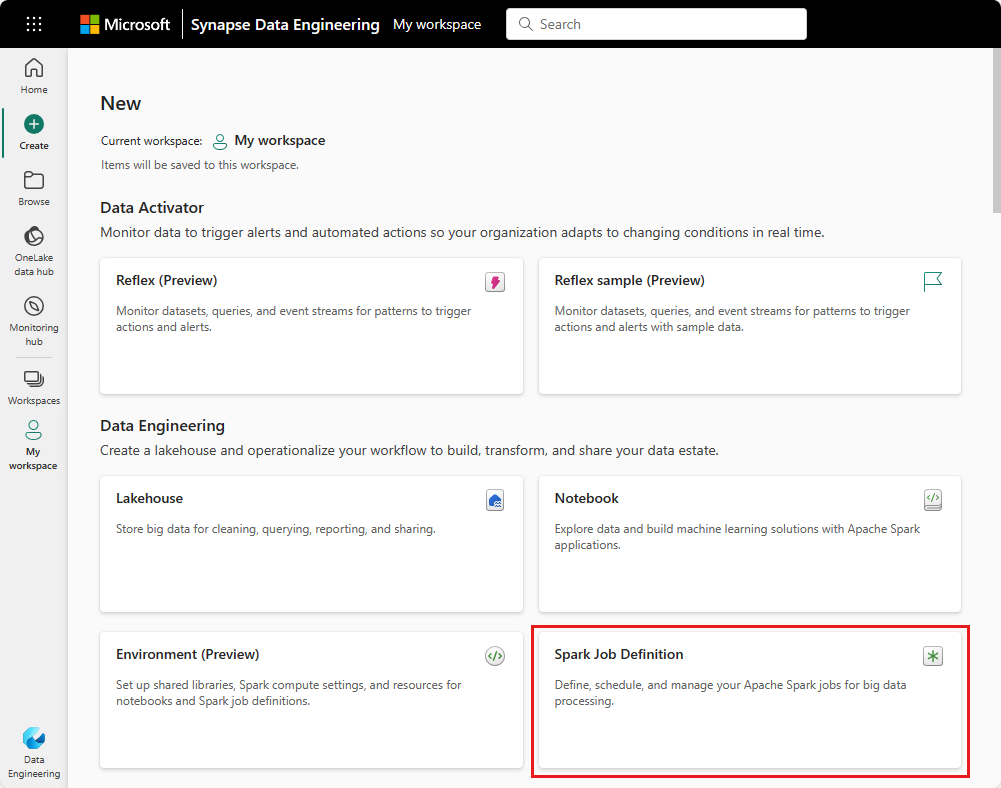
Adatmérnöki kezdőlap: Egyszerűen létrehozhat Spark-feladatdefiníciót a Spark-feladatdefiníciós kártyán keresztül a kezdőlap Új szakaszában.
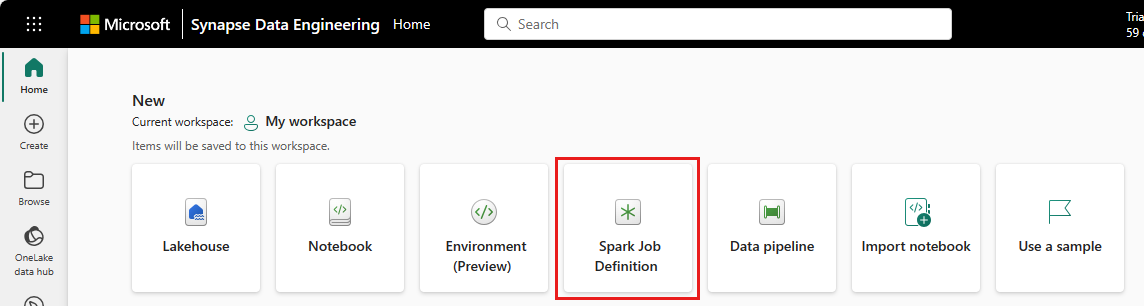
Munkaterület nézet: A Spark-feladatdefiníciót a Munkaterület nézetben is létrehozhatja, ha adatmérnök az Új legördülő menüvel.
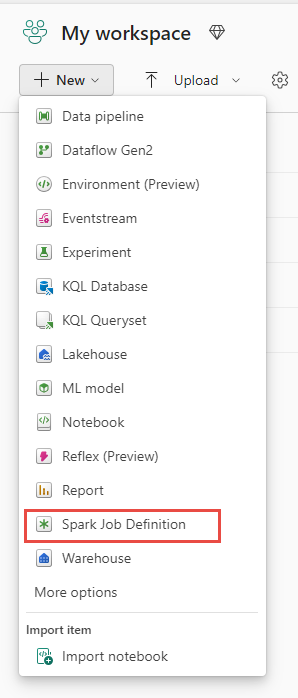
Létrehozási nézet: Egy Spark-feladatdefiníció létrehozásához egy másik belépési pont a Létrehozás lap adatmérnök alatt.
A Létrehozáskor nevet kell adnia a Spark-feladatdefiníciónak. A névnek egyedinek kell lennie az aktuális munkaterületen belül. Az új Spark-feladatdefiníció az aktuális munkaterületen jön létre.
Spark-feladatdefiníció létrehozása a PySparkhoz (Python)
Spark-feladatdefiníció létrehozása a PySparkhoz:
Töltse le a minta CSV-fájlt yellow_tripdata_2022_01.csv , és töltse fel a lakehouse fájlszakaszába.
Hozzon létre egy új Spark-feladatdefiníciót.
Válassza a PySpark (Python) lehetőséget a Nyelv legördülő listából.
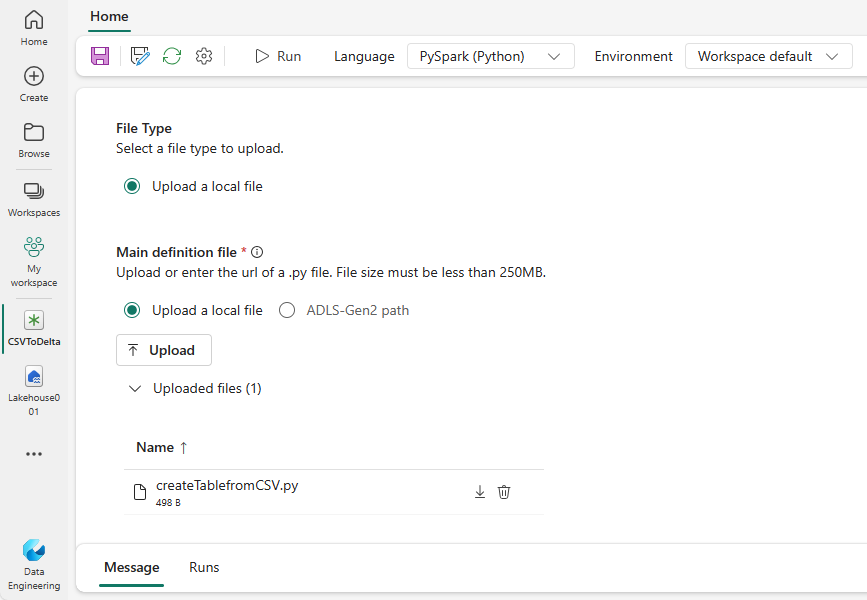
Töltse le a createTablefromCSV.py mintát, és töltse fel fő definíciós fájlként. A fő definíciós fájl (feladat. Fő) az alkalmazáslogikát tartalmazó fájl, amely kötelező a Spark-feladatok futtatásához. Minden Spark-feladatdefinícióhoz csak egy fő definíciós fájlt tölthet fel.
Feltöltheti a fő definíciós fájlt a helyi asztalról, vagy feltöltheti egy meglévő Azure Data Lake Storage (ADLS) Gen2-ből a fájl teljes ABFSS-elérési útjának megadásával. Például:
abfss://your-storage-account-name.dfs.core.windows.net/your-file-path.Referenciafájlok feltöltése .py fájlokként. A referenciafájlok a fő definíciós fájl által importált Python-modulok. A fő definíciós fájlhoz hasonlóan az asztalról vagy egy meglévő ADLS Gen2-ből is feltölthet. Több referenciafájl is támogatott.
Tipp.
Ha ADLS Gen2 elérési utat használ, hogy a fájl elérhető legyen, a feladatot futtató felhasználói fióknak megfelelő engedélyt kell adnia a tárfióknak. Ennek két különböző módját javasoljuk:
- A felhasználói fiók hozzárendelése közreműködői szerepkörhöz a tárfiókhoz.
- Adjon olvasási és végrehajtási engedélyt a fájl felhasználói fiókjának az ADLS Gen2 hozzáférés-vezérlési listáján (ACL) keresztül.
Manuális futtatás esetén a rendszer az aktuális bejelentkezési felhasználó fiókját használja a feladat futtatásához.
Szükség esetén adja meg a feladat parancssori argumentumait. Az argumentumok elválasztásához használjon szóközt osztóként.
Adja hozzá a lakehouse-hivatkozást a feladathoz. A feladathoz legalább egy lakehouse-referenciát hozzá kell adni. Ez a lakehouse a feladat alapértelmezett lakehouse-környezete.
Több lakehouse-hivatkozás is támogatott. A Spark Gépház lapon keresse meg a nem alapértelmezett lakehouse-nevet és a teljes OneLake URL-címet.
Spark-feladatdefiníció létrehozása a Scalához/Java-hoz
Spark-feladatdefiníció létrehozása a Scalához/Java-hoz:
Hozzon létre egy új Spark-feladatdefiníciót.
Válassza a Spark(Scala/Java) lehetőséget a Nyelv legördülő listából.
Töltse fel a fő definíciós fájlt .jar fájlként. A fő definíciós fájl az a fájl, amely tartalmazza a feladat alkalmazáslogikát, és kötelező a Spark-feladat futtatásához. Minden Spark-feladatdefinícióhoz csak egy fő definíciós fájlt tölthet fel. Adja meg a főosztály nevét.
Referenciafájlok feltöltése .jar fájlokként. A referenciafájlok a fő definíciós fájl által hivatkozott/importált fájlok.
Szükség esetén adja meg a feladat parancssori argumentumait.
Adja hozzá a lakehouse-hivatkozást a feladathoz. A feladathoz legalább egy lakehouse-referenciát hozzá kell adni. Ez a lakehouse a feladat alapértelmezett lakehouse-környezete.
Spark-feladatdefiníció létrehozása az R-hez
Spark-feladatdefiníció létrehozása a SparkR(R) számára:
Hozzon létre egy új Spark-feladatdefiníciót.
Válassza a SparkR(R) elemet a Nyelv legördülő listából.
Töltse fel a fő definíciós fájlt . R fájl. A fő definíciós fájl az a fájl, amely tartalmazza a feladat alkalmazáslogikát, és kötelező a Spark-feladat futtatásához. Minden Spark-feladatdefinícióhoz csak egy fő definíciós fájlt tölthet fel.
Referenciafájlok feltöltése a következőként : . R-fájlok . A referenciafájlok a fő definíciós fájl által hivatkozott/importált fájlok.
Szükség esetén adja meg a feladat parancssori argumentumait.
Adja hozzá a lakehouse-hivatkozást a feladathoz. A feladathoz legalább egy lakehouse-referenciát hozzá kell adni. Ez a lakehouse a feladat alapértelmezett lakehouse-környezete.
Feljegyzés
A Spark-feladat definíciója az aktuális munkaterületen jön létre.
A Spark-feladatdefiníciók testreszabásának lehetőségei
A Spark-feladatdefiníciók végrehajtásának további testreszabására is van lehetőség.
- Spark Compute: A Spark Compute lapon a feladat futtatásához használt Futtatókörnyezet verziója látható. Láthatja a Spark konfigurációs beállításait is, amelyek a feladat futtatásához lesznek használva. A Spark konfigurációs beállításait a Hozzáadás gombra kattintva szabhatja testre.
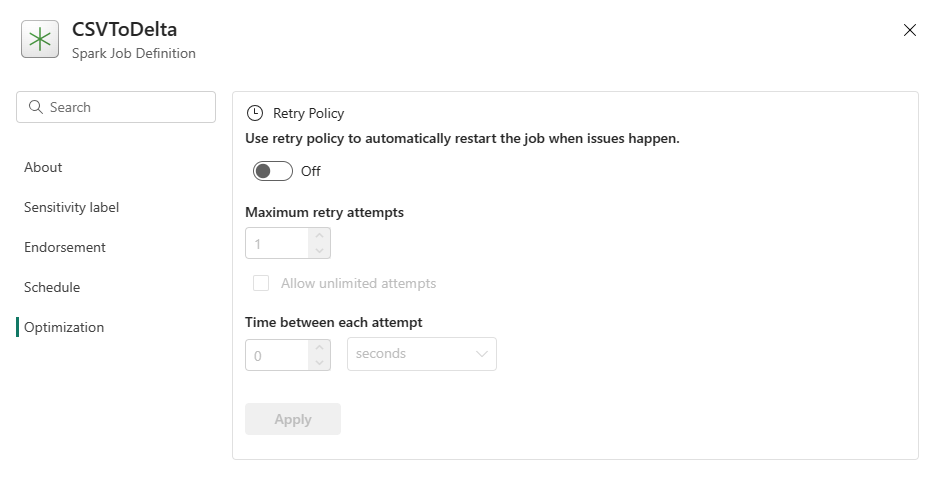
Optimalizálás: Az Optimalizálás lapon engedélyezheti és beállíthatja a feladat újrapróbálkozási szabályzatát . Ha engedélyezve van, a feladat újrapróbálkozott, ha nem sikerül. Az újrapróbálkozések maximális számát és az újrapróbálkozási időközt is beállíthatja. Minden újrapróbálkozási kísérletnél a feladat újraindul. Győződjön meg arról, hogy a feladat idempotens.
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: