Streamelési adatok lekérése a Lakehouse-ba és hozzáférés az SQL Analytics-végponttal
Ez a rövid útmutató bemutatja, hogyan hozhat létre olyan Spark-feladatdefiníciót, amely Python-kódot tartalmaz a Spark Structured Streaming szolgáltatással, hogy adatokat helyezzen el egy tóházban, majd egy SQL Analytics-végponton keresztül szolgálhassa ki őket. A rövid útmutató elvégzése után egy Spark-feladatdefinícióval rendelkezik, amely folyamatosan fut, és az SQL Analytics-végpont megtekintheti a bejövő adatokat.
Python-szkript létrehozása
Használja az alábbi Python-kódot, amely a Spark strukturált streamelését használja az adatok lakehouse-táblában való lekéréséhez.
import sys from pyspark.sql import SparkSession if __name__ == "__main__": spark = SparkSession.builder.appName("MyApp").getOrCreate() tableName = "streamingtable" deltaTablePath = "Tables/" + tableName df = spark.readStream.format("rate").option("rowsPerSecond", 1).load() query = df.writeStream.outputMode("append").format("delta").option("path", deltaTablePath).option("checkpointLocation", deltaTablePath + "/checkpoint").start() query.awaitTermination()Mentse a szkriptet Python-fájlként (.py) a helyi számítógépen.
Tóház létrehozása
A következő lépésekkel hozhat létre egy tóházat:
A Microsoft Fabricben válassza a Synapse adatmérnök ing felületet.
Lépjen a kívánt munkaterületre, vagy szükség esetén hozzon létre egy újat.
Tóház létrehozásához válassza a Lakehouse ikont a fő panel Új szakasza alatt.
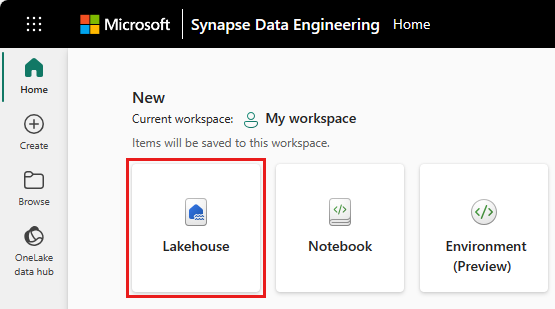
Adja meg a tóház nevét, és válassza a Létrehozás lehetőséget.
Spark-feladatdefiníció létrehozása
Spark-feladatdefiníció létrehozásához kövesse az alábbi lépéseket:
Ugyanazon a munkaterületen, ahol létrehozott egy tóházat, válassza a Létrehozás ikont a bal oldali menüből.
A "adatmérnök" területen válassza a Spark-feladatdefiníciót.
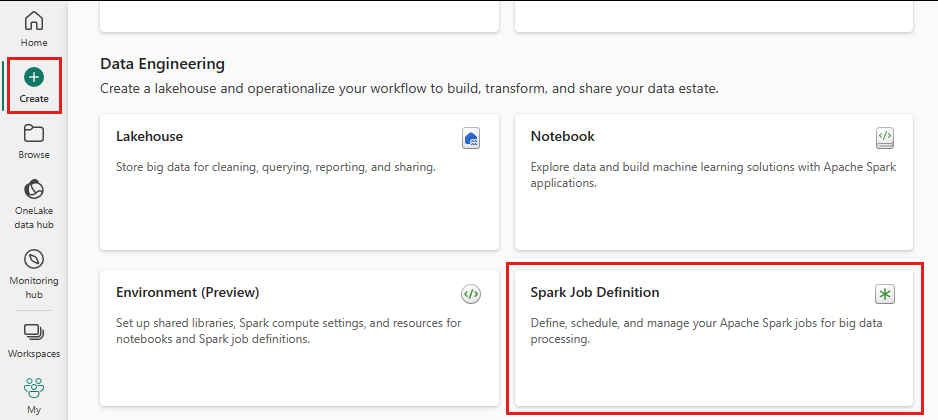
Adja meg a Spark-feladatdefiníció nevét, és válassza a Létrehozás lehetőséget.
Válassza a Feltöltés lehetőséget, és válassza ki az előző lépésben létrehozott Python-fájlt.
A Lakehouse-referencia csoportban válassza ki a létrehozott tóházat.
Újrapróbálkozési szabályzat beállítása Spark-feladatdefinícióhoz
Az alábbi lépésekkel állíthatja be a Spark-feladat definíciójához tartozó újrapróbálkozési szabályzatot:
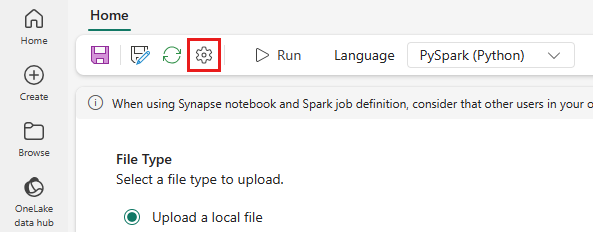
A felső menüben válassza a Beállítás ikont.
Nyissa meg az Optimalizálás lapot, és állítsa be az Újrapróbálkozási szabályzat eseményindítót.
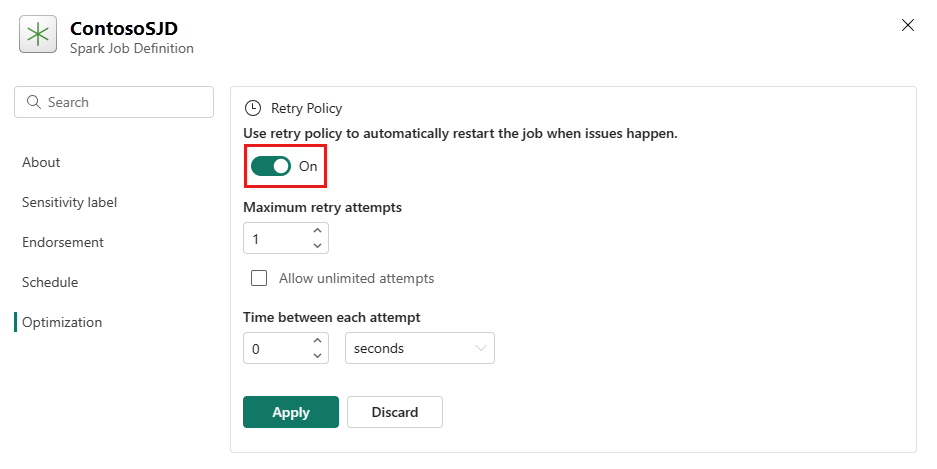
Adja meg a maximális újrapróbálkozási kísérleteket, vagy ellenőrizze a Korlátlan kísérletek engedélyezése jelölőnégyzetet.
Adja meg az egyes újrapróbálkozási kísérletek közötti időt, és válassza az Alkalmaz lehetőséget.
Megjegyzés:
Az újrapróbálkozási szabályzat beállításának élettartama 90 nap. Az újrapróbálkozási szabályzat engedélyezése után a feladat a szabályzatnak megfelelően 90 napon belül újraindul. Ezen időszak után az újrapróbálkozási szabályzat automatikusan megszűnik, és a feladat leáll. A felhasználóknak ezután manuálisan újra kell indítaniuk a feladatot, ami viszont újra engedélyezi az újrapróbálkozési szabályzatot.
A Spark-feladat definíciójának végrehajtása és figyelése
A felső menüben válassza a Futtatás ikont.
Ellenőrizze, hogy a Spark-feladat definíciója sikeresen el lett-e küldve, és fut-e.
Adatok megtekintése SQL Analytics-végpont használatával
Munkaterület nézetben válassza ki a Lakehouse-t.
A jobb sarokban válassza a Lakehouse lehetőséget , és válassza az SQL Analytics-végpontot.
A Táblák alatti SQL Analytics-végpont nézetben válassza ki azt a táblát, amelyet a szkript az adatok lehozásához használ. Ezután megtekintheti az adatokat az SQL Analytics-végponton.
Kapcsolódó tartalom
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: