Adatok elemzése az Apache Spark és a Python használatával
Ebben az oktatóanyagban megtudhatja, hogyan végezhet feltáró adatelemzést az Azure Open Datasets és az Apache Spark használatával.
Különösen a New York City (NYC) Taxi adatkészletet fogjuk elemezni. Az adatok az Azure Open Datasetsen keresztül érhetők el. Az adatkészlet ezen részhalmaza információkat tartalmaz a sárga taxis utakról: az egyes utazásokról, a kezdési és befejezési időpontokról és helyekről, a költségekről és egyéb érdekes attribútumokról.
Előfeltételek
Microsoft Fabric-előfizetés lekérése. Vagy regisztráljon egy ingyenes Microsoft Fabric-próbaverzióra.
A kezdőlap bal oldalán található élménykapcsolóval válthat a Synapse Adattudomány felületre.

Az adatok letöltése és előkészítése
Jegyzetfüzet létrehozása a PySpark használatával. Útmutatásért lásd: Jegyzetfüzet létrehozása.
Feljegyzés
A PySpark kernel miatt nem kell explicit módon létrehoznia a környezeteket. A Spark-környezet automatikusan létrejön az első kódcella futtatásakor.
Ebben az oktatóanyagban több különböző kódtárat használunk az adathalmaz vizualizációjának segítéséhez. Az elemzés elvégzéséhez importálja a következő kódtárakat:
import matplotlib.pyplot as plt import seaborn as sns import pandas as pdMivel a nyers adatok Parquet formátumúak, a Spark-környezettel közvetlenül DataFrame-ként lekérheti a fájlt a memóriába. Spark DataFrame létrehozása az adatok Open Datasets API-val történő beolvasásával. Itt a Spark DataFrame sémát használjuk olvasási tulajdonságokra az adattípusok és a séma következtetéséhez.
from azureml.opendatasets import NycTlcYellow end_date = parser.parse('2018-06-06') start_date = parser.parse('2018-05-01') nyc_tlc = NycTlcYellow(start_date=start_date, end_date=end_date) nyc_tlc_pd = nyc_tlc.to_pandas_dataframe() df = spark.createDataFrame(nyc_tlc_pd)Az adatok beolvasása után először szűrni szeretnénk az adathalmazt. Eltávolíthatjuk a szükségtelen oszlopokat, és fontos információkat kinyerő oszlopokat adhatunk hozzá. Emellett kiszűrjük az adathalmazon belüli anomáliákat.
# Filter the dataset from pyspark.sql.functions import * filtered_df = df.select('vendorID', 'passengerCount', 'tripDistance','paymentType', 'fareAmount', 'tipAmount'\ , date_format('tpepPickupDateTime', 'hh').alias('hour_of_day')\ , dayofweek('tpepPickupDateTime').alias('day_of_week')\ , dayofmonth(col('tpepPickupDateTime')).alias('day_of_month'))\ .filter((df.passengerCount > 0)\ & (df.tipAmount >= 0)\ & (df.fareAmount >= 1) & (df.fareAmount <= 250)\ & (df.tripDistance > 0) & (df.tripDistance <= 200)) filtered_df.createOrReplaceTempView("taxi_dataset")
Adatok elemzése
Adatelemzőként számos eszköz áll rendelkezésre az adatokból való elemzések kinyeréséhez. Az oktatóanyag jelen részében bemutatunk néhány hasznos eszközt, amelyek a Microsoft Fabric-jegyzetfüzetekben érhetők el. Ebben az elemzésben meg szeretnénk érteni azokat a tényezőket, amelyek magasabb taxitippeket eredményeznek a kiválasztott időszakban.
Apache Spark SQL Magic
Először feltáró adatelemzést végzünk apache Spark SQL és magic parancsok segítségével a Microsoft Fabric-jegyzetfüzettel. A lekérdezés után a beépített chart options képesség használatával vizualizáljuk az eredményeket.
Hozzon létre egy új cellát a jegyzetfüzetben, és másolja a következő kódot. Ezzel a lekérdezéssel szeretnénk megérteni, hogy az átlagos tippösszegek hogyan változtak a kiválasztott időszakban. Ez a lekérdezés más hasznos megállapításokat is segít azonosítani, beleértve a napi minimális/maximális tippösszeget és az átlagos viteldíjakat.
%%sql SELECT day_of_month , MIN(tipAmount) AS minTipAmount , MAX(tipAmount) AS maxTipAmount , AVG(tipAmount) AS avgTipAmount , AVG(fareAmount) as fareAmount FROM taxi_dataset GROUP BY day_of_month ORDER BY day_of_month ASCA lekérdezés futtatása után a diagramnézetre váltva vizualizálhatjuk az eredményeket. Ez a példa egy vonaldiagramot hoz létre a
day_of_monthmező kulcsként ésavgTipAmountértékként való megadásával. Miután kiválasztotta a kijelöléseket, válassza az Alkalmaz elemet a diagram frissítéséhez.
Adatok vizualizációja
A beépített jegyzetfüzet-diagramkészítési lehetőségek mellett népszerű nyílt forráskódú kódtárakat is használhat saját vizualizációk létrehozásához. Az alábbi példákban a Seaborn és a Matplotlib függvényt fogjuk használni. Ezeket gyakran használják Python-kódtárak adatvizualizációhoz.
Annak érdekében, hogy a fejlesztés egyszerűbb és olcsóbb legyen, az adatkészletet le kell bontanunk. A beépített Apache Spark-mintavételezési képességet fogjuk használni. Emellett a Seaborn és a Matplotlib is pandas DataFrame- vagy NumPy-tömböt igényel. Pandas DataFrame beszerzéséhez használja a
toPandas()parancsot a DataFrame konvertálásához.# To make development easier, faster, and less expensive, downsample for now sampled_taxi_df = filtered_df.sample(True, 0.001, seed=1234) # The charting package needs a Pandas DataFrame or NumPy array to do the conversion sampled_taxi_pd_df = sampled_taxi_df.toPandas()Meg szeretnénk érteni az adathalmaz tippjeinek eloszlását. A Matplotlib használatával létrehozunk egy hisztogramot, amely a csúcsösszeg és a darabszám eloszlását mutatja. Az eloszlás alapján láthatjuk, hogy a tippek a 10 usd-nél kisebb vagy azzal egyenlő összegekre vannak elvarrva.
# Look at a histogram of tips by count by using Matplotlib ax1 = sampled_taxi_pd_df['tipAmount'].plot(kind='hist', bins=25, facecolor='lightblue') ax1.set_title('Tip amount distribution') ax1.set_xlabel('Tip Amount ($)') ax1.set_ylabel('Counts') plt.suptitle('') plt.show()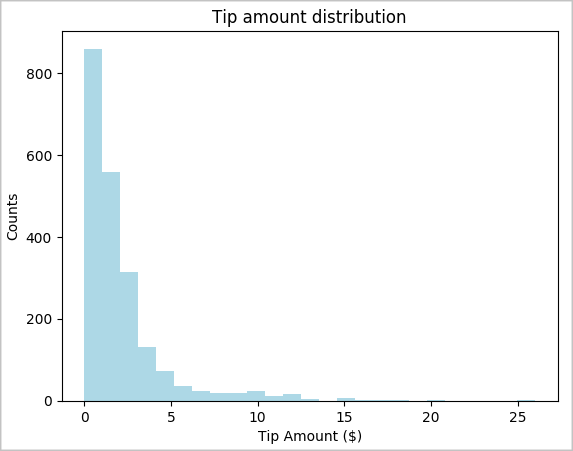
Következő lépésként meg szeretnénk érteni az adott utazás tippjei és a hét napja közötti kapcsolatot. A Seaborn használatával létrehozhat egy dobozdiagramot, amely összefoglalja a hét minden napjának trendjeit.
# View the distribution of tips by day of week using Seaborn ax = sns.boxplot(x="day_of_week", y="tipAmount",data=sampled_taxi_pd_df, showfliers = False) ax.set_title('Tip amount distribution per day') ax.set_xlabel('Day of Week') ax.set_ylabel('Tip Amount ($)') plt.show()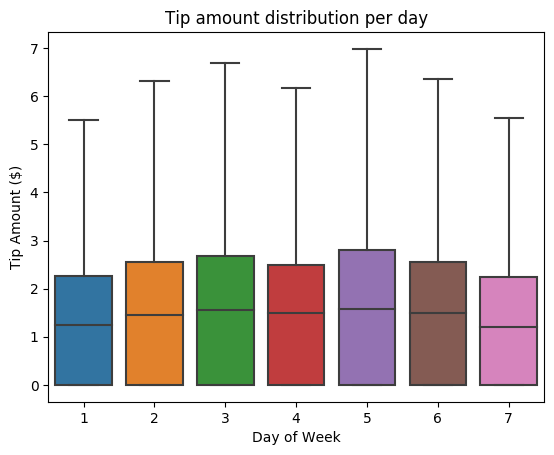
Egy másik hipotézisünk az lehet, hogy pozitív kapcsolat áll fenn az utasok száma és a taxi tipp teljes összege között. A kapcsolat ellenőrzéséhez futtassa az alábbi kódot egy dobozdiagram létrehozásához, amely bemutatja az egyes utasok számához tartozó tippek eloszlását.
# How many passengers tipped by various amounts ax2 = sampled_taxi_pd_df.boxplot(column=['tipAmount'], by=['passengerCount']) ax2.set_title('Tip amount by Passenger count') ax2.set_xlabel('Passenger count') ax2.set_ylabel('Tip Amount ($)') ax2.set_ylim(0,30) plt.suptitle('') plt.show()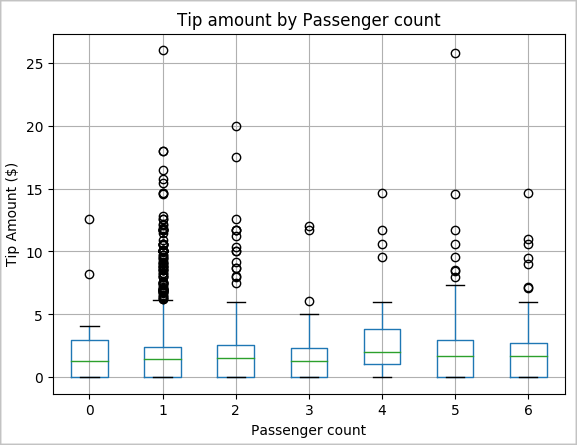
Végül meg szeretnénk érteni a viteldíj összege és a tipp összege közötti kapcsolatot. Az eredmények alapján láthatjuk, hogy számos olyan megfigyelés van, ahol az emberek nem tippelnek. A teljes viteldíj és a tippösszegek között azonban pozitív kapcsolat is látható.
# Look at the relationship between fare and tip amounts ax = sampled_taxi_pd_df.plot(kind='scatter', x= 'fareAmount', y = 'tipAmount', c='blue', alpha = 0.10, s=2.5*(sampled_taxi_pd_df['passengerCount'])) ax.set_title('Tip amount by Fare amount') ax.set_xlabel('Fare Amount ($)') ax.set_ylabel('Tip Amount ($)') plt.axis([-2, 80, -2, 20]) plt.suptitle('') plt.show()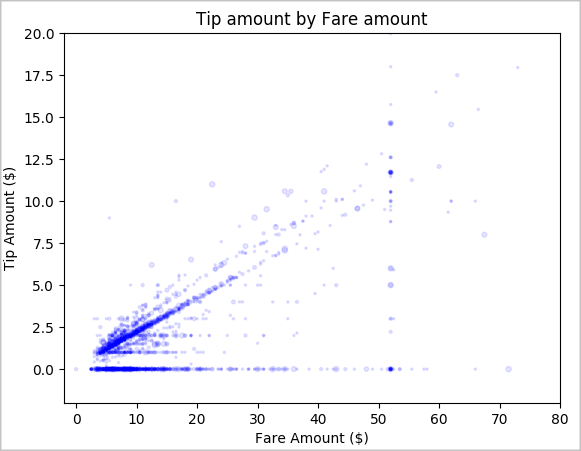
Kapcsolódó tartalom
- Megtudhatja, hogyan használhatja a Pandas API-t az Apache Spark: Pandas API-n az Apache Sparkon
- Python in-line telepítés
Visszajelzés
Hamarosan elérhető: 2024-ben fokozatosan kivezetjük a GitHub-problémákat a tartalom visszajelzési mechanizmusaként, és lecseréljük egy új visszajelzési rendszerre. További információ: https://aka.ms/ContentUserFeedback.
Visszajelzés küldése és megtekintése a következőhöz: