Megjegyzés
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhat bejelentkezni vagy módosítani a címtárat.
Az oldalhoz való hozzáféréshez engedély szükséges. Megpróbálhatja módosítani a címtárat.
A következőkre vonatkozik:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Felügyelt Azure SQL-példány
Felügyelt Azure SQL-példány![]() SQL-adatbázis a Microsoft Fabricben
SQL-adatbázis a Microsoft Fabricben
A hatékony indexek tervezése kulcsfontosságú a jó adatbázis- és alkalmazásteljesítmény eléréséhez. Az indexek hiánya, a túlindexelés vagy a rosszul megtervezett indexek az adatbázisok teljesítményproblémáinak legfőbb forrásai.
Ez az útmutató az index architektúráját és alapjait ismerteti, és ajánlott eljárásokat nyújt az alkalmazások igényeinek megfelelő hatékony indexek tervezéséhez.
Az elérhető indextípusokról további információt az Indexek című témakörben talál.
Ez az útmutató az alábbi indextípusokat ismerteti:
| Elsődleges tárolási formátum | Index típusa |
|---|---|
| Lemezalapú soráruház | |
| Clustered | |
| Nonclustered | |
| Unique | |
| Filtered | |
| Columnstore | |
| Fürtözött oszlopalapú adattár | |
| Nem fürtözött oszlopkészlet | |
| Memory-optimized | |
| Hash | |
| Memóriaoptimalizált, nem klaszterezett |
Az XML-indexekről további információt az XML-indexek (SQL Server) és a szelektív XML-indexek (SXI) című témakörben talál.
A térbeli indexekről további információt a Térbeli indexek áttekintése című témakörben talál.
A teljes szöveges indexekről további információt a Full-Text indexek feltöltése című témakörben talál.
Az index alapjai
Gondoljon egy normál könyvre: a könyv végén van egy index, amely segít gyorsan megtalálni az információkat a könyvben. Az index a kulcsszavak rendezett listája, és az egyes kulcsszavak mellett az oldalszámok halmaza látható, amelyek az egyes kulcsszavakat tartalmazó oldalakra mutatnak.
A sortár-indexek hasonlóak: az értékek rendezett listája, és minden értékhez vannak mutatók azokra az adatoldalakra , ahol ezek az értékek találhatók. Magát az indexet is tárolja a rendszer az indexoldalakon. Egy normál könyvben, ha az index több oldalra terjed ki, és az összes olyan oldalra mutató mutatót kell találnia, amely például a szót SQL tartalmazza, az index kezdetétől kezdve végig kell haladnia, amíg meg nem találja a kulcsszót SQLtartalmazó indexlapot. Innen az összes könyvoldalra mutató mutatókat követheti. Ez tovább optimalizálható, ha az index elején egyetlen oldalt hoz létre, amely betűrendes listát tartalmaz arról, hogy hol találhatók az egyes betűk. Például: "A–D – 121. oldal", "E–G – 122. oldal" stb. Ez az extra oldal kiküszöbölné a tartalomjegyzéken keresztüli lapozás lépését a kezdőpont megtalálásához. Egy ilyen oldal nem létezik a normál könyvekben, de egy soráruházban található indexben. Ezt az egyetlen lapot nevezzük az index gyökéroldalának. A gyökérlap az index által használt faszerkezet kezdőoldala. A fa analógiáját követve a tényleges adatokra mutató mutató végpontokat a fa "levéloldalainak" nevezzük.
Az index egy táblához vagy nézethez társított lemezen vagy memórián belüli struktúra, amely felgyorsítja a sorok beolvasását a táblázatból vagy nézetből. A sortárindexek a tábla vagy nézet egy vagy több oszlopában lévő értékekből létrehozott kulcsokat tartalmaznak. A sortár-indexek esetében ezek a kulcsok egy faszerkezetben (B+ fában) vannak tárolva, amely lehetővé teszi az adatbázismotor számára, hogy gyorsan és hatékonyan megtalálja a kulcsértékekhez társított sorokat.
A sortárindexek logikailag rendezett adatokat tárolnak táblázatként sorokkal és oszlopokkal, és fizikailag sorszintű adatformátumban, úgynevezett rowstore1-ben vannak tárolva. Az adatok oszlopalapú, úgynevezett oszlopcentrikus tárolásának másik módja is van.
Az adatbázis és a számítási feladat megfelelő indexeinek kialakítása összetett egyensúlyozási művelet a lekérdezési sebesség, az indexfrissítési költség és a tárolási költség között. A keskeny lemezalapú sortárindexek vagy az indexkulcsban kevés oszlopot tartalmazó indexek kevesebb tárterületet és kisebb frissítési többletterhelést igényelnek. A széles indexek viszont több lekérdezést javíthatnak. Előfordulhat, hogy a leghatékonyabb indexkészlet megtalálása előtt több különböző kialakítással kell kísérleteznie. Az alkalmazás fejlődése során előfordulhat, hogy az indexeknek változnia kell az optimális teljesítmény fenntartása érdekében. Az indexek hozzáadhatók, módosíthatók és eltávolíthatók az adatbázis sémájának vagy alkalmazástervének befolyásolása nélkül. Ezért ne habozzon kísérletezni a különböző indexekkel.
Az adatbázismotor lekérdezésoptimalizálója általában a lekérdezés végrehajtásához a leghatékonyabb indexeket választja ki. Annak megtekintéséhez, hogy a lekérdezésoptimalizáló mely indexeket használja egy adott lekérdezéshez, az SQL Server Management Studióban válassza a Lekérdezés menü Becsült végrehajtási terv megjelenítése vagy a Tényleges végrehajtási terv belefoglalása lehetőséget.
Ne mindig egyenlő legyen az indexhasználat a jó teljesítménnyel és a jó teljesítménnyel és a hatékony indexhasználattal. Ha az index használata mindig segített a legjobb teljesítmény eléréséhez, a lekérdezésoptimalizáló feladata egyszerű lenne. A valóságban a helytelen indexválasztás az optimálisnál kevesebb teljesítményt okozhat. Ezért a lekérdezésoptimalizáló feladata, hogy csak akkor válasszon ki egy indexet vagy indexkombinációt, ha javítja a teljesítményt, és hogy elkerülje az indexelt lekérést, ha az akadályozza a teljesítményt.
Gyakori tervezési hiba, hogy számos indexet spekulatív módon hoz létre, hogy "az optimalizáló lehetőségeket adja". Az eredményül kapott túlindexelés lelassítja az adatmódosításokat, és egyidejűségi problémákat okozhat.
1 A relációs táblaadatok tárolásának hagyományos módja a Rowstore. A Rowstore olyan táblára utal, amelyben az alapul szolgáló adattárolási formátum halom, B+ fa (fürtözött index) vagy memóriaoptimalizált tábla. A lemezalapú sortároló nem tartalmazza a memóriaoptimalizált táblákat.
Indextervezési feladatok
Az indexek tervezéséhez ajánlott stratégiát a következő feladatok alkotják:
Az adatbázis és az alkalmazás jellemzőinek megismerése.
Például egy olyan online tranzakciófeldolgozási (OLTP-) adatbázisban, amelynek gyakori adatmódosításai nagy átviteli sebességet kell fenntartaniuk, a legkritikusabb lekérdezésekhez megcélzott néhány keskeny soradattár-index jó kezdeti indexterv lenne. A rendkívül magas átviteli sebesség érdekében fontolja meg a memóriaoptimalizált táblákat és indexeket, amelyek zár- és reteszmentes kialakítást biztosítanak. További információkért tekintse meg a memóriaoptimalizált nemclustered indextervezési irányelveket és a kivonatindex tervezési irányelveit ebben az útmutatóban.
Ezzel szemben egy olyan elemzési vagy adattárházi (OLAP) adatbázis esetében, amely nagyon nagy adatkészleteket kell gyorsan feldolgoznia, a fürtözött oszlopcentrikus indexek használata különösen megfelelő lenne. További információkért tekintse meg az útmutató Oszlopcentrikus indexeit: áttekintés vagy oszlopcentrikus index architektúráját.
A leggyakrabban használt lekérdezések jellemzőinek megismerése.
Ha például tudja, hogy egy gyakran használt lekérdezés két vagy több táblát illeszt össze, segít meghatározni az indexek készletét ezekhez a táblákhoz.
A lekérdezési predikátumokban használt oszlopokban található adateloszlás ismertetése.
Egy index például hasznos lehet a sok különböző adatértékkel rendelkező oszlopok esetében, de kevésbé a sok ismétlődő értékkel rendelkező oszlopok esetében. A sok NULL-t tartalmazó vagy jól definiált adathalmazokkal rendelkező oszlopokhoz szűrt indexet használhat. További információkért tekintse meg az útmutató szűrt indextervezési irányelveit .
Határozza meg, hogy mely indexbeállítások növelhetik a teljesítményt.
Ha például egy meglévő nagy táblára csoportosított indexet hoz létre, hasznos lehet az
ONLINEindexbeállítás. AONLINEbeállítás lehetővé teszi, hogy a mögöttes adatokon végzett egyidejű tevékenység folytatódjon az index létrehozása vagy újraépítése során. A sor- vagy oldaladatok tömörítése javíthatja a teljesítményt az index I/O-jának és memóriaigényének csökkentésével. További információ: INDEX LÉTREHOZÁSA.Vizsgálja meg a tábla meglévő indexeit, hogy ne hozzon létre ismétlődő vagy nagyon hasonló indexeket.
Gyakran jobb módosítani egy meglévő indexet, mint új, de többnyire duplikált indexet létrehozni. Tegyük fel például, hogy egy vagy két további belefoglalt oszlopot ad hozzá egy meglévő indexhez, ahelyett, hogy új indexet hoz létre ezekkel az oszlopokkal. Ez különösen akkor fontos, ha nemclustered indexeket hangol hiányzó indexjavaslatokkal, vagy ha az adatbázismotor-finomhangolási tanácsadót használja, ahol az indexek hasonló variációit kínálhatja ugyanazon a táblán és oszlopon.
Általános indextervezési irányelvek
Az adatbázis, a lekérdezések és a táblaoszlopok jellemzőinek megismerése segíthet az optimális indexek kezdeti megtervezésében és a terv módosításában az alkalmazások fejlődésével.
Adatbázisokkal kapcsolatos szempontok
Index tervezésekor vegye figyelembe az alábbi adatbázis-irányelveket:
Az indexek nagy száma egy táblán befolyásolja a
INSERT,UPDATE,DELETE, ésMERGEutasítások teljesítményét, mivel az indexekben lévő adatoknak változhatnak, ahogy a tábla adatai változnak. Ha például egy oszlopot több indexben használnak, és végrehajt egy utasítástUPDATE, amely módosítja az adott oszlop adatait, az adott oszlopot tartalmazó indexeket is frissíteni kell.Kerülje az erősen frissített táblák túlindexelését, és tartsa szűken az indexeket, azaz a lehető legkevesebb oszlopot.
Több olyan index is lehet a táblákon, amelyeken kevés adatmódosítás, de nagy mennyiségű adat található. Ilyen táblák esetében számos index segíthet lekérdezni a teljesítményt, miközben az indexfrissítési többletterhelés elfogadható marad. Azonban ne hozzon létre indexeket spekulatív módon. Figyelje az indexhasználatot, és távolítsa el a nem használt indexeket az idő függvényében.
Előfordulhat, hogy a kis táblák indexelése nem optimális, mert az adatbázismotor hosszabb ideig tart, amíg végigmegy az indexen az adatok keresésekor, ahelyett, hogy alaptáblát vizsgálna át. Ezért előfordulhat, hogy a kis táblák indexei soha nem lesznek használva, de a tábla adatainak frissítésével továbbra is frissíteni kell.
A nézetek indexei jelentős teljesítménynövekedést biztosíthatnak, ha a nézet összesítéseket és/vagy illesztéseket tartalmaz. További információ: Indexelt nézetek létrehozása.
Az Azure SQL Database elsődleges replikáin lévő adatbázisok automatikusan létrehoznak adatbázis-tanácsadói teljesítményjavaslatokat az indexekhez. Opcionálisan engedélyezheti az automatikus indexhangolást.
A Lekérdezéstár segít azonosítani a nem optimális teljesítményt nyújtó lekérdezéseket , és olyan lekérdezés-végrehajtási tervek előzményeit biztosítja, amelyek segítségével megtekintheti az optimalizáló által kiválasztott indexeket. Ezeket az adatokat arra használhatja, hogy az index finomhangolása a leghatásosabb legyen a leggyakrabban használt és erőforrás-használó lekérdezésekre összpontosítva.
Lekérdezési szempontok
Index tervezésekor vegye figyelembe a következő lekérdezési irányelveket:
Hozzon létre nem klaszteres indexeket az oszlopokon, amelyeket gyakran használnak predikátumokban és csatolási kifejezésekben a lekérdezések során. Ezek a SARGable oszlopok. Kerülnie kell azonban, hogy szükségtelen oszlopokat adjon hozzá az indexekhez. Ha túl sok indexoszlopot ad hozzá, az hátrányosan befolyásolhatja a lemezterületet és az indexfrissítés teljesítményét.
A relációs adatbázisokban a SARGable kifejezés egy keresésiARGumentum-predikátumra utal, amely index használatával felgyorsíthatja a lekérdezés végrehajtását. További információ: SQL Server és Azure SQL indexarchitektúra és tervezési útmutató.
Tip
Mindig győződjön meg arról, hogy a létrehozott indexeket ténylegesen használja a lekérdezési számítási feladat. A nem használt indexek elvetése.
Az indexhasználati statisztikák sys.dm_db_index_usage_stats és sys.dm_db_index_operational_stats érhetők el.
Az indexek lefedése javíthatja a lekérdezés teljesítményét, mivel a lekérdezés követelményeinek teljesítéséhez szükséges összes adat magában az indexben található. Ez azt jelenti, hogy az adatigény teljesítéséhez csak az indexoldalak szükségesek, a tábla vagy a fürtözött index adatoldalaira nincs szükség; így csökkentve a teljes lemez I/O-t. Például egy oszlopok
Alekérdezése ésBegy olyan táblán, amelyen egy összetett index van létrehozva az oszlopokonA,BésCcsak az indexből tudja lekérni a megadott adatokat.Note
A lefedett index egy nem klaszterezett index, amely az alaptáblához való hozzáférés nélkül teljesíti a lekérdezések összes adathozzáférését.
Az ilyen indexek az indexkulcsban az összes szükséges SARGable oszlopot tartalmazzák, a nem SARGable oszlopokat pedig belefoglalt oszlopokként. Ez azt jelenti, hogy a lekérdezéshez szükséges összes oszlop, a , és a
WHEREzáradékokban, illetve aJOINGROUP BYzáradékokban, megtalálható az indexben.SELECTUPDATELehet, hogy jelentősen kevesebb I/O szükséges a lekérdezés végrehajtásához, ha az index elég keskeny a táblázat teljes sor- és oszlopkészletéhez képest, azaz az összes oszlop egy kisebb részhalmazát képezi.
Fontolja meg az indexek lefedését egy nagy tábla kis részének lekérdezésekor, ahol ezt a kis részt egy fix predikátum határozza meg.
Ne hozzon létre túl sok oszlopot tartalmazó lefedő indexet, mert ez csökkenti annak előnyeit, miközben növeli az adatbázis-tárolást, az I/O-t és a memóriaigényt.
Olyan lekérdezéseket írhat, amelyek a lehető legtöbb sort szúrják be vagy módosítják egyetlen utasításban, ahelyett, hogy több lekérdezést használnak ugyanazon sorok frissítésére. Ez csökkenti az indexfrissítés többletterhelését.
Oszlopokkal kapcsolatos szempontok
Index tervezésekor vegye figyelembe a következő oszlop irányelveit:
Tartsa rövidre az indexkulcs hosszát, különösen fürtözött indexek esetén.
Az ntext, szöveg, kép, varchar(max), nvarchar(max), varbinary(max), json és vektor típusú oszlopok nem adhatók meg indexkulcsoszlopként. Az ilyen adattípusokkal rendelkező oszlopok azonban nem konklúziós indexekhez nem kulcs (belefoglalt) indexoszlopként vehetők fel. További információkért tekintse meg a jelen útmutató nem klaszterezett indexekben lévő tartalmazott oszlopok használata című szakaszt.
Oszlop egyediségének vizsgálata. Az ugyanazon kulcsoszlopokon lévő nemunikus indexek helyett egyedi indexek további információkat nyújtanak a lekérdezésoptimalizáló számára, amely hasznosabbá teszi az indexet. További információkért tekintse meg az útmutató egyedi indextervezési irányelveit .
Vizsgálja meg az oszlopban lévő adateloszlást. Egy több sorból, de kevés különböző értékkel rendelkező oszlop indexének létrehozása még akkor sem javíthatja a lekérdezés teljesítményét, ha az indexet a lekérdezésoptimalizáló használja. Analógiaként a családnév alapján betűrendbe rendezett fizikai telefonkönyvtár nem gyorsítja meg a személy felkutatását, ha a város összes emberét Smithnek vagy Jonesnak hívják. Az adatterjesztésről további információt a Statisztika című témakörben talál.
Érdemes lehet szűrt indexeket használni a jól definiált részhalmazokkal rendelkező oszlopokon, például a sok NULL-et tartalmazó oszlopokon, az értékkategóriákkal rendelkező oszlopokon és az eltérő értéktartományú oszlopokon. A jól megtervezett szűrt indexek javíthatják a lekérdezések teljesítményét, csökkenthetik az indexfrissítési költségeket, és csökkenthetik a tárolási költségeket a tábla összes sorának egy kis részhalmazának tárolásával, ha ez az alkészlet sok lekérdezés esetében releváns.
Vegye figyelembe az indexkulcs oszlopainak sorrendjét, ha a kulcs több oszlopot tartalmaz. A lekérdezési predikátumban egyenlőség (
=), egyenlőtlenség (>,>=,<,<=) vagyBETWEENkifejezés esetén az oszlopot kell elsőként elhelyezni, vagy ha egy illesztésben vesz részt. A további oszlopokat a megkülönböztethetőségük szintje alapján kell rendezni, azaz a legkülönbözőbbtől a legkevésbé különbözőig.Ha például az index a következőképpen van definiálva:
LastName,FirstName, akkor az index hasznos, ha aWHEREzáradékban lévő lekérdezési predikátumWHERE LastName = 'Smith'vagyWHERE LastName = Smith AND FirstName LIKE 'J%'. A lekérdezésoptimalizáló azonban nem használja az indexet olyan lekérdezéshez, amely csak rákeresettWHERE FirstName = 'Jane', vagy az index nem növelné az ilyen lekérdezések teljesítményét.Fontolja meg a számított oszlopok indexelését, ha azok szerepelnek a lekérdezési predikátumokban. A számított oszlopok indexeiről további információkért lásd a éshivatkozást.
Indexjellemzők
Miután megállapította, hogy egy index megfelelő egy lekérdezéshez, kiválaszthatja a helyzetének leginkább megfelelő indextípust. Az index jellemzői a következők:
- Fürtözött vagy nem kizárólagos
- Egyedi vagy nem egyedi
- Egyoszlopos vagy többoszlopos
- Az index kulcsoszlopainak növekvő vagy csökkenő sorrendje
- Az összes sor vagy szűrt, nem rendezett indexek esetén
- Oszloptár vagy sortár
- Kivonat vagy nem teljes memóriaoptimalizált táblákhoz
Indexelhelyezés fájlcsoportokon vagy partíciós sémákon
Az indextervezési stratégia kidolgozása során érdemes megfontolni az indexek elhelyezését az adatbázishoz társított fájlcsoportokon.
Alapértelmezés szerint az indexek ugyanabban a fájlcsoportban vannak tárolva, mint az alaptábla (fürtözött index vagy halom), amelyen az index létrejön. Egyéb konfigurációk is lehetségesek, például:
Nem fürtözött indexek létrehozása egy másik fájlcsoportban, mint az alaptábla fájlcsoportja.
Klaszteres és nem-klaszteres indexek particionálása több fájlcsoportot átfogóan.
A nem particionált táblák esetében a legegyszerűbb módszer általában a legjobb megoldás: hozzon létre minden táblát ugyanazon a fájlcsoporton, és adjon hozzá annyi adatfájlt a fájlcsoporthoz, amennyi szükséges az összes rendelkezésre álló fizikai tároló használatához.
Fejlettebb indexelhelyezési módszereket is figyelembe lehet venni, ha a rétegzett tároló elérhető. Létrehozhat például egy fájlcsoportot a gyakran használt táblákhoz, amelyeken gyorsabb lemezeken lévő fájlok találhatók, és egy fájlcsoportot a lassabb lemezeken lévő archiváló táblákhoz.
A fürtözött indexet tartalmazó táblákat áthelyezheti az egyik fájlcsoportból a másikba a fürtözött index elvetésével, valamint egy új fájlcsoport vagy partíciós séma megadásával az MOVE TODROP INDEX utasítás záradékában, vagy az CREATE INDEX utasítás záradékkal való DROP_EXISTING használatával.
Particionált indexek
Megfontolhatja a lemezes halmok, a klaszteres és a nem-klaszteres indexek particionálását is több fájlcsoportban. A particionált indexek horizontálisan (sor szerint) vannak particionálva egy partíciófüggvény alapján. A partíciófüggvény határozza meg, hogy az egyes sorok hogyan vannak leképezve egy partícióra egy megadott oszlop, az úgynevezett particionálási oszlop értékei alapján. A partíciós séma egy partíciókészlet fájlcsoporthoz való leképezését határozza meg.
Az index particionálása a következő előnyöket nyújtja:
A nagyméretű adatbázisok kezelhetőbbé tétele. Az OLAP-rendszerek például olyan partícióérzékeny ETL-t implementálhatnak, amely jelentősen leegyszerűsíti az adatok tömeges hozzáadását és eltávolítását.
Tegye lehetővé, hogy bizonyos típusú lekérdezések, például a hosszú ideig futó elemzési lekérdezések gyorsabban fussanak. Ha a lekérdezések particionált indexet használnak, az adatbázismotor egyszerre több partíciót is feldolgozhat, és kihagyhatja (kiküszöbölheti) a lekérdezés által nem szükséges partíciókat.
Figyelmeztetés
A particionálás ritkán javítja az OLTP-rendszerek lekérdezési teljesítményét, de jelentős többletterhelést okozhat, ha egy tranzakciós lekérdezésnek számos partícióhoz kell hozzáférnie.
További információ: Particionált táblák és indexek.
Index rendezési sorrend tervezési irányelvei
Az indexek meghatározásakor fontolja meg, hogy az indexkulcs oszlopai növekvő vagy csökkenő sorrendben legyenek-e tárolva. Az alapértelmezett érték a növekvő érték. A CREATE INDEX, CREATE TABLE és ALTER TABLE utasítások szintaxisa támogatja a kulcsszavakat ASC (növekvő) és DESC (csökkenő) az egyes oszlopokon az indexekben és kötöttségekben.
A kulcsértékek indexben való tárolásának sorrendje akkor hasznos, ha a táblára hivatkozó lekérdezések olyan záradékokkal rendelkeznek ORDER BY , amelyek eltérő irányokat határoznak meg az adott index kulcsoszlopához vagy oszlopaihoz. Ezekben az esetekben az index eltávolíthatja a rendezésioperátor szükségességét a lekérdezési tervben.
Az Adventure Works Cycles beszerzési részlegének vásárlóinak például értékelniük kell a szállítóktól vásárolt termékek minőségét. A vásárlók leginkább a magas elutasítási arányú szállítók által küldött termékeket szeretnék megtalálni.
Ahogyan az AdventureWorks mintaadatbázisra vonatkozó alábbi lekérdezésben is látható, a feltételeknek RejectedQty megfelelő adatok lekéréséhez a táblázat oszlopát Purchasing.PurchaseOrderDetail csökkenő sorrendbe kell rendezni (nagytól kicsiig), az ProductID oszlopot pedig növekvő sorrendbe kell rendezni (kicsitől nagyig).
SELECT RejectedQty,
((RejectedQty / OrderQty) * 100) AS RejectionRate,
ProductID,
DueDate
FROM Purchasing.PurchaseOrderDetail
ORDER BY RejectedQty DESC, ProductID ASC;
A lekérdezés következő végrehajtási terve azt mutatja, hogy a lekérdezésoptimalizáló egy Rendezési operátort használt az eredményhalmaz visszaadásához a ORDER BY záradék által megadott sorrendben.

Ha egy lemezalapú sortár-index olyan kulcsoszlopokkal jön létre, amelyek megfelelnek a ORDER BY lekérdezés záradékában szereplő oszlopnak, a lekérdezési terv Rendezés operátora megszűnik, így a lekérdezési terv hatékonyabbá válik.
CREATE NONCLUSTERED INDEX IX_PurchaseOrderDetail_RejectedQty
ON Purchasing.PurchaseOrderDetail
(RejectedQty DESC, ProductID ASC, DueDate, OrderQty);
A lekérdezés ismételt végrehajtása után a következő végrehajtási terv azt mutatja, hogy a Rendezés operátor már nincs jelen, és az újonnan létrehozott nemclustered indexet használja a rendszer.
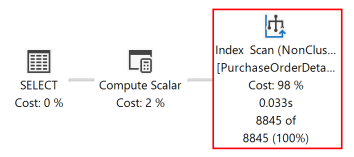
Az adatbázismotor mindkét irányban képes az indexek vizsgálatára. Olyan index, amely RejectedQty DESC, ProductID ASC, továbbra is használatban lehet egy olyan lekérdezéshez, amelyben a ORDER BY záradék oszlopainak rendezési irányai felcserélődnek. Egy záradékkal ORDER BY rendelkező ORDER BY RejectedQty ASC, ProductID DESC lekérdezés például ugyanazt az indexet használhatja.
Rendezési sorrend csak az index kulcsoszlopaihoz adható meg. A sys.index_columns katalógusnézet azt jelzi, hogy egy indexoszlop növekvő vagy csökkenő sorrendben van-e tárolva.
Fürtözött index tervezési irányelvei
A fürtözött index egy tábla összes sorát és oszlopát tárolja. A sorok az indexkulcsértékek sorrendjében vannak rendezve. Táblánként csak egy klaszterezett index lehet.
Az alaptábla kifejezés hivatkozhat fürtözött indexre vagy halomra. A halom egy olyan rendezetlen adatszerkezet a lemezen, amely egy tábla összes sorát és oszlopát tartalmazza.
Néhány kivételtől eltekintve minden táblának klaszteres indexszel kell rendelkeznie. A fürtözött index kívánt tulajdonságai a következők:
| Ingatlan | Description |
|---|---|
| Keskeny | A klaszterezett indexkulcs a nem kluszterezett indexek része ugyanazon az alaptáblán. Egy keskeny kulcs, vagy egy olyan kulcs, ahol a kulcsoszlopok teljes hossza kicsi, csökkenti a tábla összes indexének tárolási, I/O- és memóriaterhelését. A kulcs hosszának kiszámításához adja hozzá a kulcsoszlopok által használt adattípusok tárolási méretét. További információ: Adattípus-kategóriák. |
| Egyedülálló | Ha a fürtözött index nem egyedi, a rendszer automatikusan hozzáad az indexkulcshoz egy 4 bájtos belső egyediség biztosító oszlopot az egyediség biztosítása érdekében. Ha meglévő egyedi oszlopot ad hozzá a fürtözött indexkulcshoz, azzal elkerüli a tábla összes indexében található uniqueifier oszlop tárolási, I/O- és memóriaterhelését. Emellett a lekérdezésoptimalizáló hatékonyabb lekérdezési terveket is létrehozhat, ha egy index egyedi. |
| Egyre növekvő | Az egyre növekvő indexben az adatok mindig az index utolsó oldalán lesznek hozzáadva. Így elkerülhetők az index közepén lévő oldaleloszlások, amelyek csökkentik az oldalsűrűséget és csökkentik a teljesítményt. |
| Megváltoztathatatlan | A fürtözött indexkulcs a nem konklúziós indexek része. A fürtözött indexek kulcsoszlopának módosításakor minden nemclustered indexben is módosítást kell végezni, amely processzor-, naplózási, I/O- és memóriaterhelést ad hozzá. A többletterhelés elkerülhető, ha a fürtözött index kulcsoszlopai nem módosíthatók. |
| Csak nem-null értékű oszlopok | Ha egy sor null értékű oszlopokkal rendelkezik, akkor tartalmaznia kell egy NULL blokk nevű belső struktúrát, amely soronként 3-4 bájt tárterületet ad hozzá egy indexhez. Az, ha a fürtözött index összes oszlopának nem engedélyezett a null érték, elkerülhetővé teszi ezt a többletterhelést. |
| Csak rögzített szélességű oszlopokkal rendelkezik | A változó szélességű adattípusokat (például varchart vagy nvarchart ) használó oszlopok értékenként további 2 bájtot használnak a rögzített szélességű adattípusokhoz képest. A rögzített szélességű adattípusok, például az int használata elkerüli ezt a többletterhelést a tábla összes indexében. |
A fürtözött indexek tervezésekor a lehető legtöbb tulajdonság kielégítése nemcsak a fürtözött indexet, hanem az ugyanazon a táblán lévő összes nemclustered indexet is hatékonyabbá teszi. A teljesítmény javul a tárolási, I/O- és memóriaterhelések elkerülésével.
Egy egyetlen int vagy bigint nem null értékű oszlopot tartalmazó fürtözött indexkulcs például mindegyik tulajdonsággal rendelkezik, ha egy IDENTITY záradék vagy egy alapértelmezett kényszer tölti ki egy sorozat használatával, és a sor beszúrása után nem frissül.
Ezzel szemben a fürtözött indexkulcs egyetlen uniqueidentifier oszlopmal szélesebb, mivel 4 bájt helyett 16 bájt tárterületet használ az int és 8 bájt helyett a bigint számára, és nem felel meg az egyre növekvő tulajdonságnak, hacsak az értékek egymás után nem jönnek létre.
Tip
Kényszer létrehozásakor PRIMARY KEY a rendszer automatikusan létrehoz egy, a kényszert támogató egyedi indexet. Alapértelmezés szerint ez az index fürtözött; ha azonban ez az index nem felel meg a kívánt fürtözött index tulajdonságainak, létrehozhatja a korlátozást nem fürtözöttként, és ehelyett létrehozhat egy másik fürtözött indexet.
Ha nem hoz létre fürtözött indexet, a rendszer halomként tárolja a táblát, ami általában nem ajánlott.
Csoportosított indexarchitektúra
A sorosindexek B+ fákként vannak rendszerezve. Az index B+ fájának minden oldalát indexcsomópontnak nevezzük. A B+ fa legfelső csomópontját gyökércsomópontnak nevezzük. Az index alsó csomópontjait levélcsomópontoknak nevezzük. A gyökér és a levélcsomópontok közötti indexszinteket együttesen köztes szinteknek nevezzük. A fürtözött indexekben a levélcsomópontok tartalmazzák az alapul szolgáló tábla adatoldalait. A gyökér- és köztes szintű csomópontok indexsorokat tartalmazó indexoldalakat tartalmaznak. Minden indexsor tartalmaz egy kulcsértéket és egy mutatót a B+ fa egy köztes szintű lapjára, vagy egy adatsort az index levélszintjében. Az index egyes szintjein lévő lapok duplán csatolt listában vannak csatolva.
A fürtözött indexek a sys.partitionsban egy sortal rendelkeznek az index által használt minden egyes partícióhoz a következővel index_id = 1: . A fürtözött indexek alapértelmezés szerint egyetlen partícióval rendelkeznek. Ha egy fürtözött index több partícióval rendelkezik, minden partíció külön B+ fastruktúrával rendelkezik, amely az adott partíció adatait tartalmazza. Ha például egy fürtözött index négy partícióval rendelkezik, négy B+ fastruktúrával rendelkezik, amelyek mindegyike egy-egy partícióban található.
A fürtözött index adattípusaitól függően minden fürtözött indexstruktúra egy vagy több foglalási egységből áll, amelyekben egy adott partíció adatait tárolhatja és kezelheti. Legalább minden fürtözött index partíciónként egy IN_ROW_DATA foglalási egységgel rendelkezik. A fürtözött index partíciónként egy LOB_DATA foglalási egységtel is rendelkezik, ha nagy objektumoszlopokat (például nvarchar(max)) tartalmaz. Partíciónként egy ROW_OVERFLOW_DATA foglalási egységgel is rendelkezik, ha olyan változó hosszúságú oszlopokat tartalmaz, amelyek túllépik a 8060 bájtos sorméretkorlátot.
A B+ faszerkezet lapjai a fürtözött indexkulcs értéke alapján vannak rendezve. Minden beszúrás azon a lapon történik, ahol a beszúrt sor kulcsértéke illeszkedik a rendezési sorrendbe a meglévő lapok között. Az oldalon belül a sorok nem feltétlenül fizikai sorrendben vannak tárolva. Az oldal azonban fenntartja a sorok logikai sorrendjét egy ponttömb nevű belső struktúra használatával. A slot tömb bejegyzései az indexkulcs sorrendje szerint vannak rendezve.
Ez az ábra egy fürtözött index struktúráját egyetlen partícióban mutatja be.

Nem-kapcsolt indexek tervezési irányelvei
A fürtözött és a nemclustered indexek közötti fő különbség az, hogy a nemclustered index a tábla oszlopainak egy részét tartalmazza, általában a fürtözött indextől eltérő rendezéssel. A nem clustered index opcionálisan szűrhető, ami azt jelenti, hogy a tábla összes sorának egy részét tartalmazza.
A lemezalapú sortár nemclustered indexe tartalmazza azokat a sorkeresőket, amelyek az alaptábla sorának tárolási helyére mutatnak. Több nemclustered indexet is létrehozhat egy táblán vagy indexelt nézetben. Általában a nemclustered indexeket úgy kell megtervezni, hogy javítsák a gyakran használt lekérdezések teljesítményét, amelyeknek egyébként az alaptáblát kellene megvizsgálniuk.
A könyvben használt indexhez hasonlóan a lekérdezésoptimalizáló úgy keres egy adatértéket, hogy a nemclustered indexben megkeresi az adatérték helyét a táblában, majd közvetlenül erről a helyről kéri le az adatokat. Ez teszi a nemclustered indexeket optimális választássá a pontos egyezéses lekérdezésekhez, mivel az index olyan bejegyzéseket tartalmaz, amelyek a lekérdezésekben keresendő adatértékek táblájának pontos helyét írják le.
Ha például a HumanResources.Employee táblát szeretné lekérdezni egy adott vezető alá tartozó összes alkalmazottról, a lekérdezésoptimalizáló a nem klaszteres indexet IX_Employee_ManagerID használhatja; ennek a ManagerID az első kulcsoszlopa. Mivel az ManagerID értékek a nemclustered indexben vannak rendezve, a lekérdezésoptimalizáló gyorsan megtalálhatja az indexben lévő összes olyan bejegyzést, amely megfelel a megadott ManagerID értéknek. Minden indexbejegyzés az alaptábla pontos oldalára és sorára mutat, ahol az összes többi oszlop megfelelő adatai lekérhetők. Miután a lekérdezésoptimalizáló megtalálta az index összes bejegyzését, közvetlenül a pontos oldalra és sorra léphet az adatok lekéréséhez a teljes alaptábla beolvasása helyett.
Nemclustered indexarchitektúra
A lemezalapú soralapú nemclustered indexek ugyanolyan B+ fastruktúrával rendelkeznek, mint a fürtözött indexek, kivéve a következő különbségeket:
A nem klaszterezett index nem feltétlenül tartalmazza a tábla összes oszlopát és sorát.
A nem rendezett indexek levélszintje adatoldalak helyett indexlapokból áll. A nem kizárólagos indexek levélszintjén lévő indexlapok kulcsoszlopokat tartalmaznak. Opcionálisan, a táblázat más oszlopainak egy részét tartalmazhatják, hogy elkerüljük azok beolvasását az alaptáblából.
A nem klaszteres indexsorok sorkeresői vagy egy sorra mutató mutatók, vagy egy sor fürtözött indexkulcsa, a következőképpen:
Ha a táblának van fürtözött indexe, vagy az index egy indexelt nézetben található, akkor a sorkereső a sorhoz tartozó fürtözött indexkulcs.
Ha a tábla halom, ami azt jelenti, hogy nincs fürtözött indexe, a sorkereső a sorra mutató mutató. Az egérmutató a fájlazonosítóból (id), az oldalszámból és az oldal sorának számából épül fel. Az egész mutatót sorazonosítónak (RID) nevezzük.
A sorkeresők a nem rendezett indexsorok egyediségét is biztosítják. Az alábbi táblázat azt ismerteti, hogyan adja hozzá az adatbázismotor a sorkeresőket a nemclustered indexekhez:
| Alaptábla típusa | Nem klaszteres indextípus | Sorkereső |
|---|---|---|
| Heap | ||
| Nonunique | A RID hozzáadva a kulcsoszlopokhoz | |
| Unique | RID hozzáadva a belefoglalt oszlopokhoz | |
| Egyedi klaszterezett index | ||
| Nonunique | A kulcsoszlopokhoz hozzáadott fürtözött indexkulcsok | |
| Unique | Csoportosított indexkulcsok hozzáadva a belefoglalt oszlopokhoz | |
| Nem egyedi klaszterezett index | ||
| Nonunique | Klaszterezett indexkulcsok és "uniqueifier" (ha jelen van) hozzáadva a kulcsoszlopokhoz. | |
| Unique | Csoportosított indexkulcsok és egyedi azonosítók (ha vannak) hozzáadva a mellékelt oszlopokhoz |
Az adatbázismotor soha nem tárol egy adott oszlopot többször egy nemclustered indexben. A felhasználó által a nemclustered index létrehozásakor megadott indexkulcs-sorrend mindig teljesül: a kulcs végén minden olyan sorkereső oszlopot hozzáad, amelyet hozzá kell adni egy nemclustered index kulcsához, az indexdefinícióban megadott oszlopokat követve. A nemclustered indexben lévő fürtözött index kulcs sor azonosítói használhatók a lekérdezés feldolgozás során, függetlenül attól, hogy explicit módon vannak megadva az indexdefinícióban, vagy implicit módon kerültek hozzáadásra.
Az alábbi példák azt mutatják be, hogyan implementálhatók a sorkeresők nemclustered indexekben:
| Fürtözött index | Nem klaszterezett index definíció | Nem klaszteres index definíció sor elhelyezőkkel | Explanation |
|---|---|---|---|
Egyedi klaszterezett index kulcsoszlopokkal (A, B, C) |
Nem nem kizárólagos index kulcsoszlopokkal (B, A) és belefoglalt oszlopokkal (E, G) |
Kulcsoszlopok (B, A, C) és belefoglalt oszlopok (E, G) |
A nem fürtözött index nem egyedi, ezért a sorazonosítónak jelen kell lennie az index kulcsaiban. Az oszlopok B és A a sorkeresőben már megtalálhatók, ezért csak az C oszlopot adja hozzá. A rendszer hozzáadja az oszlopot C a kulcsoszlopok listájának végéhez. |
Egyedi klaszterezett index kulcsoszlopú (A) |
Nem egyedi, nem klaszterezett index kulcsoszlopokkal (B, C) és belefoglalt oszloppal (A) |
Kulcsoszlopok (B, C, A) |
A nem klaszterezett index nem egyedi, ezért a sorszám hozzáadódik a kulcshoz. Az oszlop A még nincs megadva kulcsoszlopként, ezért a rendszer hozzáadja a kulcsoszlopok listájának végéhez. Az oszlop A most már a kulcsban van, ezért nem kell belefoglalt oszlopként tárolni. |
Klaszterezett index kulcsoszlopokkal (A, B) |
Egyedi nem klaszterezett index kulcsoszloppal (C) |
Kulcsoszlop (C) és belefoglalt oszlopok (A, B) |
A nem klaszterezett index egyedi, ezért a sormutató hozzáadódik a bevont oszlopokhoz. |
A nem klaszterezett indexek egy sort tartalmaznak a sys.partitions táblában az index által használt minden egyes partícióhozindex_id > 1. Alapértelmezés szerint egy nemclustered index egyetlen partícióval rendelkezik. Ha egy nemclustered index több partícióval rendelkezik, minden partíció B+ fastruktúrával rendelkezik, amely az adott partíció indexsorait tartalmazza. Ha például egy nemclustered index négy partícióval rendelkezik, négy B+ fastruktúra van, amelyek mindegyike egy-egy partícióban található.
A nemclustered index adattípusától függően minden nemclustered indexstruktúra rendelkezik egy vagy több foglalási egységgel, amelyben egy adott partíció adatait tárolhatja és kezelheti. Legalább minden nem fürtözött index partíciónként egy IN_ROW_DATA foglalási egységgel rendelkezik, amely az index B+ fa oldalait tárolja. A nem fürtözött index partíciónként egy LOB_DATA foglalási egységgel is rendelkezik, ha nagy objektum (LOB) oszlopokat, például nvarchar(max) tartalmaz. Emellett partíciónként egy ROW_OVERFLOW_DATA foglalási egységgel rendelkezik, ha olyan változó hosszúságú oszlopokat tartalmaz, amelyek túllépik a 8060 bájtos sorméretkorlátot.
Az alábbi ábra egy nemclustered index struktúráját mutatja be egyetlen partícióban.

Belefoglalt oszlopok használata nem klaszteres indexekben
A kulcsoszlopok mellett a nem konklúziós indexek nem kulcsoszlopokat is tárolhatnak a levélszinten. A nem kulcsfontosságú oszlopokat tartalmazott oszlopoknak nevezzük, és az INCLUDE záradékában vannak megadva az CREATE INDEX utasításban.
A nem kulcsoszlopokat tartalmazó indexek jelentősen javíthatják a lekérdezés teljesítményét, ha lefedik a lekérdezést, vagyis amikor a lekérdezésben használt összes oszlop kulcs- vagy nem kulcsoszlopként szerepel az indexben. A teljesítménynövekedés azért érhető el, mert az adatbázismotor az összes oszlopértéket megtalálja az indexen belül; az alaptábla nem érhető el, ami kevesebb lemez I/O-műveletet eredményez.
Ha egy oszlopot lekérdezéssel kell lekérni, de nem használja a lekérdezési predikátumokban, összesítésekben és rendezésekben, vegye fel bele, és ne kulcsoszlopként. Ennek az alábbi előnyei vannak:
A belefoglalt oszlopok olyan adattípusokat használhatnak, amelyek nem engedélyezettek indexkulcs-oszlopokként.
Az adatbázismotor nem veszi figyelembe a belefoglalt oszlopokat az indexkulcs oszlopainak vagy az indexkulcs méretének kiszámításakor. A belefoglalt oszlopoknál nincs korlátozva a 900 bájtos maximális kulcsméret. Szélesebb indexeket hozhat létre, amelyek több lekérdezést fednek le.
Ha áthelyez egy oszlopot az indexkulcsból a belefoglalt oszlopok közé, az index összeállítása kevesebb időt vesz igénybe, mert az index rendezési művelete gyorsabb lesz.
Ha a tábla fürtözött indexet tartalmaz, a rendszer automatikusan hozzáadja a fürtözött indexkulcsban meghatározott oszlopot vagy oszlopokat a táblában lévő nem nyilvános indexekhez. Nem szükséges megadni őket sem a nem klaszterezett indexkulcsban, sem a tartalmazott oszlopokban.
A belefoglalt oszlopokkal rendelkező indexek irányelvei
Vegye figyelembe a következő irányelveket, amikor nem klaszteres indexeket tervez a belefoglalt oszlopokkal.
A belefoglalt oszlopok csak táblákon vagy indexelt nézeteken lévő nem-klaszteres indexekben definiálhatók.
Minden adattípus engedélyezett, kivéve szöveg, szövegés kép.
A determinisztikus és pontos vagy pontatlan számított oszlopok is tartalmazhatnak oszlopokat. A számított oszlopok indexeiről további információkért lásd a éshivatkozást.
A kulcsoszlopokhoz hasonlóan a képből, az ntextből és a szöveges adattípusokból származtatott számított oszlopok is belefoglalhatók az oszlopokba, feltéve, hogy a számított oszlop adattípusa engedélyezett egy belefoglalt oszlopban.
Az oszlopnevek nem adhatók meg a
INCLUDElistában és a kulcsoszloplistában sem.Az oszlopnevek nem ismételhetők meg a
INCLUDElistában.Legalább egy kulcsoszlopot meg kell határozni egy indexben. A belefoglalt oszlopok maximális száma 1023. Ez a táblaoszlopok maximális száma mínusz 1.
A belefoglalt oszlopoktól függetlenül az indexkulcsoszlopoknak a meglévő 16 kulcsoszlopra vonatkozó korlátozásokat kell követniük, és az indexkulcs teljes mérete 900 bájt.
Javaslatok tervezése a belefoglalt oszlopokkal rendelkező indexekhez
Fontolja meg a nagy indexkulcs méretű nemclustered indexek újratervezését úgy, hogy csak a lekérdezések predikátumaiban, összesítésekben és rendezésekben használt oszlopok legyenek kulcsoszlopok. A lekérdezést lefedő összes többi oszlop tartalmazjon nem kulcsos oszlopokat is. Ily módon a lekérdezés lefedéséhez minden oszlop szükséges, de maga az indexkulcs kicsi és hatékony.
Tegyük fel például, hogy egy indexet szeretne megtervezni, hogy lefedje a következő lekérdezést.
SELECT AddressLine1,
AddressLine2,
City,
StateProvinceID,
PostalCode
FROM Person.Address
WHERE PostalCode BETWEEN N'98000' AND N'99999';
A lekérdezés lefedéséhez minden oszlopot meg kell határozni az indexben. Bár az összes oszlopot kulcsoszlopként definiálhatja, a kulcs mérete 334 bájt lenne. Mivel az egyetlen keresési feltételként használt oszlop az PostalCode oszlop, amelynek hossza 30 bájt, a jobb indexterv kulcsoszlopként definiálható PostalCode , és az összes többi oszlopot nem kulcsoszlopként tartalmazza.
Az alábbi utasítás létrehoz egy olyan indexet, amely tartalmazza az oszlopokat a lekérdezés lefedéséhez.
CREATE INDEX IX_Address_PostalCode
ON Person.Address (PostalCode)
INCLUDE (AddressLine1, AddressLine2, City, StateProvinceID);
Annak ellenőrzéséhez, hogy az index lefedi-e a lekérdezést, hozza létre az indexet, majd jelenítse meg a becsült végrehajtási tervet. Ha a végrehajtási terv indexkeresési operátort jelenít meg az IX_Address_PostalCode indexhez, a lekérdezést az index fedi le.
A belefoglalt oszlopokkal rendelkező indexek teljesítménybeli szempontjai
Ne hozzon létre nagyon nagy számú oszlopot tartalmazó indexeket. Annak ellenére, hogy az index több lekérdezésre is kiterjedhet, a teljesítménybeli előnye csökken, mert:
Kevesebb indexsor fér el egy lapon. Ez növeli a lemez I/O-kapacitását, és csökkenti a gyorsítótár hatékonyságát.
Az index tárolásához több lemezterületre van szükség. A beépített oszlopokban található varchar(max), nvarchar(max), varbinary(max) vagy xml adattípusok hozzáadása jelentősen növelheti a lemezterületre vonatkozó követelményeket. Ennek az az oka, hogy a rendszer az oszlopértékeket az indexlevél szintjére másolja. Ezért mind az indexben, mind az alaptáblában találhatók.
Az adatmódosítási teljesítmény csökken, mert számos oszlopot módosítani kell mind a bázistáblában, mind a nemclustered indexben.
Meg kell határoznia, hogy a lekérdezési teljesítmény növekedése meghaladja-e az adatmódosítási teljesítmény csökkenését és a lemezterület követelményeinek növekedését.
Egyedi indextervezési irányelvek
Az egyedi index garantálja, hogy az indexkulcs nem tartalmaz ismétlődő értékeket. Egyedi index létrehozása csak akkor lehetséges, ha az egyediség maga az adatok jellemzője. Ha például meg szeretné győződni arról, hogy a NationalIDNumber tábla oszlopában HumanResources.Employee lévő értékek egyediek, az elsődleges kulcs EmployeeIDesetén hozzon létre egy kényszert UNIQUE az NationalIDNumber oszlopon. A kényszer elutasít minden olyan kísérletet, amely ismétlődő nemzeti azonosítószámmal rendelkező sorokat próbál bevezetni.
Többoszlopos egyedi indexek esetén az index garantálja, hogy az indexkulcs értékeinek minden kombinációja egyedi legyen. Ha például egyedi index jön létre a , LastNameés FirstName az oszlopok kombinációjánMiddleName, akkor a tábla két sora nem rendelkezhet ugyanazokkal az értékekkel.
A fürtözött és a nem fürtözött indexek is egyediek lehetnek. Létrehozhat egy egyedi fürtözött indexet és több egyedi nem-fürtözött indexet ugyanazon a táblán.
Az egyedi indexek előnyei a következők:
- Az adatok egyediségét megkövetelő üzleti szabályok érvényesítve vannak.
- A lekérdezésoptimalizáló számára hasznos további információk találhatók.
A PRIMARY KEY vagy UNIQUE kényszer létrehozása automatikusan létrehoz egy egyedi indexet a megadott oszlopokon. Nincs jelentős különbség a UNIQUE kényszer létrehozása és a korlátozástól független egyedi index létrehozása között. Az adatérvényesítés ugyanúgy történik, és a lekérdezésoptimalizáló nem tesz különbséget a kényszer által létrehozott vagy manuálisan létrehozott egyedi indexek között. Azonban létre kell hoznia egy UNIQUE vagy PRIMARY KEY korlátozást az oszlopon, ha az üzleti szabályok érvényesítése a cél. Ezzel az index célja egyértelmű.
Egyedi indexelési szempontok
Egyedi index,
UNIQUEkényszer vagyPRIMARY KEYkényszer nem hozható létre, ha ismétlődő kulcsértékek találhatók az adatokban.Ha az adatok egyediek, és az egyediséget szeretné kikényszeríteni, a nemunikus indexek helyett egy egyedi index létrehozása ugyanazon oszlopok kombinációján további információt nyújt a lekérdezésoptimalizáló számára, amely hatékonyabb végrehajtási terveket hozhat létre.
UNIQUEEbben az esetben egy korlátozás vagy egy egyedi index létrehozása ajánlott.Az egyedi nem klaszteres indexek tartalmazhatnak nem kulcsként megadott oszlopokat is. További információ: A nemclustered indexekben szereplő oszlopok használata.
PRIMARY KEYkényszertől eltérően egyUNIQUEkényszer vagy egy egyedi index is létrehozható null értéket elfogadó oszloppal az indexkulcsban. Az egyediség érvényesítése érdekében két NULL egyenlőnek minősül. Ez például azt jelenti, hogy egy egyoszlopos egyedi indexben az oszlop csak a tábla egy sorához lehet NULL értékű.
Szűrt indextervezési irányelvek
A szűrt index egy optimalizált nemclustered index, amely különösen olyan lekérdezésekhez használható, amelyek a táblában lévő adatok kis részét igénylik. Az indexdefinícióban egy szűrő predikátumot használ a tábla sorainak egy részének indexeléséhez. A jól megtervezett szűrt indexek javíthatják a lekérdezési teljesítményt, csökkenthetik az indexfrissítés költségeit, és csökkenthetik az index tárolási költségeit a teljes táblázatos indexekhez képest.
A szűrt indexek a következő előnyöket biztosítják a teljes táblázatos indexekhez képest:
Továbbfejlesztett lekérdezési teljesítmény és tervminőség
A jól megtervezett szűrt index javítja a lekérdezési teljesítményt és a végrehajtási terv minőségét, mivel kisebb, mint egy teljes táblás nem klaszterezett index. A szűrt indexek szűrt statisztikákat tartalmaz, amelyek pontosabbak a teljes táblázatos statisztikáknál, mivel csak a szűrt index sorait fedik le.
Alacsonyabb indexfrissítési költségek
Az indexek csak akkor frissülnek, ha az adatkezelési nyelvi (DML-) utasítások hatással vannak az indexben lévő adatokra. A szűrt indexek csökkentik az indexfrissítés költségeit a teljes táblás, nemclustered indexekhez képest, mivel kisebbek, és csak akkor frissülnek, ha az index adatai érintettek. Nagy számú szűrt index létezhet, különösen akkor, ha ritkán módosuló adatokat tartalmaznak. Hasonlóképpen, ha egy szűrt index csak a gyakran érintett adatokat tartalmazza, az index kisebb mérete csökkenti a statisztikák frissítésének költségeit.
Alacsonyabb indextárolási költségek
A szűrt index létrehozása csökkentheti a nem fürtözött indexek lemeztárolását, ha nincs szükség teljes táblás indexre. Előfordulhat, hogy egy teljes táblás, nemclustered indexet több szűrt indexre is lecserélhet anélkül, hogy jelentősen növelné a tárolási követelményeket.
A szűrt indexek akkor hasznosak, ha az oszlopok jól definiált adathalmazokat tartalmaznak. Ilyenek például a következők:
Sok NULL-t tartalmazó oszlopok.
Heterogén oszlopok, amelyek adatkategóriákat tartalmaznak.
Olyan oszlopok, amelyek értéktartományokat, például mennyiségeket, időt és dátumokat tartalmaznak.
A szűrt indexek alacsonyabb frissítési költségei akkor a legfeltűnőbbek, ha az index sorainak száma kicsi a teljes táblázatos indexhez képest. Ha a szűrt index a tábla legtöbb sorát tartalmazza, a teljes táblázatos indexnél többe kerülhet a karbantartás. Ebben az esetben szűrt index helyett teljes táblázatos indexet kell használnia.
A szűrt indexek egy táblában vannak definiálva, és csak az egyszerű összehasonlító operátorokat támogatják. Ha összetett logikával rendelkező szűrőkifejezésre van szüksége, vagy több táblára hivatkozik, akkor indexelt számított oszlopot vagy indexelt nézetet kell létrehoznia.
Szűrt indextervezési szempontok
A hatékony szűrt indexek kialakítása érdekében fontos tisztában lenni azzal, hogy az alkalmazás milyen lekérdezéseket használ, és hogyan kapcsolódnak az adatok részhalmazaihoz. A jól definiált részhalmazokkal rendelkező adatokra néhány példa a sok NULL-t tartalmazó oszlopok, az értékek heterogén kategóriáival rendelkező oszlopok és az eltérő értéktartományokkal rendelkező oszlopok.
Az alábbi tervezési szempontok számos forgatókönyvet kínálnak arra vonatkozóan, hogy a szűrt indexek milyen előnyökkel járhatnak a teljes táblázatos indexekkel szemben.
Szűrt indexek az adatrészhalmazokhoz
Ha egy oszlop csak néhány releváns értékkel rendelkezik a lekérdezésekhez, létrehozhat egy szűrt indexet az értékek részhalmazán. Ha például az oszlop többnyire NULL értékű, és a lekérdezés csak nem NULL értékeket igényel, létrehozhat egy szűrt indexet, amely a nem NULL sorokat tartalmazza.
Az AdventureWorks mintaadatbázis például 2679 sorból áll Production.BillOfMaterials . Az EndDate oszlopban csak 199 sor található, amelyek nem NULL értéket tartalmaznak, a többi 2480 sor pedig NULL értéket tartalmaz. Az alábbi szűrt index olyan lekérdezéseket tartalmaz, amelyek az indexben meghatározott oszlopokat adják vissza, és csak olyan sorokat igényelnek, amelyekhez nem NULL értékű sorok szükségesek EndDate.
CREATE NONCLUSTERED INDEX FIBillOfMaterialsWithEndDate
ON Production.BillOfMaterials (ComponentID, StartDate)
WHERE EndDate IS NOT NULL;
A szűrt index FIBillOfMaterialsWithEndDate a következő lekérdezésre érvényes.
A becsült végrehajtási terv megjelenítése annak megállapításához, hogy a lekérdezésoptimalizáló használta-e a szűrt indexet.
SELECT ProductAssemblyID,
ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL
AND ComponentID = 5
AND StartDate > '20080101';
A szűrt indexek létrehozásáról és a szűrt index predikátum kifejezésének definiálásáról további információt a Szűrt indexek létrehozása című témakörben talál.
Heterogén adatok szűrt indexei
Ha egy tábla heterogén adatsorokkal rendelkezik, létrehozhat egy szűrt indexet egy vagy több adatkategóriához.
A táblázatban felsorolt Production.Product termékek például egyhez ProductSubcategoryIDvannak rendelve, amelyek viszont a Kerékpárok, Összetevők, Ruházat vagy Tartozékok termékkategóriákhoz vannak társítva. Ezek a kategóriák heterogének, mert a Production.Product táblázatban lévő oszlopértékek nincsenek szorosan korrelálva. Például az oszlopok Color, ReorderPoint, ListPrice, Weight, Class, és Style egyedi jellemzőkkel rendelkeznek az egyes termékkategóriákhoz. Tegyük fel, hogy gyakori lekérdezések vannak a tartozékokra vonatkozóan, amelyek 27 és 36 közötti alkategóriákkal rendelkeznek. A tartozékok lekérdezéseinek teljesítményének javításához hozzon létre egy szűrt indexet a tartozékok alkategóriáiban az alábbi példában látható módon.
CREATE NONCLUSTERED INDEX FIProductAccessories
ON Production.Product (ProductSubcategoryID, ListPrice)
INCLUDE (Name)
WHERE ProductSubcategoryID >= 27 AND ProductSubcategoryID <= 36;
A szűrt index FIProductAccessories a következő lekérdezésre vonatkozik, mivel a lekérdezési eredmények az indexben találhatók, és a lekérdezési tervhez nem szükséges hozzáférni az alaptáblához. A lekérdezési predikátum kifejezés ProductSubcategoryID = 33 például a szűrt index predikátum részhalmaza, a ProductSubcategoryID >= 27ProductSubcategoryID <= 36 lekérdezési predikátumban ProductSubcategoryID szereplő ListPrice oszlopok pedig az index kulcsoszlopai, a név pedig az index levélszintjében van tárolva belefoglalt oszlopként.
SELECT Name,
ProductSubcategoryID,
ListPrice
FROM Production.Product
WHERE ProductSubcategoryID = 33
AND ListPrice > 25.00;
Szűrt indexek kulcsoszlopai és tartalmazott oszlopai
Ajánlott kis számú oszlopot hozzáadni egy szűrt indexdefinícióhoz, csak akkor, ha szükséges ahhoz, hogy a lekérdezés-optimalizáló kiválaszthassa a lekérdezés végrehajtási tervéhez tartozó szűrt indexet. A lekérdezésoptimalizáló választhat egy szűrt indexet a lekérdezéshez, függetlenül attól, hogy az lefedi-e a lekérdezést. A lekérdezésoptimalizáló azonban nagyobb valószínűséggel választ szűrt indexet, ha az lefedi a lekérdezést.
Bizonyos esetekben a szűrt indexek lefedik a lekérdezést anélkül, hogy a szűrt indexkifejezés oszlopait kulcsként vagy a szűrt indexdefiníció oszlopai közé sorolták. Az alábbi irányelvek elmagyarázzák, hogy a szűrt index kifejezés egyik oszlopának kulcs- vagy beépített oszlopként kell szerepelnie a szűrt indexdefinícióban. A példák a korábban létrehozott szűrt indexre FIBillOfMaterialsWithEndDate vonatkoznak.
A szűrt indexkifejezés egyik oszlopának nem kell kulcsnak vagy oszlopnak lennie a szűrt indexdefinícióban, ha a szűrt indexkifejezés egyenértékű a lekérdezési predikátummal, és a lekérdezés nem adja vissza a szűrt indexkifejezés oszlopát a lekérdezés eredményeivel. Például a következő lekérdezést azért fedi le FIBillOfMaterialsWithEndDate, mert a lekérdezési predikátum egyenértékű a szűrőkifejezéssel, és EndDate nem szerepel a lekérdezés eredményeiben. Az FIBillOfMaterialsWithEndDate indexnek nincs szüksége EndDate kulcsként vagy oszlopként a szűrt indexdefinícióban.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
A szűrt indexkifejezés egyik oszlopának kulcsnak vagy oszlopnak kell lennie a szűrt index definíciójában, ha a lekérdezési predikátum az oszlopot olyan összehasonlításban használja, amely nem egyezik meg a szűrt indexkifejezéssel. A következő lekérdezés például azért érvényes, FIBillOfMaterialsWithEndDate mert a szűrt indexből kiválasztja a sorok egy részhalmazát. Ez azonban nem fedi le a következő lekérdezést, mert EndDate az összehasonlításban EndDate > '20040101'használják, ami nem egyenértékű a szűrt indexkifejezéssel. A lekérdezésfeldolgozó nem tudja végrehajtani ezt a lekérdezést a lekérdezés értékeinek EndDatevizsgálata nélkül.
EndDate Ezért kulcsnak vagy oszlopnak kell lennie a szűrt indexdefinícióban.
SELECT ComponentID,
StartDate
FROM Production.BillOfMaterials
WHERE EndDate > '20040101';
A szűrt indexkifejezés egyik oszlopának kulcsnak vagy oszlopnak kell lennie a szűrt index definíciójában, ha az oszlop szerepel a lekérdezés eredményhalmazában. Például nem fedi le a következő lekérdezést, FIBillOfMaterialsWithEndDate mert a EndDate lekérdezés eredményében szereplő oszlopot adja vissza.
EndDate Ezért kulcsnak vagy oszlopnak kell lennie a szűrt indexdefinícióban.
SELECT ComponentID,
StartDate,
EndDate
FROM Production.BillOfMaterials
WHERE EndDate IS NOT NULL;
A tábla fürtözött indexkulcsának nem kell kulcsnak vagy oszlopnak lennie a szűrt indexdefinícióban. A klaszterezett indexkulcs automatikusan bekerül az összes nem-klaszterezett indexbe, beleértve a szűrt indexeket is.
Adatkonvertálási operátorok a szűrő predikátumában
Ha a szűrt index szűrt indexkifejezésében megadott összehasonlító operátor implicit vagy explicit adatkonvertálást eredményez, hiba történik, ha az átalakítás az összehasonlító operátor bal oldalán történik. A megoldás a szűrt indexkifejezés írása az összehasonlító operátor jobb oldalán lévő adatkonvertálási operátorral (CAST vagy CONVERT).
Az alábbi példa egy különböző adattípusú oszlopokat tartalmazó táblát hoz létre.
CREATE TABLE dbo.TestTable
(
a INT,
b VARBINARY(4)
);
A következő szűrt indexdefinícióban az oszlop b implicit módon egész adattípussá alakul az 1 állandóval való összehasonlításhoz. Ez a hibaüzenet 10611-et generál, mert az átalakítás az operátor bal oldalán történik a szűrt predikátumban.
CREATE NONCLUSTERED INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = 1;
A megoldás az, hogy a jobb oldalon lévő állandót az oszlop btípusával megegyező típusúvá konvertálja, ahogyan az az alábbi példában látható:
CREATE INDEX TestTabIndex
ON dbo.TestTable (a, b)
WHERE b = CONVERT (VARBINARY(4), 1);
Ha az adatkonvertálást az összehasonlító operátor bal oldaláról jobbra helyezi át, az megváltoztathatja az átalakítás jelentését. Az előző példában, amikor az CONVERT operátort hozzáadták a jobb oldalra, az összehasonlítás egy int összehasonlításról varbináris összehasonlításra változott.
Oszlopcentrikus indexarchitektúra
Az oszloptároló index olyan technológia, amely az oszloptároló adatformátum használatával történik, az adatok tárolását, beolvasását és kezelését szolgálja. További információ: Oszlopcentrikus indexek: áttekintés.
A verzióval kapcsolatos információkért és az újdonságokért tekintse meg az oszlopcentrikus indexek újdonságai című témakört.
Ezen alapok ismerete megkönnyíti az oszlop adattár cikkek megértését, amelyek ismertetik, hogyan lehet hatékonyan használni ezt a technológiát.
Az adattárolás oszloptárat és sortárat használ
Az oszlopcentrikus indexek megvitatásakor a rowstore és a columnstore kifejezéseket használjuk az adattár formátumának kiemeléséhez. Az oszlopcentrikus indexek mindkét tárolási típust használják.

Az oszloptárak olyan adatok, amelyek logikailag táblázatként rendezve, sorokkal és oszlopokkal, és fizikailag oszlopalapú adatformátumban tárolódnak.
Az oszlopcentrikus indexek fizikailag a legtöbb adatot oszlopcentrikus formátumban tárolják. Oszlopcentrikus formátumban az adatok tömörítve és tömörítetlenül jelennek meg oszlopként. Nincs szükség a lekérdezés által nem kért többi érték kibontására az egyes sorokban. Így gyorsan beolvashatja egy nagy tábla teljes oszlopát.
A sortárak olyan adatok, amelyek logikailag táblázatként rendezve, sorokkal és oszlopokkal, majd sorszintű adatformátumban fizikailag tárolva. Ez volt a hagyományos módszer a relációs táblaadatok, mint például a csoportosított B+ faindex vagy a halom tárolására.
Az oszlopcentrikus indexek bizonyos sorokat fizikailag is tárolnak egy deltastore nevű sortár formátumban. A deltastore, más néven delta sorcsoportok, olyan sorok gyűjtőhelye, amelyek száma túl kicsi ahhoz, hogy alkalmasak legyenek oszloptárba való tömörítésre. Minden delta sorcsoport fürtözött B+ faindexként van implementálva, amely egy sortár.
A műveletek sorcsoportokon és oszlopszegmenseken hajthatók végre
Az oszlopcentrikus index kezelhető egységekbe csoportosítja a sorokat. Ezeket az egységeket sorcsoportnak nevezzük. A legjobb teljesítmény érdekében a sorcsoportok sorainak száma elég nagy ahhoz, hogy javítsa a tömörítési arányt, és elég kicsi ahhoz, hogy kihasználhassa a memóriaműveletek előnyeit.
Az oszlopcentrikus index például sorcsoportokon hajtja végre ezeket a műveleteket:
Sorcsoportokat tömörít az oszloptárba. A tömörítés egy sorcsoport minden oszlopszegmensén történik.
Sorcsoportokat egyesít egy
ALTER INDEX ... REORGANIZEművelet során, beleértve a törölt adatok eltávolítását is.Egy művelet során újra létrehozza az összes sorcsoportot
ALTER INDEX ... REBUILD.Jelentések a sorcsoport egészségi állapotáról és töredezettségéről a dinamikus kezelői nézetekben (DMV-k).
A deltastore egy vagy több, delta rowgroups nevű sorcsoportból áll. Minden delta sorcsoport egy fürtözött B+ faindex, amely kis méretű tömeges terheléseket tárol és adatokat illeszt be, amíg a sorcsoport el nem éri az 1 048 576 sort. Ekkor a tuple-mover nevű folyamat automatikusan tömörít egy zárt sorcsoportot az oszloptárba.
További információ a sorcsoport állapotáról: sys.dm_db_column_store_row_group_physical_stats.
Tip
Ha túl sok kis sorcsoport van, az csökkenti az oszlopcentrikus index minőségét. Az újrarendezési művelet egyesíti a kisebb sorcsoportokat egy belső küszöbérték-szabályzatot követve, amely meghatározza a törölt sorok eltávolításának és a tömörített sorcsoportok kombináljának módját. Az egyesítés után az index minősége javul.
Az SQL Server 2019 (15.x) és újabb verzióiban a tuple-mover működését egy háttértömörítési feladat támogatja, amely automatikusan tömöríti a belső küszöbérték által meghatározott ideig létező kisebb, nyitott delta sorcsoportokat, vagy egyesíti azokat a tömörített sorcsoportokat, amelyekből nagyszámú sor törlésre került.
Minden oszlopnak vannak értékei az egyes sorcsoportokban. Ezeket az értékeket oszlopszegmenseknek nevezzük. Minden sorcsoport egy oszlopszegmenst tartalmaz a tábla minden oszlopához. Minden oszlop egy oszlopszegmenst tartalmaz minden sorcsoportban.

Amikor az oszlopcentrikus index tömörít egy sorcsoportot, az egyes oszlopszegmenseket külön tömöríti. Egy teljes oszlop kibontásához az oszlopcentrikus indexnek csak egy oszlopszegmenst kell feloldania az egyes sorcsoportokból.
Kis terhelések és beszúrások a deltastore-ba kerülnek
Az oszlopcentrikus index javítja az oszlopcentrikus tömörítést és a teljesítményt, ha egyszerre legalább 102 400 sort tömörít az oszlopcentrikus indexbe. A sorok tömeges tömörítése érdekében az oszlopstore index kis adatokat felhalmoz, és beszúrja őket a deltastore-ba. A deltastore-műveleteket a háttérben kezeli a rendszer. A lekérdezési eredmények visszaadásához a fürtözött oszlopcentrikus index egyesíti az oszloptárból és a deltastore-ból származó lekérdezési eredményeket.
A sorok a deltastore-ba kerülnek, amikor a következők:
INSERT INTO ... VALUESutasítással beszúrva.A tömeges terhelés végén 102 400-nál kevesebbet tesznek ki.
Updated. Minden frissítés törlésként és beszúrásként van implementálva.
A deltastore a töröltként megjelölt, de az oszloptárból fizikailag még nem törölt törölt törölt sorok azonosítóinak listáját is tárolja.
Ha a delta sorcsoportok megteltek, a rendszer tömöríti őket az oszloptárba
A fürtözött oszlopalapú indexek legfeljebb 1 048 576 sort gyűjtenek össze minden delta sorcsoportban, mielőtt a sorcsoport tömörítésre kerülne az oszloptárolóba. Ez javítja az oszlopcentrikus index tömörítését. Amikor egy delta sorcsoport eléri a sorok maximális számát, áttér egy OPEN állapotra CLOSED . Egy tuple-mover nevű háttérfolyamat ellenőrzi a zárt sorcsoportokat. Ha a folyamat egy zárt sorcsoportot talál, tömöríti a sorcsoportot, és az oszloptárba tárolja.
Ha egy delta sorcsoport tömörítése megtörtént, a meglévő delta sorcsoport áttűnik az TOMBSTONE állapotba, amelyet később eltávolít a csoportmozgató, ha már nincs rá hivatkozás, és az új tömörített sorcsoportot úgy jelöli, mint COMPRESSED.
További információ a sorcsoport állapotáról: sys.dm_db_column_store_row_group_physical_stats.
Az ALTER INDEX használatával kényszerítheti a delta sorcsoportokat az oszloptárba az index újraépítéséhez vagy átrendezéséhez. Ha a tömörítés során memóriaterhelés tapasztalható, az oszlopcentrikus index csökkentheti a tömörített sorcsoport sorainak számát.
Minden táblapartíció saját sorcsoportokkal és delta sorcsoportokkal rendelkezik
A particionálás fogalma megegyezik a fürtözött indexekben, a halomban és az oszlopcentrikus indexekben. A tábla particionálása a táblázatot oszlopértékek tartománya szerint kisebb sorokra osztja. Gyakran használják az adatok kezelésére. Létrehozhat például egy partíciót minden adatévhez, majd partícióváltással archiválhatja a régi adatokat a kevésbé költséges tároláshoz.
A sorcsoportok mindig egy táblapartícióban vannak definiálva. Az oszlopcentrikus index particionálásakor minden partíció saját tömörített sorcsoportokkal és delta sorcsoportokkal rendelkezik. A nem particionált táblák egyetlen partíciót tartalmaznak.
Tip
Fontolja meg a táblaparticionálás használatát, ha el kell távolítania az adatokat az oszloptárból. A már nem szükséges partíciók ki- és csonkolása hatékony stratégia az adatok törlésére anélkül, hogy töredezettség lenne az oszloptárban.
Minden partíció több delta sorcsoporttal is rendelkezhet
Minden partíció több deltasorcsoporttal is rendelkezhet. Ha az oszlopcentrikus indexnek adatokat kell hozzáadnia egy delta sorcsoporthoz, és a delta sorcsoportot egy másik tranzakció zárolja, az oszlopcentrikus index megpróbál zárolni egy másik delta sorcsoportot. Ha nincsenek elérhető delta sorcsoportok, az oszlopcentrikus index létrehoz egy új delta sorcsoportot. Egy 10 partíciót tartalmazó táblázat például könnyen rendelkezhet 20 vagy több delta sorcsoporttal.
Oszlop- és sorindexek kombinálása ugyanazon a táblán
A nem-klaszterezett index a mögöttes tábla sorainak és oszlopainak egy részét vagy mindegyikét tartalmazó másolatot tartalmaz. Az index a tábla egy vagy több oszlopaként van definiálva, és egy választható feltétellel rendelkezik, amely szűri a sorokat.
Létrehozhat egy frissíthető , nemclustered oszlopcentrikus indexet egy sortártáblán. Az oszlopcentrikus index tárolja az adatok másolatát, így további tárterületre van szüksége. Az oszlopcentrikus index adatai azonban sokkal kisebb méretűre tömörödnek, mint amennyit a sortártábla igényel. Ezzel egyszerre végezhet elemzéseket az oszlop-tárolós indexen és az OLTP munkaterheléseken a sor-alapú indexen. Az oszloptár akkor frissül, amikor az adatok megváltoznak a sortártáblában, így mindkét index ugyanazon adatokon dolgozik.
A soros táblának lehet egy nem klaszterezett oszlopalapú indexe. További információ: Oszlopcentrikus indexek – tervezési útmutató.
Fürtözött oszlopalapú táblán lehet egy vagy több nemfürtözött rowstore index. Ezzel hatékony táblakereséseket hajthat végre a mögöttes oszloptárban. Más lehetőségek is elérhetővé válnak. Az egyediséget például a sortártáblára vonatkozó korlátozással UNIQUE kényszerítheti ki. Ha egy nemunikus érték nem illeszthető be a sortártáblába, az adatbázismotor sem szúrja be az értéket az oszloptárba.
Nem fürtözött oszlopalapú teljesítmény szempontjai
A nem klaszterezett oszlopalapú index definíciója támogatja a szűrt feltétel használatát. Az oszlopcentrikus indexek hozzáadásának teljesítményének minimalizálása érdekében szűrőkifejezéssel hozzon létre nemclustered oszlopcentrikus indexet csak az elemzéshez szükséges adathalmazon.
A memóriaoptimalizált táblák egy oszlopcentrikus indexet tartalmazhatnak. A tábla létrehozásakor vagy később az ALTER TABLE használatával is létrehozhatja.
További információ: Oszlopcentrikus indexek – lekérdezési teljesítmény.
Memóriaoptimalizált kivonatindex tervezési irányelvei
AzIn-Memory OLTP használatakor minden memóriaoptimalizált táblának rendelkeznie kell legalább egy indexkel. A memóriaoptimalizált táblák esetében minden index memóriaoptimalizált is. A kivonatindexek a memóriaoptimalizált táblák egyik lehetséges indextípusai. További információ: Indexek Memory-Optimized táblákon.
Memóriaoptimalizált kivonatindex architektúra
A kivonatindex egy mutatótömbből áll, és a tömb minden elemét kivonatgyűjtőnek nevezzük.
- Minden vödör 8 bájt, amelyet a kulcsbejegyzések láncolt listájának memóriacímének tárolására használnak.
- Minden bejegyzés egy indexkulcs értéke, valamint a mögöttes memóriaoptimalizált táblában lévő megfelelő sor címe.
- Minden bejegyzés az aktuális gyűjtőhöz láncolt bejegyzések hivatkozáslistájában a következő bejegyzésre mutat.
A gyűjtők számát az index létrehozásakor kell megadni:
- Minél alacsonyabb a vödrök aránya a táblázatsorokhoz vagy a különböző értékekhez képest, annál hosszabb az átlagos vödörhivatkozások listája.
- A rövid hivatkozáslisták gyorsabbak, mint a hosszú hivatkozáslisták.
- A hash indexekben lévő gyűjtők maximális száma 1 073 741 824.
Tip
Az adataihoz megfelelő BUCKET_COUNT meghatározásához tekintse meg a hash index gyűjtőszámának konfigurálását.
A kivonatfüggvény az indexkulcs oszlopaira lesz alkalmazva, és a függvény eredménye határozza meg, hogy melyik gyűjtőbe tartozik a kulcs. Minden vödörhöz tartozik egy mutató azokhoz a sorokhoz, amelyeknek a kivonatolt kulcsértékeit az adott vödörhez rendelik.
A kivonatindexekhez használt kivonatolási függvény a következő jellemzőkkel rendelkezik:
- Az adatbázismotor egyetlen kivonatfüggvényt használ az összes kivonatindexhez.
- A kivonatfüggvény determinisztikus. A rendszer mindig ugyanazt a bemenetikulcs-értéket rendeli hozzá a kivonatindex ugyanazon gyűjtőhöz.
- Előfordulhat, hogy több indexkulcs is ugyanarra a hash vödörre van leképezve.
- A kivonatfüggvény kiegyensúlyozott, ami azt jelenti, hogy az indexkulcsértékek eloszlása a kivonatgyűjtők között általában Poisson- vagy haranggörbék eloszlását követi, nem pedig egyenes lineáris eloszlást.
- A Poisson-eloszlás nem páros eloszlás. Az indexkulcs értékei nem egyenletesen vannak elosztva a kivonatgyűjtőkben.
- Ha két indexkulcs ugyanarra a kivonatgyűjtőre van leképezve, akkor a rendszer kivonat-ütközést észlelt. A hash ütközések nagy száma befolyásolhatja a teljesítményt az olvasási műveleteknél. Reális cél, hogy a gyűjtők 30 százaléka két különböző kulcsértéket tartalmazzon.
A hash index és a gyűjtők közötti kölcsönhatás az alábbi képen van összefoglalva.

A kivonatindex gyűjtőszámának konfigurálása
A kivonatindex gyűjtőszáma az index létrehozásakor van megadva, és a ALTER TABLE...ALTER INDEX REBUILD szintaxis használatával módosítható.
A legtöbb esetben a vödrök száma az indexkulcs különböző értékeinek számánál 1-2-szerese kell, hogy legyen.
Előfordulhat, hogy nem mindig tudja előre jelezni, hogy egy adott indexkulcs hány értékkel rendelkezik. A teljesítmény általában akkor is jó, ha az BUCKET_COUNT érték a kulcsértékek tényleges számának 10-szeresén belül van, és a túlbecsülés általában jobb, mint az alulbecsülés.
Túl kevés vödörnek a következő hátrányai lehetnek:
- Több kivonat-ütközés különböző kulcsértékek esetén.
- Minden különálló értéknek ugyanazt a gyűjtőt kell megosztania egy másik különböző értékkel.
- A gyűjtőnkénti átlagos lánchossz növekszik.
- Minél hosszabb a gyűjtőlánc, annál lassabb az egyenlőségi keresések sebessége az indexben.
A túl sok vödörnek a következő hátrányai lehetnek:
- A gyűjtők túl magas száma több üres gyűjtőt eredményezhet.
- Az üres vödrök befolyásolják a teljes index-ellenőrzések teljesítményét. Ha rendszeresen végeznek vizsgálatokat, érdemes lehet a különböző indexkulcsértékek számához közeli gyűjtőszámot választani.
- Az üres vödrök memóriát használnak, noha minden vödör csak 8 bájtot használ.
Note
Több vödör hozzáadása nem tesz semmit annak érdekében, hogy csökkentse a duplikált értéket tartalmazó bejegyzések összeláncolását. Az értékkettőzés mértéke annak eldöntésére szolgál, hogy a kivonatindex vagy a nem klaszterezett index a megfelelő indextípus-e, és nem a gyűjtőszám kiszámításához.
A kivonatindexek teljesítménybeli szempontjai
A kivonatindex teljesítménye:
- Kiváló, ha a záradék predikátuma
WHEREpontos értéket ad meg a kivonatindexkulcs minden oszlopához. A kivonatindex egy egyenlőtlenségi predikátum alapján vizsgálatra vált. - Gyenge, ha a záradék predikátuma
WHEREértéktartományt keres az indexkulcsban. - Nem megfelelő, ha a záradékban szereplő
WHEREpredikátum egy adott értéket határoz meg egy kétoszlopos kivonatindexkulcs első oszlopához, de nem ad meg értéket a kulcs többi oszlopához.
Tip
A predikátumnak tartalmaznia kell a kivonatindexkulcs összes oszlopát. A hash index a teljes kulcsot használja az indexbe való kereséshez.
Ha hash indexet használ, és az egyedi indexkulcsok száma több mint 100-szor kisebb, mint a sorok száma, fontolja meg nagyobb vödörszám használatát a nagy sorláncok elkerülése érdekében, vagy használjon nem klaszterezett indexet.
Kivonatindex létrehozása
Kivonatindex létrehozásakor vegye figyelembe a következő szempontokat:
- A kivonatindexek csak memóriaoptimalizált táblázatban létezhetnek. Nem létezhet lemezalapú táblában.
- A hash-index alapértelmezés szerint nem egyedi, de egyedivé nyilvánítható.
Az alábbi példa egy egyedi kivonatindexet hoz létre:
ALTER TABLE MyTable_memop ADD INDEX ix_hash_Column2
UNIQUE HASH (Column2) WITH (BUCKET_COUNT = 64);
Sorverziók és szemétgyűjtés memóriaoptimalizált táblákban
A memóriaoptimalizált táblázatban, amikor egy sorra hatással van egy UPDATE utasítás, a táblázat létrehozza a sor frissített verzióját. A frissítési tranzakció során előfordulhat, hogy más munkamenetek is beolvashatják a sor régebbi verzióját, így elkerülheti a sorzároláshoz kapcsolódó teljesítménycsökkenést.
A kivonatindex bejegyzéseinek különböző verzióival is rendelkezhet, hogy megfeleljen a frissítésnek.
Később, amikor a régebbi verziókra már nincs szükség, egy szemétgyűjtési (GC) szál bejárja a gyűjtőket és azok hivatkozáslistáit, hogy megtisztítsa a régi bejegyzéseket. A GC-szál akkor teljesít jobban, ha a hivatkozáslistalánc hossza rövid. További információ: In-Memory OLTP szemétgyűjtés.
Memóriaoptimalizált nem fürtözött indextervezési irányelvek
A kivonatindexeken kívül a nemclustered indexek a memóriaoptimalizált táblák egyéb lehetséges indextípusai. További információ: Indexek Memory-Optimized táblákon.
Memóriaoptimalizált nem halmozott indexarchitektúra
A memóriaoptimalizált táblák nemclustered indexei egy Bw-tree nevű adatstruktúrával implementálhatók, amelyet eredetileg a Microsoft Research 2011-ben készített és ismertet. A Bw-fa a B-fa zár- és reteszmentes változata. További információért lásd A Bw-fa: Egy B-fa új hardverplatformokhoz.
Átfogó szinten a Bw-fa úgy értendő, mint egy oldalazonosítók szerint szervezett oldaltérkép (PidMap), egy oldalazonosítók lefoglalására és újrafelhasználására szolgáló rendszer (PidAlloc), valamint egymáshoz és a térképhez kapcsolódó oldalak halmaza. Ez a három magas szintű alkomponens egy Bw-fa alapvető belső szerkezetét alkotja.
A struktúra hasonló a normál B-fához abban az értelemben, hogy minden oldalhoz vannak rendezett kulcsértékek, és az indexben vannak szintek, amelyek egy alacsonyabb szintre mutatnak, a levélszintek pedig egy adatsorra mutatnak. Azonban számos különbség van.
A kivonatindexekhez hasonlóan több adatsor is összekapcsolható a verziószámozás támogatásához. A szintek közötti lapmutatók logikai lapazonosítók, amelyek eltolódások egy lapleképezési táblázatban, amely viszont tartalmazza az egyes lapok fizikai címét.
Az indexlapok nincsenek helyben frissítve. Erre a célra új deltaoldalakat vezetünk be.
- Az oldalfrissítésekhez nincs szükség reteszelésre vagy zárolásra.
- Az indexlapok mérete nem rögzített.
Az egyes nem levélszintű lapok kulcsértéke az a legmagasabb érték, amelyet az a gyermek oldal tartalmaz, amire mutat, és minden sor szintén tartalmazza a lap logikai oldalazonosítóját. A levélszintű oldalakon a kulcsértékkel együtt tartalmazza az adatsor fizikai címét.
A pontkeresések hasonlóak a B-fákhoz, azzal a kivétellel, hogy mivel a lapok csak egy irányba vannak csatolva, az Adatbázis Motor a jobb oldali oldal mutatókat követi, ahol minden nemlevél oldal a gyermek legmagasabb értékét használja, nem pedig a legalacsonyabb értéket, mint a B-fában.
Ha egy levélszintű lapot módosítani kell, az adatbázismotor nem módosítja magát a lapot. Az adatbázismotor ehelyett létrehoz egy változásrekordot, amely leírja a módosítást, és hozzáfűzi az előző laphoz. Ezután frissíti az előző oldal oldaltérkép-táblázatának címét is a lap fizikai címévé váló deltarekord címére.
A Bw-fa szerkezetének kezeléséhez három különböző műveletre lehet szükség: összevonás, felosztás és egyesítés.
Delta konszolidáció
A deltarekordok hosszú lánca végül csökkentheti a keresési teljesítményt, mivel hosszú láncbejárást igényelhet egy indexen keresztüli keresés során. Ha egy új deltarekordot ad hozzá egy olyan lánchoz, amely már 16 elemet tartalmaz, a rendszer a deltarekordok módosításait a hivatkozott indexlapra konszolidálja, majd újraépül a lap, beleértve az összesítést kiváltó új deltarekord által jelzett módosításokat is. Az újonnan újjáépített lap lapazonosítója ugyanaz, de új memóriacímmel rendelkezik.

Oldal felosztása
A Bw-fában lévő indexlapok igény szerint növekednek, kezdve attól, hogy egyetlen sort tárolnak, és legfeljebb 8 KB-t tárolnak. Miután az indexlap 8 KB-ra nőtt, egyetlen sor új beszúrása az indexlap felosztását eredményezi. Egy belső lap esetében ez azt jelenti, hogy ha nincs több hely egy másik kulcsérték és mutató hozzáadásához, és egy levéloldal esetében ez azt jelenti, hogy a sor túl nagy lenne ahhoz, hogy elférjen a lapon, miután az összes deltarekord be lett építve. A levéloldal oldalfejlécében található statisztikai adatok nyomon követik, hogy mennyi hely szükséges a deltarekordok összevonásához. Ez az információ az egyes új deltarekordok hozzáadásakor módosul.
A felosztási művelet két atomi lépésben történik. A következő ábrán tegyük fel, hogy egy levéllap felosztásra kényszerít, mert egy 5 értékű kulcsot szúrnak be, és létezik egy nem levél szintű oldal, amely az aktuális levélszintű lap végére mutat (4. kulcsérték).

1. lépés: Foglaljon le két új lapot P1 , és P2ossza fel a sorokat a régi P1 lapról ezekre az új oldalakra, beleértve az újonnan beszúrt sort is. Az oldalleképezési táblázat új pontját használja a rendszer az oldal P2fizikai címének tárolására. Lapok P1 , és P2 egyelőre nem érhetők el egyidejű műveletekhez. Emellett a logikai mutató a P1-ról a P2-re van állítva. Ezután egy atomi lépésben frissítse az oldalleképezési táblázatot, hogy az egérmutató régiről P1 újra P1változzon.
2. lépés: A nem levél lap erre mutat: P1, de nincs közvetlen mutató a nem levél lapról a P2-re.
P2 kizárólag P1-n keresztül érhető el. Ha egy nem kiszolgáló lapról szeretne mutatót létrehozni P2-ra, foglaljon le egy új, nem kiszolgáló lapot (belső indexlapot), másolja ki az összes sort a régi nem kiszolgáló lapról, és adjon hozzá egy új sort, amely P2-re mutat. Ha ez megtörtént, egy atomi lépésben frissítse az oldaltérképező táblázatot, hogy a mutatót a régi nem levél oldalról az új nem levél oldalra módosítsa.
Lap egyesítése
Ha egy DELETE művelet eredményeként egy lap a maximális oldalméret 10 százalékánál (8 KB) kisebb, vagy egyetlen sor van rajta, a lap össze lesz egyesítve egy összefüggő oldallal.
Ha egy sor törlődik egy lapról, a rendszer hozzáad egy delta rekordot a törléshez. Emellett ellenőrzi, hogy az indexlap (nemleaf oldal) jogosult-e az egyesítésre. Ez az ellenőrzés ellenőrzi, hogy a sor törlése után fennmaradó terület kisebb-e, mint a maximális oldalméret 10 százaléka. Ha ez megfelel, az egyesítés három atomi lépésben történik.
Az alábbi képen tegyük fel, hogy egy DELETE művelet törli a kulcsértéket 10.

1. lépés: Létrejön egy kulcsértéket 10 (kék háromszöget) jelképező deltalap, amelynek mutatója a nemleaf oldalon Pp1 az új deltaoldalra van állítva. Emellett létrejön egy speciális egyesítés-delta oldal (zöld háromszög), amely a deltaoldalra mutatva van összekapcsolva. Ebben a szakaszban mindkét oldal (delta oldal és egyesítési-delta oldal) nem látható egyetlen egyidejű tranzakcióban sem. Egy atomi lépésben a lapleképezési táblázat levélszintű lapjára P1 mutató mutató frissül, hogy a merge-delta lapra mutasson. A lépés után a 10 kulcsérték Pp1 bejegyzése most az egyesítési-delta oldalra mutat.
2. lépés: El kell távolítani a nemleaf oldalon 7 lévő kulcsértéket Pp1 képviselő sort, és a kulcsérték 10 bejegyzése a következőre módosul.P1 Ehhez egy új nemleaf lap Pp2 lesz lefoglalva, és az összes sor Pp1 ki lesz másolva, kivéve a kulcsértéket 7képviselő sort, majd a kulcsérték 10 sorát a rendszer az oldalra P1mutatásra frissíti. Ha ez megtörtént, egy atomi lépésben a lapleképezési táblázat bejegyzése Pp1 úgy lesz frissítve, hogy Pp2-re mutasson.
Pp1 már nem érhető el.
3. lépés: A levélszintű lapok P2P1 egyesülnek, és eltávolítják a delta oldalakat. Ehhez kiosztanak egy új lapot P3, és az újba P2 be lesznek illesztve a P1 és P3 sorok egyesítése, valamint a delta lap változásai. Ezután egy atomi lépésben az oldalleképezési táblázat lapra P1 mutató bejegyzése frissül, hogy az oldalra P3mutasson.
Teljesítménybeli szempontok a memóriaoptimalizált nem klaszteres indexekhez
A nemclustered index teljesítménye jobb, mint a kivonatindexek esetében, amikor egy memóriaoptimalizált táblát kérdez le egyenlőtlenségi predikátumokkal.
A memóriaoptimalizált tábla egy oszlopa része lehet mind egy hash-indexnek, mind egy nem klaszterezett indexnek.
Ha egy nemclustered index egyik kulcsoszlopa sok duplikált értékkel rendelkezik, a teljesítmény csökkenhet a frissítések, beszúrások és törlések esetében. Ebben a helyzetben a teljesítmény javításának egyik módja egy olyan oszlop hozzáadása, amely jobb szelektivitást tartalmaz az indexkulcsban.
Metaadatok indexelése
Az index metaadatainak, például az indexdefinícióknak, a tulajdonságoknak és az adatstatisztikáknak a vizsgálatához használja a következő rendszernézeteket:
- sys.objects
- sys.indexes
- sys.index_columns
- sys.columns
- sys.types
- sys.partitions
- sys.internal_partitions
- sys.dm_db_index_usage_stats
- sys.dm_db_partition_stats
- sys.dm_db_index_operational_stats
Az előző nézetek minden indextípusra érvényesek. Oszlopcentrikus indexek esetén használja a következő nézeteket is:
- sys.column_store_row_groups
- sys.column_store_segments
- sys.column_store_dictionaries
- sys.dm_column_store_object_pool
- sys.dm_db_column_store_row_group_operational_stats
- sys.dm_db_column_store_row_group_physical_stats
Oszlopcentrikus indexek esetén a rendszer az összes oszlopot a metaadatokban tárolja a benne foglalt oszlopok szerint. Az oszlopalapú index nem rendelkezik kulcsoszlopokkal.
A memóriaoptimalizált táblák indexeihez használja a következő nézeteket is:
- sys.hash_indexes
- sys.dm_db_xtp_hash_index_stats
- sys.dm_db_xtp_index_stats
- sys.dm_db_xtp_nonclustered_index_stats
- sys.dm_db_xtp_object_stats
- sys.dm_db_xtp_table_memory_stats
- sys.memory_optimized_tables_internal_attributes
Kapcsolódó tartalom
- INDEX LÉTREHOZÁSA (Transact-SQL)
- Indexkarbantartás optimalizálása a lekérdezési teljesítmény javítása és az erőforrás-felhasználás csökkentése
- particionált táblák és indexek
- Indexek a Memory-Optimized táblákon
- Oszlopalapú indexek: áttekintés
- Számított oszlopok indexei
- Nem klaszterezett indexek optimalizálása hiányzó indexjavaslatokkal