Rekomendasi untuk respons insiden keamanan
Berlaku untuk rekomendasi daftar periksa Azure Well-Architected Framework Security:
| SE:12 | Tentukan dan uji prosedur respons insiden yang efektif yang mencakup spektrum insiden, dari masalah yang dilokalkan hingga pemulihan bencana. Tentukan dengan jelas tim atau individu mana yang menjalankan prosedur. |
|---|
Panduan ini menjelaskan rekomendasi untuk menerapkan respons insiden keamanan untuk beban kerja. Jika ada kompromi keamanan terhadap sistem, pendekatan respons insiden sistematis membantu mengurangi waktu yang diperlukan untuk mengidentifikasi, mengelola, dan mengurangi insiden keamanan. Insiden ini dapat mengancam kerahasiaan, integritas, dan ketersediaan sistem dan data perangkat lunak.
Sebagian besar perusahaan memiliki tim operasi keamanan pusat (juga dikenal sebagai Security Operations Center (SOC), atau SecOps). Tanggung jawab tim operasi keamanan adalah mendeteksi, memprioritaskan, dan melakukan triase serangan potensial dengan cepat. Tim juga memantau data telemetri terkait keamanan dan menyelidiki pelanggaran keamanan.
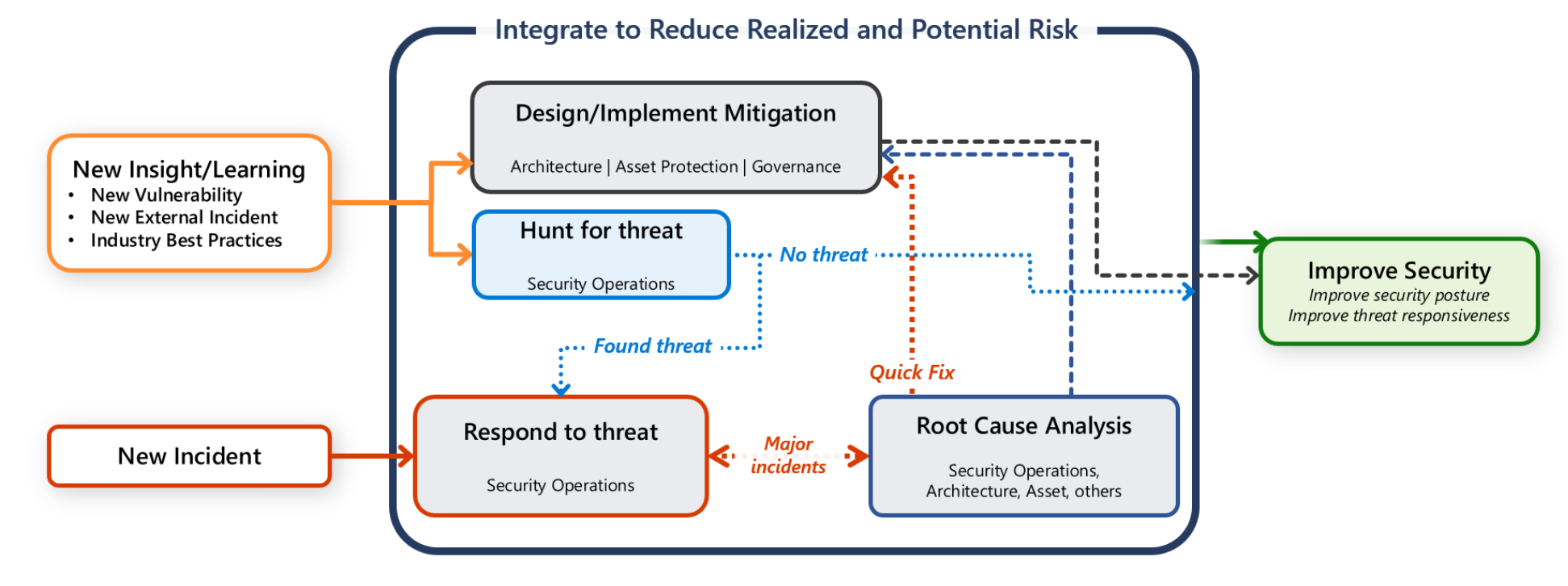
Namun, Anda juga memiliki tanggung jawab untuk melindungi beban kerja Anda. Penting bahwa setiap aktivitas komunikasi, investigasi, dan perburuan adalah upaya kolaboratif antara tim beban kerja dan tim SecOps.
Panduan ini memberikan rekomendasi bagi Anda dan tim beban kerja Anda untuk membantu Anda mendeteksi, melakukan triase, dan menyelidiki serangan dengan cepat.
Definisi
| Istilah | Definisi |
|---|---|
| Peringatan | Pemberitahuan yang berisi informasi tentang insiden. |
| Keakuratan pemberitahuan | Akurasi data yang menentukan pemberitahuan. Pemberitahuan dengan keakuratan tinggi berisi konteks keamanan yang diperlukan untuk mengambil tindakan segera. Pemberitahuan dengan keakuratan rendah tidak memiliki informasi atau berisi kebisingan. |
| Positif palsu | Pemberitahuan yang menunjukkan insiden yang tidak terjadi. |
| Insiden | Peristiwa yang menunjukkan akses tidak sah ke sistem. |
| Respons Insiden | Proses yang mendeteksi, merespons, dan mengurangi risiko yang terkait dengan insiden. |
| Triase | Operasi respons insiden yang menganalisis masalah keamanan dan memprioritaskan mitigasinya. |
Strategi desain utama
Anda dan tim Anda melakukan operasi respons insiden saat ada sinyal atau pemberitahuan untuk potensi penyusupan. Pemberitahuan dengan keakuratan tinggi berisi konteks keamanan yang cukup yang memudahkan analis untuk membuat keputusan. Pemberitahuan dengan keakuratan tinggi menghasilkan jumlah positif palsu yang rendah. Panduan ini mengasumsikan bahwa sistem peringatan memfilter sinyal keakuratan rendah dan berfokus pada peringatan dengan keakuratan tinggi yang mungkin menunjukkan insiden nyata.
Menetapkan pemberitahuan insiden
Pemberitahuan keamanan perlu menjangkau orang yang sesuai di tim Anda dan di organisasi Anda. Buat titik kontak yang ditunjuk di tim beban kerja Anda untuk menerima pemberitahuan insiden. Pemberitahuan ini harus mencakup informasi sebanyak mungkin tentang sumber daya yang disusupi dan sistem. Pemberitahuan harus menyertakan langkah berikutnya, sehingga tim Anda dapat mempercepat tindakan.
Kami menyarankan agar Anda mencatat dan mengelola pemberitahuan dan tindakan insiden dengan menggunakan alat khusus yang menyimpan jejak audit. Dengan menggunakan alat standar, Anda dapat mempertahankan bukti yang mungkin diperlukan untuk potensi penyelidikan hukum. Cari peluang untuk menerapkan otomatisasi yang dapat mengirim pemberitahuan berdasarkan tanggung jawab pihak yang bertanggung jawab. Jaga rantai komunikasi dan pelaporan yang jelas selama insiden.
Manfaatkan solusi manajemen peristiwa informasi keamanan (SIEM) dan solusi respons otomatis orkestrasi keamanan (SOAR) yang disediakan organisasi Anda. Atau, Anda dapat memperoleh alat manajemen insiden dan mendorong organisasi Anda untuk menstandarkannya untuk semua tim beban kerja.
Menyelidiki dengan tim triase
Anggota tim yang menerima pemberitahuan insiden bertanggung jawab untuk menyiapkan proses triase yang melibatkan orang yang sesuai berdasarkan data yang tersedia. Tim triase, yang sering disebut tim jembatan, harus menyetujui mode dan proses komunikasi. Apakah insiden ini memerlukan diskusi asinkron atau panggilan jembatan? Bagaimana tim harus melacak dan mengomunikasikan kemajuan penyelidikan? Di mana tim dapat mengakses aset insiden?
Respons insiden adalah alasan penting untuk selalu memperbarui dokumentasi, seperti tata letak arsitektur sistem, informasi pada tingkat komponen, klasifikasi privasi atau keamanan, pemilik, dan titik kontak utama. Jika informasi tidak akurat atau kedaluarsa, tim jembatan membuang waktu yang berharga mencoba memahami cara kerja sistem, siapa yang bertanggung jawab atas setiap area, dan apa efek dari peristiwa tersebut.
Untuk penyelidikan lebih lanjut, libatkan orang yang sesuai. Anda mungkin menyertakan manajer insiden, petugas keamanan, atau prospek yang berorientasi pada beban kerja. Agar triase tetap fokus, kecualikan orang yang berada di luar cakupan masalah. Terkadang tim terpisah menyelidiki insiden tersebut. Mungkin ada tim yang awalnya menyelidiki masalah dan mencoba mengurangi insiden, dan tim khusus lain yang mungkin melakukan forensik untuk penyelidikan mendalam untuk memastikan masalah yang luas. Anda dapat mengkarantina lingkungan beban kerja untuk memungkinkan tim forensik melakukan penyelidikan mereka. Dalam beberapa kasus, tim yang sama mungkin menangani seluruh penyelidikan.
Pada fase awal, tim triase bertanggung jawab untuk menentukan vektor potensial dan efeknya terhadap kerahasiaan, integritas, dan ketersediaan (juga disebut CIA) sistem.
Dalam kategori CIA, tetapkan tingkat keparahan awal yang menunjukkan kedalaman kerusakan dan urgensi remediasi. Tingkat ini diharapkan berubah dari waktu ke waktu karena lebih banyak informasi ditemukan dalam tingkat triase.
Dalam fase penemuan, penting untuk menentukan rencana tindakan dan komunikasi segera. Apakah ada perubahan pada status sistem yang sedang berjalan? Bagaimana serangan dapat dimuat untuk menghentikan eksploitasi lebih lanjut? Apakah tim perlu mengirimkan komunikasi internal atau eksternal, seperti pengungkapan yang bertanggung jawab? Pertimbangkan waktu deteksi dan respons. Anda mungkin berkewajiban secara hukum untuk melaporkan beberapa jenis pelanggaran kepada otoritas peraturan dalam periode waktu tertentu, yang sering kali berjam-jam atau berhari-hari.
Jika Anda memutuskan untuk mematikan sistem, langkah berikutnya mengarah ke proses pemulihan bencana (DR) beban kerja.
Jika Anda tidak mematikan sistem, tentukan cara memulihkan insiden tanpa memengaruhi fungsionalitas sistem.
Pulihkan dari insiden
Perlakukan insiden keamanan seperti bencana. Jika remediasi memerlukan pemulihan lengkap, gunakan mekanisme DR yang tepat dari perspektif keamanan. Proses pemulihan harus mencegah kemungkinan pengulangan. Jika tidak, pemulihan dari cadangan yang rusak akan memperkenalkan kembali masalah tersebut. Menyebarkan ulang sistem dengan kerentanan yang sama menyebabkan insiden yang sama. Memvalidasi langkah dan proses failover dan failback.
Jika sistem tetap berfungsi, nilai efek pada bagian sistem yang sedang berjalan. Terus pantau sistem untuk memastikan bahwa target keandalan dan performa lainnya terpenuhi atau dibaca dengan menerapkan proses degradasi yang tepat. Jangan membahayakan privasi karena mitigasi.
Diagnosis adalah proses interaktif sampai vektor, dan potensi perbaikan dan fallback, diidentifikasi. Setelah diagnosis, tim bekerja pada remediasi, yang mengidentifikasi dan menerapkan perbaikan yang diperlukan dalam periode yang dapat diterima.
Metrik pemulihan mengukur berapa lama waktu yang diperlukan untuk memperbaiki masalah. Jika terjadi pematian, mungkin ada urgensi mengenai waktu remediasi. Untuk menstabilkan sistem, perlu waktu untuk menerapkan perbaikan, patch, dan pengujian, dan menyebarkan pembaruan. Tentukan strategi penahanan untuk mencegah kerusakan lebih lanjut dan penyebaran insiden. Kembangkan prosedur pemberantasan untuk sepenuhnya menghapus ancaman dari lingkungan.
Tradeoff: Ada tradeoff antara target keandalan dan waktu remediasi. Selama insiden, kemungkinan Anda tidak memenuhi persyaratan nonfungsi atau fungsional lainnya. Misalnya, Anda mungkin perlu menonaktifkan bagian sistem saat menyelidiki insiden, atau Anda bahkan mungkin perlu membuat seluruh sistem offline sampai Anda menentukan cakupan insiden. Pembuat keputusan bisnis perlu secara eksplisit memutuskan apa target yang dapat diterima selama insiden tersebut. Tentukan dengan jelas orang yang bertanggung jawab atas keputusan tersebut.
Belajar dari insiden
Insiden mengungkap celah atau titik rentan dalam desain atau implementasi. Ini adalah peluang peningkatan yang didorong oleh pelajaran dalam aspek desain teknis, otomatisasi, proses pengembangan produk yang mencakup pengujian, dan efektivitas proses respons insiden. Pertahankan catatan insiden terperinci, termasuk tindakan yang diambil, garis waktu, dan temuan.
Kami sangat menyarankan Anda melakukan tinjauan pasca-insiden terstruktur, seperti analisis akar penyebab dan retrospektif. Lacak dan prioritaskan hasil tinjauan tersebut, dan pertimbangkan untuk menggunakan apa yang Anda pelajari dalam desain beban kerja di masa mendatang.
Rencana perbaikan harus mencakup pembaruan pada latihan dan pengujian keamanan, seperti latihan kelangsungan bisnis dan pemulihan bencana (BCDR). Gunakan kompromi keamanan sebagai skenario untuk melakukan latihan BCDR. Latihan dapat memvalidasi cara kerja proses yang didokumenkan. Seharusnya tidak ada beberapa playbook respons insiden. Gunakan satu sumber yang dapat Anda sesuaikan berdasarkan ukuran insiden dan seberapa luas atau lokal efeknya. Latihan didasarkan pada situasi hipotetis. Lakukan latihan di lingkungan berisiko rendah, dan sertakan fase pembelajaran dalam latihan.
Lakukan tinjauan pasca-insiden, atau postmortem, untuk mengidentifikasi kelemahan dalam proses respons dan area untuk perbaikan. Berdasarkan pelajaran yang Anda pelajari dari insiden tersebut, perbarui rencana respons insiden (IRP) dan kontrol keamanan.
Kirim komunikasi yang diperlukan
Terapkan rencana komunikasi untuk memberi tahu pengguna tentang gangguan dan untuk memberi tahu pemangku kepentingan internal tentang remediasi dan peningkatan. Orang lain di organisasi Anda perlu diberi tahu tentang perubahan apa pun pada garis besar keamanan beban kerja untuk mencegah insiden di masa mendatang.
Buat laporan insiden untuk penggunaan internal dan, jika perlu, untuk kepatuhan terhadap peraturan atau tujuan hukum. Selain itu, adopsi laporan format standar (templat dokumen dengan bagian yang ditentukan) yang digunakan tim SOC untuk semua insiden. Pastikan bahwa setiap insiden memiliki laporan yang terkait dengannya sebelum Anda menutup penyelidikan.
Fasilitasi Azure
Microsoft Sentinel adalah solusi SIEM dan SOAR. Ini adalah solusi tunggal untuk deteksi peringatan, visibilitas ancaman, berburu proaktif, dan respons ancaman. Untuk informasi selengkapnya, lihat Apa itu Microsoft Azure Sentinel?
Pastikan bahwa portal pendaftaran Azure menyertakan informasi kontak administrator sehingga operasi keamanan dapat diberi tahu langsung melalui proses internal. Untuk informasi selengkapnya, lihat Memperbarui pengaturan pemberitahuan.
Untuk mempelajari selengkapnya tentang membuat titik kontak yang ditunjuk yang menerima pemberitahuan insiden Azure dari Microsoft Defender untuk Cloud, lihat Mengonfigurasi pemberitahuan email untuk pemberitahuan keamanan.
Perataan organisasi
Cloud Adoption Framework untuk Azure menyediakan panduan tentang perencanaan respons insiden dan operasi keamanan. Untuk informasi selengkapnya, lihat Operasi keamanan.
Tautan terkait
- Secara otomatis membuat insiden dari pemberitahuan keamanan Microsoft
- Melakukan perburuan ancaman end-to-end dengan menggunakan fitur perburuan
- Konfigurasikan pemberitahuan email untuk pemberitahuan keamanan
- Gambaran umum respons insiden
- Kesiapan insiden Microsoft Azure
- Menavigasi dan menyelidiki insiden di Microsoft Azure Sentinel
- Kontrol keamanan: Respons insiden
- Solusi SOAR di Microsoft Azure Sentinel
- Pelatihan: Pengantar kesiapan insiden Azure
- Memperbarui pengaturan pemberitahuan portal Azure
- Apa itu SOC?
- Apa itu Microsoft Azure Sentinel?
Daftar periksa keamanan
Lihat serangkaian rekomendasi lengkap.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk