Arsitektur referensi ini menunjukkan cara melatih model rekomendasi dengan menggunakan Azure Databricks, lalu menyebarkan model sebagai API dengan menggunakan Azure Cosmos DB, Azure Pembelajaran Mesin, dan Azure Kubernetes Service (AKS). Untuk implementasi referensi arsitektur ini, lihat Membangun API Rekomendasi Real-time di GitHub.
Sistem
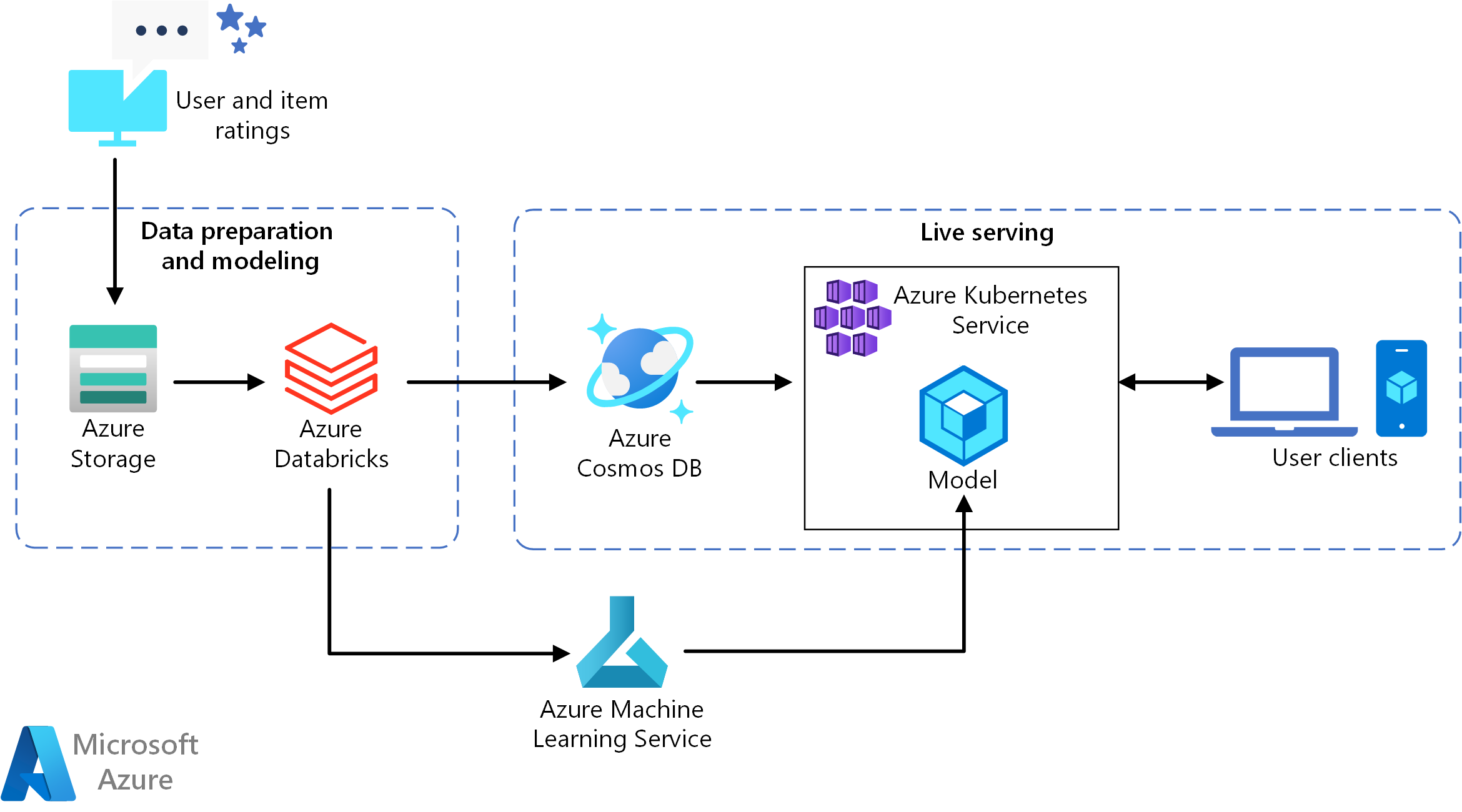
Unduh file Visio arsitektur ini.
Arsitektur referensi ini untuk melatih dan menyebarkan API layanan pemberi rekomendasi real-time yang dapat memberikan 10 rekomendasi film teratas untuk pengguna.
Aliran data
- Melacak perilaku pengguna. Misalnya, layanan back-end mungkin mencatat saat pengguna menilai film atau mengklik artikel produk atau berita.
- Memuat data ke Azure Databricks dari sumber data yang tersedia.
- Persiapkan data dan membaginya menjadi set pelatihan dan pengujian untuk melatih model. (Panduan ini menjelaskan opsi untuk memisahkan data.)
- Menyesuaikan model Penyaringan Kolaboratif Spark dengan data.
- Mengevaluasi kualitas model menggunakan metrik tingkat dan peringkat. (Panduan ini menyediakan detail tentang metrik yang dapat Anda gunakan untuk mengevaluasi pemberi rekomendasi Anda.)
- Melakukan pra-komputasi 10 rekomendasi teratas per pengguna dan menyimpan sebagai cache di Azure Cosmos DB.
- Sebarkan layanan API ke AKS menggunakan API Pembelajaran Mesin untuk membuat kontainer dan menyebarkan API.
- Ketika layanan back-end mendapatkan permintaan dari pengguna, panggil API rekomendasi yang dihosting di AKS untuk mendapatkan 10 rekomendasi teratas dan menampilkannya kepada pengguna.
Komponen
- Azure Databricks. Databricks adalah lingkungan pengembangan yang digunakan untuk menyiapkan data input dan melatih model perekomendasi di kluster Spark. Azure Databricks juga menyediakan ruang kerja interaktif untuk menjalankan dan berkolaborasi di buku catatan untuk setiap pemrosesan data atau tugas pembelajaran mesin.
- Azure Kubernetes Service (AKS). AKS digunakan untuk menyebarkan dan mengoperasionalkan API layanan model pembelajaran mesin di kluster Kubernetes. AKS meng-host model dalam kontainer, yang menyediakan skalabilitas yang memenuhi persyaratan throughput, pengelolaan identitas dan akses, dan pengelogan serta pemantauan kesehatan.
- Azure Cosmos DB. Azure Cosmos DB adalah layanan database yang didistribusikan secara global yang digunakan untuk menyimpan 10 film teratas yang direkomendasikan untuk setiap pengguna. Azure Cosmos DB sangat cocok untuk skenario ini, karena menyediakan latensi rendah (10 md pada persentil ke-99) untuk membaca item rekomendasi teratas untuk pengguna tertentu.
- Pembelajaran Mesin. Layanan ini digunakan untuk melacak dan mengelola model pembelajaran mesin, lalu mengemas dan menyebarkan model ini ke lingkungan AKS yang dapat diskalakan.
- Microsoft Recommenders. Repositori sumber terbuka ini berisi kode utilitas dan sampel untuk membantu pengguna memulai membangun, mengevaluasi, dan mengoperasionalkan sistem perekomendasi.
Detail skenario
Arsitektur ini dapat digeneralisasi untuk sebagian besar skenario mesin rekomendasi, termasuk rekomendasi untuk produk, film, dan berita.
Kemungkinan kasus penggunaan
Skenario: Organisasi media ingin memberikan rekomendasi film atau video kepada penggunanya. Dengan memberikan rekomendasi yang dipersonalisasi, organisasi memenuhi beberapa tujuan bisnis, termasuk peningkatan tarif klik-tayangan, peningkatan keterlibatan di situs webnya, dan kepuasan pengguna yang lebih tinggi.
Solusi ini dioptimalkan untuk industri ritel dan untuk industri media dan hiburan.
Pertimbangan
Pertimbangan ini mengimplementasikan pilar Azure Well-Architected Framework, yang merupakan serangkaian tenet panduan yang dapat digunakan untuk meningkatkan kualitas beban kerja. Untuk informasi selengkapnya, lihat Microsoft Azure Well-Architected Framework.
Penilaian batch model Spark di Azure Databricks menjelaskan arsitektur referensi yang menggunakan Spark dan Azure Databricks untuk menjalankan proses penilaian batch terjadwal. Kami merekomendasikan pendekatan ini untuk menghasilkan rekomendasi baru.
Efisiensi kinerja
Efisiensi performa adalah kemampuan beban kerja Anda untuk diskalakan agar memenuhi permintaan yang diberikan oleh pengguna dengan cara yang efisien. Untuk informasi selengkapnya, lihat Gambaran umum pilar efisiensi performa.
Performa adalah pertimbangan utama untuk rekomendasi real-time, karena rekomendasi biasanya berada di jalur kritis permintaan pengguna di situs web Anda.
Kombinasi AKS dan Azure Cosmos DB memungkinkan arsitektur ini memberikan titik awal yang baik untuk memberikan rekomendasi untuk beban kerja berukuran sedang dengan overhead minimal. Dalam pengujian beban dengan 200 pengguna bersamaan, arsitektur ini memberikan rekomendasi pada latensi rata-rata sekitar 60 md dan berperforma pada throughput 180 permintaan per detik. Pengujian beban dijalankan terhadap konfigurasi penyebaran default (kluster AKS 3x D3 v2 dengan 12 vCPU, memori 42 GB, dan 11.000 Unit Permintaan (RUs) per detik yang diprovisikan untuk Azure Cosmos DB).
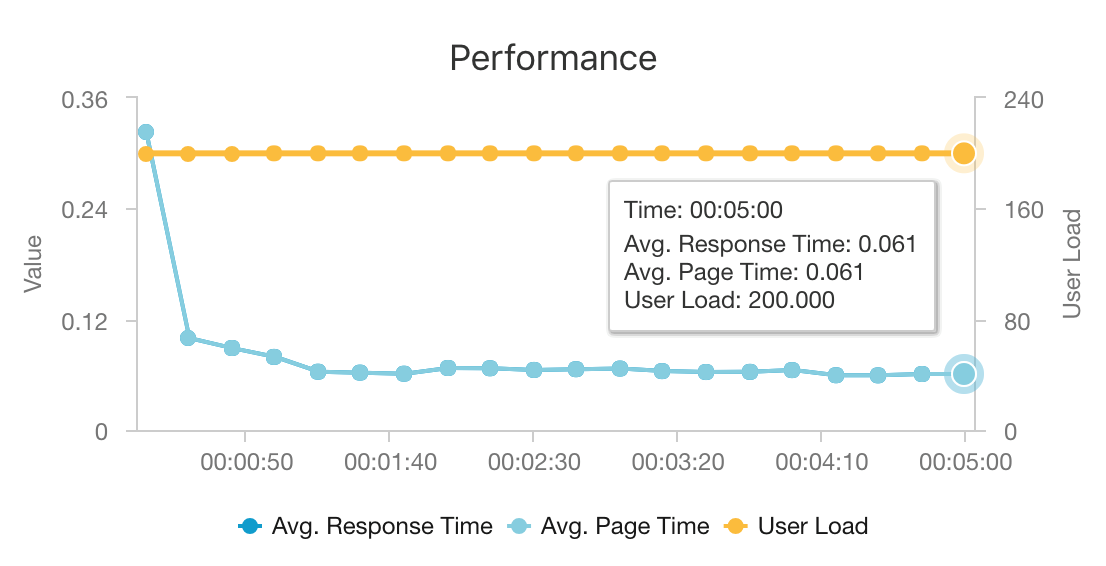
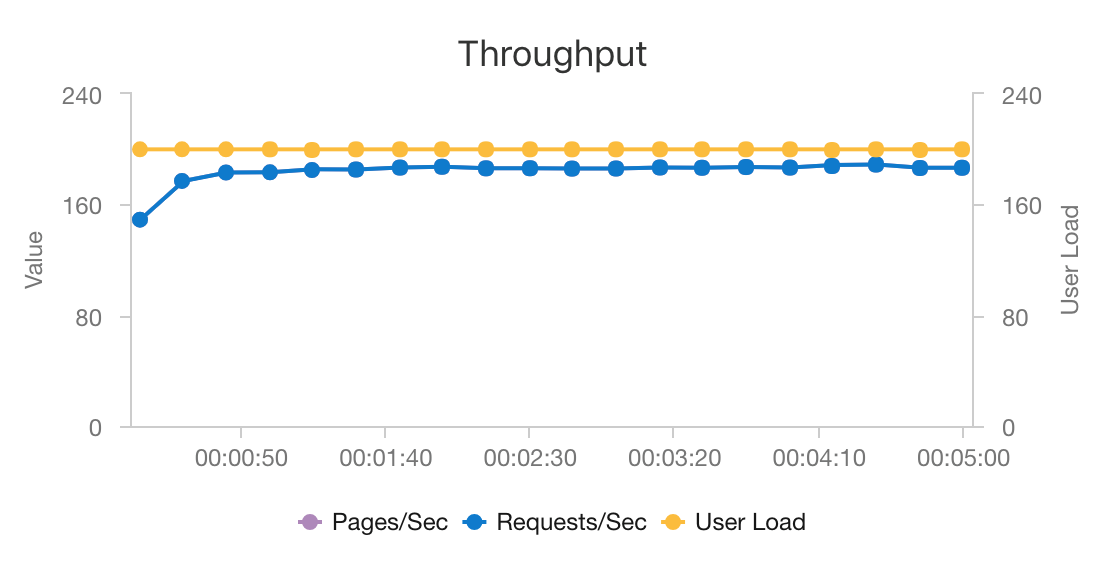
Azure Cosmos DB direkomendasikan untuk distribusi dan kegunaan global yang siap pakai dalam memenuhi persyaratan database apa pun yang dimiliki aplikasi Anda. Untuk mengurangi latensi sedikit, pertimbangkan untuk menggunakan Azure Cache for Redis alih-alih Azure Cosmos DB untuk melayani pencarian. Azure Cache for Redis dapat meningkatkan performa sistem yang sangat bergantung pada data di penyimpanan back-end.
Skalabilitas
Jika Anda tidak berencana menggunakan Spark, atau Anda memiliki beban kerja yang lebih kecil yang tidak memerlukan distribusi, pertimbangkan untuk menggunakan Ilmu Data Virtual Machine (DSVM) alih-alih Azure Databricks. DSVM adalah komputer virtual Azure dengan kerangka kerja dan alat pembelajaran mendalam untuk pembelajaran mesin dan ilmu data. Seperti halnya Azure Databricks, model apa pun yang Anda buat di DSVM dapat dioprasikan sebagai layanan di AKS melalui Pembelajaran Mesin.
Selama pelatihan, provisikan kluster Spark berukuran tetap yang lebih besar di Azure Databricks, atau konfigurasikan autoscaling. Saat autoscaling diaktifkan, Databricks memantau beban pada kluster Anda dan meningkatkan dan menurunkan skala sesuai kebutuhan. Provisikan atau perluas skala kluster yang lebih besar jika Anda memiliki ukuran data yang besar dan Anda ingin mengurangi jumlah waktu yang dibutuhkan untuk persiapan data atau tugas pemodelan.
Skalakan kluster AKS untuk memenuhi persyaratan performa dan throughput Anda. Hati-hati dalam meningkatkan skala jumlah pod untuk sepenuhnya memanfaatkan kluster, dan untuk menskalakan simpul kluster untuk memenuhi permintaan layanan Anda. Anda juga dapat mengatur autoscaling pada kluster AKS. Untuk informasi selengkapnya, lihat Menyebarkan model ke kluster Azure Kubernetes Service.
Untuk mengelola performa Azure Cosmos DB, perkirakan jumlah pembacaan yang diperlukan per detik, dan provisikan jumlah RU per detik (throughput) yang diperlukan. Gunakan praktik terbaik untuk partisi dan penskalaan horizontal.
Pengoptimalan biaya
Optimalisasi biaya adalah tentang mencari cara untuk mengurangi pengeluaran yang tidak perlu dan meningkatkan efisiensi operasional. Untuk informasi selengkapnya, lihat Gambaran umum pilar pengoptimalan biaya.
Pendorong utama biaya dalam skenario ini adalah:
- Ukuran kluster Azure Databricks yang diperlukan untuk pelatihan.
- Ukuran kluster AKS yang diperlukan untuk memenuhi persyaratan performa Anda.
- RU Azure Cosmos DB yang diprovisikan untuk memenuhi persyaratan performa Anda.
Kelola biaya Azure Databricks dengan melatih ulang lebih jarang dan menonaktifkan kluster Spark saat tidak digunakan. Biaya AKS dan Azure Cosmos DB terkait dengan throughput dan performa yang diperlukan oleh situs Anda dan akan meningkatkan dan menurunkan skala tergantung pada volume lalu lintas ke situs Anda.
Menyebarkan skenario ini
Untuk menyebarkan arsitektur ini, ikuti petunjuk Azure Databricks di dokumen penyiapan. Secara singkat, instruksi mengharuskan Anda:
- Membuat ruang kerja Azure Databricks.
- Buat kluster baru dengan konfigurasi berikut di Azure Databricks:
- Mode kluster: Standar
- Versi runtime Databricks: 4.3 (termasuk Apache Spark 2.3.1, Scala 2.11)
- Versi Python: 3
- Jenis driver: Standard_DS3_v2
- Jenis pekerja: Standard_DS3_v2 (min dan maks sesuai kebutuhan)
- Penghentian otomatis: (sesuai kebutuhan)
- Konfigurasi Spark: (sesuai kebutuhan)
- Variabel lingkungan: (sesuai kebutuhan)
- Membuat token akses pribadi di dalam ruang kerja Azure Databricks. Lihat dokumentasi autentikasi Azure Databricks untuk mengetahui detailnya.
- Mengklon repositori Microsoft Recommenders ke dalam lingkungan tempat Anda dapat menjalankan skrip (misalnya, komputer lokal Anda).
- Mengikuti petunjuk penyiapan Penginstalan cepat untuk menginstal pustaka yang relevan di Azure Databricks.
- Mengikuti petunjuk penyiapan Penginstalan cepat untuk menyiapkan Azure Databricks untuk operasionalisasi.
- Mengimpor buku catatan Operasionalisasi Film ALS ke ruang kerja Anda. Setelah masuk ke ruang kerja Azure Databricks Anda, lakukan hal berikut:
- Klik Beranda di sebelah kiri ruang kerja.
- Klik kanan ruang putih di direktori beranda Anda. Pilih impor.
- Pilih URL, dan tempelkan yang berikut ini ke bidang teks:
https://github.com/Microsoft/Recommenders/blob/main/examples/05_operationalize/als_movie_o16n.ipynb - Klik Impor.
- Membuka buku catatan di dalam Azure Databricks dan lampirkan kluster yang dikonfigurasi.
- Menjalankan buku catatan untuk membuat sumber daya Azure yang diperlukan untuk membuat API rekomendasi yang menyediakan 10 rekomendasi film teratas untuk pengguna tertentu.
Kontributor
Artikel ini dikelola oleh Microsoft. Ini awalnya ditulis oleh kontributor berikut.
Penulis utama:
- Miguel Fierro | Manajer Ilmuwan Data Utama
- Nikhil Joglekar | Manajer Produk, algoritma Azure, dan ilmu data
Untuk melihat profil LinkedIn non-publik, masuk ke LinkedIn.
Langkah berikutnya
- Membangun API Rekomendasi Real-time
- Apa itu Azure Databricks?
- Azure Kubernetes Service
- Selamat datang di Microsoft Azure Cosmos DB
- Apa itu Azure Pembelajaran Mesin?