Grup ketersediaan Selalu Aktif di SQL Server di Azure VMs
Berlaku untuk:![]() SQL Server di Azure VM
SQL Server di Azure VM
Artikel ini memperkenalkan Grup Ketersediaan AlwaysOn untuk SQL Server di Microsoft Azure Virtual Machines (VM).
Untuk memulai, lihat tutorial grup ketersediaan.
Gambaran Umum
Grup Ketersediaan AlwaysOn di Microsoft Azure Virtual Machines mirip dengan Grup Ketersediaan AlwaysOn lokal, mengandalkan Kluster Failover Windows Server yang mendasarinya. Namun, karena komputer virtual dihosting di Azure, ada beberapa pertimbangan tambahan juga, seperti redundansi VM, dan lalu lintas perutean di jaringan Azure.
Diagram berikut ini mengilustrasikan grup ketersediaan untuk SQL Server di Azure VMs:
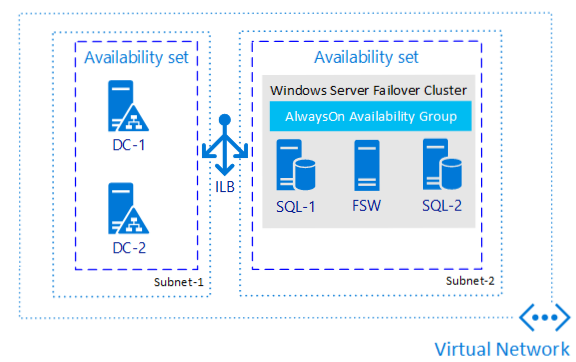
Catatan
Sekarang dimungkinkan untuk mengangkat dan mengalihkan solusi grup ketersediaan Anda ke SQL Server di Azure VM menggunakan Azure Migrate. Lihat Memigrasikan grup ketersediaan untuk mempelajari selengkapnya.
Redundansi komputer virtual
Untuk meningkatkan redundansi dan ketersediaan tinggi, VM SQL Server harus berada dalam set ketersediaan yang sama atau zona ketersediaan yang berbeda.
Menempatkan sekumpulan VM dalam set ketersediaan yang sama melindungi dari pemadaman dalam pusat data yang disebabkan oleh kegagalan peralatan (VM dalam Set Ketersediaan tidak berbagi sumber daya) atau dari pembaruan (VM dalam set ketersediaan tidak diperbarui pada saat yang sama).
Zona Ketersediaan melindungi dari kegagalan seluruh pusat data, dengan setiap Zona mewakili set pusat data dalam suatu wilayah. Dengan memastikan sumber daya ditempatkan di Zona Ketersediaan yang berbeda, tidak ada pemadaman tingkat pusat data yang dapat membuat semua komputer virtual Anda offline.
Saat membuat Azure VM, Anda harus memilih antara mengonfigurasi Set Ketersediaan vs Zona Ketersediaan. Azure VM tidak dapat berpartisipasi dalam keduanya.
Meskipun Zona Ketersediaan dapat memberikan ketersediaan yang lebih baik daripada Set Ketersediaan (99,99% vs 99,95%), kinerja juga harus menjadi pertimbangan. VM dalam Set Ketersediaan dapat ditempatkan dalam grup penempatan kedekatan yang menjamin mereka dekat satu sama lain, meminimalkan latensi jaringan di antara mereka. VM yang terletak di Zona Ketersediaan yang berbeda memiliki latensi jaringan yang lebih besar di antara mereka, yang dapat meningkatkan waktu yang diperlukan untuk menyinkronkan data antara replika primer dan sekunder. Hal ini dapat menyebabkan keterlambatan pada replika utama serta meningkatkan kemungkinan kehilangan data jika terjadi failover yang tidak direncanakan. Penting untuk menguji solusi yang diusulkan di bawah beban dan memastikan bahwa solusi tersebut memenuhi SLA untuk performa dan ketersediaan.
Konektivitas
Agar sesuai dengan pengalaman lokal untuk terhubung ke pendengar grup ketersediaan Anda, sebarkan mesin virtual SQL Server Anda ke beberapa subnet dalam jaringan virtual yang sama. Memiliki beberapa subnet meniadakan kebutuhan akan ketergantungan ekstra pada Azure Load Balancer, atau nama jaringan terdistribusi (DNN) untuk mengarahkan lalu lintas Anda ke pendengar Anda.
Jika Anda menyebarkan mesin virtual SQL Server ke satu subnet, Anda dapat mengonfigurasi nama jaringan virtual (VNN) dan Azure Load Balancer, atau nama jaringan terdistribusi (DNN) untuk mengarahkan lalu lintas ke pendengar grup ketersediaan Anda. Tinjau perbedaan antara keduanya, lalu sebarkan nama jaringan terdistribusi (DNN) atau nama jaringan virtual (VNN) untuk grup ketersediaan Anda.
Sebagian besar fitur SQL Server bekerja secara transparan dengan grup ketersediaan saat menggunakan DNN, tetapi ada fitur tertentu yang mungkin memerlukan pertimbangan khusus. Lihat Interoperabilitas FCI dan DNN untuk mempelajari selengkapnya.
Selain itu, ada beberapa perbedaan perilaku antara fungsionalitas pendengar VNN dan pendengar DNN yang penting untuk dicatat:
- Waktu failover: Waktu failover lebih cepat saat menggunakan pendengar DNN karena tidak perlu menunggu penyeimbang beban jaringan mendeteksi peristiwa kegagalan dan mengubah peruteannya.
- Koneksi yang ada: Koneksi yang dibuat ke database tertentu dalam grup ketersediaan yang gagal akan ditutup, tetapi koneksi lain ke replika utama akan tetap terbuka karena DNN tetap online selama proses failover. Ini berbeda dari lingkungan VNN tradisional tempat semua koneksi ke replika utama biasanya ditutup ketika grup ketersediaan gagal, pendengar menjadi offline, dan replika utama bertransisi ke peran sekunder. Saat menggunakan pendengar DNN, Anda mungkin perlu menyesuaikan string koneksi aplikasi untuk memastikan bahwa koneksi dialihkan ke replika utama baru setelah kegagalan.
- Transaksi terbuka: Transaksi terbuka terhadap database dalam grup ketersediaan yang gagal akan ditutup dan gulung balik, dan Anda perlu menyambungkan kembali secara manual. Misalnya, di SQL Server Management Studio, tutup jendela kueri dan buka yang baru.
Menyiapkan pendengar VNN di Azure memerlukan penyeimbang muatan. Ada dua opsi utama untuk penyeimbang muatan di Azure: eksternal (publik) atau internal. Penyeimbang beban eksternal (publik) merupakan internet-facing dan dikaitkan dengan IP virtual publik yang dapat diakses melalui internet. Penyeimbang beban internal hanya mendukung klien dalam jaringan virtual yang sama. Untuk jenis penyeimbang beban mana pun, Anda harus mengaktifkan Pengembalian Server Langsung.
Anda masih dapat terhubung ke setiap replika ketersediaan secara terpisah dengan terhubung langsung ke instans layanan. Juga, karena grup ketersediaan kompatibel mundur dengan klien pencerminan database, Anda dapat tersambung ke replika ketersediaan seperti mitra pencerminan database selama replika dikonfigurasi mirip dengan pencerminan database:
- Ada satu replika utama dan satu replika sekunder.
- Replika sekunder dikonfigurasi sebagai tidak dapat dibaca (opsi Sekunder yang Dapat Dibaca diatur ke Tidak).
Berikut ini adalah contoh string koneksi klien yang sesuai dengan konfigurasi seperti pencerminan database ini menggunakan ADO.NET atau SQL Server Native Client:
Data Source=ReplicaServer1;Failover Partner=ReplicaServer2;Initial Catalog=AvailabilityDatabase;
Untuk informasi selengkapnya tentang konektivitas klien, lihat:
- Menggunakan Kata Kunci String Koneksi dengan SQL Server Native Client
- Menyambungkan Klien ke Sesi Pencerminan Database (SQL Server)
- Menyambungkan ke listener grup ketersediaan di IT Hybrid
- Listener Grup Ketersediaan, Konektivitas Klien, dan Kegagalan Aplikasi (SQL Server)
- Menggunakan String Koneksi Pencerminan Database dengan Grup Ketersediaan
Subnet tunggal memerlukan load balancer
Saat Anda membuat pendengar grup ketersediaan pada Windows Server Failover Cluster (WSFC) lokal tradisional, rekaman DNS dibuat untuk pendengar dengan alamat IP yang Anda berikan, dan alamat IP ini memetakan ke alamat MAC replika Utama saat ini dalam tabel ARP sakelar dan router di jaringan lokal. Kluster melakukan ini dengan menggunakan ARP Gratuitous (GARP), di mana ia menyiarkan pemetaan alamat IP-ke-MAC terbaru ke jaringan setiap kali Primer baru dipilih setelah failover. Dalam hal ini, alamat IP adalah untuk pendengar, dan MAC adalah replika Utama saat ini. GARP memaksa pembaruan ke entri tabel ARP untuk sakelar dan router, dan ke setiap pengguna yang terhubung ke alamat IP pendengar dirutekan dengan mulus ke replika Utama saat ini.
Untuk alasan keamanan, penyiaran di cloud publik apa pun (Azure, Google, AWS) tidak diizinkan, sehingga penggunaan ARP dan GARP di Azure tidak didukung. Untuk mengatasi perbedaan ini dalam lingkungan jaringan, komputer virtual SQL Server dalam satu grup ketersediaan subnet mengandalkan load balancer untuk merutekan lalu lintas ke alamat IP yang sesuai. Load balancer dikonfigurasi dengan alamat IP frontend yang sesuai dengan pendengar dan port pemeriksaan ditetapkan sehingga Azure Load Balancer secara berkala melakukan polling untuk status replika dalam grup ketersediaan. Karena hanya replika utama komputer virtual SQL Server yang merespons pemeriksaan TCP, lalu lintas masuk kemudian dirutekan ke VM yang berhasil merespons pemeriksaan. Selain itu, port pemeriksaan yang sesuai dikonfigurasi sebagai IP kluster WSFC, memastikan replika Utama merespons pemeriksaan TCP.
Grup ketersediaan yang dikonfigurasi dalam satu subnet harus menggunakan load balancer atau nama jaringan terdistribusi (DNN) untuk merutekan lalu lintas ke replika yang sesuai. Untuk menghindari dependensi ini, konfigurasikan grup ketersediaan Anda di beberapa subnet sehingga pendengar grup ketersediaan dikonfigurasi dengan alamat IP untuk replika di setiap subnet, dan dapat merutekan lalu lintas dengan tepat.
Jika Anda telah membuat grup ketersediaan dalam satu subnet, Anda dapat memigrasikannya ke lingkungan multi-subnet.
Mekanisme sewa
Untuk SQL Server, DLL sumber daya AG menentukan kesehatan AG berdasarkan mekanisme sewa AG dan deteksi kesehatan Grup Ketersediaan AlwaysOn. DLL sumber daya AG memaparkan kesehatan sumber daya melalui operasi IsAlive. Pemantau sumber daya mengangket IsAlive pada interval heartbeat kluster, yang ditetapkan oleh nilai cluster-wide CrossSubnetDelay dan SameSubnetDelay. Pada node utama, layanan kluster memulai failover setiap kali panggilan IsAlive ke DLL sumber daya mengembalikan bahwa AG tidak sehat.
DLL sumber daya AG memantau status komponen SQL Server internal. Sp_server_diagnostics melaporkan kesehatan komponen-komponen ini ke SQL Server pada interval yang dikendalikan oleh HealthCheckTimeout.
Tidak seperti mekanisme failover lainnya, instans SQL Server memainkan peran aktif dalam mekanisme sewa. Mekanisme sewa digunakan sebagai validasi LooksAlive antara host sumber daya Kluster dan proses SQL Server. Mekanisme ini digunakan untuk memastikan bahwa kedua belah pihak (Layanan Kluster dan layanan SQL Server) sering berinteraksi, memeriksa keadaan satu sama lain dan akhirnya mencegah skenario split-brain.
Saat mengonfigurasi AG di Azure VM, sering kali ada kebutuhan untuk mengonfigurasi ambang batas ini secara berbeda dari yang akan dikonfigurasi di lingkungan lokal. Untuk mengonfigurasi pengaturan ambang batas sesuai dengan praktik terbaik untuk Azure VMs, lihat praktik terbaik kluster.
Konfigurasi jaringan
Sebarkan mesin virtual SQL Server Anda ke beberapa subnet bila memungkinkan untuk menghindari ketergantungan pada Azure Load Balancer atau nama jaringan terdistribusi (DNN) untuk mengarahkan lalu lintas ke pendengar grup ketersediaan Anda.
Pada kluster failover mesin virtual Azure, kami merekomendasikan satu NIC per server (node kluster). Jaringan Azure memiliki redundansi fisik, yang membuat NIC tambahan tidak diperlukan pada kluster failover mesin virtual Azure. Meskipun laporan validasi kluster mengeluarkan peringatan bahwa simpul hanya dapat dijangkau pada satu jaringan, peringatan ini dapat diabaikan dengan aman pada kluster failover Azure VM.
Grup ketersediaan dasar
Karena grup ketersediaan dasar tidak mengizinkan lebih dari satu replika sekunder dan tidak ada akses baca ke replika sekunder, Anda dapat menggunakan string koneksi pencerminan database untuk grup ketersediaan dasar. Penggunaan string koneksi menghilangkan kebutuhan untuk memiliki pendengar. Penghapusan dependensi pendengar sangat membantu untuk grup ketersediaan di Azure VM karena menghilangkan kebutuhan akan penyeimbang muatan atau keharusan menambahkan IP tambahan ke penyeimbang muatan saat Anda memiliki beberapa pendengar untuk database tambahan.
Misalnya, untuk secara eksplisit terhubung menggunakan TCP/IP ke database AG AdventureWorks baik pada Replica_A atau Replica_B AG Dasar (atau AG apa pun yang hanya memiliki satu replika sekunder dan akses baca tidak diizinkan di replika sekunder), aplikasi klien dapat menyediakan string koneksi pencerminan database berikut agar berhasil tersambung ke AG
Server=Replica_A; Failover_Partner=Replica_B; Database=AdventureWorks; Network=dbmssocn
Opsi penyebaran
Tip
Hilangkan kebutuhan akan Azure Load Balancer atau nama jaringan terdistribusi (DNN) untuk grup ketersediaan AlwaysOn Anda dengan membuat komputer virtual SQL Server Anda di beberapa subnet dalam jaringan virtual Azure yang sama.
Ada beberapa opsi untuk menyebarkan grup ketersediaan ke SQL Server di Azure VMs, beberapa dengan lebih banyak otomatisasi daripada yang lain.
Tabel berikut ini menyediakan perbandingan opsi yang tersedia:
| portal Microsoft Azure, | Azure CLI/PowerShell | Templat Mulai Cepat | Manual (subnet tunggal) | Manual (multi-subnet) | |
|---|---|---|---|---|---|
| Versi SQL Server | 2016 + | 2016 + | 2016 + | 2012 + | 2012 + |
| Edisi SQL Server | Enterprise | Enterprise | Enterprise | Perusahaan, Standar | Perusahaan, Standar |
| Versi Windows Server | 2016 + | 2016 + | 2016 + | Semua | Semua |
| Membuat kluster untuk Anda | Ya | Ya | Ya | Tidak | Tidak |
| Membuat grup ketersediaan dan listener untuk Anda | Ya | Tidak | Tidak | Tidak | Tidak |
| Membuat pendengar dan load balancer secara independen | T/A | Tidak | Tidak | Ya | T/A |
| Memungkinkan untuk membuat pendengar DNN menggunakan metode ini? | T/A | Tidak | Tidak | Ya | T/A |
| Konfigurasi kuorum WSFC | Bukti cloud | Bukti cloud | Bukti cloud | Semua | Semua |
| DR dengan beberapa wilayah | Tidak | Tidak | Tidak | Ya | Ya |
| Dukungan multisubnet | Ya | Tidak | Tidak | T/A | Ya |
| Dukungan untuk AD yang sudah ada | Ya | Ya | Ya | Ya | Ya |
| DR dengan multizona di wilayah yang sama | Ya | Ya | Ya | Ya | Ya |
| AG terdistribusi tanpa AD | Tidak | Tidak | Tidak | Ya | Ya |
| AG terdistribusi tanpa kluster | Tidak | Tidak | Tidak | Ya | Ya |
| Membutuhkan penyeimbang beban atau DNN | Tidak | Ya | Ya | Ya | Tidak |
Langkah berikutnya
Untuk memulai, tinjau praktik terbaik HADR, lalu sebarkan grup ketersediaan Anda secara manual dengan tutorial grup ketersediaan.
Untuk mempelajari selengkapnya, lihat:
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk