Mengelola penskalakan horizontal kluster (peluasan skala) di Azure Data Explorer untuk mengakomodasi perubahan permintaan
Mengukur kluster dengan tepat sangat penting untuk performa Azure Data Explorer. Ukuran kluster statis dapat menyebabkan kurangnya penggunaan atau penggunaan berlebih, yang tidak ideal. Karena permintaan pada kluster tidak dapat diprediksi dengan akurasi absolut, lebih baik untuk menskalakan kluster, menambahkan dan menghapus kapasitas dan sumber daya CPU dengan permintaan yang berubah.
Ada dua alur kerja untuk menskalakan kluster Azure Data Explorer:
- Penskalan horizontal, juga disebut penskalakan masuk dan keluar.
- Penskalan vertikal, juga disebut penskalakan ke atas dan ke bawah. Artikel ini menjelaskan alur kerja penskalakan horizontal.
Mengonfigurasi penskalakan horizontal
Dengan menggunakan penskalakan horizontal, Anda dapat menskalakan jumlah instans secara otomatis, berdasarkan aturan dan jadwal yang telah ditentukan sebelumnya. Untuk menentukan pengaturan skala otomatis untuk kluster Anda:
Di portal Azure, buka sumber daya kluster Azure Data Explorer Anda. Di bawah Pengaturan, pilih Peluasan skala.
Di jendela Peluasan skala , pilih metode skala otomatis yang Anda inginkan: Skala manual, Skala otomatis yang dioptimalkan, atau Skala otomatis kustom.
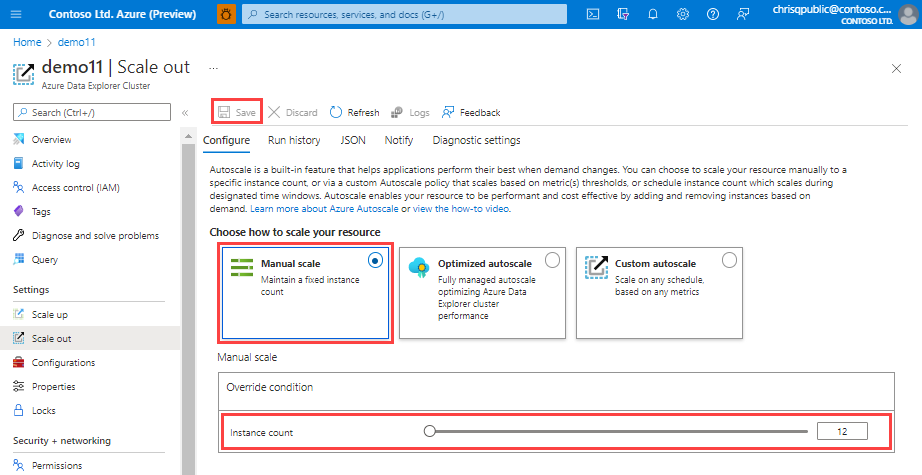
Skala manual
Dalam opsi skala manual, kluster memiliki kapasitas statis yang tidak berubah secara otomatis. Pilih kapasitas statis dengan menggunakan bilah Jumlah instans . Penskalan kluster tetap pada pengaturan yang dipilih hingga berubah.
Skala otomatis yang dioptimalkan (opsi yang disarankan)
Skala otomatis yang dioptimalkan adalah pengaturan default selama pembuatan kluster dan metode penskalaan yang direkomendasikan. Metode ini mengoptimalkan performa dan biaya kluster, sebagai berikut:
- Jika kluster kurang digunakan, kluster diskalakan ke biaya yang lebih rendah tanpa memengaruhi performa yang diperlukan.
- Jika kluster terlalu banyak digunakan, kluster diskalakan untuk mempertahankan performa yang optimal.
Untuk mengonfigurasi skala otomatis yang dioptimalkan:
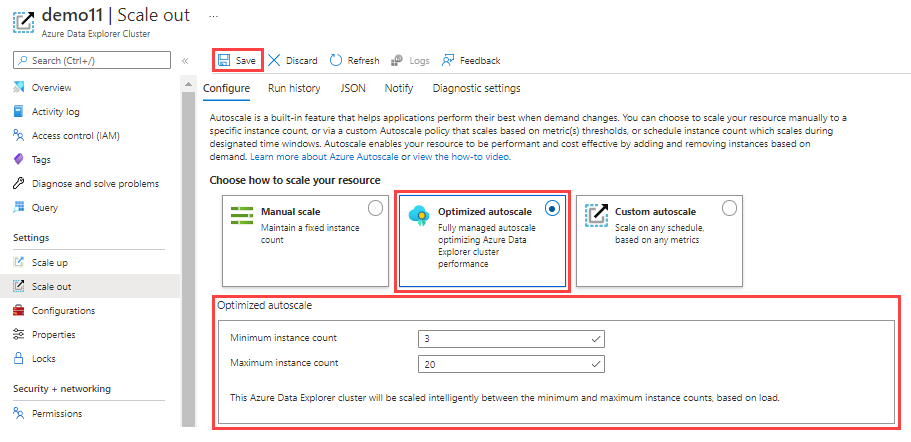
Pilih Skala otomatis yang dioptimalkan.
Tentukan jumlah instans minimum dan maksimum. Rentang autoscaling kluster antara nilai-nilai ini berdasarkan beban.
Pilih Simpan.
Skala otomatis yang dioptimalkan mulai berfungsi. Tindakannya dapat dilihat di log aktivitas kluster di Azure.
Logika skala otomatis yang dioptimalkan
Skala otomatis yang dioptimalkan dikelola oleh logika prediktif atau reaktif. Logika prediktif melacak pola penggunaan kluster dan ketika mengidentifikasi musiman dengan keyakinan tinggi, ia mengelola penskalaan kluster. Jika tidak, logika reaktif yang melacak penggunaan aktual kluster digunakan untuk membuat keputusan tentang operasi skala kluster berdasarkan tingkat penggunaan sumber daya saat ini.
Metrik utama untuk alur prediktif dan reaktif adalah:
- CPU
- Faktor pemanfaatan cache
- Pemanfaatan penyerapan
Baik logika prediktif maupun reaktif terikat pada batas ukuran kluster, jumlah instans min dan maks, seperti yang didefinisikan dalam konfigurasi skala otomatis yang dioptimalkan. Perluasan skala dan skala kluster yang sering dalam operasi tidak diinginkan karena dampak pada sumber daya kluster dan waktu yang diperlukan untuk menambahkan atau menghapus instans, serta menyeimbangkan kembali cache panas di semua simpul.
Skala otomatis prediktif
Logika prediktif memperkirakan penggunaan kluster untuk hari berikutnya berdasarkan pola penggunaannya selama beberapa minggu terakhir. Prakiraan digunakan untuk membuat jadwal operasi penskalaan masuk atau peluasan skala untuk menyesuaikan ukuran kluster sebelumnya. Ini memungkinkan penskalaan kluster dan penyeimbangan ulang data selesai tepat waktu ketika beban berubah. Logika ini sangat efektif untuk pola musiman, seperti lonjakan penggunaan harian atau mingguan.
Namun, dalam skenario di mana ada lonjakan unik penggunaan yang melebihi perkiraan, skala otomatis yang dioptimalkan akan kembali pada logika reaktif. Ketika ini terjadi, operasi penskalaan masuk atau peluasan skala dilakukan ad hoc berdasarkan tingkat penggunaan sumber daya terbaru.
Skala otomatis reaktif
Peluasan skala
Ketika kluster mendekati keadaan overutilization, operasi peluasan skala akan dilakukan untuk mempertahankan performa yang optimal. Operasi peluasan skala dilakukan ketika setidaknya salah satu kondisi berikut terjadi:
- Pemanfaatan cache tinggi selama lebih dari satu jam
- CPU tinggi selama lebih dari satu jam
- Pemanfaatan penyerapan tinggi selama lebih dari satu jam
Menskalakan masuk
Ketika kluster kurang digunakan, skala dalam operasi akan berlangsung untuk menurunkan biaya sambil mempertahankan performa optimal. Beberapa metrik digunakan untuk memverifikasi bahwa aman untuk diskalakan dalam kluster.
Untuk memastikan bahwa tidak ada kelebihan beban sumber daya, metrik berikut dievaluasi sebelum penskalaan dilakukan:
- Pemanfaatan cache tidak tinggi
- CPU berada di bawah rata-rata
- Pemanfaatan penyerapan di bawah rata-rata
- Jika penyerapan streaming digunakan, pemanfaatan penyerapan streaming tidak tinggi
- Metrik tetap hidup berada di atas minimum yang ditentukan, diproses dengan benar, dan tepat waktu yang menunjukkan bahwa kluster responsif
- Tidak ada pembatasan kueri
- Jumlah kueri yang gagal di bawah minimum yang ditentukan
Catatan
Skala dalam logika memerlukan evaluasi 1 hari sebelum implementasi skala yang dioptimalkan. Evaluasi ini berlangsung sekali setiap jam. Jika perubahan segera diperlukan, gunakan skala manual.
Skala otomatis kustom
Meskipun skala otomatis yang dioptimalkan adalah opsi penskalakan yang direkomendasikan, skala otomatis kustom Azure juga didukung. Dengan menggunakan skala otomatis kustom, Anda dapat menskalakan kluster secara dinamis berdasarkan metrik yang Anda tentukan. Gunakan langkah-langkah berikut untuk mengonfigurasi skala otomatis kustom.
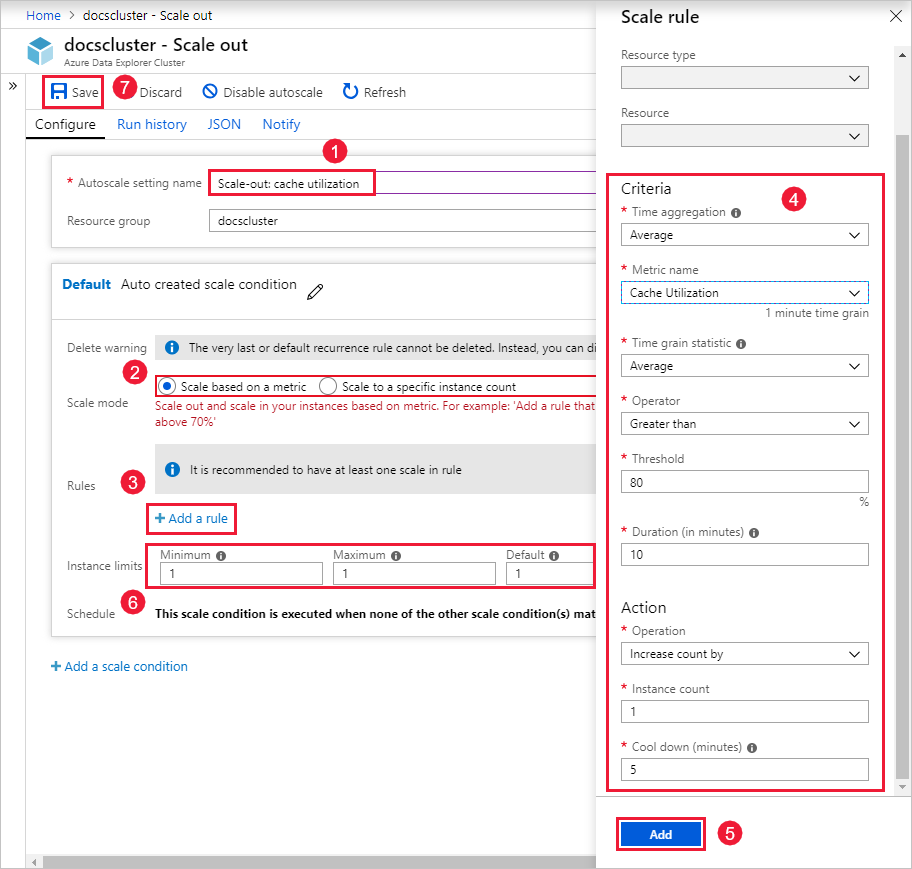
Dalam kotak Nama pengaturan skala otomatis , masukkan nama, seperti Peluasan skala: pemanfaatan cache.
Untuk Mode skala, pilih Skalakan berdasarkan metrik. Mode ini menyediakan penskalakan dinamis. Anda juga dapat memilih Skalakan ke jumlah instans tertentu.
Pilih + Tambahkan aturan.
Di bagian Aturan skala di sebelah kanan, masukkan nilai untuk setiap pengaturan.
Kriteria
Pengaturan Deskripsi dan nilai Agregasi waktu Pilih kriteria agregasi, seperti Rata-rata. Nama metrik Pilih metrik yang Anda inginkan untuk didasarkan pada operasi skala, seperti Pemanfaatan Cache. Statistik butir waktu Pilih antara Rata-Rata, Minimum, Maksimum, dan Jumlah. Operator Pilih opsi yang sesuai, seperti Lebih besar dari atau sama dengan. Ambang Pilih nilai yang sesuai. Misalnya, untuk pemanfaatan cache, 80 persen adalah titik awal yang baik. Durasi (dalam menit) Pilih jumlah waktu yang tepat bagi sistem untuk melihat kembali saat menghitung metrik. Mulailah dengan default 10 menit. Tindakan
Pengaturan Deskripsi dan nilai Operasi Pilih opsi yang sesuai untuk menskalakan masuk atau meluaskan skala. Jumlah Instans Pilih jumlah simpul atau instans yang ingin Anda tambahkan atau hapus saat kondisi metrik terpenuhi. Pendinginan (menit) Pilih interval waktu yang sesuai untuk menunggu di antara operasi skala. Mulailah dengan default lima menit. Pilih Tambahkan.
Di bagian Batas instans di sebelah kiri, masukkan nilai untuk setiap pengaturan.
Pengaturan Deskripsi dan nilai Minimum Jumlah instans yang tidak akan diskalakan kluster Anda di bawah ini, terlepas dari pemanfaatannya. Maksimum Jumlah instans yang tidak akan diskalakan kluster Anda di atas, terlepas dari pemanfaatannya. Default Jumlah default instans. Pengaturan ini digunakan jika ada masalah dengan membaca metrik sumber daya. Pilih Simpan.
Sekarang Anda telah mengonfigurasi penskalaan horizontal untuk kluster Azure Data Explorer Anda. Tambahkan aturan lain untuk penskalaan vertikal. Jika Anda memerlukan bantuan terkait masalah penskalaan kluster, buka permintaan dukungan di portal Azure.
Konten terkait
- Memantau performa, kesehatan, dan penggunaan Azure Data Explorer dengan metrik
- Mengelola penskalaan vertikal kluster untuk ukuran kluster yang sesuai.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk