Konektor Azure Data Explorer untuk Apache Spark
Apache Spark adalah mesin analitik terpadu untuk pemrosesan data skala besar. Azure Data Explorer adalah layanan analitik data yang cepat dan dikelola sepenuhnya untuk analisis real-time pada data bervolume besar.
Konektor Kusto untuk Spark adalah proyek sumber terbuka yang dapat berjalan pada kluster Spark apa pun. Ini mengimplementasikan sumber data dan sink data untuk memindahkan data di seluruh kluster Azure Data Explorer dan Spark. Dengan menggunakan Azure Data Explorer dan Apache Spark, Anda dapat membangun aplikasi yang cepat dan dapat diskalakan yang menargetkan skenario berbasis data. Misalnya, pembelajaran mesin (ML), Extract-Transform-Load (ETL), dan Log Analytics. Dengan konektor, Azure Data Explorer menjadi penyimpanan data yang valid untuk operasi sumber dan sink Spark standar, seperti menulis, membaca, dan menulisStream.
Anda dapat menulis ke Azure Data Explorer melalui penyerapan antrean atau penyerapan streaming. Membaca dari Azure Data Explorer mendukung pemangkasan kolom dan pushdown predikat, yang memfilter data di Azure Data Explorer, mengurangi volume data yang ditransfer.
Catatan
Untuk informasi tentang bekerja dengan konektor Synapse Spark untuk Azure Data Explorer, lihat Menyambungkan ke Azure Data Explorer menggunakan Apache Spark untuk Azure Synapse Analytics.
Topik ini menjelaskan cara menginstal dan mengonfigurasi konektor Azure Data Explorer Spark dan memindahkan data antara kluster Azure Data Explorer dan Apache Spark.
Catatan
Meskipun beberapa contoh di bawah ini mengacu pada kluster Azure Databricks Spark, konektor Azure Data Explorer Spark tidak mengambil dependensi langsung pada Databricks atau distribusi Spark lainnya.
Prasyarat
- Langganan Azure. Membuat akun Azure gratis.
- Kluster dan database Azure Data Explorer. Membuat kluster dan database.
- Kluster Spark
- Instal pustaka konektor:
- Pustaka bawaan untuk Spark 2.4+Scala 2.11 atau Spark 3+scala 2.12
- Repositori Maven
- Maven 3.x terinstal
Tip
Versi Spark 2.3.x juga didukung, tetapi mungkin memerlukan beberapa perubahan dalam dependensi pom.xml.
Cara membangun konektor Spark
Mulai versi 2.3.0 kami memperkenalkan Id artefak baru menggantikan spark-kusto-connector: kusto-spark_3.0_2.12 yang menargetkan Spark 3.x dan Scala 2.12.
Catatan
Versi sebelum 2.5.1 tidak berfungsi lagi untuk diserap ke tabel yang ada, harap perbarui ke versi yang lebih baru. Langkah ini bersifat opsional. Jika Anda menggunakan pustaka bawaan, misalnya, Maven, lihat Penyiapan kluster Spark.
Membangun prasyarat
Lihat sumber ini untuk membangun Konektor Spark.
Untuk aplikasi Scala/Java menggunakan definisi proyek Maven, tautkan aplikasi Anda dengan artefak terbaru. Temukan artefak terbaru di Maven Central.
For more information, see [https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12](https://mvnrepository.com/artifact/com.microsoft.azure.kusto/kusto-spark_3.0_2.12).Jika Anda tidak menggunakan pustaka bawaan, Anda perlu menginstal pustaka yang tercantum dalam dependensi termasuk pustaka SDK Java Kusto berikut. Untuk menemukan versi yang tepat untuk diinstal, lihat di pom rilis yang relevan:
Untuk membangun jar dan menjalankan semua pengujian:
mvn clean package -DskipTestsUntuk membangun jar, jalankan semua pengujian, dan instal jar ke repositori Maven lokal Anda:
mvn clean install -DskipTests
Untuk informasi selengkapnya, lihat penggunaan konektor.
Penyiapan kluster Spark
Catatan
Disarankan untuk menggunakan rilis konektor Kusto Spark terbaru saat melakukan langkah-langkah berikut.
Konfigurasikan pengaturan kluster Spark berikut, berdasarkan kluster Azure Databricks Spark 3.0.1 dan Scala 2.12:
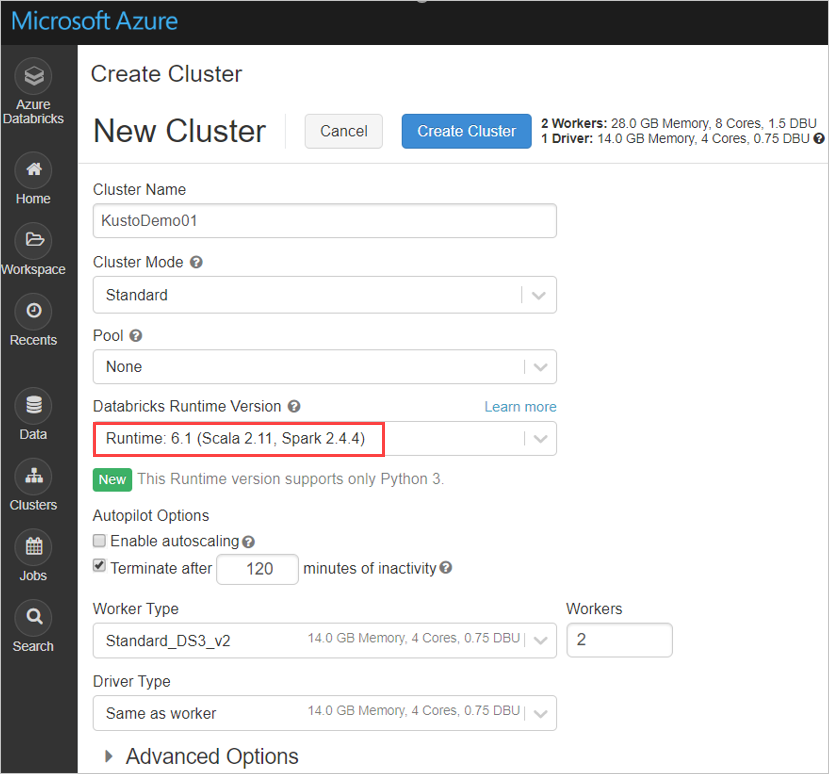
Instal pustaka spark-kusto-connector terbaru dari Maven:
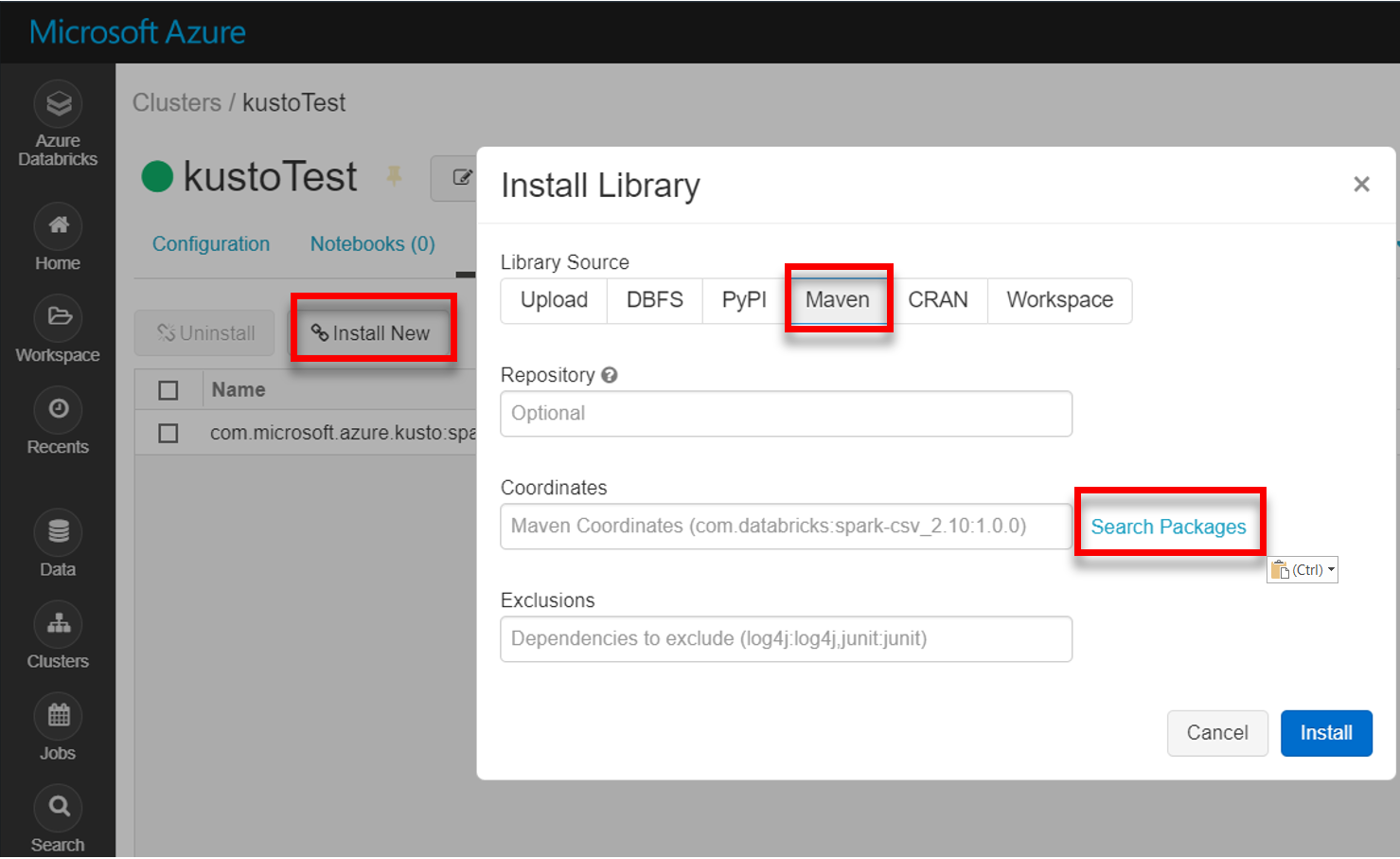
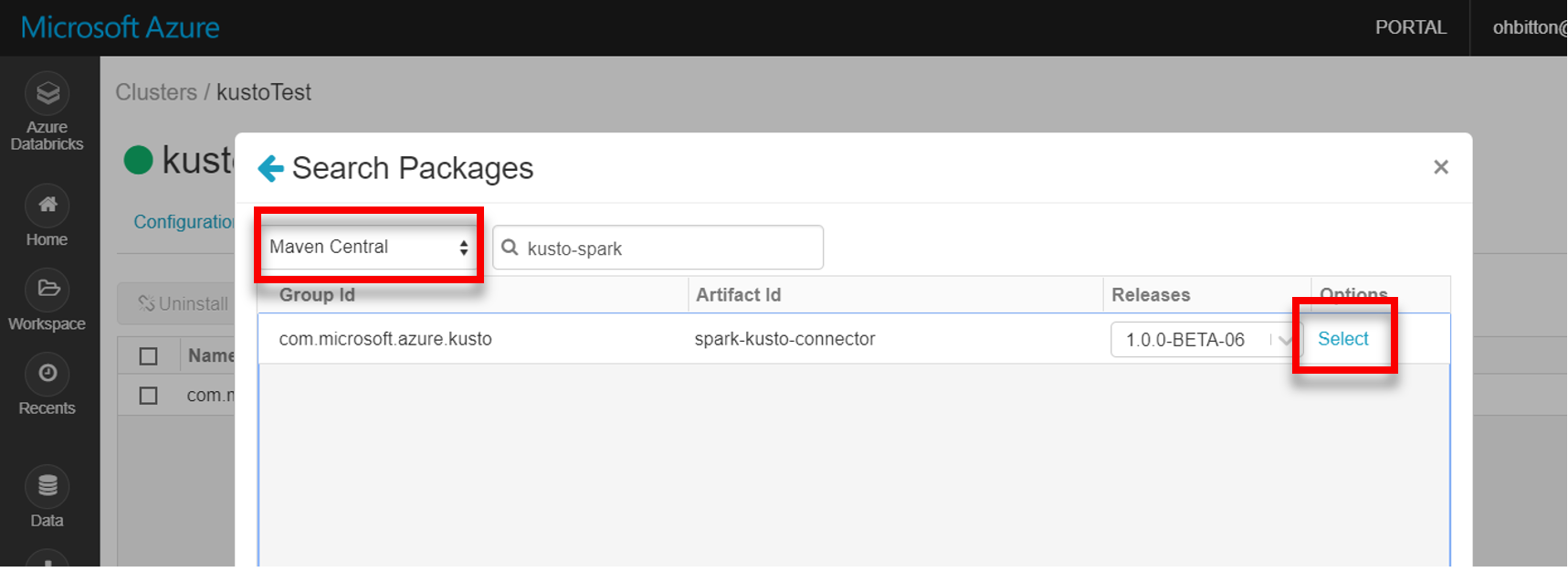
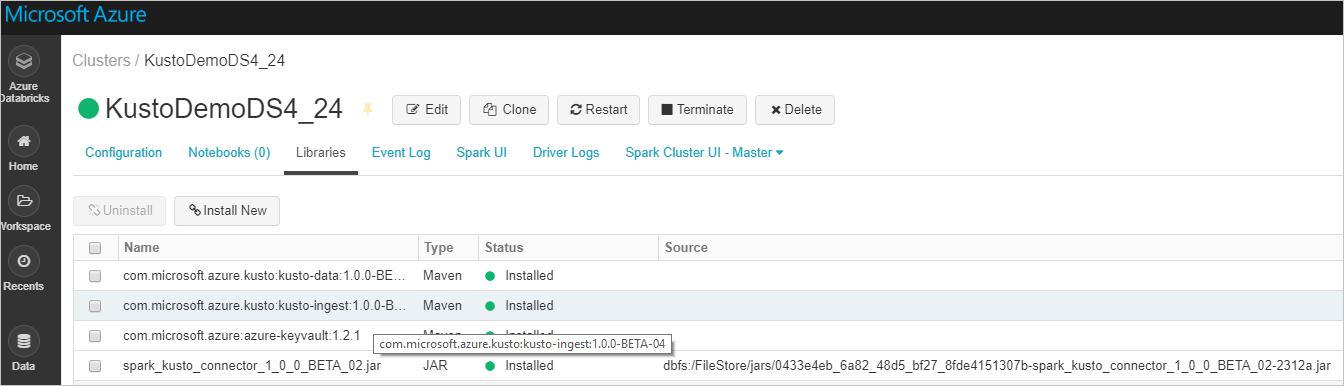
Verifikasi bahwa semua pustaka yang diperlukan diinstal:
Untuk penginstalan menggunakan file JAR, verifikasi bahwa dependensi lain telah diinstal:
Autentikasi
Konektor Kusto Spark memungkinkan Anda mengautentikasi dengan ID Microsoft Entra menggunakan salah satu metode berikut:
- Aplikasi Microsoft Entra
- Token akses Microsoft Entra
- Autentikasi perangkat (untuk skenario nonproduksi)
- Azure Key Vault Untuk mengakses sumber daya Key Vault, instal paket azure-keyvault dan berikan kredensial aplikasi.
Autentikasi aplikasi Microsoft Entra
Autentikasi aplikasi Microsoft Entra adalah metode autentikasi paling sederhana dan paling umum dan direkomendasikan untuk konektor Kusto Spark.
Masuk ke langganan Azure Anda melalui Azure CLI. Kemudian autentikasi di browser.
az loginPilih langganan untuk menghosting perwakilan. Langkah ini diperlukan saat Anda memiliki beberapa langganan.
az account set --subscription YOUR_SUBSCRIPTION_GUIDBuat perwakilan layanan. Dalam contoh ini, perwakilan layanan disebut
my-service-principal.az ad sp create-for-rbac -n "my-service-principal" --role Contributor --scopes /subscriptions/{SubID}Dari data JSON yang dikembalikan, salin
appId,password, dantenantuntuk penggunaan di masa mendatang.{ "appId": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "displayName": "my-service-principal", "name": "my-service-principal", "password": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn", "tenant": "1234abcd-e5f6-g7h8-i9j0-1234kl5678mn" }
Anda telah membuat aplikasi Microsoft Entra dan perwakilan layanan Anda.
Konektor Spark menggunakan properti aplikasi Entra berikut untuk autentikasi:
| Properti | String Opsi | Deskripsi |
|---|---|---|
| KUSTO_AAD_APP_ID | kustoAadAppId | Pengidentifikasi aplikasi Microsoft Entra (klien). |
| KUSTO_AAD_AUTHORITY_ID | kustoAadAuthorityID | Otoritas autentikasi Microsoft Entra. ID Microsoft Entra Directory (penyewa). Opsional - default ke microsoft.com. Untuk informasi selengkapnya, lihat Otoritas Microsoft Entra. |
| KUSTO_AAD_APP_SECRET | kustoAadAppSecret | Kunci aplikasi Microsoft Entra untuk klien. |
| KUSTO_ACCESS_TOKEN | kustoAccessToken | Jika Anda sudah memiliki accessToken yang dibuat dengan akses ke Kusto, yang dapat digunakan diteruskan ke konektor juga untuk autentikasi. |
Catatan
Versi API yang lebih lama (kurang dari 2.0.0) memiliki penamaan berikut: "kustoAADClientID", "kustoClientAADClientPassword", "kustoAADAuthorityID"
Hak istimewa Kusto
Berikan hak istimewa berikut di sisi kusto berdasarkan operasi Spark yang ingin Anda lakukan.
| Operasi Spark | Hak Istimewa |
|---|---|
| Baca - Mode Tunggal | Pembaca |
| Baca – Mode Terdistribusi Paksa | Pembaca |
| Opsi buat tabel Write – Queued Mode dengan CreateTableIfNotExist | Admin |
| Opsi buat tabel Write – Queued Mode dengan FailIfNotExist | Ingestor |
| Tulis – TransactionalMode | Admin |
Untuk informasi selengkapnya tentang peran utama, lihat kontrol akses berbasis peran. Untuk mengelola peran keamanan, lihat manajemen peran keamanan.
Spark sink: menulis ke Kusto
Siapkan parameter sink:
val KustoSparkTestAppId = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppId") val KustoSparkTestAppKey = dbutils.secrets.get(scope = "KustoDemos", key = "KustoSparkTestAppKey") val appId = KustoSparkTestAppId val appKey = KustoSparkTestAppKey val authorityId = "72f988bf-86f1-41af-91ab-2d7cd011db47" // Optional - defaults to microsoft.com val cluster = "Sparktest.eastus2" val database = "TestDb" val table = "StringAndIntTable"Tulis Spark DataFrame ke kluster Kusto sebagai batch:
import com.microsoft.kusto.spark.datasink.KustoSinkOptions import org.apache.spark.sql.{SaveMode, SparkSession} df.write .format("com.microsoft.kusto.spark.datasource") .option(KustoSinkOptions.KUSTO_CLUSTER, cluster) .option(KustoSinkOptions.KUSTO_DATABASE, database) .option(KustoSinkOptions.KUSTO_TABLE, "Demo3_spark") .option(KustoSinkOptions.KUSTO_AAD_APP_ID, appId) .option(KustoSinkOptions.KUSTO_AAD_APP_SECRET, appKey) .option(KustoSinkOptions.KUSTO_AAD_AUTHORITY_ID, authorityId) .option(KustoSinkOptions.KUSTO_TABLE_CREATE_OPTIONS, "CreateIfNotExist") .mode(SaveMode.Append) .save()Atau gunakan sintaks yang disederhanakan:
import com.microsoft.kusto.spark.datasink.SparkIngestionProperties import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val sparkIngestionProperties = Some(new SparkIngestionProperties()) // Optional, use None if not needed df.write.kusto(cluster, database, table, conf, sparkIngestionProperties)Menulis data streaming:
import org.apache.spark.sql.streaming.Trigger import java.util.concurrent.TimeUnit import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.Trigger // Set up a checkpoint and disable codeGen. spark.conf.set("spark.sql.streaming.checkpointLocation", "/FileStore/temp/checkpoint") // Write to a Kusto table from a streaming source val kustoQ = df .writeStream .format("com.microsoft.kusto.spark.datasink.KustoSinkProvider") .options(conf) .trigger(Trigger.ProcessingTime(TimeUnit.SECONDS.toMillis(10))) // Sync this with the ingestionBatching policy of the database .start()
Sumber Spark: membaca dari Kusto
Saat membaca sejumlah kecil data, tentukan kueri data:
import com.microsoft.kusto.spark.datasource.KustoSourceOptions import org.apache.spark.SparkConf import org.apache.spark.sql._ import com.microsoft.azure.kusto.data.ClientRequestProperties val query = s"$table | where (ColB % 1000 == 0) | distinct ColA" val conf: Map[String, String] = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey ) val df = spark.read.format("com.microsoft.kusto.spark.datasource"). options(conf). option(KustoSourceOptions.KUSTO_QUERY, query). option(KustoSourceOptions.KUSTO_DATABASE, database). option(KustoSourceOptions.KUSTO_CLUSTER, cluster). load() // Simplified syntax flavor import com.microsoft.kusto.spark.sql.extension.SparkExtension._ val cpr: Option[ClientRequestProperties] = None // Optional val df2 = spark.read.kusto(cluster, database, query, conf, cpr) display(df2)Opsional: Jika Anda menyediakan penyimpanan blob sementara (dan bukan Kusto) blob dibuat di bawah tanggung jawab pemanggil. Ini termasuk menyediakan penyimpanan, memutar kunci akses, dan menghapus artefak sementara. Modul KustoBlobStorageUtils berisi fungsi pembantu untuk menghapus blob berdasarkan koordinat akun dan kontainer dan kredensial akun, atau URL SAS lengkap dengan izin tulis, baca, dan daftar. Ketika RDD yang sesuai tidak lagi diperlukan, setiap transaksi menyimpan artefak blob sementara dalam direktori terpisah. Direktori ini ditangkap sebagai bagian dari log informasi transaksi baca yang dilaporkan pada simpul Driver Spark.
// Use either container/account-key/account name, or container SaS val container = dbutils.secrets.get(scope = "KustoDemos", key = "blobContainer") val storageAccountKey = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountKey") val storageAccountName = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageAccountName") // val storageSas = dbutils.secrets.get(scope = "KustoDemos", key = "blobStorageSasUrl")Dalam contoh di atas, Key Vault tidak diakses menggunakan antarmuka konektor; metode yang lebih sederhana untuk menggunakan rahasia Databricks digunakan.
Baca dari Kusto.
Jika Anda menyediakan penyimpanan blob sementara, baca dari Kusto sebagai berikut:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_APP_ID -> appId, KustoSourceOptions.KUSTO_AAD_APP_SECRET -> appKey KustoSourceOptions.KUSTO_BLOB_STORAGE_SAS_URL -> storageSas) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)Jika Kusto menyediakan penyimpanan blob sementara, baca dari Kusto sebagai berikut:
val conf3 = Map( KustoSourceOptions.KUSTO_AAD_CLIENT_ID -> appId, KustoSourceOptions.KUSTO_AAD_CLIENT_PASSWORD -> appKey) val df2 = spark.read.kusto(cluster, database, "ReallyBigTable", conf3) val dfFiltered = df2 .where(df2.col("ColA").startsWith("row-2")) .filter("ColB > 12") .filter("ColB <= 21") .select("ColA") display(dfFiltered)