Tutorial: Buat aplikasi Scala Maven untuk Apache Spark di HDInsight menggunakan IntelliJ
Dalam tutorial ini, Anda belajar cara membuat aplikasi Apache Spark yang ditulis dalam Scala menggunakan Apache Maven dengan IntelliJ IDEA. Artikel ini menggunakan Apache Maven sebagai sistem build. Dan dimulai dengan arketipe Maven yang ada untuk Scala yang disediakan oleh IntelliJ IDEA. Membuat aplikasi Scala di IntelliJ IDEA mencakup langkah-langkah berikut:
- Gunakan Maven sebagai sistem build.
- Perbarui file Project Object Model (POM/Model Objek Proyek) untuk menangani dependensi modul Spark.
- Tulis aplikasi Anda dalam Scala.
- Buat file jar yang dapat dikirim ke kluster Spark HDInsight.
- Jalankan aplikasi pada kluster Spark menggunakan Livy.
Dalam tutorial ini, Anda akan mempelajari cara:
- Pasang plugin Scala untuk IntelliJ IDEA
- Gunakan IntelliJ untuk mengembangkan aplikasi Scala Maven
- Buat proyek Scala mandiri
Prasyarat
Klaster Apache Spark pada HDInsight. Untuk petunjuk selengkapnya, lihat Membuat kluster Apache Spark di Microsoft Azure HDInsight.
Kit Pengembangan Oracle Java. Tutorial ini menggunakan Java versi 8.0.202.
Java IDE. Artikel ini menggunakan Komunitas IntelliJ IDEA versi 2018.3.4.
Azure Toolkit untuk IntelliJ. Lihat Menginstal Azure Toolkit untuk IntelliJ.
Pasang plugin Scala untuk IntelliJ IDEA
Lakukan langkah-langkah berikut untuk menginstal plugin Scala:
Buka IntelliJ IDEA.
Pada layar selamat datang, navigasi ke Konfigurasikan>Plugin untuk membuka jendela Plugin.
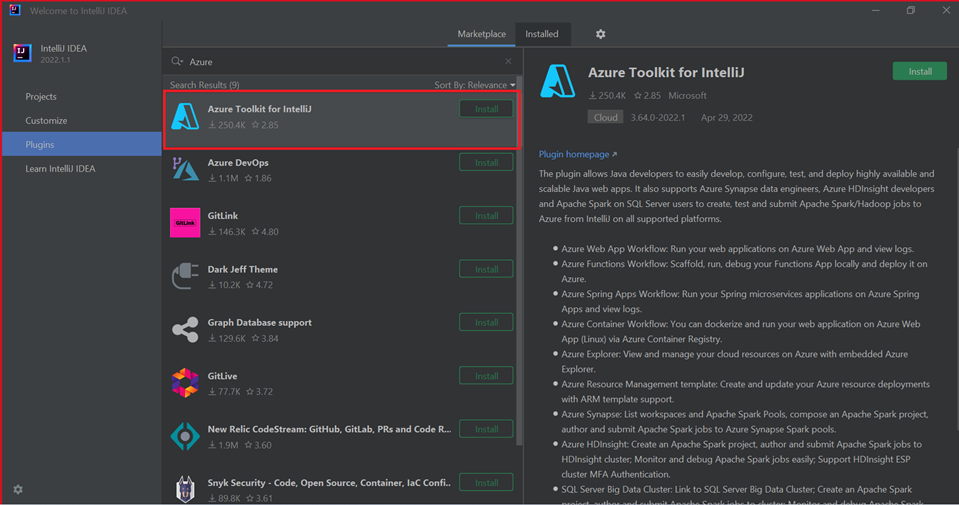
Pilih Instal untuk Azure Toolkit untuk IntelliJ.
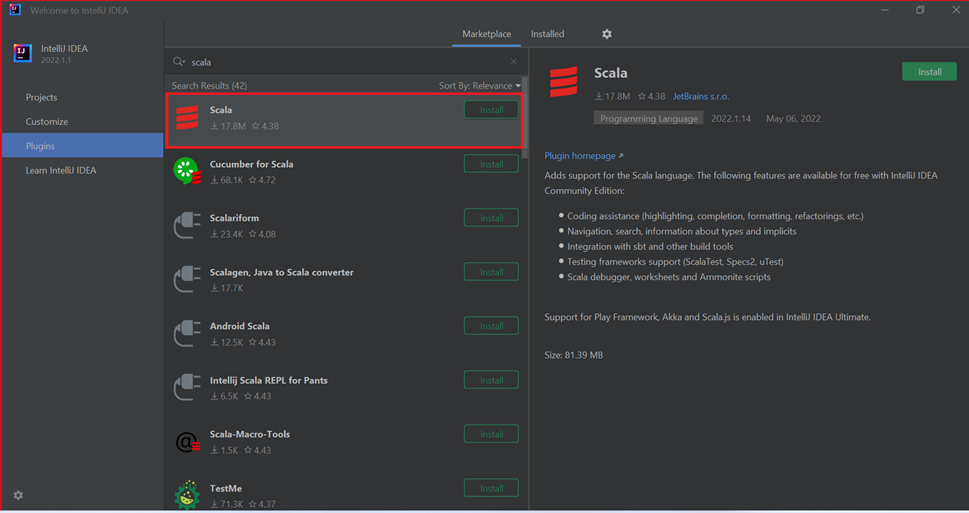
Pilih Instal untuk plugin Scala yang ditampilkan di jendela baru.
Setelah plugin berhasil diinstal, Anda harus menghidupkan ulang IDE.
Gunakan IntelliJ untuk membuat aplikasi
Buka IntelliJ IDEA, dan pilih Buat Proyek Baru untuk membuka jendela Proyek Baru.
Pilih Apache Spark/Azure HDInsight dari panel sebelah kiri.
Pilih Proyek Spark (Scala) dari jendela utama.
Dari daftar menurun Alat build, pilih salah satu nilai berikut ini:
- Maven untuk dukungan wizard pembuatan proyek Scala.
- SBT untuk mengelola dependensi dan pembangunan proyek Scala.
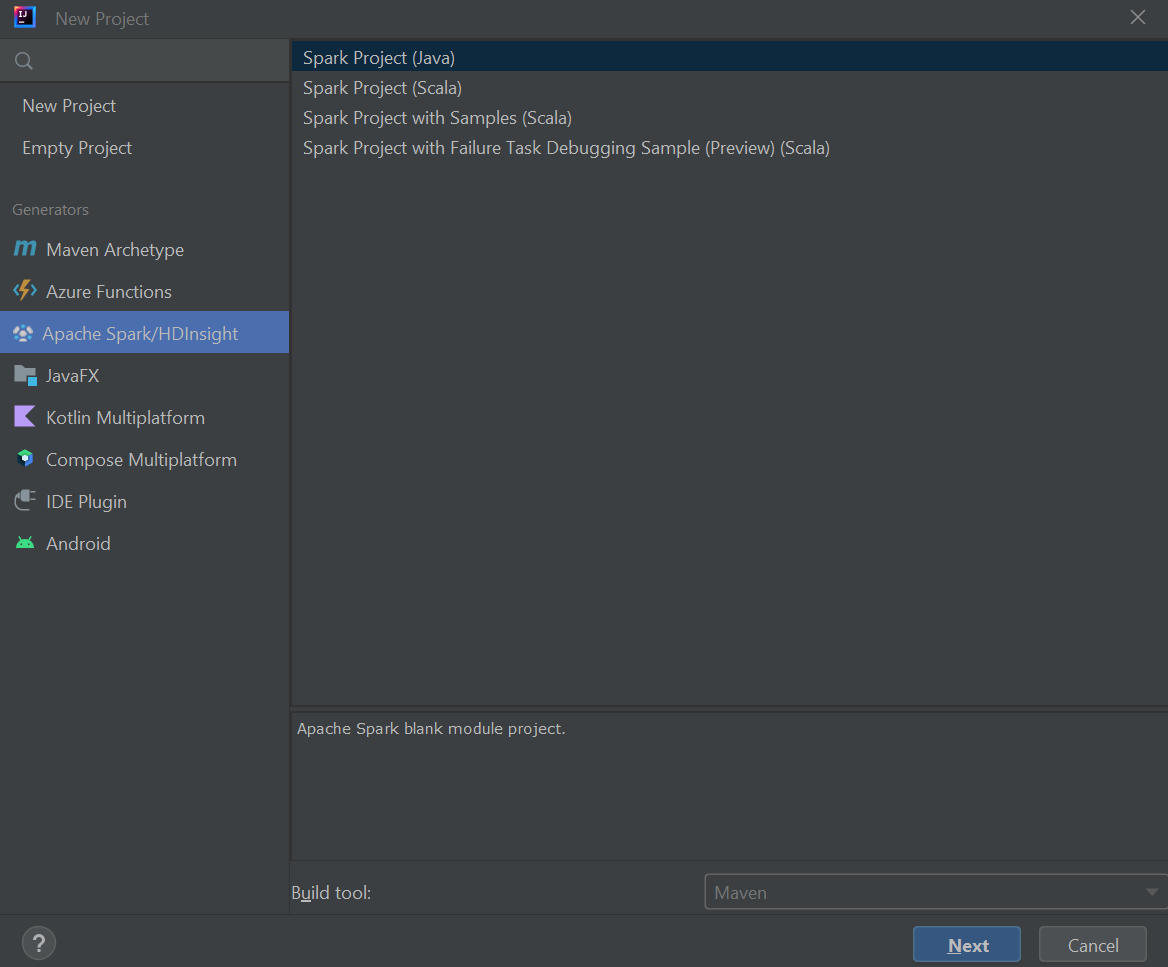
Pilih Selanjutnya.
Di jendela Proyek Baru, berikan informasi berikut ini:
Properti Deskripsi Nama proyek Masukkan nama. Lokasi proyek Masukkan lokasi untuk menyimpan proyek Anda. SDK Proyek Bidang ini kosong pada penggunaan IDEA pertama Anda. Pilih Baru... dan navigasi ke JDK Anda. Versi Spark Wizard pembuatan mengintegrasikan versi yang tepat untuk SDK Spark dan SDK Scala. Jika versi kluster Spark lebih lama dari 2.0, pilih Spark 1.x. Jika tidak, pilih Spark2.x. Contoh ini menggunakan Spark 2.3.0 (Scala 2.11.8). 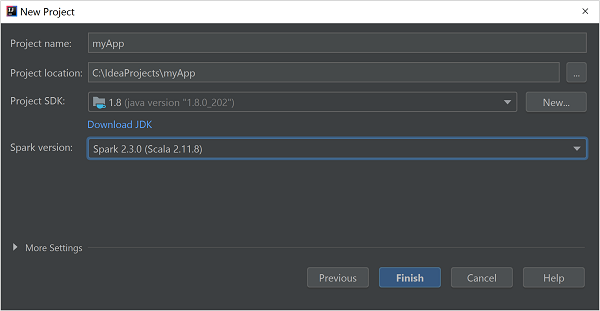
Pilih Selesai.
Buat proyek Scala mandiri
Buka IntelliJ IDEA, dan pilih Buat Proyek Baru untuk membuka jendela Proyek Baru.
Pilih Maven dari panel kiri.
Tentukan SDK Proyek. Jika kosong, pilih Baru... dan navigasi ke direktori instalasi Java.
Pilih kotak centang Buat dari arketipe.
Dari daftar arketipe, pilih
org.scala-tools.archetypes:scala-archetype-simple. Arketipe ini membuat struktur direktori yang tepat dan mengunduh dependensi default yang diperlukan untuk menulis program Scala.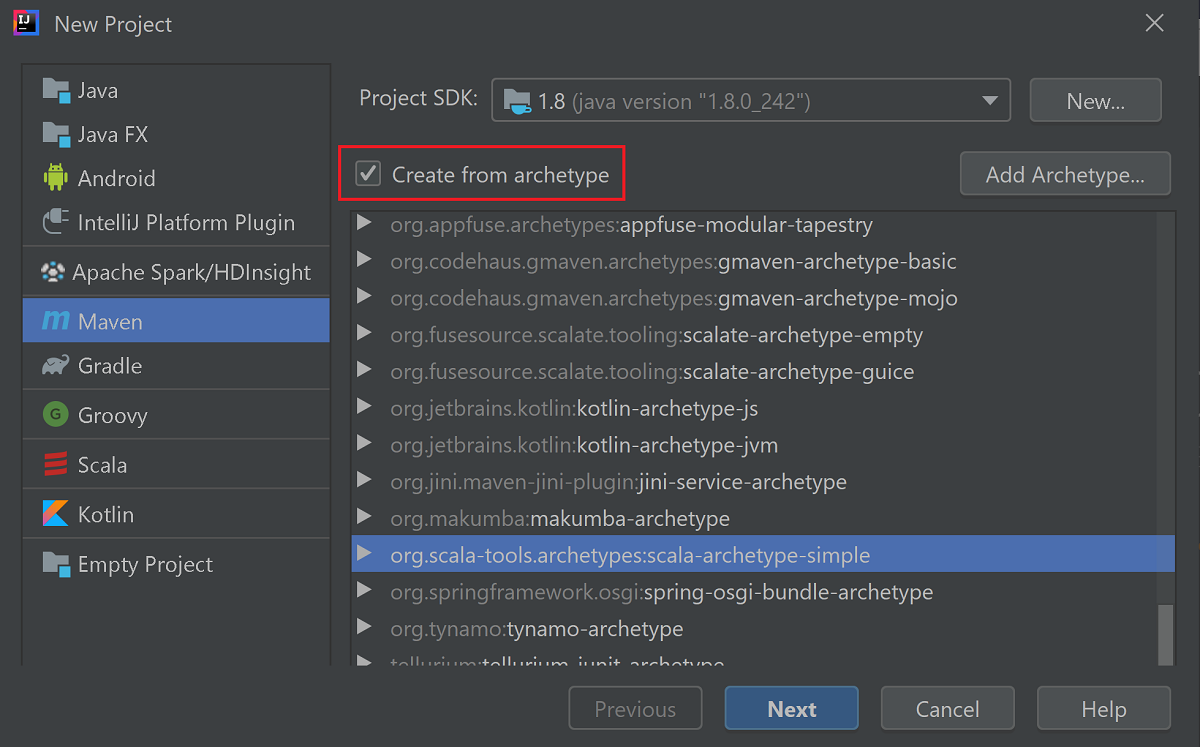
Pilih Selanjutnya.
Luaskan Koordinat Artefak. Berikan nilai yang relevan untuk GroupId, dan ArtifactId. Nama, dan Lokasi akan otomatis diisi. Nilai-nilai berikut digunakan dalam tutorial ini:
- GroupId: com.microsoft.spark.example
- ArtifactId: SparkSimpleApp
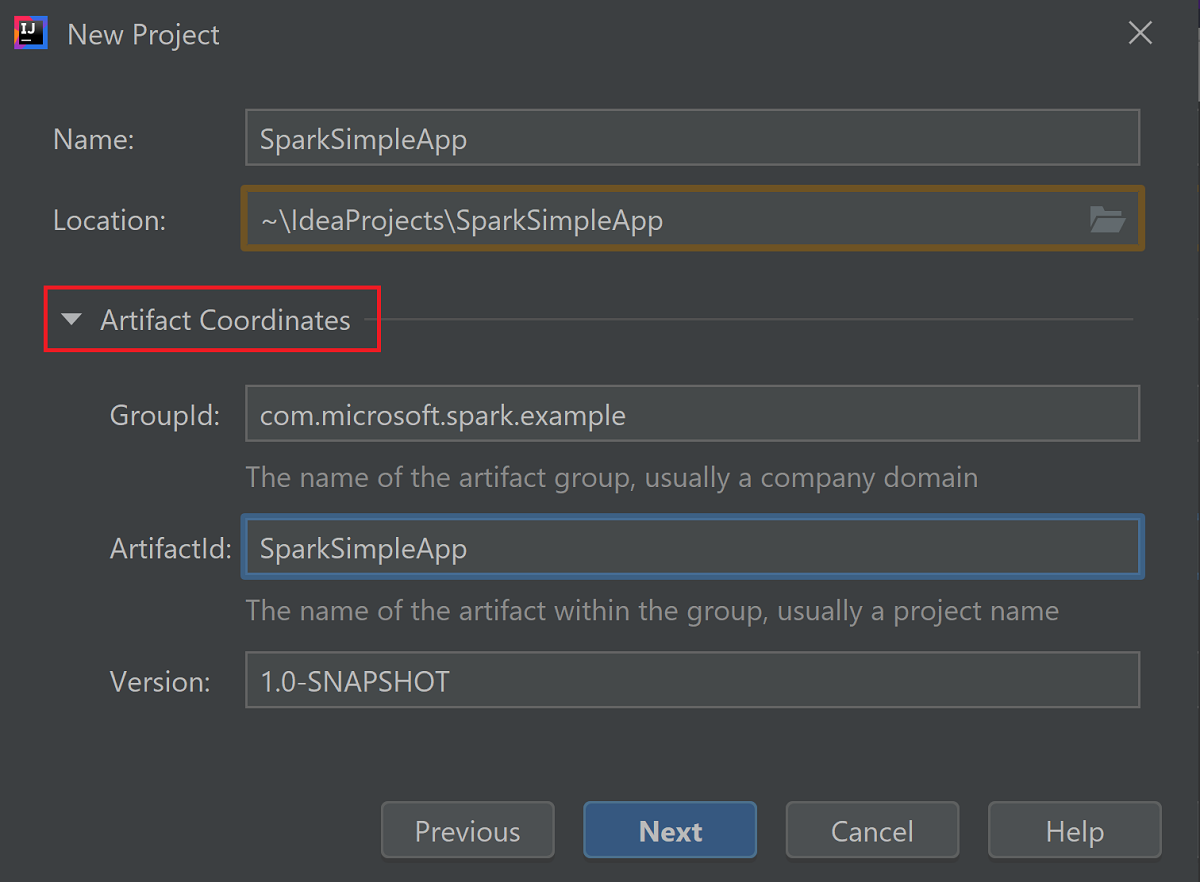
Pilih Selanjutnya.
Verifikasi pengaturan tersebut lalu pilih Berikutnya.
Verifikasi nama dan lokasi proyek, lalu pilih Selesai. Proyek ini akan memakan waktu beberapa menit untuk mengimpor.
Setelah proyek diimpor, dari panel kiri navigasi ke SparkSimpleApp>src>test>scala>com>microsoft>spark>example. Klik kanan MySpec, lalu pilih Hapus.... Anda tidak memerlukan file ini untuk aplikasi ini. Pilih OK dalam kotak dialog.
Pada langkah selanjutnya, Anda perbarui pom.xml untuk menentukan dependensi aplikasi Spark Scala. Supaya dependensi tersebut diunduh dan ditangani secara otomatis, Anda harus mengonfigurasikan Maven.
Dari menu File, pilih Pengaturan untuk membuka jendela Pengaturan.
Dari jendela Pengaturan, navigasi ke Build, Eksekusi, Penyebaran>Alat Build>Maven>Mengimpor.
Pilih kotak centang Impor proyek Maven secara otomatis.
Pilih Terapkan, lalu pilih OK. Anda kemudian akan dikembalikan ke jendela proyek.
:::image type="content" source="./media/apache-spark-create-standalone-application/configure-maven-download.png" alt-text="Configure Maven for automatic downloads." border="true":::Dari panel kiri, navigasi ke src>main>scala>com.microsoft.spark.example, lalu klik dua kali App untuk membuka App.scala.
Ganti kode sampel yang ada dengan kode berikut dan simpan perubahan. Kode ini membaca data dari HVAC.csv (tersedia di semua kluster Spark HDInsight). Ambil baris yang hanya memiliki satu digit di kolom keenam. Dan tulis output ke /HVACOut di dalam kontainer penyimpanan default untuk kluster itu.
package com.microsoft.spark.example import org.apache.spark.SparkConf import org.apache.spark.SparkContext /** * Test IO to wasb */ object WasbIOTest { def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("WASBIOTest") val sc = new SparkContext(conf) val rdd = sc.textFile("wasb:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows which have only one digit in the 7th column in the CSV val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasb:///HVACout") } }Di panel kiri, klik dua kali pom.xml.
Dalam
<project>\<properties>tambahkan segmen berikut:<scala.version>2.11.8</scala.version> <scala.compat.version>2.11.8</scala.compat.version> <scala.binary.version>2.11</scala.binary.version>Dalam
<project>\<dependencies>tambahkan segmen berikut:<dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${scala.binary.version}</artifactId> <version>2.3.0</version> </dependency>Save changes to pom.xml.Membuat file .jar. IntelliJ IDEA memungkinkan pembuatan JAR sebagai artefak proyek. Lakukan langkah-langkah berikut.
Dari menu File, pilih Struktur Proyek....
Dari jendela Struktur Proyek, navigasi ke Artefak>simbol plus +>JAR>Dari modul dengan dependensi....
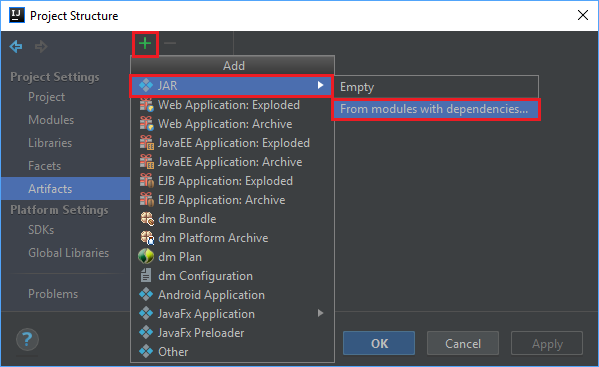
Di jendela Buat JAR dari Modul, pilih ikon folder di kotak teks Kelas Utama.
Di jendela Pilih Kelas Utama, pilih kelas yang muncul secara default lalu pilih OK.
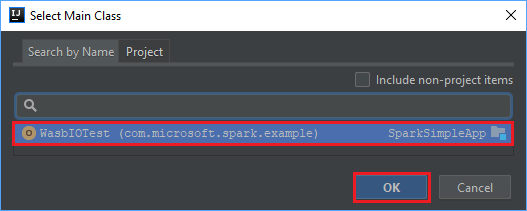
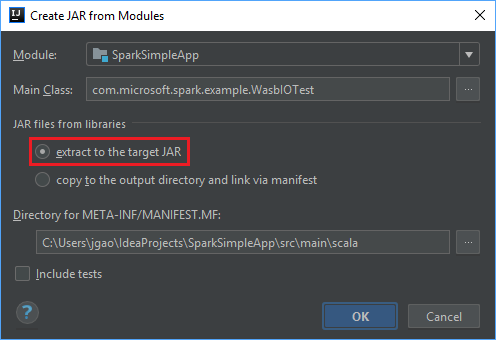
Di jendela Buat JAR dari Modul, pastikan opsi ekstrak ke JAR target dipilih, lalu pilih OK. Pengaturan ini membuat satu JAR dengan semua dependensi.
Tab Tata Letak Output mencantumkan semua jar yang termasuk dalam bagian proyek Maven. Anda dapat memilih dan menghapus jar yang tidak memiliki dependensi langsung dengan aplikasi Scala. Untuk aplikasi ini, yang Anda buat di sini, Anda dapat menghapus semua kecuali yang terakhir (output kompilasi SparkSimpleApp). Pilih jar yang akan dihapus lalu pilih simbol negatif -.
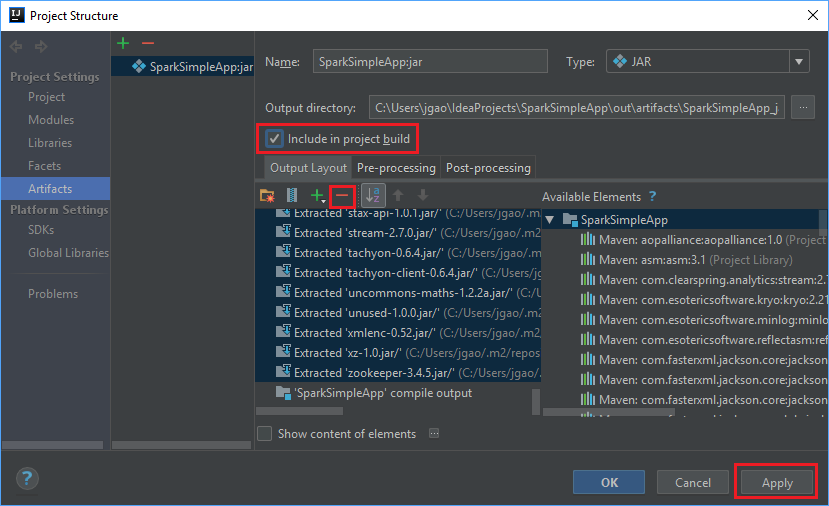
Pastikan kotak centang Sertakan dalam build proyek dipilih. Opsi ini memastikan bahwa jar dibuat setiap kali proyek dibangun atau diperbarui. Pilih Terapkan lalu pilih OK.
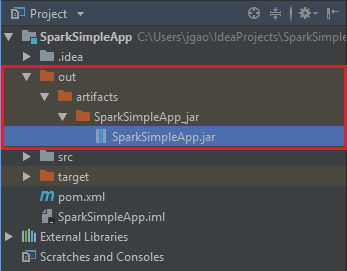
Untuk membuat jar, navigasi ke Build>Bangun Artefak>Bangun. Proyek ini akan dibangun dalam waktu sekitar 30 detik. Jar output dibuat di \out\artefak.
Jalankan aplikasi pada kluster Apache Spark
Untuk menjalankan aplikasi pada kluster, Anda dapat menggunakan pendekatan berikut:
Salin jar aplikasi ke blob Microsoft Azure Storage yang berkaitan dengan kluster. Anda dapat menggunakan AzCopy, utilitas baris perintah, untuk melakukannya. Ada banyak klien lain yang juga dapat Anda gunakan untuk mengunggah data. Anda dapat mengetahui lebih banyak tentang mereka di Pekerjaan mengunggah data ke Apache Hadoop di HDInsight.
Gunakan Apache Livy untuk mengirim pekerjaan aplikasi dari jarak jauh ke kluster Spark. Kluster spark di HDInsight mencakup Livy yang memperlihatkan titik akhir REST untuk mengirimkan pekerjaan Spark dari jarak jauh. Untuk informasi selengkapnya, lihat Mengirim pekerjaan Apache Spark dari jarak jauh menggunakan Apache Livy dengan kluster Spark di HDInsight.
Membersihkan sumber daya
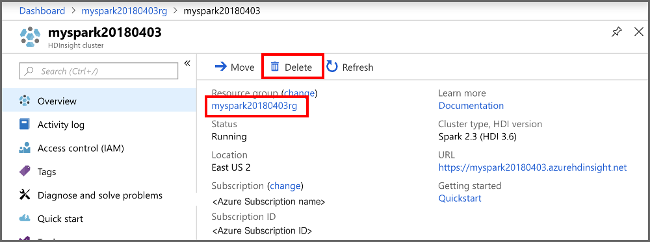
Jika Anda tidak akan terus menggunakan aplikasi ini, hapus kluster yang Anda buat dengan langkah-langkah berikut:
Masuk ke portal Azure.
Dalam kotak Pencarian di bagian atas, ketik Microsoft Azure HDInsight.
Pilih kluster Microsoft Azure HDInsight di Layanan.
Dalam daftar kluster HDInsight yang muncul, pilih ... di samping kluster yang Anda buat untuk tutorial ini.
Pilih Hapus. Pilih Ya.
Langkah selanjutnya
Di artikel ini, Anda belajar cara membuat aplikasi scala Apache Spark. Lanjutkan ke artikel berikutnya untuk mempelajari cara menjalankan aplikasi ini pada kluster Spark HDInsight menggunakan Livy.