DevOps untuk alur penyerapan data
Dalam kebanyakan skenario, solusi penyerapan data merupakan gabungan dari skrip, pemanggilan layanan, dan alur yang mengatur semua aktivitas. Dalam artikel ini, Anda akan mempelajari cara menerapkan praktik DevOps ke siklus hidup pengembangan alur penyerapan data umum yang menyiapkan data untuk pelatihan model pembelajaran mesin. Alur ini dibangun menggunakan layanan Azure berikut:
- Azure Data Factory: Membaca data mentah dan mengatur penyiapan data.
- Azure Databricks: Menjalankan notebook Python yang mentransformasikan data.
- Azure Pipelines: Mengotomatiskan proses integrasi dan pengembangan berkelanjutan.
Alur kerja penyerapan data
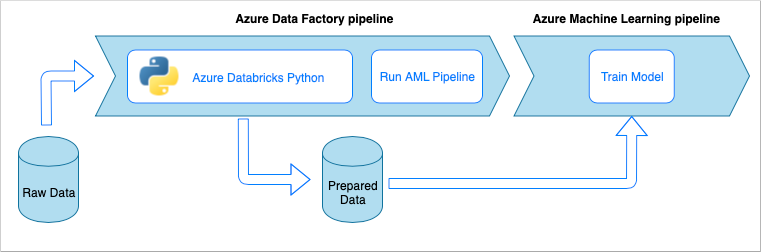
Alur penyerapan data mengimplementasikan alur kerja berikut:
- Data mentah dibaca di alur Azure Data Factory (ADF).
- Alur ADF mengirimkan data ke kluster Azure Databricks, yang menjalankan notebook Python untuk mentransformasikan data.
- Data disimpan ke kontainer blob. Di sini, data tersebut dapat digunakan oleh Pembelajaran Mesin Microsoft Azure untuk melatih model.
Ringkasan integrasi dan pengiriman berkelanjutan
Seperti kebanyakan solusi perangkat lunak lainnya, terdapat tim (misalnya, Teknisi Data) yang mengerjakannya. Tim ini berkolaborasi dan berbagi sumber daya Azure yang sama seperti akun Azure Data Factory, Azure Databricks, dan Azure Storage. Pengumpulan sumber daya ini adalah lingkungan Pengembangan. Teknisi data berkontribusi pada basis kode sumber yang sama.
Sistem integrasi dan pengiriman berkelanjutan mengotomatiskan proses pembangunan, pengujian, dan pengiriman (penyebaran) solusi. Proses Integrasi Berkelanjutan (CI) melakukan tugas-tugas berikut:
- Menggabungkan kode
- Memeriksanya dengan pengujian kualitas kode
- Menjalankan pengujian unit
- Menghasilkan artefak seperti kode yang diuji dan templat Azure Resource Manager
Proses Pengiriman Berkelanjutan (CD) menyebarkan artefak ke lingkungan hilir.
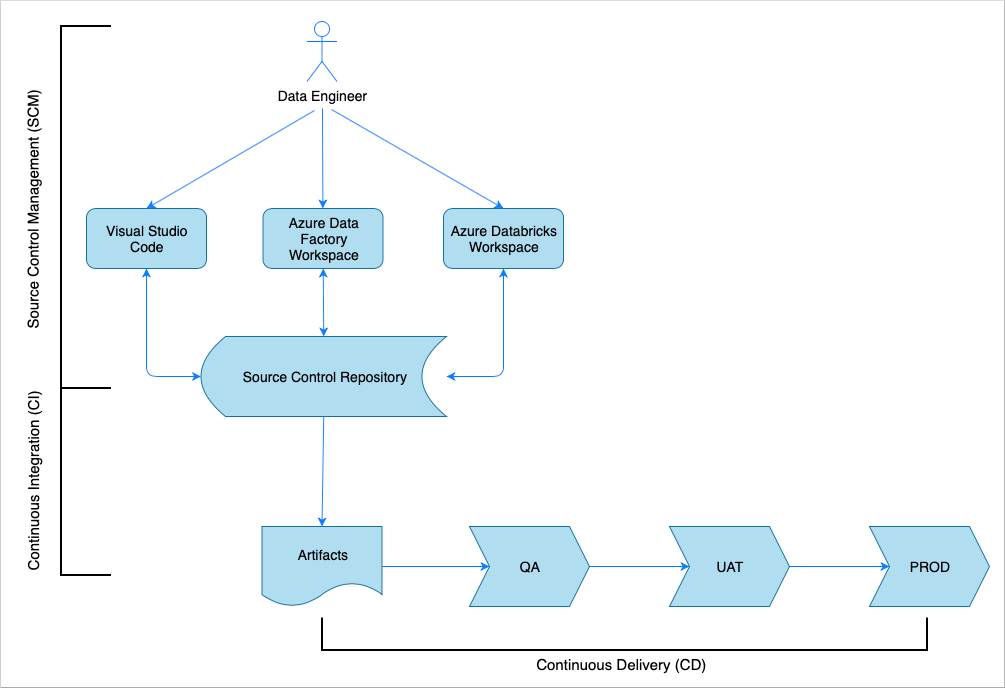
Artikel ini menunjukkan cara mengotomatisasi proses CI dan CD dengan Azure Pipelines.
Manajemen kontrol sumber
Manajemen kontrol sumber diperlukan untuk melacak perubahan dan memungkinkan kolaborasi antar-anggota tim. Misalnya, kode akan disimpan di repositori Azure DevOps, GitHub, atau GitLab. Alur kerja kolaborasi didasarkan pada model percabangan.
Kode Sumber Python Notebook
Teknisi data bekerja dengan kode sumber notebook Python baik secara lokal dalam IDE (misalnya, Visual Studio Code) atau langsung di ruang kerja Databricks. Setelah perubahan kode selesai, kode tersebut digabungkan ke repositori dengan mengikuti kebijakan percabangan.
Tip
Sebaiknya simpan kode dalam file .py, jangan simpan dalam format .ipynb Jupyter Notebook. Hal ini akan meningkatkan keterbacaan kode dan mengaktifkan pemeriksaan kualitas kode otomatis dalam proses CI.
Kode Sumber Azure Data Factory
Kode sumber alur Azure Data Factory adalah kumpulan file JSON yang dihasilkan oleh ruang kerja Azure Data Factory. Biasanya teknisi data bekerja dengan desainer visual di ruang kerja Azure Data Factory, bukan dengan file kode sumber secara langsung.
Guna mengonfigurasi ruang kerja untuk menggunakan repositori kontrol sumber, lihat Menulis dengan integrasi Azure Repos Git.
Integrasi berkelanjutan (CI)
Tujuan akhir dari proses Integrasi Berkelanjutan adalah mengumpulkan kerja tim gabungan dari kode sumber dan mempersiapkannya untuk penyebaran ke lingkungan hilir. Seperti halnya manajemen kode sumber, proses ini berbeda untuk notebook Python dan alur Azure Data Factory.
Python Notebook CI
Proses CI untuk Python Notebooks mendapatkan kode dari cabang kolaborasi (misalnya, master atau develop) dan melakukan aktivitas berikut:
- Code linting
- Pengujian Unit
- Menyimpan kode sebagai artefak
Cuplikan kode berikut menunjukkan implementasi langkah-langkah ini dalam alur yaml Azure DevOps:
steps:
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
- publish: $(Build.SourcesDirectory)
artifact: di-notebooks
Alur ini menggunakan flake8 untuk melakukan code linting Python. Alur ini menjalankan pengujian unit yang ditentukan dalam kode sumber serta menerbitkan hasil linting dan pengujian, sehingga tersedia di layar eksekusi Azure Pipeline.
Jika linting dan pengujian unit berhasil, alur ini akan menyalin kode sumber ke repositori artefak yang akan digunakan oleh langkah-langkah penyebaran berikutnya.
Azure Data Factory CI
Proses CI untuk alur Azure Data Factory adalah hambatan untuk alur penyerapan data. Tidak ada integrasi berkelanjutan. Artefak yang dapat disebarkan untuk Azure Data Factory adalah kumpulan templat Azure Resource Manager. Satu-satunya cara untuk menghasilkan templat tersebut adalah dengan mengklik tombol terbitkan di ruang kerja Azure Data Factory.
- Teknisi data menggabungkan kode sumber dari cabang fitur mereka ke dalam cabang kolaborasi, misalnya, master atau develop.
- Seseorang yang memiliki izin mengklik tombol terbitkan untuk menghasilkan templat Azure Resource Manager dari kode sumber di cabang kolaborasi.
- Ruang kerja memvalidasi alur (anggap saja sebagai pengujian unit dan linting) menghasilkan templat Azure Resource Manager (anggap saja seperti membangun), dan menyimpan templat yang dihasilkan ke cabang teknis adf_publish dalam repositori kode yang sama (anggap saja seperti menerbitkan artefak). Cabang ini dibuat secara otomatis oleh ruang kerja Azure Data Factory.
Untuk informasi selengkapnya tentang proses ini, lihat Integrasi dan pengiriman berkelanjutan di Azure Data Factory.
Sangat penting untuk memastikan bahwa templat Azure Resource Manager yang dihasilkan akan mengabaikan lingkungan. Ini berarti bahwa semua nilai yang mungkin berbeda antara lingkungan akan dijadikan sebagai parameter. Azure Data Factory cukup cerdas untuk mengekspos sebagian besar nilai seperti parameter. Misalnya dalam templat berikut, properti koneksi ke ruang kerja Pembelajaran Mesin Microsoft Azure diekspos sebagai parameter:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
"AzureMLService_servicePrincipalKey": {
"value": ""
},
"AzureMLService_properties_typeProperties_subscriptionId": {
"value": "0fe1c235-5cfa-4152-17d7-5dff45a8d4ba"
},
"AzureMLService_properties_typeProperties_resourceGroupName": {
"value": "devops-ds-rg"
},
"AzureMLService_properties_typeProperties_servicePrincipalId": {
"value": "6e35e589-3b22-4edb-89d0-2ab7fc08d488"
},
"AzureMLService_properties_typeProperties_tenant": {
"value": "72f988bf-86f1-41af-912b-2d7cd611db47"
}
}
}
Namun, sebaiknya Anda mengekspos properti kustom yang tidak ditangani oleh ruang kerja Azure Data Factory secara default. Dalam skenario artikel ini, alur Azure Data Factory memanggil notebook Python yang memproses data. Notebook menerima parameter dengan nama file data input.
import pandas as pd
import numpy as np
data_file_name = getArgument("data_file_name")
data = pd.read_csv(data_file_name)
labels = np.array(data['target'])
...
Nama ini berbeda untuk lingkungan Dev, QA, UAT, dan PROD. Dalam alur yang kompleks dengan beberapa aktivitas, mungkin saja terdapat beberapa properti kustom. Mengumpulkan semua nilai tersebut di satu tempat dan menetapkannya sebagai variabel alur adalah praktik terbaik:
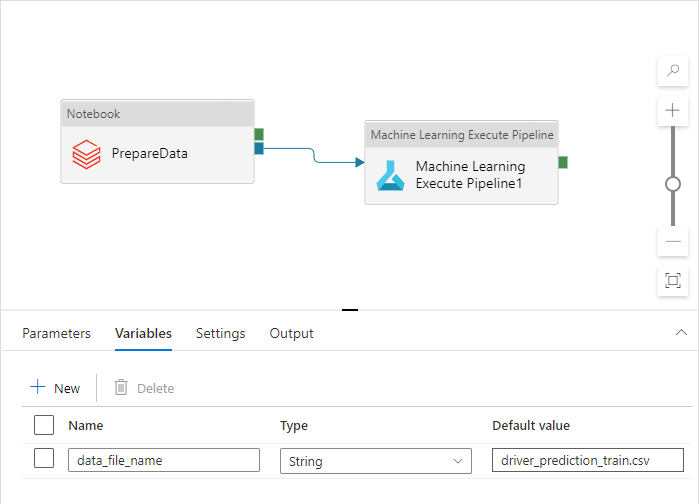
Aktivitas alur dapat mengacu pada variabel alur sekaligus menggunakannya dalam praktik nyata:
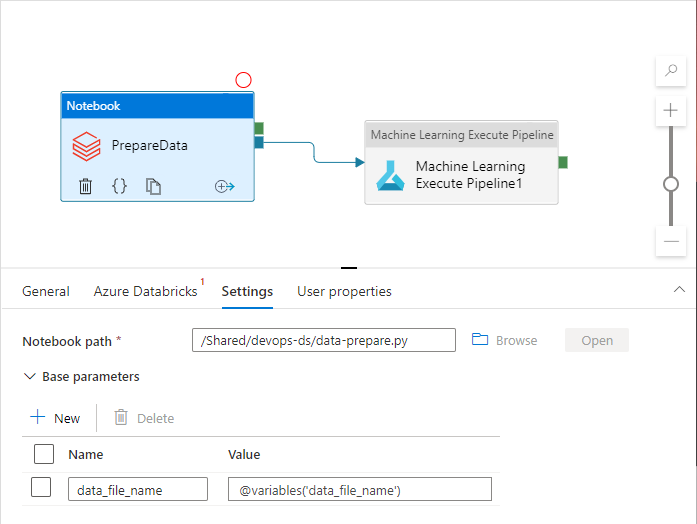
Ruang kerja Azure Data Factory tidak mengekspos variabel alur sebagai parameter templat Azure Resource Manager secara default. Ruang kerja ini menggunakan Templat Parameterisasi Default yang memberi instruksi terkait apa yang harus diekspos properti alur sebagai parameter templat Azure Resource Manager. Untuk menambahkan variabel alur ke daftar, perbarui bagian "Microsoft.DataFactory/factories/pipelines"Template Parameterisasi Default dengan cuplikan berikut, dan letakkan file json hasil di akar folder sumber:
"Microsoft.DataFactory/factories/pipelines": {
"properties": {
"variables": {
"*": {
"defaultValue": "="
}
}
}
}
Tindakan ini akan memaksa ruang kerja Azure Data Factory untuk menambahkan variabel ke daftar parameter saat tombol terbitkan diklik:
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"factoryName": {
"value": "devops-ds-adf"
},
...
"data-ingestion-pipeline_properties_variables_data_file_name_defaultValue": {
"value": "driver_prediction_train.csv"
}
}
}
Nilai dalam file JSON adalah nilai default yang dikonfigurasi dalam definisi alur. Nilai ini diharapkan akan diambil alih dengan nilai lingkungan target saat templat Azure Resource Manager disebarkan.
Pengiriman berkelanjutan (CD)
Proses Pengiriman Berkelanjutan membawa artefak dan menyebarkannya ke lingkungan target pertama. Hal ini memastikan bahwa solusi berfungsi dengan menjalankan tes. Jika berhasil, solusi akan berlanjut ke lingkungan berikutnya.
CD Azure Pipeline terdiri dari beberapa tahap yang mewakili lingkungan. Setiap tahap berisi penyebaran dan pekerjaan yang menjalankan langkah-langkah berikut:
- Menyebarkan Python Notebook ke ruang kerja Azure Databricks
- Menyebarkan alur Azure Data Factory
- Menjalankan alur
- Memeriksa hasil penyerapan data
Tahapan alur dapat dikonfigurasi dengan persetujuan dan gerbang yang memberikan kontrol tambahan terkait bagaimana proses penyebaran berevolusi melalui rantai lingkungan.
Menyebarkan Python Notebook
Cuplikan kode berikut menetapkan penyebaran Azure Pipeline yang menyalin notebook Python ke kluster Databricks:
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
Artefak yang dihasilkan oleh CI akan otomatis disalin ke agen penyebaran dan tersedia di folder $(Pipeline.Workspace). Dalam kasus ini, tugas penyebaran mengacu pada artefak di-notebooks yang berisi notebook Python. Penyebaran ini menggunakan ekstensi Databricks Azure DevOps untuk menyalin file notebook ke ruang kerja Databricks.
Tahap Deploy_to_QA berisi referensi ke grup variabel devops-ds-qa-vg yang ditentukan dalam proyek Azure DevOps. Langkah-langkah dalam tahap ini mengacu pada variabel dari grup variabel ini (misalnya, $(DATABRICKS_URL) dan $(DATABRICKS_TOKEN) ). Konsepnya adalah bahwa tahap berikutnya (misalnya, Deploy_to_UAT) akan beroperasi dengan nama variabel yang sama, yang ditentukan dalam grup variabel cakupan UAT tersendiri.
Menyebarkan alur Azure Data Factory
Artefak yang dapat disebarkan untuk Azure Data Factory adalah templat Azure Resource Manager. Templat akan disebarkan dengan tugas Penyebaran Grup Sumber Daya Azure seperti yang ditunjukkan dalam cuplikan berikut:
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
Nilai parameter nama file data berasal dari variabel $(DATA_FILE_NAME) yang ditentukan dalam grup variabel tahap QA. Demikian pula, semua parameter yang ditentukan dalam ARMTemplateForFactory.json juga dapat diambil alih. Jika tidak, nilai default akan digunakan.
Menjalankan alur dan memeriksa hasil penyerapan data
Langkah selanjutnya adalah memastikan bahwa solusi yang disebarkan sudah berfungsi. Definisi pekerjaan berikut menjalankan alur Azure Data Factory dengan skrip PowerShell dan menjalankan notebook Python pada kluster Azure Databricks. Notebook ini memeriksa apakah data tersebut telah diserap dengan benar dan memvalidasi file data hasil dengan nama $(bin_FILE_NAME).
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'
Tugas akhir dalam pekerjaan memeriksa hasil eksekusi notebook. Jika menampilkan kesalahan, tugas ini mengatur status eksekusi alur ke gagal.
Ringkasan
CI/CD Azure Pipeline yang lengkap terdiri dari tahapan berikut:
- CI
- Menyebarkan ke QA
- Menyebarkan ke Databricks + Menyebarkan ke ADF
- Pengujian Integrasi
Pengujian berisi sejumlah tahapan Sebarkan yang sama dengan jumlah lingkungan target yang Anda miliki. Setiap tahapan Deploy berisi dua penyebaran yang berjalan secara paralel dan pekerjaan yang berjalan setelah penyebaran untuk menguji solusi pada lingkungan.
Sampel implementasi alur dikumpulkan dalam cuplikan yaml berikut:
variables:
- group: devops-ds-vg
stages:
- stage: 'CI'
displayName: 'CI'
jobs:
- job: "CI_Job"
displayName: "CI Job"
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- script: pip install --upgrade flake8 flake8_formatter_junit_xml
displayName: 'Install flake8'
- checkout: self
- script: |
flake8 --output-file=$(Build.BinariesDirectory)/lint-testresults.xml --format junit-xml
workingDirectory: '$(Build.SourcesDirectory)'
displayName: 'Run flake8 (code style analysis)'
- script: |
python -m pytest --junitxml=$(Build.BinariesDirectory)/unit-testresults.xml $(Build.SourcesDirectory)
displayName: 'Run unit tests'
- task: PublishTestResults@2
condition: succeededOrFailed()
inputs:
testResultsFiles: '$(Build.BinariesDirectory)/*-testresults.xml'
testRunTitle: 'Linting & Unit tests'
failTaskOnFailedTests: true
displayName: 'Publish linting and unit test results'
# The CI stage produces two artifacts (notebooks and ADF pipelines).
# The pipelines Azure Resource Manager templates are stored in a technical branch "adf_publish"
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/code/dataingestion
artifact: di-notebooks
- checkout: git://${{variables['System.TeamProject']}}@adf_publish
- publish: $(Build.SourcesDirectory)/$(Build.Repository.Name)/devops-ds-adf
artifact: adf-pipelines
- stage: 'Deploy_to_QA'
displayName: 'Deploy to QA'
variables:
- group: devops-ds-qa-vg
jobs:
- deployment: "Deploy_to_Databricks"
displayName: 'Deploy to Databricks'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: deploynotebooks@0
inputs:
notebooksFolderPath: '$(Pipeline.Workspace)/di-notebooks'
workspaceFolder: '/Shared/devops-ds'
displayName: 'Deploy (copy) data processing notebook to the Databricks cluster'
- deployment: "Deploy_to_ADF"
displayName: 'Deploy to ADF'
timeoutInMinutes: 0
environment: qa
strategy:
runOnce:
deploy:
steps:
- task: AzureResourceGroupDeployment@2
displayName: 'Deploy ADF resources'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
resourceGroupName: $(RESOURCE_GROUP)
location: $(LOCATION)
csmFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateForFactory.json'
csmParametersFile: '$(Pipeline.Workspace)/adf-pipelines/ARMTemplateParametersForFactory.json'
overrideParameters: -data-ingestion-pipeline_properties_variables_data_file_name_defaultValue "$(DATA_FILE_NAME)"
- job: "Integration_test_job"
displayName: "Integration test job"
dependsOn: [Deploy_to_Databricks, Deploy_to_ADF]
pool:
vmImage: 'ubuntu-latest'
timeoutInMinutes: 0
steps:
- task: AzurePowerShell@4
displayName: 'Execute ADF Pipeline'
inputs:
azureSubscription: $(AZURE_RM_CONNECTION)
ScriptPath: '$(Build.SourcesDirectory)/adf/utils/Invoke-ADFPipeline.ps1'
ScriptArguments: '-ResourceGroupName $(RESOURCE_GROUP) -DataFactoryName $(DATA_FACTORY_NAME) -PipelineName $(PIPELINE_NAME)'
azurePowerShellVersion: LatestVersion
- task: UsePythonVersion@0
inputs:
versionSpec: '3.x'
addToPath: true
architecture: 'x64'
displayName: 'Use Python3'
- task: configuredatabricks@0
inputs:
url: '$(DATABRICKS_URL)'
token: '$(DATABRICKS_TOKEN)'
displayName: 'Configure Databricks CLI'
- task: executenotebook@0
inputs:
notebookPath: '/Shared/devops-ds/test-data-ingestion'
existingClusterId: '$(DATABRICKS_CLUSTER_ID)'
executionParams: '{"bin_file_name":"$(bin_FILE_NAME)"}'
displayName: 'Test data ingestion'
- task: waitexecution@0
displayName: 'Wait until the testing is done'