Hapus duplikat di setiap tabel untuk penyatuan data
Langkah aturan deduplikasi penyatuan menemukan dan menghapus rekaman duplikat untuk pelanggan dari tabel sumber sehingga setiap pelanggan diwakili oleh satu baris di setiap tabel. Setiap tabel diduplikasi secara terpisah menggunakan aturan untuk mengidentifikasi rekaman untuk pelanggan tertentu.
Aturan diproses secara berurutan. Setelah semua aturan dijalankan pada semua rekaman dalam tabel, grup pencocokan yang berbagi baris umum digabungkan menjadi satu grup pencocokan.
Tentukan aturan deduplikasi
Aturan yang baik mengidentifikasi pelanggan yang unik. Pertimbangkan data Anda. Mungkin cukup untuk mengidentifikasi pelanggan berdasarkan bidang seperti email. Namun, jika Anda ingin membedakan pelanggan yang berbagi email, Anda dapat memilih untuk memiliki aturan dengan dua kondisi, yang cocok pada Email + Nama Depan. Untuk informasi selengkapnya, lihat Praktik terbaik deduplikasi.
Pada halaman Aturan duplikasi, pilih tabel dan pilih Tambahkan aturan untuk menentukan aturan duplikasi.
Tip
Jika Anda memperkaya tabel di tingkat sumber data untuk membantu meningkatkan hasil penyatuan, pilih Gunakan tabel yang diperkaya di bagian atas halaman. Untuk informasi selengkapnya, lihat Pengayaan untuk sumber data.
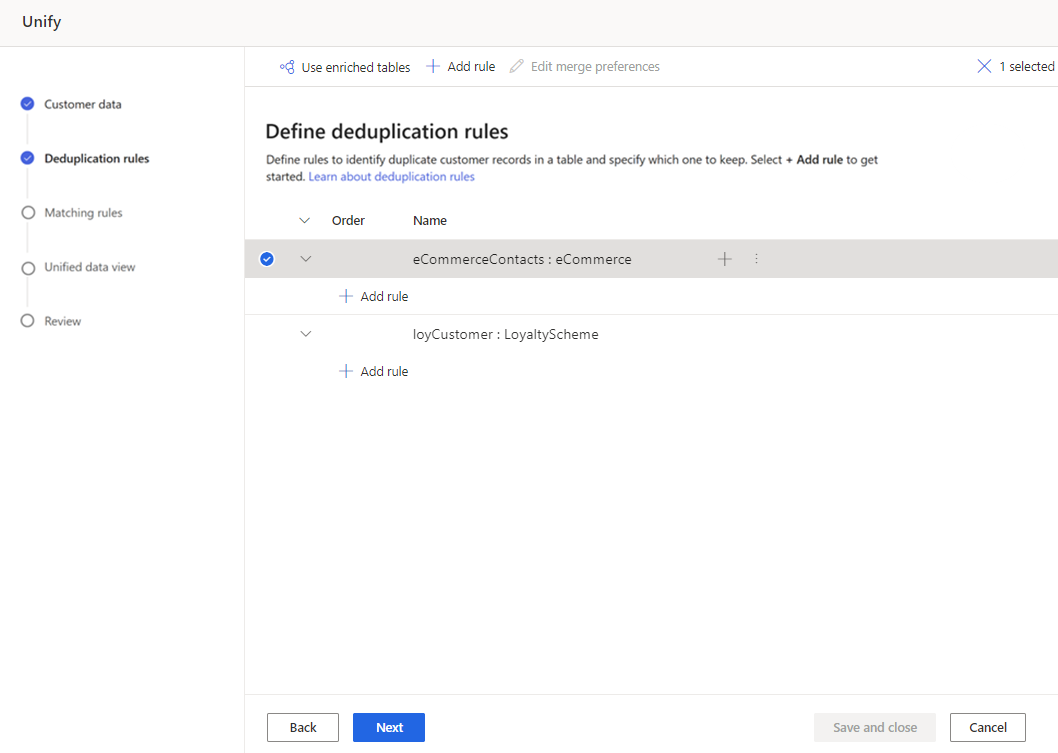
Di panel Tambahkan aturan , masukkan informasi berikut:
Pilih bidang: Pilih dari daftar bidang yang tersedia dari tabel yang ingin Anda periksa untuk duplikat. Pilih bidang yang mungkin unik untuk setiap pelanggan. Contohnya, alamat email, atau kombinasi nama, kota, dan nomor telepon.
Normalisasi: Pilih opsi normalisasi untuk kolom. Normalisasi hanya memengaruhi langkah yang cocok, dan tidak mengubah data.
- Angka: Mengonversi simbol Unicode yang mewakili angka menjadi angka sederhana.
- Simbol: Menghapus simbol dan karakter khusus seperti !" #$%&'()*+,-./:;<=>?@[]^_'{|}~. Misalnya, Kepala & Bahu menjadi HeadShoulder.
- Teks ke huruf kecil: Mengonversi karakter huruf besar menjadi huruf kecil. "SEMUA huruf besar dan huruf besar judul" menjadi "semua huruf besar dan huruf besar judul."
- Jenis (Telepon, Nama, Alamat, Organisasi): Standarisasi nama, gelar, nomor telepon, dan alamat.
- Unicode ke ASCII: Mengonversi karakter Unicode menjadi huruf ASCII yang setara. Misalnya, aksen ề diubah menjadi karakter e.
- Spasi kosong: Menghapus semua spasi. Hello World menjadi HelloWorld.
- Pemetaan alias: Memungkinkan Anda mengunggah daftar pasangan string kustom untuk menunjukkan string yang harus selalu dianggap sama persis.
- Bypass kustom: Memungkinkan Anda mengunggah daftar string kustom untuk menunjukkan string yang tidak boleh dicocokkan.
Presisi: Atur tingkat presisi. Presisi digunakan untuk pencocokan persis dan pencocokan fuzzy, dan menentukan seberapa dekat dua string yang harus dianggap cocok.
- Dasar: Pilih dari Rendah (30%), Sedang (60%), Tinggi (80%), dan Tepat (100%). Pilih Persis untuk hanya mencocokkan rekaman yang cocok 100 persen.
- Kustom: Tetapkan persentase yang harus dicocokkan oleh catatan. Sistem hanya mencocokkan rekaman yang melewati ambang batas ini.
Nama: Nama untuk aturan.
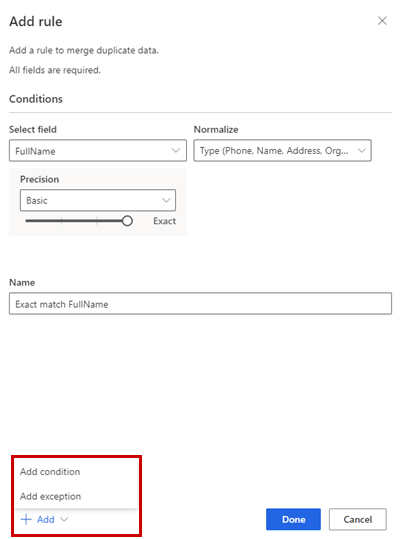
Secara opsional, pilih Tambahkan>kondisi untuk menambahkan lebih banyak kondisi ke aturan. Kondisi terhubung dengan operator AND logis dan dengan demikian hanya dijalankan jika semua kondisi terpenuhi.
Secara opsional,Tambahkan Tambah pengecualian untuk>menambahkan pengecualian ke aturan . ... Pengecualian digunakan untuk mengatasi kasus positif palsu dan negatif palsu yang jarang terjadi.
Pilih Selesai untuk membuat aturan.
Secara opsional, tambahkan lebih banyak aturan.
Pilih tabel, lalu Edit preferensi gabungan.
Di panel preferensi Gabungkan :
Pilih salah satu dari tiga opsi untuk menentukan rekaman mana yang akan disimpan jika duplikat ditemukan:
- Paling banyak terisi: Mengidentifikasi rekaman dengan kolom terbanyak diisi sebagai rekaman pemenang. Ini adalah pilihan penggabungan default.
- Terbaru: Mengidentifikasi catatan pemenang berdasarkan yang paling baru. Memerlukan tanggal atau bidang numerik untuk menentukan keterkinian.
- Paling tidak terbaru: Mengidentifikasi catatan pemenang berdasarkan kebaruan yang paling sedikit. Memerlukan tanggal atau bidang numerik untuk menentukan keterkinian.
Jika ada seri, catatan pemenang adalah yang memiliki MAX(PK) atau nilai kunci utama yang lebih besar.
Secara opsional, untuk menentukan preferensi penggabungan pada masing-masing kolom tabel, pilih Lanjutan di bagian bawah panel. Misalnya, Anda dapat memilih untuk menyimpan email terbaru DAN alamat terlengkap dari catatan yang berbeda. Perluas tabel untuk melihat semua kolomnya dan tentukan opsi mana yang akan digunakan untuk masing-masing kolom. Jika Anda memilih opsi berbasis kebaruan, Anda juga perlu menentukan bidang tanggal/waktu yang menentukan kebaruan.
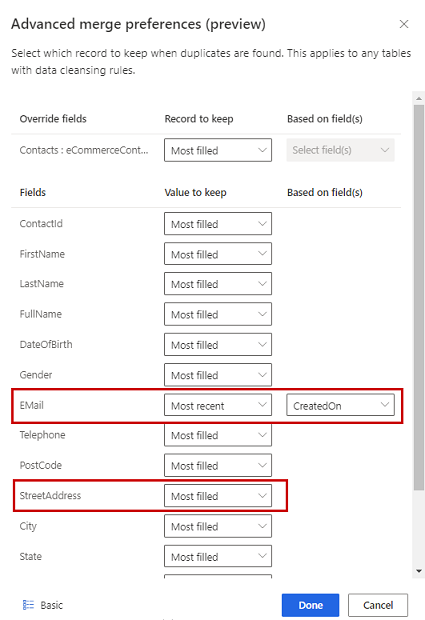
Pilih Selesai untuk menerapkan preferensi penggabungan Anda.
Setelah menentukan aturan deduplikasi dan preferensi penggabungan, pilih Berikutnya.
