Resep: Layanan Azure AI - Deteksi Anomali Multivariat
Resep ini menunjukkan bagaimana Anda dapat menggunakan layanan SynapseML dan Azure AI di Apache Spark untuk deteksi anomali multivariat. Deteksi anomali multivariat memungkinkan deteksi anomali di antara banyak variabel atau rangkaian waktu, dengan mempertimbangkan semua inter-korelasi dan dependensi antara variabel yang berbeda. Dalam skenario ini, kami menggunakan SynapseML untuk melatih model deteksi anomali multivariat menggunakan layanan Azure AI, dan kami kemudian menggunakan model untuk menyimpulkan anomali multivariat dalam himpunan data yang berisi pengukuran sintetis dari tiga sensor IoT.
Penting
Mulai tanggal 20 September 2023 Anda tidak akan dapat membuat sumber daya Detektor Anomali baru. Layanan Detektor Anomali dihentikan pada tanggal 1 Oktober 2026.
Untuk mempelajari selengkapnya tentang Detektor Anomali Azure AI, lihat halaman dokumentasi ini.
Prasyarat
- Langganan Azure - buat langganan gratis
- Lampirkan buku catatan Anda ke lakehouse. Di sisi kiri, pilih Tambahkan untuk menambahkan lakehouse yang ada atau buat lakehouse.
Penyiapan
Ikuti instruksi untuk membuat Anomaly Detector sumber daya menggunakan portal Azure atau sebagai alternatif, Anda juga dapat menggunakan Azure CLI untuk membuat sumber daya ini.
Setelah menyiapkan Anomaly Detector, Anda dapat menjelajahi metode penanganan data dari berbagai bentuk. Katalog layanan dalam Azure AI menyediakan beberapa opsi: Visi, Ucapan, Bahasa, Pencarian web, Keputusan, Terjemahan, dan Kecerdasan Dokumen.
Membuat sumber daya Pendeteksi Anomali
- Di portal Azure, pilih Buat di grup sumber daya Anda, lalu ketik Detektor Anomali. Pilih sumber daya Detektor Anomali.
- Beri nama sumber daya, dan idealnya gunakan wilayah yang sama dengan grup sumber daya Anda lainnya. Gunakan opsi default untuk sisanya, lalu pilih Tinjau + Buat lalu Buat.
- Setelah sumber daya Detektor Anomali dibuat, buka dan pilih
Keys and Endpointspanel di navigasi kiri. Salin kunci untuk sumber daya Detektor Anomali keANOMALY_API_KEYdalam variabel lingkungan, atau simpan dalamanomalyKeyvariabel.
Membuat sumber daya Akun Penyimpanan
Untuk menyimpan data perantara, Anda perlu membuat Akun Azure Blob Storage. Dalam akun penyimpanan tersebut, buat kontainer untuk menyimpan data perantara. Catat nama kontainer, dan salin string koneksi ke kontainer tersebut. Anda membutuhkannya nanti untuk mengisi containerName variabel dan BLOB_CONNECTION_STRING variabel lingkungan.
Memasukkan kunci layanan Anda
Mari kita mulai dengan menyiapkan variabel lingkungan untuk kunci layanan kita. Sel berikutnya mengatur ANOMALY_API_KEY variabel lingkungan dan BLOB_CONNECTION_STRING berdasarkan nilai yang disimpan di Azure Key Vault kami. Jika Anda menjalankan tutorial ini di lingkungan Anda sendiri, pastikan Anda mengatur variabel lingkungan ini sebelum melanjutkan.
import os
from pyspark.sql import SparkSession
from synapse.ml.core.platform import find_secret
# Bootstrap Spark Session
spark = SparkSession.builder.getOrCreate()
Sekarang, mari kita baca ANOMALY_API_KEY variabel lingkungan dan BLOB_CONNECTION_STRING atur containerName variabel dan location .
# An Anomaly Dectector subscription key
anomalyKey = find_secret("anomaly-api-key") # use your own anomaly api key
# Your storage account name
storageName = "anomalydetectiontest" # use your own storage account name
# A connection string to your blob storage account
storageKey = find_secret("madtest-storage-key") # use your own storage key
# A place to save intermediate MVAD results
intermediateSaveDir = (
"wasbs://madtest@anomalydetectiontest.blob.core.windows.net/intermediateData"
)
# The location of the anomaly detector resource that you created
location = "westus2"
Pertama, kita terhubung ke akun penyimpanan kita sehingga detektor anomali dapat menyimpan hasil perantara di sana:
spark.sparkContext._jsc.hadoopConfiguration().set(
f"fs.azure.account.key.{storageName}.blob.core.windows.net", storageKey
)
Mari kita impor semua modul yang diperlukan.
import numpy as np
import pandas as pd
import pyspark
from pyspark.sql.functions import col
from pyspark.sql.functions import lit
from pyspark.sql.types import DoubleType
import matplotlib.pyplot as plt
import synapse.ml
from synapse.ml.cognitive import *
Sekarang, mari kita baca data sampel kita ke dalam Spark DataFrame.
df = (
spark.read.format("csv")
.option("header", "true")
.load("wasbs://publicwasb@mmlspark.blob.core.windows.net/MVAD/sample.csv")
)
df = (
df.withColumn("sensor_1", col("sensor_1").cast(DoubleType()))
.withColumn("sensor_2", col("sensor_2").cast(DoubleType()))
.withColumn("sensor_3", col("sensor_3").cast(DoubleType()))
)
# Let's inspect the dataframe:
df.show(5)
Kita sekarang dapat membuat estimator objek, yang digunakan untuk melatih model kita. Kami menentukan waktu mulai dan berakhir untuk data pelatihan. Kami juga menentukan kolom input yang akan digunakan, dan nama kolom yang berisi tanda waktu. Terakhir, kami menentukan jumlah titik data yang akan digunakan di jendela geser deteksi anomali, dan kami mengatur string koneksi ke Akun Azure Blob Storage.
trainingStartTime = "2020-06-01T12:00:00Z"
trainingEndTime = "2020-07-02T17:55:00Z"
timestampColumn = "timestamp"
inputColumns = ["sensor_1", "sensor_2", "sensor_3"]
estimator = (
FitMultivariateAnomaly()
.setSubscriptionKey(anomalyKey)
.setLocation(location)
.setStartTime(trainingStartTime)
.setEndTime(trainingEndTime)
.setIntermediateSaveDir(intermediateSaveDir)
.setTimestampCol(timestampColumn)
.setInputCols(inputColumns)
.setSlidingWindow(200)
)
Sekarang setelah kita membuat estimator, mari kita paskan dengan data:
model = estimator.fit(df)
```parameter
Once the training is done, we can now use the model for inference. The code in the next cell specifies the start and end times for the data we would like to detect the anomalies in.
```python
inferenceStartTime = "2020-07-02T18:00:00Z"
inferenceEndTime = "2020-07-06T05:15:00Z"
result = (
model.setStartTime(inferenceStartTime)
.setEndTime(inferenceEndTime)
.setOutputCol("results")
.setErrorCol("errors")
.setInputCols(inputColumns)
.setTimestampCol(timestampColumn)
.transform(df)
)
result.show(5)
Ketika kita memanggil .show(5) di sel sebelumnya, itu menunjukkan kepada kita lima baris pertama dalam dataframe. Hasilnya semua null karena tidak berada di dalam jendela inferensi.
Untuk menampilkan hasil hanya untuk data yang disimpulkan, mari kita pilih kolom yang kita butuhkan. Kita kemudian dapat mengurutkan baris dalam dataframe dengan urutan naik, dan memfilter hasilnya untuk hanya menampilkan baris yang berada dalam rentang jendela inferensi. Dalam kasus inferenceEndTime kami sama dengan baris terakhir dalam dataframe, sehingga dapat mengabaikannya.
Terakhir, untuk dapat memplot hasil dengan lebih baik, mari kita konversi dataframe Spark menjadi dataframe Pandas.
rdf = (
result.select(
"timestamp",
*inputColumns,
"results.contributors",
"results.isAnomaly",
"results.severity"
)
.orderBy("timestamp", ascending=True)
.filter(col("timestamp") >= lit(inferenceStartTime))
.toPandas()
)
rdf
contributors Format kolom yang menyimpan skor kontribusi dari setiap sensor ke anomali yang terdeteksi. Sel berikutnya memformat data ini, dan membagi skor kontribusi setiap sensor ke dalam kolomnya sendiri.
def parse(x):
if type(x) is list:
return dict([item[::-1] for item in x])
else:
return {"series_0": 0, "series_1": 0, "series_2": 0}
rdf["contributors"] = rdf["contributors"].apply(parse)
rdf = pd.concat(
[rdf.drop(["contributors"], axis=1), pd.json_normalize(rdf["contributors"])], axis=1
)
rdf
Bagus! Kita sekarang memiliki skor kontribusi sensor 1, 2, dan 3 di series_0kolom , series_1, dan series_2 masing-masing.
Jalankan sel berikutnya untuk memplot hasilnya. Parameter minSeverity menentukan tingkat keparahan minimum anomali yang akan diplot.
minSeverity = 0.1
####### Main Figure #######
plt.figure(figsize=(23, 8))
plt.plot(
rdf["timestamp"],
rdf["sensor_1"],
color="tab:orange",
linestyle="solid",
linewidth=2,
label="sensor_1",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_2"],
color="tab:green",
linestyle="solid",
linewidth=2,
label="sensor_2",
)
plt.plot(
rdf["timestamp"],
rdf["sensor_3"],
color="tab:blue",
linestyle="solid",
linewidth=2,
label="sensor_3",
)
plt.grid(axis="y")
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.legend()
anoms = list(rdf["severity"] >= minSeverity)
_, _, ymin, ymax = plt.axis()
plt.vlines(np.where(anoms), ymin=ymin, ymax=ymax, color="r", alpha=0.8)
plt.legend()
plt.title(
"A plot of the values from the three sensors with the detected anomalies highlighted in red."
)
plt.show()
####### Severity Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.plot(
rdf["timestamp"],
rdf["severity"],
color="black",
linestyle="solid",
linewidth=2,
label="Severity score",
)
plt.plot(
rdf["timestamp"],
[minSeverity] * len(rdf["severity"]),
color="red",
linestyle="dotted",
linewidth=1,
label="minSeverity",
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("Severity of the detected anomalies")
plt.show()
####### Contributors Figure #######
plt.figure(figsize=(23, 1))
plt.tick_params(axis="x", which="both", bottom=False, labelbottom=False)
plt.bar(
rdf["timestamp"], rdf["series_0"], width=2, color="tab:orange", label="sensor_1"
)
plt.bar(
rdf["timestamp"],
rdf["series_1"],
width=2,
color="tab:green",
label="sensor_2",
bottom=rdf["series_0"],
)
plt.bar(
rdf["timestamp"],
rdf["series_2"],
width=2,
color="tab:blue",
label="sensor_3",
bottom=rdf["series_0"] + rdf["series_1"],
)
plt.grid(axis="y")
plt.legend()
plt.ylim([0, 1])
plt.title("The contribution of each sensor to the detected anomaly")
plt.show()
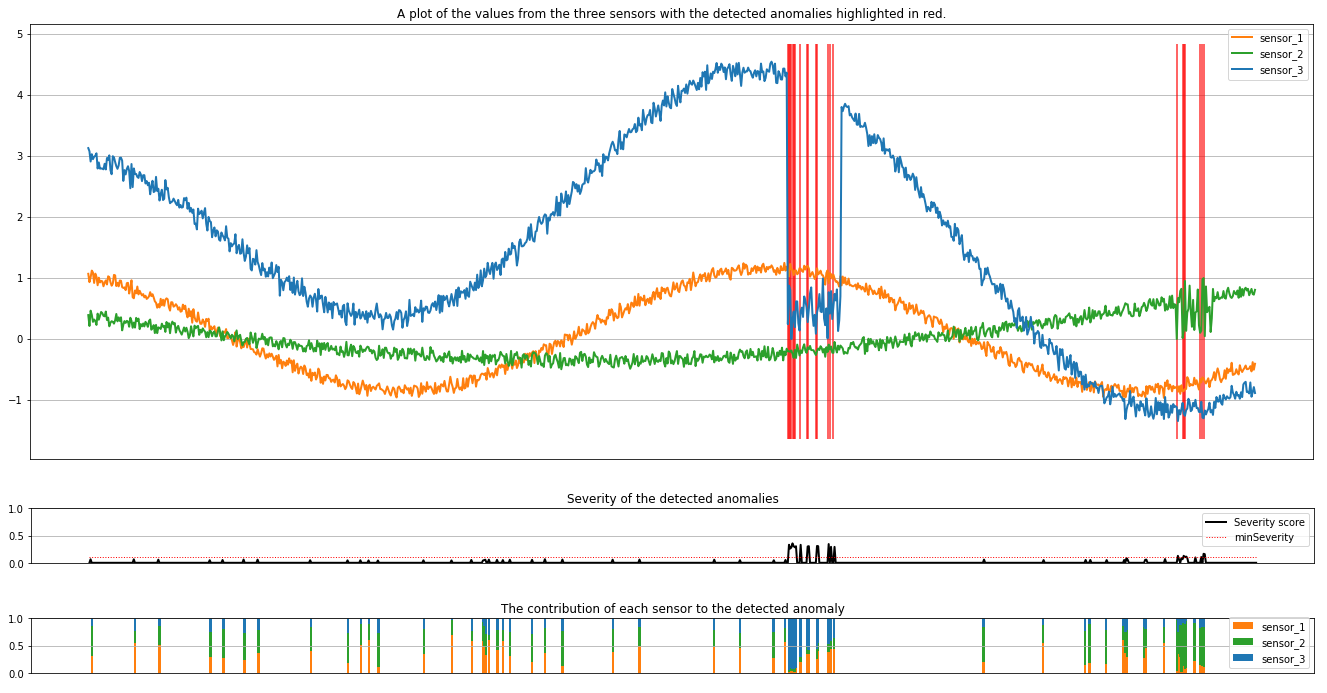
Plot menunjukkan data mentah dari sensor (di dalam jendela inferensi) berwarna oranye, hijau, dan biru. Garis vertikal merah pada gambar pertama menunjukkan anomali yang terdeteksi yang memiliki tingkat keparahan minSeveritylebih besar dari atau sama dengan .
Plot kedua menunjukkan skor tingkat keparahan semua anomali yang terdeteksi, dengan minSeverity ambang yang ditunjukkan dalam garis merah putus-putus.
Terakhir, plot terakhir menunjukkan kontribusi data dari setiap sensor ke anomali yang terdeteksi. Ini membantu kita mendiagnosis dan memahami penyebab paling mungkin dari setiap anomali.
Konten terkait
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk