Catatan
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba masuk atau mengubah direktori.
Akses ke halaman ini memerlukan otorisasi. Anda dapat mencoba mengubah direktori.
Penting
Terjemahan non-bahasa Inggris disediakan hanya untuk kenyamanan. Silakan lihat EN-US versi dokumen ini untuk versi pengikatan.
Apa itu catatan transparansi?
Sistem AI tidak hanya menangani teknologi, tetapi juga orang-orang yang akan menggunakannya, orang-orang yang akan terpengaruh olehnya, dan lingkungan tempat AI disebarkan. Menciptakan sistem yang sesuai dengan tujuan yang dimaksudkan membutuhkan pemahaman tentang cara kerja teknologi, kemampuan dan batasannya, serta cara mencapai performa terbaik.
Microsoft menyediakan catatan transparansi untuk membantu Anda memahami cara kerja teknologi AI kami. Termasuk pilihan yang dapat diambil pemilik sistem yang memengaruhi performa dan perilaku sistem, dan pentingnya memikirkan keseluruhan sistem, termasuk teknologi, manusia, dan lingkungan. Anda dapat menggunakan catatan transparansi saat mengembangkan atau menggunakan sistem Anda sendiri, atau membagikannya kepada orang yang akan menggunakan atau terpengaruh oleh sistem Anda.
Catatan transparansi adalah bagian dari upaya yang lebih luas di Microsoft untuk mempraktikkan prinsip AI kami. Untuk mengetahui selengkapnya, lihat Prinsip AI Microsoft.
Dasar-dasar Kecerdasan Dokumen
Pendahuluan
Kecerdasan Dokumen diakses melalui sekumpulan API dan memungkinkan pengembang untuk dengan mudah mengekstrak teks, struktur, dan bidang dari dokumen mereka. Ini terdiri dari fitur-fitur seperti:
- Baca untuk ekstraksi teks.
- Tata Letak dan Dokumen Umum untuk wawasan struktural serta nilai umum dan entitas seperti nama, tempat, dan benda.
- Model bawaan untuk jenis dokumen tertentu seperti faktur, tanda terima, kartu nama, W2, dan ID.
- Model kustom untuk membangun model khusus untuk jenis dokumen Anda.
Kecerdasan Dokumen mendukung satu atau beberapa bahasa dan lokal untuk setiap fitur, seperti yang tercantum dalam artikel Bahasa yang didukung .
Istilah kunci
| Istilah | Definisi |
|---|---|
| Bacalah | Fitur ini mengekstrak baris teks, kata, dan lokasinya dari gambar dan dokumen, bersama dengan informasi lain seperti bahasa yang terdeteksi. |
| Tata letak | Fitur ini mengekstrak teks, tanda pilihan, dan struktur tabel (nomor baris dan kolom yang terkait dengan teks). Lihat Tata Letak Kecerdasan Dokumen. |
| Dokumen Umum | Analisis dokumen dan kaitkan nilai ke kunci dan entri ke tabel yang ditemukannya. Untuk informasi lebih lanjut, lihat Dokumen Umum Kecerdasan Dokumen. |
| Model bawaan | Model bawaan adalah model khusus dokumen untuk jenis formulir unik. Model ini tidak memerlukan pelatihan kustom sebelum digunakan. Misalnya, model faktur bawaan mengekstrak bidang kunci dari faktur. Untuk informasi selengkapnya, lihat Model faktur bawaan Kecerdasan Dokumen. |
| Model khusus | Kecerdasan Dokumen memungkinkan Anda melatih model kustom yang disesuaikan dengan formulir dan dokumen Anda. Model ini mengekstrak teks, pasangan kunci-nilai, tanda pilihan, dan data tabel. Model kustom dapat ditingkatkan dengan umpan balik manusia dengan menerapkan tinjauan manusia, memperbarui label, dan melatih kembali model dengan menggunakan API. |
| Nilai Kepercayaan | Semua operasi Dapatkan Hasil Analisis mengembalikan nilai keyakinan dalam rentang antara 0 dan 1 untuk semua kata yang diekstrak dan pemetaan nilai kunci. Nilai ini mewakili perkiraan layanan tentang berapa kali ia mengekstrak kata dengan benar dari 100 atau memetakan pasangan kunci-nilai dengan benar. Misalnya, kata yang diperkirakan diekstraksi dengan benar 82% waktu menghasilkan nilai keyakinan 0,82. |
| Fitur add-on | Kecerdasan Dokumen menawarkan serangkaian fitur add-on untuk memperluas hasil agar menyertakan lebih banyak elemen dari dokumen Anda. Beberapa fitur add-on dikenakan biaya tambahan dan dapat diaktifkan dan dinonaktifkan tergantung pada skenario ekstraksi dokumen. Saat ini kami menawarkan kemampuan ekstraksi resolusi tinggi, rumus, styleFont, barcode, bahasa, keyValuePairs, dan queryFields. Untuk informasi selengkapnya, lihat Fitur Tambahan untuk Kecerdasan Dokumen. |
Kemampuan
Perilaku sistem
Azure AI Document Intelligence adalah layanan Azure AI berbasis cloud yang dibangun dengan menggunakan pengenalan karakter optik (OCR), Analitik Teks, dan Teks Kustom dari layanan Azure AI. Model kustom saat ini menggunakan model GPT-3.5 layanan Azure OpenAI. OCR digunakan untuk mengekstrak typeface dan dokumen teks tulisan tangan. Kecerdasan Dokumen menggunakan OCR untuk mendeteksi dan mengekstrak informasi dari formulir dan dokumen yang didukung oleh AI untuk memberikan lebih banyak struktur dan informasi untuk ekstraksi teks.
Kasus penggunaan
Penggunaan yang dimaksudkan
Kecerdasan Dokumen mencakup fitur yang memungkinkan pelanggan dari berbagai industri mengekstrak data dari dokumen mereka. Skenario berikut adalah contoh kasus penggunaan yang sesuai:
Akun yang harus dibayarkan: Perusahaan dapat meningkatkan efisiensi petugas akun yang harus dibayar dengan menggunakan model faktur bawaan dan formulir kustom untuk mempercepat entri data faktur dengan melibatkan manusia. Model faktur bawaan dapat mengekstrak bidang kunci, seperti Total Faktur dan Alamat Pengiriman.
Pemrosesan formulir asuransi: Pelanggan dapat melatih model dengan menggunakan formulir kustom untuk mengekstrak pasangan kunci-nilai dalam bentuk asuransi dan kemudian memberi umpan data ke aliran bisnis mereka untuk meningkatkan akurasi dan efisiensi proses mereka. Untuk formulir unik mereka, pelanggan dapat membangun model mereka sendiri yang mengekstrak nilai kunci dengan menggunakan formulir kustom. Nilai yang diekstrak ini kemudian menjadi data yang dapat ditindaklanjuti untuk berbagai alur kerja dalam bisnis mereka.
Pemrosesan formulir bank: Bank dapat menggunakan model ID bawaan dan formulir kustom untuk mempercepat entri data untuk dokumentasi "kenali pelanggan Anda", atau untuk mempercepat entri data untuk paket hipotek. Jika bank mengharuskan pelanggan mereka untuk mengirimkan identifikasi pribadi sebagai bagian dari proses, model ID bawaan dapat mengekstrak nilai kunci, seperti Nama dan Nomor Dokumen, mempercepat waktu keseluruhan untuk entri data.
Otomatisasi proses robotik (RPA): Dengan menggunakan model ekstraksi kustom, pelanggan dapat mengekstrak data tertentu yang diperlukan dari berbagai jenis dokumen. Pasangan kunci-nilai yang diekstrak kemudian dapat dimasukkan ke dalam berbagai sistem seperti database, atau sistem CRM, melalui RPA, menggantikan entri data manual. Pelanggan juga dapat menggunakan model klasifikasi kustom untuk mengategorikan dokumen berdasarkan konten mereka dan mengajukannya di lokasi yang tepat. Dengan demikian, sekumpulan data terorganisir yang diekstrak dari model kustom dapat menjadi langkah pertama yang penting untuk mendokumentasikan skenario RPA untuk bisnis yang menangani dokumen dalam volume besar secara teratur.
Pertimbangan saat memilih kasus penggunaan lainnya
Pertimbangkan faktor-faktor berikut saat Anda memilih kasus penggunaan:
Pertimbangkan untuk menerapkan tinjauan manusia dengan cermat ketika data atau skenario sensitif terlibat: Penting untuk menyertakan manusia dalam proses untuk tinjauan manual saat Anda berhadapan dengan skenario dengan risiko tinggi (misalnya memengaruhi hak penting seseorang) atau data sensitif. Model pembelajaran mesin tidak sempurna. Pertimbangkan dengan cermat kapan harus menyertakan langkah tinjauan manual untuk alur kerja tertentu. Misalnya, verifikasi identitas di pelabuhan masuk seperti bandara harus mencakup pengawasan manusia.
Pertimbangkan dengan cermat saat menggunakan untuk pemberian atau penolakan tunjangan: Kecerdasan dokumen tidak dirancang atau dievaluasi untuk pemberian atau penolakan tunjangan, dan penggunaan dalam skenario ini mungkin memiliki konsekuensi yang tidak diinginkan. Skenario ini meliputi:
- Asuransi medis: Ini akan mencakup penggunaan catatan kesehatan dan resep medis sebagai dasar keputusan atas imbalan atau penolakan asuransi.
- Persetujuan pinjaman: Ini termasuk pengajuan untuk pinjaman baru atau pembiayaan kembali yang ada.
Pertimbangkan dengan cermat jenis dan lokal dokumen yang didukung: Model bawaan memiliki daftar bidang yang didukung yang telah ditentukan sebelumnya dan dibuat untuk lokal tertentu. Pastikan untuk memeriksa dengan cermat lokal dan jenis dokumen yang didukung secara resmi untuk memastikan hasil terbaik. Misalnya, lihat Templat tanda terima bawaan Document Intelligence.
-
Pertimbangan hukum dan peraturan: Organisasi perlu mengevaluasi potensi kewajiban hukum dan peraturan tertentu saat menggunakan layanan dan solusi AI apa pun, yang mungkin tidak sesuai untuk digunakan di setiap industri atau skenario. Selain itu, layanan atau solusi AI tidak dirancang untuk dan tidak dapat digunakan dengan cara yang dilarang dalam ketentuan layanan yang berlaku dan kode etik yang relevan.
Keterbatasan
Batasan teknis, faktor operasional, dan rentang
Batasan model bawaan
Model bawaan Kecerdasan Dokumen digunakan untuk memproses jenis dokumen tertentu dan telah dilatih sebelumnya pada ribuan formulir. Kemampuan ini memungkinkan pengembang untuk memulai dan mendapatkan hasil dalam hitungan menit, tanpa memerlukan data pelatihan atau pelabelan. Untuk model bawaan, penting untuk mencatat daftar persyaratan input, jenis dokumen yang didukung, dan lokal untuk setiap model bawaan untuk hasil yang optimal. Misalnya, lihat persyaratan input Faktur bawaan.
Batasan model kustom
Model kustom Kecerdasan Dokumen dilatih menggunakan data pelatihan Anda sendiri agar model dapat beradaptasi dengan formulir dan dokumen spesifik Anda. Kemampuan ini sangat bergantung pada cara Anda memberi label data, serta jenis himpunan data pelatihan yang Anda berikan. Untuk model kustom, penting untuk dicatat batas ukuran himpunan data pelatihan, batas halaman dokumen, dan jumlah sampel minimum yang diperlukan untuk setiap jenis dokumen. Saat ini, model kustom menggunakan model GPT-3.5 dari Azure OpenAI Service. Informasi lebih lanjut tentang model Azure OpenAI dapat ditemukan di Catatan Transparansi Azure OpenAI.
Halaman Batas layanan berisi informasi selengkapnya tentang kuota dan batas layanan Azure AI Document Intelligence untuk semua tingkat harga. Ini juga berisi batasan model dan praktik terbaik untuk penggunaan model dan menghindari pembatasan permintaan.
Dukungan fitur
Lihat tabel Fitur analisis untuk daftar berbagai operasi yang dapat dilakukan model Kecerdasan Dokumen.
Performa sistem
Akurasi
Teks terdiri dari baris dan kata-kata di tingkat dasar dan entitas seperti nama, harga, jumlah, nama perusahaan, dan produk di tingkat pemahaman dokumen.
Akurasi tingkat kata
Ukuran akurasi yang populer untuk OCR adalah tingkat kesalahan kata (WER), atau berapa banyak kata yang salah dihasilkan dalam hasil yang diekstraksi. Semakin rendah WER, semakin tinggi akurasinya.
WER didefinisikan sebagai:
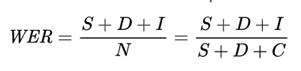
Lokasi:
| Istilah | Definisi | Contoh |
|---|---|---|
| S | Jumlah kata yang salah ("diganti") dalam output. | "Velvet" akan diekstraksi menjadi "Veivet" karena "l" terdeteksi secara salah sebagai "i." |
| D | Jumlah kata yang hilang ("dihapus") dalam output. | Untuk teks "Nama Perusahaan: Microsoft," Microsoft tidak diekstrak karena ditulis tangan atau sulit dibaca. |
| Saya | Jumlah kata yang tidak terdapat ("disisipkan") dalam output. | "Departemen" disegmentasikan secara salah menjadi tiga kata sebagai "Dep artm ent." Dalam hal ini, hasilnya adalah satu kata yang dihapus dan tiga kata yang dimasukkan. |
| C | Jumlah kata yang diekstrak dengan benar dalam output. | Semua kata yang telah diekstrak dengan benar. |
| N | Jumlah total kata dalam referensi (N=S+D+C) dengan mengesampingkan I karena kata-kata tersebut hilang dari referensi asli dan salah diprediksi ada. | Pertimbangkan gambar dengan kalimat, "Microsoft, yang bermarkas di Redmond, WA mengumumkan produk baru yang disebut Velvet untuk departemen keuangan." Asumsikan output OCR adalah " , yang bermarkas di Redmond, WA mengumumkan produk baru yang disebut Veivet untuk dep artm ents keuangan." Dalam hal ini, S (Velvet) = 1, D (Microsoft) = 1, I (dep artm ents) = 3, C (11), dan N = S + D + C = 13. Oleh karena itu, WER = (S + D + I) / N = 5 / 13 = 0,38 atau 38% (dari 100). |
Menggunakan nilai keyakinan
Seperti yang dibahas di bagian sebelumnya, layanan memberikan nilai keyakinan untuk setiap kata yang diprediksi dalam output OCR. Pelanggan menggunakan nilai ini untuk mengkalibrasi ambang batas khusus pada konten dan skenario mereka sehingga dapat merutekan konten untuk pemrosesan otomatis atau meneruskan ke proses manusia dalam loop. Pengukuran yang dihasilkan menentukan akurasi khusus skenario.
Implikasi performa sistem OCR dapat bervariasi menurut skenario di mana teknologi OCR diterapkan. Kami akan meninjau beberapa contoh untuk mengilustrasikan konsep tersebut.
- Kepatuhan perangkat medis: Dalam contoh pertama ini, perusahaan farmasi multinasial dengan beragam portofolio produk paten, perangkat, obat-obatan, dan perawatan perlu menganalisis informasi label produk yang sesuai FDA dan dokumen hasil analisis. Perusahaan mungkin lebih memilih ambang batas keyakinan yang rendah untuk menerapkan human-in-the-loop karena biaya data yang salah diekstraksi dapat berdampak signifikan bagi konsumen dan denda dari lembaga pengatur.
- Pemrosesan gambar dan dokumen: Dalam contoh kedua ini, perusahaan melakukan pemrosesan aplikasi asuransi dan pinjaman. Pelanggan yang menggunakan OCR mungkin lebih memilih ambang batas nilai keyakinan menengah karena ekstraksi teks otomatis dikombinasikan hilir dengan input informasi lain dan langkah-langkah human-in-the-loop untuk tinjauan holistik aplikasi.
- Moderasi konten: Untuk volume besar data katalog e-niaga yang diimpor dari pemasok dalam skala besar, pelanggan mungkin lebih memilih ambang nilai keyakinan tinggi dengan akurasi tinggi karena bahkan persentase kecil konten yang ditandai dengan salah dapat menghasilkan banyak overhead untuk tim ulasan manusia dan pemasok mereka.
Akurasi tingkat dokumen dan entitas
Pada tingkat dokumen, misalnya, dalam kasus faktur atau tanda terima, kesalahan hanya satu karakter di seluruh dokumen mungkin dinilai tidak signifikan. Tetapi jika kesalahan tersebut ada dalam teks yang mewakili jumlah berbayar, seluruh faktur atau tanda terima mungkin ditandai sebagai salah.
Metrik lain yang berguna adalah tingkat kesalahan entitas (EER). Ini adalah persentase entitas yang salah diekstraksi, seperti nama, harga, jumlah, dan nomor telepon, dari jumlah total entitas yang sesuai dalam satu atau beberapa dokumen. Misalnya, untuk total 30 kata yang mewakili 10 nama, 2 kata yang salah dari 30 sama dengan 0,06 (6%) WER. Tetapi jika itu menghasilkan 2 nama dari 10 yang salah, tingkat kesalahan Nama (Nama EER) adalah 0,20 (20%), yang jauh lebih tinggi dari WER.
Mengukur WER dan EER adalah latihan yang berguna untuk mendapatkan perspektif penuh tentang akurasi pemahaman dokumen.
Praktik terbaik untuk meningkatkan performa sistem
Pertimbangkan poin-poin berikut tentang batasan dan performa:
Layanan ini mendukung gambar dan dokumen. Untuk batas yang diizinkan untuk jumlah halaman, ukuran gambar, ukuran kertas, dan ukuran file, lihat Apa itu Kecerdasan Dokumen?.
- Banyak variabel dapat memengaruhi akurasi hasil OCR di mana Kecerdasan Dokumen bergantung. Variabel ini termasuk kualitas pemindaian dokumen, resolusi, kontras, kondisi cahaya, rotasi, dan atribut teks seperti ukuran, warna, dan kepadatan. Misalnya, kami menyarankan agar gambar setidaknya 50 x 50 piksel. Lihat spesifikasi produk dan uji layanan pada dokumen Anda untuk memvalidasi kecocokan situasi Anda.
- Perhatikan batasan setiap layanan sehubungan dengan input, bahasa, dan lokal yang didukung saat ini, dan jenis dokumen. Misalnya, lihat Bahasa tata letak yang didukung.
Praktik terbaik untuk meningkatkan kualitas model kustom
Saat Anda menggunakan model kustom Kecerdasan Dokumen, Anda menyediakan data pelatihan Anda sendiri agar model dapat menyesuaikan dengan formulir dan dokumen spesifik Anda. Daftar berikut menggunakan jenis model formulir kustom untuk berbagi tips pemula untuk meningkatkan kualitas model Anda.
- Untuk formulir yang diisi, gunakan contoh yang semua bidangnya telah terisi.
- Gunakan formulir dengan nilai nyata yang Anda harapkan untuk setiap bidang.
- Jika gambar formulir Anda berkualitas lebih rendah, gunakan himpunan data yang lebih besar (misalnya 10-15 gambar).
Untuk panduan lengkap dan persyaratan input, lihat Membangun himpunan data pelatihan untuk model kustom.
Evaluasi Kecerdasan Dokumen
Kinerja Kecerdasan Dokumen akan bervariasi tergantung pada solusi di dunia nyata yang diterapkannya. Untuk memastikan performa optimal dalam skenario mereka, pelanggan harus melakukan evaluasi mereka sendiri. Layanan ini memberikan nilai keyakinan dalam rentang antara 0 dan 1 untuk setiap pemetaan kata dan nilai kunci yang diekstrak. Pelanggan harus menjalankan uji coba atau bukti konsep yang mewakili kasus penggunaan mereka untuk memahami rentang tingkat kepercayaan dan kualitas ekstraksi dari Intelijen Dokumen. Mereka kemudian dapat memperkirakan ambang batas nilai keyakinan untuk hasil yang akan dikirim untuk pemrosesan langsung (STP) atau ditinjau oleh manusia. Misalnya, pelanggan dapat mengirimkan hasil dengan nilai keyakinan yang lebih besar dari atau sama dengan .80 untuk pemrosesan langsung dan menerapkan tinjauan manusia ke hasil dengan nilai keyakinan kurang dari .80.
Mengevaluasi dan mengintegrasikan Kecerdasan Dokumen untuk penggunaan Anda
Microsoft ingin membantu Anda mengembangkan dan menyebarkan solusi yang menggunakan Kecerdasan Dokumen secara bertanggung jawab. Kami mengambil pendekatan berprinsip untuk menjunjung tinggi badan pribadi dan martabat dengan mempertimbangkan kewajaran, keandalan dan keamanan sistem AI, privasi dan keamanan, inklusif, transparansi, dan akuntabilitas manusia. Pertimbangan ini sejalan dengan komitmen kami untuk mengembangkan Responsible AI.
Saat Anda bersiap-siap untuk menyebarkan produk atau fitur yang didukung AI, aktivitas berikut ini membantu menyiapkan Anda agar sukses:
Pahami apa yang dapat dilakukannya: Menilai sepenuhnya potensi Kecerdasan Dokumen untuk memahami kemampuan dan batasannya. Pahami bagaimana performanya dalam skenario dan konteks tertentu Anda. Misalnya, jika Anda menggunakan model faktur bawaan, uji dengan faktur dunia nyata dari proses bisnis Anda untuk menganalisis dan membuat tolok ukur hasil terhadap metrik proses yang ada.
Hormati hak privasi individu: Hanya kumpulkan data dan informasi dari individu untuk tujuan yang sah dan dapat dibenar. Hanya gunakan data dan informasi yang anda miliki persetujuan untuk digunakan untuk tujuan ini.
Tinjauan hukum: Dapatkan tinjauan hukum yang sesuai, terutama jika Anda berencana untuk menggunakannya dalam aplikasi sensitif atau berisiko tinggi. Pahami batasan apa yang mungkin perlu Anda kerjakan, dan tanggung jawab Anda untuk menyelesaikan masalah apa pun yang mungkin muncul di masa mendatang.
Human-in-the-loop: Pertahankan keterlibatan manusia, dan sertakan pengawasan manusia sebagai pola konsisten untuk dieksplorasi. Ini berarti memastikan pengawasan manusia yang konstan terhadap produk atau fitur yang didukung AI dan untuk mempertahankan peran manusia dalam pengambilan keputusan. Pastikan Anda memiliki kemampuan untuk intervensi manusia secara real-time untuk solusi guna mencegah bahaya. Keterlibatan manusia memungkinkan Anda mengelola situasi saat Inteligensi Dokumen tidak berfungsi sesuai kebutuhan.
Keamanan: Pastikan solusi Anda aman dan memiliki kontrol yang memadai untuk mempertahankan integritas konten Anda dan mencegah akses yang tidak sah.
Rekomendasi untuk menjaga privasi
Pendekatan privasi yang berhasil memberdayakan individu dengan informasi dan memberikan kontrol dan perlindungan untuk menjaga privasi mereka.
- Jika Kecerdasan Dokumen adalah bagian dari solusi yang dirancang untuk menggabungkan informasi identitas pribadi (PII), pikirkan dengan cermat apakah dan cara merekam data tersebut. Ikuti peraturan nasional dan regional yang berlaku tentang privasi dan data sensitif.
- Manajer privasi harus mempertimbangkan kebijakan retensi pada teks dan nilai yang diekstraksi, dan dokumen atau gambar yang mendasari dokumen tersebut. Kebijakan retensi akan dikaitkan dengan penggunaan yang dimaksudkan dari setiap aplikasi.
Pelajari selengkapnya tentang AI yang bertanggung jawab
- Prinsip Microsoft AI
- Sumber daya AI yang bertanggung jawab Microsoft
- Kursus Microsoft Azure Learning tentang AI yang bertanggung jawab