Indeks Penyimpan Kolom - Panduan pemuatan data
Berlaku untuk:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics Analytics
Azure Synapse Analytics Analytics![]() Platform System (PDW)
Platform System (PDW)
Opsi dan rekomendasi untuk memuat data ke dalam indeks penyimpan kolom dengan menggunakan metode pemuatan massal dan penyisipan massal SQL standar. Memuat data ke dalam indeks penyimpan kolom adalah bagian penting dari proses pergudangan data apa pun karena memindahkan data ke dalam indeks sebagai persiapan untuk analitik.
Baru mengindeks penyimpan kolom? Lihat Indeks penyimpan kolom - gambaran umum dan Arsitektur Indeks Penyimpan Kolom.
Apa itu pemuatan massal?
Pemuatan massal mengacu pada cara sejumlah besar baris ditambahkan ke penyimpanan data. Ini adalah cara paling berperforma untuk memindahkan data ke indeks penyimpan kolom karena beroperasi pada batch baris. Pemuatan massal mengisi grup baris hingga kapasitas maksimum dan memadatkannya langsung ke dalam penyimpanan kolom. Hanya baris di akhir beban yang tidak memenuhi minimal 102.400 baris per grup baris yang masuk ke deltastore.
Untuk melakukan pemuatan massal, Anda dapat menggunakan Utilitas bcp, Layanan Integrasi, atau memilih baris dari tabel penahapan.
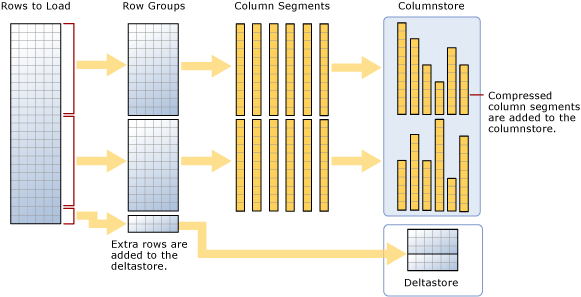
Seperti yang disarankan diagram, beban massal:
- Tidak mempertahankan data. Data disisipkan ke dalam grup baris dalam urutan diterimanya.
- Jika ukuran batch adalah >= 102400, baris langsung dimuat ke dalam grup baris terkompresi. Anda harus memilih ukuran >batch =102400 untuk impor massal yang efisien, karena Anda dapat menghindari pemindahan baris data ke grup baris delta sebelum baris akhirnya dipindahkan ke grup baris terkompresi oleh utas latar belakang, Penggerak Tuple (TM).
- Jika ukuran < batch 102.400 atau jika baris yang tersisa adalah < 102.400, baris dimuat ke dalam grup baris delta.
Catatan
Pada tabel rowstore dengan data indeks penyimpan kolom berkluster, SQL Server selalu menyisipkan data ke dalam tabel dasar. Data tidak pernah disisipkan langsung ke dalam indeks penyimpan kolom.
Pemuatan massal memiliki pengoptimalan performa bawaan ini:
Beban paralel: Anda dapat memiliki beberapa beban massal bersamaan (sisipan massal atau bcp ) yang masing-masing memuat file data terpisah. Tidak seperti pemuatan massal rowstore ke SQL Server, Anda tidak perlu menentukan
TABLOCKkarena setiap utas impor massal memuat data secara eksklusif ke dalam grup baris terpisah (grup baris terkompresi atau delta) dengan kunci eksklusif di atasnya.Pengurangan pengelogan: Data yang langsung dimuat ke dalam grup baris terkompresi, menyebabkan pengurangan ukuran log yang signifikan. Misalnya, jika data dikompresi 10x, log transaksi yang sesuai kira-kira 10x lebih kecil tanpa memerlukan tablock atau model pemulihan yang dicatat secara massal/Sederhana. Setiap data yang masuk ke grup baris delta sepenuhnya dicatat. Ini termasuk ukuran batch apa pun yang kurang dari 102.400 baris. Praktik terbaik adalah menggunakan batchsize >= 102400. Karena tidak ada TABLOCK yang diperlukan, Anda dapat memuat data secara paralel.
Pengelogan minimal: Anda bisa mendapatkan pengurangan lebih lanjut dalam pengelogan jika Anda mengikuti prasyarat untuk pengelogan minimal. Namun, tidak seperti memuat data ke dalam rowstore, TABLOCK mengarah ke kunci X pada tabel daripada kunci BU (Pembaruan Massal) dan oleh karena itu beban data paralel tidak dapat dilakukan. Untuk informasi selengkapnya tentang penguncian, lihat Mengunci dan membuat versi baris.
Pengoptimalan penguncian: Kunci X pada grup baris secara otomatis diperoleh saat memuat data ke dalam grup baris terkompresi. Namun, ketika memuat secara massal ke dalam grup baris delta, kunci X diperoleh di grup baris tetapi SQL Server masih mengunci HALAMAN/EXTENT karena kunci grup baris X bukan bagian dari penguncian hierarki.
Jika Anda memiliki indeks pohon B non-kluster pada indeks penyimpan kolom, tidak ada pengoptimalan penguncian atau pengelogan untuk indeks itu sendiri tetapi pengoptimalan pada indeks penyimpan kolom berkluster seperti yang dijelaskan sebelumnya berlaku.
Modifikasi data (sisipkan, hapus, perbarui) bukan operasi mode batch karena tidak paralel.
Merencanakan ukuran beban massal untuk meminimalkan grup baris delta
Indeks penyimpan kolom berkinerja terbaik ketika sebagian besar baris dikompresi ke dalam penyimpan kolom dan tidak duduk di grup baris delta. Yang terbaik adalah mengukur beban Anda sehingga baris langsung masuk ke penyimpan kolom dan melewati deltastore sebanyak mungkin.
Skenario ini menjelaskan kapan baris yang dimuat langsung masuk ke penyimpan kolom atau saat masuk ke deltastore. Dalam contoh, setiap grup baris dapat memiliki 102.400-1.048.576 baris per grup baris. Dalam praktiknya, ukuran maksimum grup baris bisa lebih kecil dari 1.048.576 baris ketika ada tekanan memori.
| Baris untuk dimuat secara massal | Baris ditambahkan ke grup baris terkompresi | Baris ditambahkan ke grup baris delta |
|---|---|---|
| 102.000 | 0 | 102.000 |
| 145,000 | 145,000 Ukuran grup baris: 145.000 |
0 |
| 1,048,577 | 1,048,576 Ukuran grup baris: 1.048.576. |
1 |
| 2,252,152 | 2,252,152 Ukuran grup baris: 1.048.576, 1.048.576, 155.000. |
0 |
Contoh berikut menunjukkan hasil pemuatan 1.048.577 baris ke dalam tabel. Hasilnya menunjukkan bahwa satu grup baris TERKOMPRESI di penyimpan kolom (sebagai segmen kolom terkompresi), dan 1 baris di deltastore.
SELECT object_id, index_id, partition_number, row_group_id, delta_store_hobt_id,
state, state_desc, total_rows, deleted_rows, size_in_bytes
FROM sys.dm_db_column_store_row_group_physical_stats;

Menggunakan tabel penahapan untuk meningkatkan performa
Jika Anda memuat data hanya untuk tahap sebelum menjalankan lebih banyak transformasi, memuat tabel ke tabel timbunan jauh lebih cepat daripada memuat data ke tabel penyimpan kolom berkluster. Selain itu, memuat data ke [tabel sementara][Sementara] juga akan memuat jauh lebih cepat daripada memuat tabel ke penyimpanan permanen.
Pola umum untuk beban data adalah memuat data ke dalam tabel penahapan, melakukan beberapa transformasi lalu memuatnya ke dalam tabel target menggunakan perintah berikut:
INSERT INTO [<columnstore index>]
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Perintah ini memuat data ke dalam indeks penyimpan kolom dengan cara yang sama dengan sisipan bcp atau massal tetapi dalam satu batch. Jika jumlah baris dalam tabel < penahapan 102400, baris dimuat ke dalam grup baris delta jika tidak, baris langsung dimuat ke dalam grup baris terkompresi. Salah satu batasan utamanya adalah bahwa operasi ini INSERT memiliki satu utas. Untuk memuat data secara paralel, Anda dapat membuat beberapa tabel penahapan atau masalah INSERT/SELECT dengan rentang baris yang tidak tumpang tindih dari tabel penahapan. Batasan ini hilang dengan SQL Server 2016 (13.x). Perintah berikut memuat data dari tabel penahapan secara paralel tetapi Anda harus menentukan TABLOCK. Anda mungkin menemukan kontradiktif ini dengan apa yang dikatakan sebelumnya dengan beban massal tetapi perbedaan utamanya adalah beban data paralel dari tabel penahapan dijalankan di bawah transaksi yang sama.
INSERT INTO [<columnstore index>] WITH (TABLOCK)
SELECT col1 /* include actual list of columns in place of col1*/
FROM [<Staging Table>]
Ada pengoptimalan berikut yang tersedia saat memuat ke dalam indeks penyimpan kolom berkluster dari tabel penahapan:
- Pengoptimalan Log: Pengurangan pengelogan saat data dimuat ke dalam grup baris terkompresi.
- Pengoptimalan Penguncian: Saat memuat data ke dalam grup baris terkompresi, kunci X pada grup baris diperoleh. Namun, dengan grup baris delta, kunci X diperoleh di grup baris tetapi SQL Server masih mengunci KUNCI PAGE/EXTENT karena kunci grup baris X bukan bagian dari hierarki penguncian.
Jika Anda memiliki satu atau beberapa indeks non-kluster, tidak ada pengoptimalan penguncian atau pengelogan untuk indeks itu sendiri, tetapi pengoptimalan pada indeks penyimpan kolom berkluster seperti yang dijelaskan sebelumnya masih ada.
Apa itu penyisipan trickle?
Penyisipan trickle mengacu pada cara masing-masing baris berpindah ke indeks penyimpan kolom. Penyisipan trickle menggunakan pernyataan INSERT INTO . Dengan penyisipan trik, semua baris masuk ke deltastore. Ini berguna untuk sejumlah kecil baris, tetapi tidak praktis untuk beban besar.
INSERT INTO [<table-name>] VALUES ('some value' /*replace with actual set of values*/)
Catatan
Utas bersamaan menggunakan INSERT INTO untuk menyisipkan nilai ke dalam indeks penyimpan kolom berkluster dapat menyisipkan baris ke dalam grup baris deltastore yang sama.
Setelah grup baris berisi 1.048.576 baris, grup baris delta yang ditandai ditutup tetapi masih tersedia untuk kueri dan operasi pembaruan/hapus, tetapi baris yang baru disisipkan masuk ke grup baris deltastore yang sudah ada atau yang baru dibuat. Ada utas latar belakang Tuple Mover (TM) yang memadatkan grup baris delta tertutup secara berkala setiap 5 menit atau lebih. Anda dapat secara eksplisit memanggil perintah berikut untuk memadatkan grup baris delta tertutup.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE
Jika Anda ingin memaksa grup baris delta ditutup dan dikompresi, Anda dapat menjalankan perintah berikut. Anda mungkin ingin menjalankan perintah ini jika Anda selesai memuat baris dan tidak mengharapkan baris baru. Dengan menutup dan mengompresi grup baris delta secara eksplisit, Anda dapat menyimpan penyimpanan lebih lanjut dan meningkatkan performa kueri analitik. Praktik terbaik adalah memanggil perintah ini jika Anda tidak mengharapkan baris baru disisipkan.
ALTER INDEX [<index-name>] on [<table-name>] REORGANIZE with (COMPRESS_ALL_ROW_GROUPS = ON)
Cara kerja pemuatan ke dalam tabel yang dipartisi
Untuk data yang dipartisi, SQL Server terlebih dahulu menetapkan setiap baris ke partisi, lalu melakukan operasi penyimpan kolom pada data dalam partisi. Setiap partisi memiliki grup barisnya sendiri dan setidaknya satu grup baris delta.
Langkah berikutnya
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk