Regresi
Model regresi dilatih untuk memprediksi nilai label numerik berdasarkan data pelatihan yang mencakup fitur dan label yang diketahui. Proses untuk melatih model regresi (atau memang, model pembelajaran mesin yang diawasi) melibatkan beberapa iterasi di mana Anda menggunakan algoritma yang sesuai (biasanya dengan beberapa pengaturan parameter) untuk melatih model, mengevaluasi performa prediktif model, dan memperbaiki model dengan mengulangi proses pelatihan dengan algoritma dan parameter yang berbeda sampai Anda mencapai tingkat akurasi prediktif yang dapat diterima.
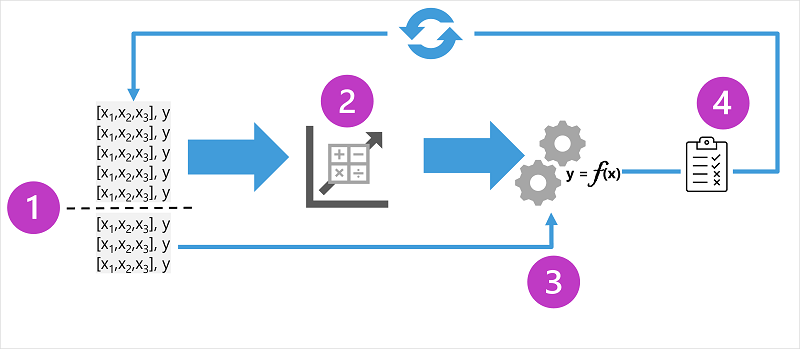
Diagram menunjukkan empat elemen utama dari proses pelatihan untuk model pembelajaran mesin yang diawasi:
- Pisahkan data pelatihan (secara acak) untuk membuat himpunan data untuk melatih model sambil menahan subset data yang akan Anda gunakan untuk memvalidasi model terlatih.
- Gunakan algoritma agar sesuai dengan data pelatihan dengan model. Dalam kasus model regresi, gunakan algoritma regresi seperti regresi linier.
- Gunakan data validasi yang Anda tahan untuk menguji model dengan memprediksi label untuk fitur.
- Bandingkan label aktual yang diketahui dalam himpunan data validasi dengan label yang diprediksi model. Kemudian agregat perbedaan antara nilai label yang diprediksi dan aktual untuk menghitung metrik yang menunjukkan seberapa akurat model yang diprediksi untuk data validasi.
Setelah setiap pelatihan, validasi, dan evaluasi iterasi, Anda dapat mengulangi proses dengan algoritma dan parameter yang berbeda hingga metrik evaluasi yang dapat diterima tercapai.
Contoh - regresi
Mari kita jelajahi regresi dengan contoh yang disederhanakan di mana kita akan melatih model untuk memprediksi label numerik (y) berdasarkan satu nilai fitur (x). Sebagian besar skenario nyata melibatkan beberapa nilai fitur, yang menambahkan beberapa kompleksitas; tetapi prinsipnya sama.
Sebagai contoh, mari kita tetap dengan skenario penjualan es krim yang kita bahas sebelumnya. Untuk fitur kami, kita akan mempertimbangkan suhu (mari kita asumsikan nilainya adalah suhu maksimum pada hari tertentu), dan label yang ingin kita latih model untuk memprediksi adalah jumlah es krim yang dijual hari itu. Kita akan mulai dengan beberapa data historis yang mencakup catatan suhu harian (x) dan penjualan es krim (y):
 |
 |
|---|---|
| Suhu (x) | Penjualan es krim (y) |
| 51 | 1 |
| 52 | 0 |
| 67 | 14 |
| 65 | 14 |
| 70 | 23 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 73 | 22 |
| 81 | 30 |
| 78 | 26 |
| 83 | 36 |
Melatih model regresi
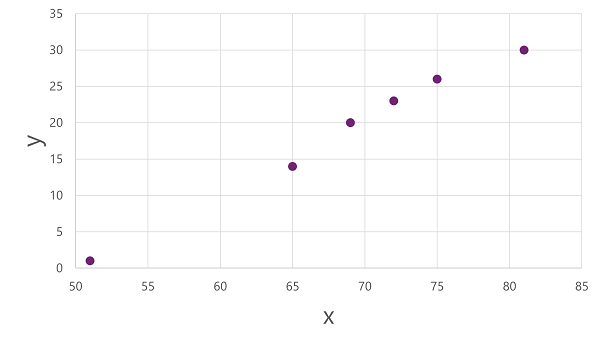
Kita akan mulai dengan membagi data dan menggunakan subsetnya untuk melatih model. Berikut himpunan data pelatihannya:
| Suhu (x) | Penjualan es krim (y) |
|---|---|
| 51 | 1 |
| 65 | 14 |
| 69 | 20 |
| 72 | 23 |
| 75 | 26 |
| 81 | 30 |
Untuk mendapatkan wawasan tentang bagaimana nilai x dan y ini mungkin berhubungan satu sama lain, kita dapat memplotnya sebagai koordinat di sepanjang dua sumbu, seperti ini:
Sekarang kami siap untuk menerapkan algoritma ke data pelatihan kami dan menyesuaikannya dengan fungsi yang menerapkan operasi ke x untuk menghitung y. Salah satu algoritma tersebut adalah regresi linier, yang bekerja dengan memperoleh fungsi yang menghasilkan garis lurus melalui persimpangan nilai x dan y sambil meminimalkan jarak rata-rata antara garis dan titik yang diplot, seperti ini:
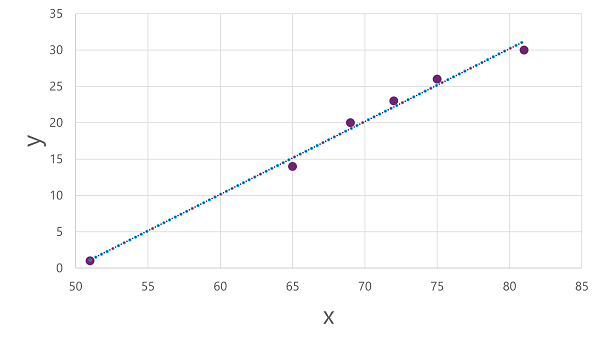
Garis adalah representasi visual fungsi di mana kelereng baris menjelaskan cara menghitung nilai y untuk nilai x tertentu. Garis mencegat sumbu x pada 50, jadi ketika x adalah 50, y adalah 0. Seperti yang Anda lihat dari penanda sumbu di plot, lereng garis sehingga setiap peningkatan 5 sepanjang sumbu x menghasilkan peningkatan 5 sumbu y; jadi ketika x adalah 55, y adalah 5; ketika x adalah 60, y adalah 10, dan sebagainya. Untuk menghitung nilai y untuk nilai x tertentu, fungsi hanya mengurangi 50; dengan kata lain, fungsi dapat diekspresikan seperti ini:
f(x) = x-50
Anda dapat menggunakan fungsi ini untuk memprediksi jumlah es krim yang dijual pada hari dengan suhu tertentu. Misalnya, prakiraan cuaca memberi tahu kita bahwa besok akan menjadi 77 derajat. Kita dapat menerapkan model kita untuk menghitung 77-50 dan memprediksi bahwa kita akan menjual 27 es krim besok.
Tapi seberapa akurat model kita?
Mengevaluasi model regresi
Untuk memvalidasi model dan mengevaluasi seberapa baik prediksinya, kami menahan beberapa data yang kami ketahui nilai label (y). Berikut data yang kami tahan:
| Suhu (x) | Penjualan es krim (y) |
|---|---|
| 52 | 0 |
| 67 | 14 |
| 70 | 23 |
| 73 | 22 |
| 78 | 26 |
| 83 | 36 |
Kita dapat menggunakan model untuk memprediksi label untuk setiap pengamatan dalam himpunan data ini berdasarkan nilai fitur (x) ; lalu membandingkan label yang diprediksi (ŷ) dengan nilai label aktual yang diketahui (y).
Menggunakan model yang kami latih sebelumnya, yang merangkum fungsi f(x) = x-50, menghasilkan prediksi berikut:
| Suhu (x) | Penjualan aktual (y) | Penjualan yang diprediksi (ŷ) |
|---|---|---|
| 52 | 0 | 2 |
| 67 | 14 | 17 |
| 70 | 23 | 20 |
| 73 | 22 | 23 |
| 78 | 26 | 28 |
| 83 | 36 | 33 |
Kita dapat memplot label yang diprediksi dan aktual terhadap nilai fitur seperti ini:
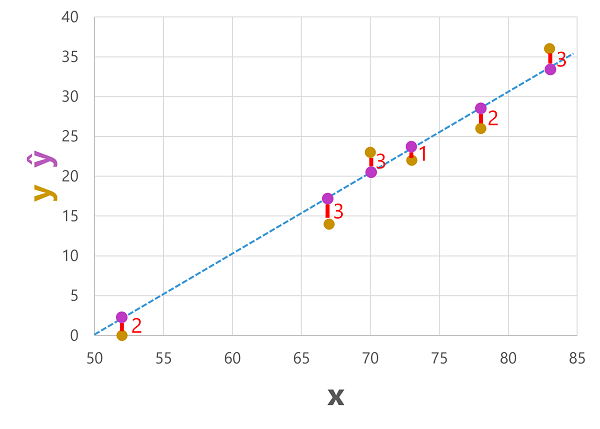
Label yang diprediksi dihitung oleh model sehingga berada di baris fungsi, tetapi ada beberapa varians antara nilai ŷ yang dihitung oleh fungsi dan nilai y aktual dari himpunan data validasi; yang ditunjukkan pada plot sebagai garis antara nilai ŷ dan y yang menunjukkan seberapa jauh dari prediksi dari nilai aktual.
Metrik evaluasi regresi
Berdasarkan perbedaan antara nilai yang diprediksi dan aktual, Anda dapat menghitung beberapa metrik umum yang digunakan untuk mengevaluasi model regresi.
Mean Absolute Error (MAE)
Varians dalam contoh ini menunjukkan oleh berapa banyak es krim setiap prediksi salah. Tidak masalah apakah prediksi berakhir atau di bawah nilai aktual (jadi misalnya, -3 dan +3 keduanya menunjukkan varian 3). Metrik ini dikenal sebagai kesalahan absolut untuk setiap prediksi, dan dapat diringkas untuk seluruh validasi yang ditetapkan sebagai kesalahan absolut rata-rata (MAE).
Dalam contoh es krim, rata-rata (rata-rata) dari kesalahan absolut (2, 3, 3, 1, 2, dan 3) adalah 2,33.
Mean Squared Error (MSE)
Metrik kesalahan absolut rata-rata memperhitungkan semua perbedaan antara label yang diprediksi dan aktual secara merata. Namun, mungkin lebih diinginkan untuk memiliki model yang secara konsisten salah dengan jumlah kecil dari yang membuat lebih sedikit, tetapi kesalahan yang lebih besar. Salah satu cara untuk menghasilkan metrik yang "memperkuat" kesalahan yang lebih besar dengan mencukupi kesalahan individu dan menghitung rata-rata nilai kuadrat. Metrik ini dikenal sebagai kesalahan kuadrat rata-rata (MSE).
Dalam contoh es krim kami, rata-rata nilai absolut kuadrat (yaitu 4, 9, 9, 1, 4, dan 9) adalah 6.
Root Mean Squared Error (RMSE)
Kesalahan kuadrat rata-rata membantu memperhitungkan besarnya kesalahan, tetapi karena kuadrat nilai kesalahan, metrik yang dihasilkan tidak lagi mewakili kuantitas yang diukur oleh label. Dengan kata lain, kita dapat mengatakan bahwa MSE model kita adalah 6, tetapi itu tidak mengukur akurasinya dalam hal jumlah es krim yang salah diprediksi; 6 hanyalah skor numerik yang menunjukkan tingkat kesalahan dalam prediksi validasi.
Jika kita ingin mengukur kesalahan dalam hal jumlah es krim, kita perlu menghitung akar kuadrat MSE; yang menghasilkan metrik yang disebut, tidak mengherankan, Root Mean Squared Error. Dalam hal ini √6, yaitu 2,45 (es krim).
Koefisien penentuan (R2)
Semua metrik sejauh ini membandingkan perbedaan antara nilai yang diprediksi dan aktual untuk mengevaluasi model. Namun, pada kenyataannya, ada beberapa variansi acak alami dalam penjualan harian es krim yang dihitungkan model. Dalam model regresi linier, algoritma pelatihan cocok dengan garis lurus yang meminimalkan varians rata-rata antara fungsi dan nilai label yang diketahui. Koefisien penentuan (lebih umum disebut sebagai R2 atau R-Squared) adalah metrik yang mengukur proporsi varians dalam hasil validasi yang dapat dijelaskan oleh model, dibandingkan dengan beberapa aspek anomali dari data validasi (misalnya, hari dengan jumlah penjualan es krim yang sangat tidak biasa karena festival lokal).
Perhitungan untuk R2 lebih kompleks daripada untuk metrik sebelumnya. Ini membandingkan jumlah perbedaan kuadrat antara label yang diprediksi dan aktual dengan jumlah perbedaan kuadrat antara nilai label aktual dan rata-rata nilai label aktual, seperti ini:
R2 = 1- ∑(y-ŷ)2 ÷ ∑(y-ȳ)2
Jangan terlalu khawatir jika terlihat rumit; sebagian besar alat pembelajaran mesin dapat menghitung metrik untuk Anda. Poin pentingnya adalah bahwa hasilnya adalah nilai antara 0 dan 1 yang menjelaskan proporsi varians yang dijelaskan oleh model. Dalam istilah sederhana, semakin dekat ke 1 nilai ini, semakin baik modelnya sesuai dengan data validasi. Dalam kasus model regresi es krim, R2 yang dihitung dari data validasi adalah 0,95.
Pelatihan berulang
Metrik yang dijelaskan di atas umumnya digunakan untuk mengevaluasi model regresi. Dalam sebagian besar skenario dunia nyata, ilmuwan data akan menggunakan proses berulang untuk berulang kali melatih dan mengevaluasi model, bervariasi:
- Pemilihan fitur dan persiapan (memilih fitur mana yang akan disertakan dalam model, dan perhitungan yang diterapkan untuk membantu memastikan kecocokan yang lebih baik).
- Pemilihan algoritma (Kami menjelajahi regresi linier dalam contoh sebelumnya, tetapi ada banyak algoritma regresi lainnya)
- Parameter algoritma (pengaturan numerik untuk mengontrol perilaku algoritma, yang lebih akurat disebut hiperparameter untuk membedakannya dari parameter x dan y).
Setelah beberapa iterasi, model yang menghasilkan metrik evaluasi terbaik yang dapat diterima untuk skenario tertentu dipilih.