Aktivasi Suara
Catatan
Topik ini terutama mengacu pada pengalaman konsumen kami, yang saat ini dikirimkan dalam Windows 10 (versi 1909 dan yang lebih lama) Untuk informasi selengkapnya, lihat Akhir dukungan untuk Cortana di Windows dan Teams.
Cortana, teknologi asisten pribadi ditunjukkan untuk pertama kalinya di Konferensi Pengembang Microsoft BUILD pada tahun 2013. Platform ucapan Windows digunakan untuk mendukung semua pengalaman ucapan dalam Windows 10 seperti Cortana dan Dikte. Aktivasi suara adalah fitur yang memungkinkan pengguna memanggil mesin pengenalan ucapan dari berbagai status daya perangkat dengan mengucapkan frasa tertentu - "Hey Cortana". Untuk membuat perangkat keras yang mendukung teknologi aktivasi suara, tinjau informasi dalam topik ini.
Catatan
Menerapkan aktivasi suara adalah proyek yang signifikan dan merupakan tugas yang diselesaikan oleh vendor SoC. OEM dapat menghubungi vendor SoC mereka untuk informasi tentang implementasi SoC aktivasi suara mereka.
Pengalaman Pengguna Akhir Cortana
Untuk memahami pengalaman interaksi suara yang tersedia di Windows, tinjau topik-topik ini.
| Topik | Deskripsi |
|---|---|
| Apa itu Cortana? | Memberikan gambaran umum dan arah penggunaan untuk Cortana |
Pengantar Aktivasi Suara "Hey Cortana" dan "Pelajari suara saya"
Hey Cortana" Aktivasi Suara
Fitur Aktivasi Suara (VA) "Hey Cortana" memungkinkan pengguna untuk dengan cepat melibatkan pengalaman Cortana di luar konteks aktif mereka (yaitu, apa yang saat ini ada di layar) dengan menggunakan suara mereka. Pengguna sering ingin dapat langsung mengakses pengalaman tanpa harus berinteraksi secara fisik menyentuh perangkat. Untuk pengguna ponsel ini mungkin karena mengemudi di dalam mobil dan memiliki perhatian dan tangan mereka terlibat dengan pengoperasian kendaraan. Untuk pengguna Xbox, ini mungkin karena tidak ingin menemukan dan menyambungkan pengontrol. Untuk pengguna PC, ini mungkin karena akses cepat ke pengalaman tanpa harus melakukan beberapa tindakan mouse, sentuhan, dan/atau keyboard, misalnya komputer di dapur.
Aktivasi suara menyediakan input ucapan yang selalu mendengarkan melalui frasa kunci yang telah ditentukan sebelumnya atau "frasa aktivasi". Frasa kunci dapat diucapkan sendiri ("Hey Cortana") sebagai perintah bertahap, atau diikuti dengan tindakan ucapan, misalnya, "Hey Cortana, di mana pertemuan saya berikutnya?", perintah berantai.
Istilah Deteksi Kata Kunci, menjelaskan deteksi kata kunci oleh perangkat keras atau perangkat lunak.
Kata kunci hanya aktivasi terjadi ketika hanya kata kunci Cortana yang dikatakan, Cortana memulai dan memutar suara EarCon untuk menunjukkan bahwa ia telah memasuki mode mendengarkan.
Perintah berantai menjelaskan kemampuan mengeluarkan perintah segera mengikuti kata kunci (seperti "Hey Cortana, call John") dan meminta Cortana memulai (jika belum dimulai) dan mengikuti perintah (memulai panggilan telepon dengan John).
Diagram ini menggambarkan aktivasi berantai dan hanya kata kunci.
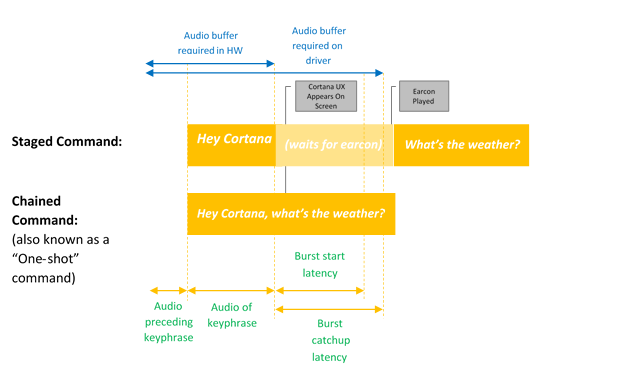
Microsoft menyediakan spotter kata kunci default OS (spotter kata kunci perangkat lunak) yang digunakan untuk memastikan kualitas deteksi kata kunci perangkat keras dan untuk memberikan pengalaman Hey Cortana dalam kasus di mana deteksi kata kunci perangkat keras tidak ada atau tidak tersedia.
Fitur "Pelajari suara saya"
Fitur "Pelajari suara saya" memungkinkan pengguna untuk melatih Cortana mengenali suara unik mereka. Ini dicapai oleh pengguna yang memilih Pelajari bagaimana saya mengatakan "Hai Cortana" di layar pengaturan Cortana. Pengguna kemudian mengulangi enam frasa yang dipilih dengan hati-hati yang menyediakan berbagai pola fonetik yang memadai untuk mengidentifikasi atribut unik suara pengguna.
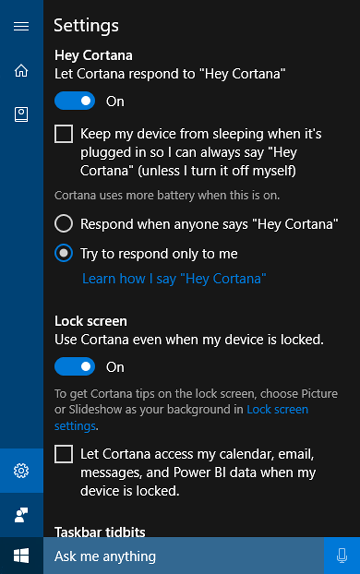
Saat aktivasi suara dipasangkan dengan "Pelajari suara saya", kedua algoritma akan bekerja sama untuk mengurangi aktivasi palsu. Ini sangat berharga untuk skenario ruang pertemuan, di mana satu orang mengatakan "Hey Cortana" di ruangan yang penuh dengan perangkat. Fitur ini hanya tersedia untuk Windows 10 versi 1903 dan yang lebih lama.
Aktivasi suara didukung oleh spotter kata kunci (KWS) yang bereaksi jika frasa kunci terdeteksi. Jika KWS adalah untuk membangunkan perangkat dari status bertenaga rendah, solusinya dikenal sebagai Wake on Voice (WoV). Untuk informasi selengkapnya, lihat Bangun di Voice.
Glosarium Istilah
Glosarium ini meringkas istilah yang terkait dengan aktivasi suara.
| Istilah | Contoh/definisi |
|---|---|
| Perintah Bertahap | Contoh: Hey Cortana <jeda, tunggu earcon> Apa cuacanya? Ini terkadang disebut sebagai "Perintah dua bidikan" atau "Khusus kata kunci" |
| Perintah Berantai | Contoh: Hey Cortana bagaimana cuacanya? Ini kadang-kadang disebut sebagai "Perintah satu kali" |
| Aktivasi Suara | Skenario menyediakan deteksi kata kunci dari frasa kunci aktivasi yang telah ditentukan sebelumnya. Misalnya, "Hey Cortana" adalah skenario Aktivasi Suara Microsoft. |
| WoV | Wake-on-Voice – Teknologi yang memungkinkan Aktivasi Suara dari layar mati, status daya yang lebih rendah, ke layar pada status daya penuh. |
| WoV dari Siaga Modern | Wake-on-Voice dari status layar Siaga Modern (S0ix) ke layar pada status daya penuh (S0). |
| Siaga Modern | Infrastruktur Windows Low Power Idle - penerus Connected Standby (CS) di Windows 10. Status pertama siaga modern adalah ketika layar mati. Status tidur terdalam adalah ketika berada di DRIPS/Ketahanan. Untuk informasi selengkapnya, lihat Siaga Modern |
| KWS | Spotter kata kunci - algoritma yang menyediakan deteksi "Hey Cortana" |
| SW KWS | Spotter kata kunci perangkat lunak – implementasi KWS yang berjalan pada host (CPU). Untuk "Hey Cortana", SW KWS disertakan sebagai bagian dari Windows. |
| HW KWS | Spotter kata kunci yang dilepas perangkat keras – implementasi KWS yang berjalan offload pada perangkat keras. |
| Burst Buffer | Buffer melingkar yang digunakan untuk menyimpan data PCM yang dapat 'meledak' jika terjadi deteksi KWS, sehingga semua audio yang memicu deteksi KWS disertakan. |
| Adaptor OEM Detektor Kata Kunci | Shim tingkat driver yang memungkinkan HW berkemampuan WoV untuk berkomunikasi dengan Windows dan tumpukan Cortana. |
| Model | File data model akustik yang digunakan oleh algoritma KWS. File data bersifat statis. Model dilokalkan, satu per lokal. |
Mengintegrasikan Spotter Kata Kunci Perangkat Keras
Untuk mengimplementasikan spotter kata kunci perangkat keras (HW KWS) Vendor SoC harus menyelesaikan tugas-tugas berikut.
- Buat detektor kata kunci kustom berdasarkan sampel SYSVAD yang dijelaskan nanti dalam topik ini. Anda akan menerapkan metode ini dalam COM DLL, yang dijelaskan dalam Antarmuka Adaptor OEM Pendeteksi Kata Kunci.
- Terapkan peningkatan WAVE RT yang dijelaskan dalam Peningkatan WAVERT.
- Berikan entri file INF untuk menjelaskan API kustom apa pun yang digunakan untuk deteksi kata kunci.
- PKEY_FX_KeywordDetector_StreamEffectClsid
- PKEY_FX_KeywordDetector_ModeEffectClsid
- PKEY_FX_KeywordDetector_EndpointEffectClsid
- PKEY_SFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_MFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- PKEY_EFX_KeywordDetector_ProcessingModes_Supported_For_Streaming
- Tinjau rekomendasi perangkat keras dan panduan pengujian di Rekomendasi Perangkat Audio. Topik ini memberikan panduan dan rekomendasi untuk desain dan pengembangan perangkat input audio yang dimaksudkan untuk digunakan dengan Platform Ucapan Microsoft.
- Mendukung perintah bertahap dan berantai.
- Dukung "Hey Cortana" untuk masing-masing lokal Cortana yang didukung.
- API (Objek Pemrosesan Audio) harus memberikan efek berikut:
- AEC
- AGC
- NS
- Efek untuk mode pemrosesan Ucapan harus dilaporkan oleh MFX APO.
- APO dapat melakukan konversi format sebagai MFX.
- APO harus menghasilkan format berikut:
- 16 kHz, mono, FLOAT.
- Secara opsional merancang API kustom apa pun untuk meningkatkan proses pengambilan audio. Untuk informasi selengkapnya, lihat Objek Pemrosesan Audio Windows.
Persyaratan WoV spotter kata kunci yang dibongkar perangkat keras (HW KWS)
- HW KWS WoV didukung selama status S0 Working dan status tidur S0 juga dikenal sebagai Modern Standby.
- HW KWS WoV tidak didukung dari S3.
Persyaratan AEC untuk HW KWS
Untuk Windows Versi 1709
- Untuk mendukung HW KWS WoV untuk status tidur S0 (Modern Standby) AEC tidak diperlukan.
- HW KWS WoV untuk status kerja S0 tidak didukung di Windows Versi 1709.
Untuk Windows Versi 1803
- HW KWS WoV untuk status kerja S0 didukung.
- Untuk mengaktifkan HW KWS WoV untuk status kerja S0, APO harus mendukung AEC.
Gambaran Umum Kode Sampel
Ada kode sampel untuk driver audio yang mengimplementasikan aktivasi suara di GitHub sebagai bagian dari sampel adaptor audio virtual SYSVAD. Disarankan untuk menggunakan kode ini sebagai titik awal. Kode tersedia di lokasi ini.
https://github.com/Microsoft/Windows-driver-samples/tree/main/audio/sysvad/
Untuk informasi selengkapnya tentang driver audio sampel SYSVAD, lihat Driver Audio Sampel.
Informasi Sistem Pengenalan Kata Kunci
Dukungan Tumpukan Audio Aktivasi Suara
Antarmuka eksternal tumpukan audio untuk mengaktifkan Aktivasi Suara berfungsi sebagai alur komunikasi untuk platform ucapan dan driver audio. Antarmuka eksternal dibagi menjadi tiga bagian.
- Antarmuka Driver Perangkat Pendeteksi Kata Kunci (DDI). Antarmuka Driver Perangkat pendeteksi Kata Kunci bertanggung jawab untuk mengonfigurasi dan mempersenjatai HW Keyword Spotter (KWS). Ini juga digunakan oleh driver untuk memberi tahu sistem peristiwa deteksi.
- DLL Adaptor OEM Detektor Kata Kunci. DLL ini mengimplementasikan antarmuka COM untuk menyesuaikan data buram khusus driver untuk digunakan oleh OS untuk membantu deteksi kata kunci.
- Peningkatan streaming WaveRT. Penyempurnaan memungkinkan driver audio untuk melakukan streaming data audio yang di-buffer dari deteksi kata kunci.
Properti Titik Akhir Audio
Bangunan grafik titik akhir audio terjadi secara normal. Grafik disiapkan untuk menangani lebih cepat daripada pengambilan real time. Tanda waktu pada buffer yang diambil tetap benar. Secara khusus, tanda waktu akan dengan benar mencerminkan data yang diambil di masa lalu dan di-buffer, dan sekarang "meledak".
Teori Bluetooth melewati streaming audio
Driver mengekspos filter KS untuk perangkat tangkapannya seperti biasa. Filter ini mendukung beberapa properti KS dan peristiwa KS untuk mengonfigurasi, mengaktifkan, dan memberi sinyal peristiwa deteksi. Filter ini juga menyertakan pabrik pin tambahan yang diidentifikasi sebagai pin spotter kata kunci (KWS). Pin ini digunakan untuk mengalirkan audio dari spotter kata kunci.
Propertinya adalah:
- Jenis kata kunci yang didukung - KSPROPERTY_SOUNDDETECTOR_PATTERNS. Properti ini diatur oleh sistem operasi untuk mengonfigurasi kata kunci yang akan terdeteksi.
- Daftar GUID pola kata kunci - KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. Properti ini digunakan untuk mendapatkan daftar GUID yang mengidentifikasi jenis pola yang didukung.
- Bersenjata - KSPROPERTY_SOUNDDETECTOR_ARMED. Properti baca/tulis ini adalah status Boolean sederhana yang menunjukkan apakah detektor dipersenjatai. OS mengatur ini untuk melibatkan detektor kata kunci. OS dapat menghapus ini untuk melepaskan. Driver secara otomatis menghapus ini ketika pola kata kunci diatur dan juga setelah kata kunci terdeteksi. (OS harus direarm.)
- Cocokkan hasil - KSPROPERTY_SOUNDDETECTOR_MATCHRESULT. Properti baca ini menyimpan data hasil setelah deteksi terjadi.
Peristiwa yang diaktifkan saat kata kunci terdeteksi adalah peristiwa KSEVENT_SOUNDDETECTOR_MATCHDETECTED .
Urutan Operasi
Startup Sistem
- OS membaca jenis kata kunci yang didukung untuk memverifikasi bahwa OS memiliki kata kunci dalam format tersebut.
- OS mendaftar untuk peristiwa perubahan status detektor.
- OS mengatur pola kata kunci.
- OS mempersenjatai detektor.
Saat Menerima Peristiwa KS
- Driver melucuti detektor.
- OS membaca status detektor kata kunci, mengurai data yang dikembalikan, dan menentukan pola mana yang terdeteksi.
- OS menyerbu ulang detektor.
Pengoperasian Driver dan Perangkat Keras Internal
Saat detektor dipersenjatai, perangkat keras dapat terus menangkap dan menyangga data audio dalam buffer FIFO kecil. (Ukuran buffer FIFO ini ditentukan oleh persyaratan di luar dokumen ini, tetapi biasanya mungkin ratusan milidetik hingga beberapa detik.) Algoritma deteksi beroperasi pada streaming data melalui buffer ini. Desain driver dan perangkat keras sedemikian rupa sehingga sementara bersenjata tidak ada interaksi antara driver dan perangkat keras dan tidak ada gangguan pada prosesor "aplikasi" sampai kata kunci terdeteksi. Ini memungkinkan sistem untuk mencapai status daya yang lebih rendah jika tidak ada aktivitas lain.
Ketika perangkat keras mendeteksi kata kunci, perangkat keras akan menghasilkan gangguan. Saat menunggu driver melayani interupsi, perangkat keras terus mengambil audio ke dalam buffer, memastikan tidak ada data setelah kata kunci hilang, dalam batas buffering.
Tanda Waktu Kata Kunci
Setelah mendeteksi kata kunci, semua solusi aktivasi suara harus menyangga semua kata kunci lisan, termasuk 250ms sebelum dimulainya kata kunci. Driver audio harus menyediakan tanda waktu yang mengidentifikasi awal dan akhir frasa kunci di aliran.
Untuk mendukung tanda waktu mulai/akhir kata kunci, perangkat lunak DSP mungkin perlu menandakan waktu peristiwa secara internal berdasarkan jam DSP. Setelah kata kunci terdeteksi, perangkat lunak DSP berinteraksi dengan driver untuk menyiapkan peristiwa KS. Driver dan perangkat lunak DSP perlu memetakan tanda waktu DSP ke nilai penghitung kinerja Windows. Metode melakukan ini khusus untuk desain perangkat keras. Salah satu solusi yang mungkin adalah bagi driver untuk membaca penghitung kinerja saat ini, mengkueri tanda waktu DSP saat ini, membaca penghitung kinerja saat ini lagi, dan kemudian memperkirakan korelasi antara penghitung kinerja dan waktu DSP. Kemudian mengingat korelasi, driver dapat memetakan tanda waktu DSP kata kunci ke tanda waktu penghitung kinerja Windows.
Antarmuka Adaptor OEM Detektor Kata Kunci
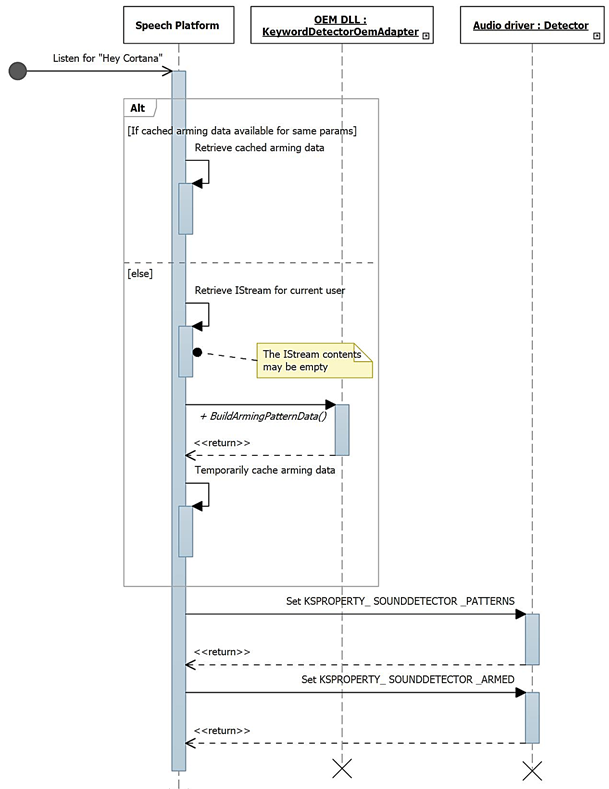
OEM memasok implementasi objek COM yang bertindak sebagai perantara antara OS dan driver, membantu menghitung atau mengurai data buram yang ditulis dan dibaca ke driver audio melalui KSPROPERTY_SOUNDDETECTOR_PATTERNS dan KSPROPERTY_SOUNDDETECTOR_MATCHRESULT.
CLSID objek COM adalah GUID jenis pola detektor yang dikembalikan oleh KSPROPERTY_SOUNDDETECTOR_SUPPORTEDPATTERNS. OS memanggil CoCreateInstance yang meneruskan GUID jenis pola untuk membuat instans objek COM yang sesuai yang kompatibel dengan jenis pola kata kunci dan memanggil metode pada antarmuka IKeywordDetectorOemAdapter objek.
Persyaratan Model Utas COM
Implementasi OEM dapat memilih salah satu model utas COM.
IKeywordDetectorOemAdapter
Desain antarmuka mencoba untuk menjaga implementasi objek tanpa status. Dengan kata lain, implementasi tidak boleh memerlukan status untuk disimpan di antara panggilan metode. Bahkan, kelas C++ internal kemungkinan tidak memerlukan variabel anggota apa pun di luar yang diperlukan untuk mengimplementasikan objek COM secara umum.
Metode
Terapkan metode berikut.
- IKeywordDetectorOemAdapter::BuildArmingPatternData
- IKeywordDetectorOemAdapter::ComputeAndAddUserModelData
- IKeywordDetectorOemAdapter::GetCapabilities
- IKeywordDetectorOemAdapter::P arseDetectionResultData
- IKeywordDetectorOemAdapter::VerifyUserKeyword
KATA KUNCIID
Enumerasi KEYWORDID mengidentifikasi teks/fungsi frasa kata kunci dan juga digunakan dalam adaptor Windows Biometric Service. Untuk informasi selengkapnya, lihat Gambaran Umum Kerangka Kerja Biometrik - Komponen Platform Inti
typedef enum {
KwInvalid = 0,
KwHeyCortana = 1,
KwSelect = 2
} KEYWORDID;
KATA KUNCISELECTOR
Struktur KEYWORDSELECTOR adalah sekumpulan ID yang secara unik memilih kata kunci dan bahasa tertentu.
typedef struct
{
KEYWORDID KeywordId;
LANGID LangId;
} KEYWORDSELECTOR;
Menangani Data Model
Model independen pengguna statis - DLL OEM biasanya akan menyertakan beberapa data model independen pengguna statis baik yang disertakan dalam DLL atau dalam file data terpisah yang disertakan dengan DLL. Kumpulan ID kata kunci yang didukung yang dikembalikan oleh rutinitas GetCapabilities akan bergantung pada data ini. Misalnya, jika daftar ID kata kunci yang didukung yang dikembalikan oleh GetCapabilities mencakup KwHeyCortana, data model independen pengguna statis akan menyertakan data untuk "Hey Cortana" (atau terjemahannya) untuk semua bahasa yang didukung.
Model dependen pengguna dinamis - IStream menyediakan model penyimpanan akses acak. OS meneruskan penunjuk antarmuka IStream ke banyak metode pada antarmuka IKeywordDetectorOemAdapter. OS mendukung implementasi IStream dengan penyimpanan yang sesuai hingga 1MB data.
Konten dan struktur data dalam penyimpanan ini ditentukan oleh OEM. Tujuan yang dimaksudkan adalah untuk penyimpanan persisten data model dependen pengguna yang dihitung atau diambil oleh DLL OEM.
OS dapat memanggil metode antarmuka dengan IStream kosong, terutama jika pengguna belum pernah melatih kata kunci. OS membuat penyimpanan IStream terpisah untuk setiap pengguna. Dengan kata lain, IStream tertentu menyimpan data model untuk satu dan hanya satu pengguna.
Pengembang DLL OEM memutuskan cara mengelola data dependen pengguna dan independen pengguna. Namun, itu tidak akan pernah menyimpan data pengguna di mana saja di luar IStream. Salah satu kemungkinan desain DLL OEM akan beralih secara internal antara mengakses IStream dan data independen pengguna statis tergantung pada parameter metode saat ini. Desain alternatif mungkin memeriksa IStream di awal setiap panggilan metode dan menambahkan data independen pengguna statis ke IStream jika belum ada, memungkinkan sisa metode untuk mengakses hanya IStream untuk semua data model.
Pemrosesan Audio Pelatihan dan Operasi
Seperti yang dijelaskan sebelumnya, alur UI pelatihan menghasilkan kalimat lengkap yang kaya secara fonetik tersedia di aliran audio. Setiap kalimat diteruskan secara individual ke IKeywordDetectorOemAdapter::VerifyUserKeyword untuk memverifikasi bahwa kalimat tersebut berisi kata kunci yang diharapkan dan memiliki kualitas yang dapat diterima. Setelah semua kalimat dikumpulkan dan diverifikasi oleh UI, semuanya diteruskan dalam satu panggilan ke IKeywordDetectorOemAdapter::ComputeAndAddUserModelData.
Audio diproses dengan cara unik untuk pelatihan aktivasi suara. Tabel berikut ini meringkas perbedaan antara pelatihan aktivasi suara dan penggunaan pengenalan suara reguler.
|
| Pelatihan Suara | Pengenalan Suara | |
| Mode | Mentah | Mentah atau Ucapan |
| Pin | Normal | KWS |
| Format Audio | Float 32-bit (Jenis = Audio, Subtipe = IEEE_FLOAT, Laju Pengambilan Sampel = 16 kHz, bit = 32) | Dikelola oleh tumpukan audio OS |
| Mikha | Mikrofon 0 | Semua mikrofon dalam array, atau mono |
Gambaran Umum Sistem Pengenalan Kata Kunci
Diagram ini memberikan gambaran umum tentang sistem pengenalan kata kunci.
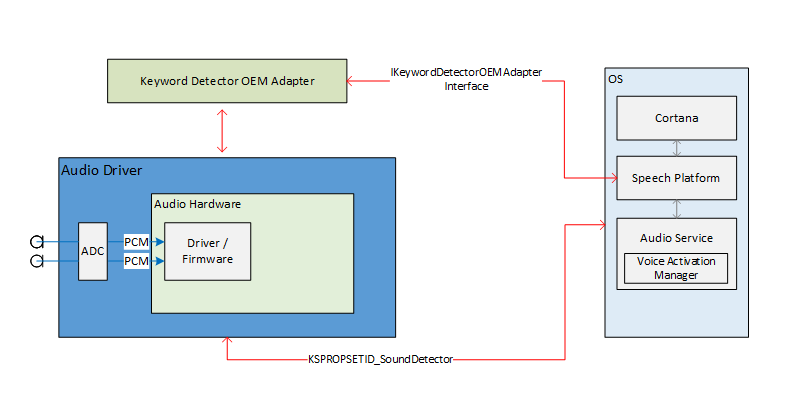
Diagram Urutan Pengenalan Kata Kunci
Dalam diagram ini, modul runtime ucapan ditampilkan sebagai "platform ucapan". Seperti disebutkan sebelumnya, platform ucapan Windows digunakan untuk mendukung semua pengalaman ucapan dalam Windows 10 seperti Cortana dan dikte.
Selama startup, kemampuan dikumpulkan menggunakan IKeywordDetectorOemAdapter::GetCapabilities.
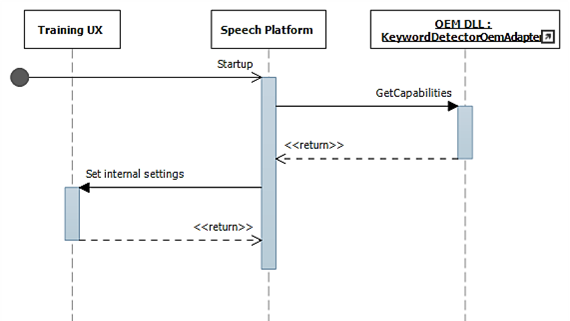
Kemudian ketika pengguna memilih untuk "Pelajari suara saya", alur pelatihan dipanggil.
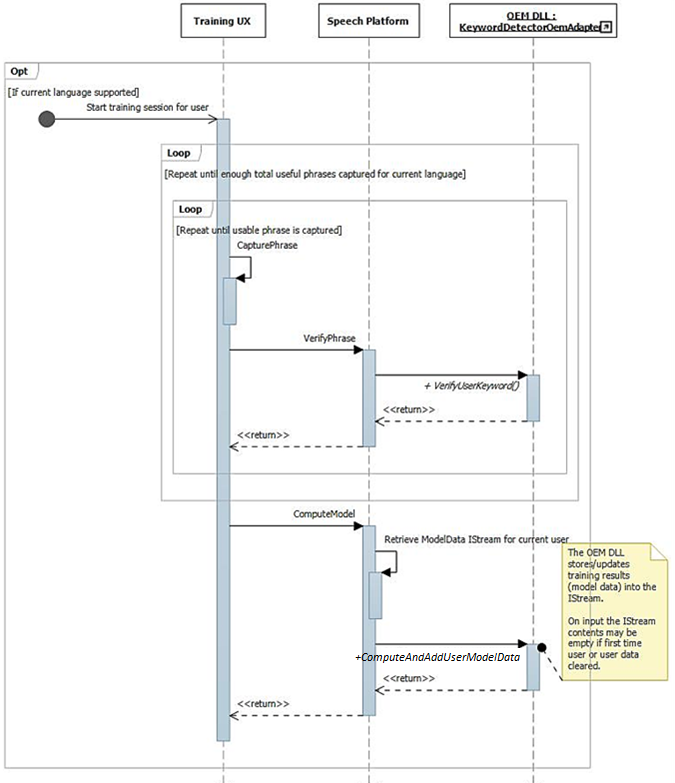
Diagram ini menjelaskan proses arming untuk deteksi kata kunci.
Peningkatan WAVERT
Antarmuka miniport didefinisikan untuk diimplementasikan oleh driver miniport WaveRT. Antarmuka ini menyediakan metode untuk menyederhanakan driver audio, meningkatkan performa dan keandalan alur audio OS, atau mendukung skenario baru. Properti antarmuka perangkat PnP baru didefinisikan memungkinkan driver untuk memberikan ekspresi statis dari batasan ukuran buffer-nya ke OS.
Ukuran Buffer
Driver beroperasi di bawah berbagai batasan saat memindahkan data audio antara OS, driver, dan perangkat keras. Kendala ini mungkin disebabkan oleh transportasi perangkat keras fisik yang memindahkan data antara memori dan perangkat keras, dan/atau karena modul pemrosesan sinyal dalam perangkat keras atau DSP terkait.
Solusi HW-KWS harus mendukung ukuran pengambilan audio setidaknya 100ms dan hingga 200ms.
Driver mengekspresikan batasan ukuran buffer dengan mengatur properti perangkat DEVPKEY_KsAudio_PacketSize_Constraints pada antarmuka perangkat PnP KSCATEGORY_AUDIO dari filter KS yang memiliki pin streaming KS. Properti ini harus tetap valid dan stabil saat antarmuka filter KS diaktifkan. OS dapat membaca nilai ini kapan saja tanpa harus membuka handel ke driver dan memanggil driver.
DEVPKEY_KsAudio_PacketSize_Constraints
Nilai properti DEVPKEY_KsAudio_PacketSize_Constraints berisi struktur KSAUDIO_PACKETSIZE_CONSTRAINTS yang menjelaskan batasan perangkat keras fisik (yaitu karena mekanisme mentransfer data dari buffer WaveRT ke perangkat keras audio). Struktur ini mencakup array 0 atau lebih struktur KSAUDIO_PACKETSIZE_PROCESSINGMODE_CONSTRAINT yang menjelaskan batasan khusus untuk mode pemrosesan sinyal apa pun. Driver mengatur properti ini sebelum memanggil PcRegisterSubdevice atau mengaktifkan antarmuka filter KS-nya untuk pin streaming-nya.
IMiniportWaveRTInputStream
Driver mengimplementasikan antarmuka ini untuk koordinasi aliran data audio yang lebih baik dari driver ke OS. Jika antarmuka ini tersedia pada aliran pengambilan, OS menggunakan metode pada antarmuka ini untuk mengakses data di buffer WaveRT. Untuk informasi selengkapnya lihat, IMiniportWaveRTInputStream::GetReadPacket
IMiniportWaveRTOutputStream
Miniport WaveRT secara opsional mengimplementasikan antarmuka ini untuk disarankan untuk menulis kemajuan dari OS dan untuk mengembalikan posisi stream yang tepat. Untuk informasi selengkapnya lihat IMiniportWaveRTOutputStream::SetWritePacket, IMiniportWaveRTOutputStream::GetOutputStreamPresentationPosition dan IMiniportWaveRTOutputStream::GetPacketCount.
Tanda waktu penghitung kinerja
Beberapa rutinitas driver mengembalikan tanda waktu penghitung kinerja Windows yang mencerminkan waktu pengambilan sampel atau disajikan oleh perangkat.
Dalam perangkat yang memiliki alur DSP yang kompleks dan pemrosesan sinyal, menghitung tanda waktu yang akurat mungkin menantang dan harus dilakukan dengan bijaksana. Tanda waktu tidak boleh hanya mencerminkan waktu di mana sampel ditransfer ke atau dari OS ke DSP.
- Dalam DSP, lacak stempel waktu sampel menggunakan beberapa jam dinding DSP internal.
- Antara driver dan DSP, hitung korelasi antara penghitung kinerja Windows dan jam dinding DSP. Prosedur untuk ini dapat berkisar dari sangat sederhana (tetapi kurang tepat) hingga cukup kompleks atau baru (tetapi lebih tepat).
- Faktor dalam setiap penundaan konstan karena algoritma pemrosesan sinyal atau alur atau transportasi perangkat keras, kecuali penundaan ini diperhitungkan sebaliknya.
Operasi Baca Burst
Bagian ini menjelaskan interaksi OS dan driver untuk pembacaan ledakan. Pembacaan burst dapat terjadi di luar skenario aktivasi suara selama driver mendukung model WaveRT streaming berbasis paket, termasuk fungsi IMiniportWaveRTInputStream::GetReadPacket .
Dua skenario baca contoh ledakan dibahas. Dalam satu skenario, jika miniport mendukung pin yang memiliki kategori pin KSNODETYPE_AUDIO_KEYWORDDETECTOR maka driver akan mulai menangkap dan menyangga data secara internal saat kata kunci terdeteksi. Dalam skenario lain, driver dapat secara opsional menyangga data secara internal di luar buffer WaveRT jika OS tidak membaca data dengan cukup cepat dengan memanggil IMiniportWaveRTInputStream::GetReadPacket.
Untuk meledakkan data yang telah diambil sebelum transisi ke KSSTATE_RUN, driver harus menyimpan informasi tanda waktu sampel yang akurat bersama dengan data tangkapan yang di-buffer. Tanda waktu mengidentifikasi instan pengambilan sampel sampel yang diambil.
Setelah transisi aliran ke KSSTATE_RUN, driver segera mengatur peristiwa pemberitahuan buffer karena sudah memiliki data yang tersedia.
Pada kejadian ini, OS memanggil GetReadPacket() untuk mendapatkan informasi tentang data yang tersedia.
a. Driver mengembalikan nomor paket data yang diambil yang valid (0 untuk paket pertama setelah transisi dari KSSTATE_STOP ke KSSTATE_RUN), dari mana OS dapat memperoleh posisi paket dalam buffer WaveRT serta posisi paket relatif terhadap awal aliran.
b. Driver juga mengembalikan nilai penghitung kinerja yang sesuai dengan instan pengambilan sampel pertama dalam paket. Perhatikan bahwa nilai penghitung kinerja ini mungkin relatif lama, tergantung pada berapa banyak data pengambilan yang telah di-buffer dalam perangkat keras atau driver (di luar buffer WaveRT).
c. Jika ada lebih banyak data buffer yang belum dibaca, driver juga tersedia: i. Segera mentransfer data tersebut ke ruang buffer WaveRT yang tersedia (yaitu ruang yang tidak digunakan oleh paket yang dikembalikan dari GetReadPacket), mengembalikan true untuk MoreData, dan mengatur peristiwa pemberitahuan buffer sebelum kembali dari rutinitas ini. Atau, ii. Perangkat keras program untuk meledakkan paket berikutnya ke ruang buffer WaveRT yang tersedia, mengembalikan false untuk MoreData, dan kemudian mengatur peristiwa buffer ketika transfer selesai.
OS membaca data dari buffer WaveRT menggunakan informasi yang dikembalikan oleh GetReadPacket().
OS menunggu peristiwa pemberitahuan buffer berikutnya. Penantian mungkin segera berakhir jika driver mengatur pemberitahuan buffer dalam langkah (2c).
Jika driver tidak segera mengatur peristiwa dalam langkah (2c), driver mengatur peristiwa setelah mentransfer lebih banyak data yang diambil ke buffer WaveRT dan membuatnya tersedia bagi OS untuk dibaca
Buka (2). Untuk pin detektor kata kunci KSNODETYPE_AUDIO_KEYWORDDETECTOR, driver harus mengalokasikan buffering ledakan internal yang cukup untuk setidaknya 5000ms data audio. Jika OS gagal membuat aliran pada pin sebelum buffer meluap, driver dapat mengakhiri aktivitas buffer internal dan sumber daya terkait gratis.
Bangun di Voice
Wake On Voice (WoV) memungkinkan pengguna untuk mengaktifkan dan mengkueri mesin pengenalan ucapan dari layar nonaktif, status daya yang lebih rendah, ke layar aktif, status daya penuh dengan mengatakan kata kunci tertentu, seperti "Hey Cortana".
Fitur ini memungkinkan perangkat untuk selalu mendengarkan suara pengguna saat perangkat dalam keadaan daya rendah, termasuk ketika layar mati dan perangkat diam. Ini dilakukan dengan menggunakan mode mendengarkan, yang merupakan daya yang lebih rendah jika dibandingkan dengan penggunaan daya yang jauh lebih tinggi yang terlihat selama perekaman mikrofon normal. Pengenalan ucapan berdaya rendah memungkinkan pengguna untuk hanya mengatakan frasa kunci yang telah ditentukan sebelumnya seperti "Hey Cortana", diikuti dengan frasa ucapan berantai seperti "kapan janji saya berikutnya" untuk memanggil ucapan dengan cara hands-free. Ini akan berfungsi terlepas dari apakah perangkat sedang digunakan atau diam dengan layar mati.
Tumpukan audio bertanggung jawab untuk mengkomunikasikan data bangun (ID pembicara, pemicu kata kunci, tingkat keyakinan) serta memberi tahu klien yang tertarik bahwa kata kunci telah terdeteksi.
Validasi pada Sistem Siaga Modern
WoV dari status diam sistem dapat divalidasi pada sistem Modern Standby menggunakan Modern Standby Wake on Voice Basic Test pada SUMBER daya AC dan Modern Standby Wake on Voice Basic Test pada DC-power Source di HLK. Pengujian ini memeriksa bahwa sistem memiliki spotter kata kunci perangkat keras (HW-KWS), dapat memasuki Deepest Runtime Idle Platform State (DRIPS) dan dapat bangun dari Modern Standby pada perintah suara dengan latensi resume sistem kurang dari atau sama dengan satu detik.
Saran dan Komentar
Segera hadir: Sepanjang tahun 2024 kami akan menghentikan penggunaan GitHub Issues sebagai mekanisme umpan balik untuk konten dan menggantinya dengan sistem umpan balik baru. Untuk mengetahui informasi selengkapnya, lihat: https://aka.ms/ContentUserFeedback.
Kirim dan lihat umpan balik untuk